当前位置:网站首页>手撕二叉搜索树(Binary Search Tree)
手撕二叉搜索树(Binary Search Tree)
2022-06-29 06:41:00 【林慢慢脑瓜子嗡嗡的】
1.二叉搜索树的概念
二叉搜索树又称二叉排序树。
二叉搜索树的特性
1. 二叉搜索树的左孩子比父节点小,右孩子比父节点大。
2.二叉搜索树的左子树的全部节点都小于根节点,右子树的全部节点都大于根节点。
3.所有节点的左右子树都为二叉搜索树
4. 键值是唯一的,所以二叉搜索树不能有相同的键值。
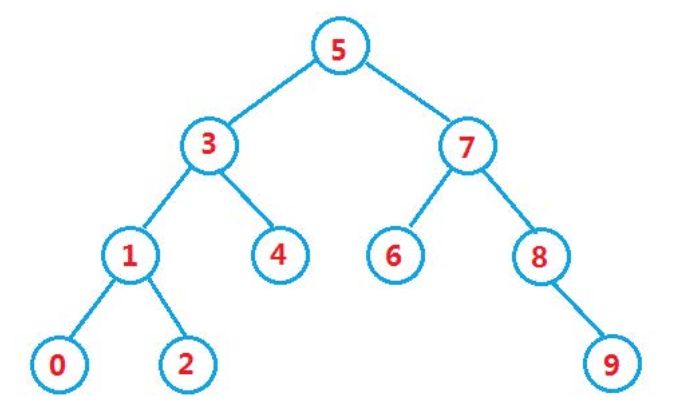
二叉搜索树的使用场景:
根据使用场景的不同,二叉搜索树还分为K模型和KV模型:
K模型:即只有key作为关键码,只需要存储Key即可,关键码即为需要搜索到的值。如STL中的set
KV模型:每一个关键码key,都有与之对应的值Value,即<Key, Value>的键值对。如STL中的map
2.二叉搜索树的性能分析
由于二叉搜索树的特征,对有n个结点的二叉搜索树,若每个元素查找的概率相等,则二叉搜索树平均查找长度是结点在二叉搜索树的深度的函数,即结点越深,则比较次数越多。
但对于同一个关键码集合,如果各关键码插入的次序不同,可能得到不同结构的二叉搜索树:

如上图所示,最优情况下,二叉搜索树为完全二叉树,其平均比较次数为:log2N

最差情况下,二叉搜索树退化为单支树,其平均比较次数为:N/2。
3.二叉搜索树的实现
这里只介绍最常用的查找、插入、删除三个接口
节点由左右指针和一个值val构成
template<class K>
struct BSTreeNode
{
public:
BSTreeNode(const K& val = K())
:_left(nullptr)
, _right(nullptr)
, _val(val)
{}
BSTreeNode<K>* _left;
BSTreeNode<K>* _right;
K _val;
};
排序
根据二叉搜索树的特性,左子树小于根节点,右子树大于根节点。
所以通过一趟中序遍历,即可获得排序的结果。
根据这条性质,你可以AC leetcode 98.验证二叉搜索树
查找
二叉搜索树的查找十分简单,键值比根节点大则进入右子树,键值比根节点小则进入左子树,他的思路有点类似于
二分查找,平均时间复杂度为O(log2N)。
但如果构建时树为有序数列,则二叉搜索树会退化为单支树,时间复杂度则会变为O(N)

退化成单支树时间复杂度剧增怎么办?
为搜索二叉树加上平衡二叉树的属性,也就是我们通常所说的AVL树。
查找操作的实现
从根节点出发,比根节点大则查找右子树,比根节点小则查找左子树,相同则返回。如果遍历完还没找到,则说明不存在此树中,返回nullptr
Node* Find(const K& key)
{
//根据二叉搜索树的性质,从根节点出发,比根节点大则查找右子树,比根节点小则查找左子树
Node* cur = _root;
while (cur)
{
//比根节点大则查找右子树
if (key > cur->_key)
{
cur = cur->_right;
}
//比根节点小则查找左子树
else if (key < cur->_key)
{
cur = cur->_left;
}
//相同则返回
else
{
return cur;
}
}
//遍历完则说明查找不到,返回false
return nullptr;
}
插入
首先要找到我们需要插入的位置(为了保证能够找到父节点还需要用一个指针指向父节点),找到了合适的位置后,我们需要判断当前的键值比父节点大还是比父节点小,来决定应该插入到父节点的左子树还是右子树
1.如果是空树,直接插入。
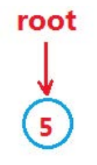
2.如果树非空,先找到要插入的结点位置,再插入。

插入操作的实现
- 插入节点一定是插入值为NULL节点的位置
- 插入节点后记得父节点要与插入节点连接
- 插入的节点比当前节点大往右子树走,反之往左子树走,相等返回false(插入失败)
bool Insert(const K& key)
{
//如果此时树为空,则初始化根节点
if (_root == nullptr)
{
_root = new Node(key);
return true;
}
Node* cur = _root;
Node* parent = cur;
//找到合适的插入位置
while (cur)
{
//比根节点大则查找右子树
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
//比根节点小则查找左子树
else if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
//相同则返回false,因为搜索树不能存在相同数据
else
{
return false;
}
}
cur = new Node(key);
//判断cur要插入到parent的左子树还是右子树
if (parent->_key > key)
{
parent->_left = cur;
}
else if (parent->_key < key)
{
parent->_right = cur;
}
return true;
}
删除

针对被删除节点分4种情况:
1.空树
2.叶子结点(比如删除9)
3.只有一个孩子(比如删除8)
4.有两个孩子(比如删除1)
对于第一种情况,即空树,返回false即可;
对于第二种情况,直接删除叶子结点;
对于第三种情况,若要删除的结点只有左孩子结点,则删除该结点且使被删除节点的双亲结点指向被删除节点的左孩子结点,若要删除的结点只有右孩子结点,则删除该结点且使被删除节点的双亲结点指向被删除结点的右孩子结点。
对于第四种情况,采用替代法删除结点,即找到该节点左子树中key值最大的结点或者找到其右子树key值最小的结点,把该节点的值赋给要删除的结点,然后将这个替代的结点删除即可。
再接着进一步分析,这里的第二、三种情况可以合并处理,因为叶子节点的左右子树都为空,即使让父节点指向这两个空节点,也没有任何问题。
删除操作的实现(非递归):
bool erase(const K& key)
{
Node* cur = _root;
Node* parent = cur;
while (cur)
{
if (key > cur->_key)
{
parent = cur;
cur = cur->_right;
}
else if (key < cur->_key)
{
parent = cur;
cur = cur->_left;
}
else
{
//二、三种情况合并处理,如果当前结点只有一个子树,则让父节点指向他的子树
//处理只有右子树时
if (cur->_left == nullptr)
{
//如果当前节点为根节点,则让右子树成为新的根节点
if (cur == _root)
{
_root = cur->_right;
}
else
{
//判断当前节点是他父节点的哪一个子树
if (parent->_right == cur)
{
parent->_right = cur->_right;
}
else
{
parent->_left = cur->_right;
}
}
delete cur;
}
//处理只有左子树时
else if (cur->_right == nullptr)
{
//如果当前节点为根节点,则让左子树成为新的根节点
if (cur == _root)
{
_root = cur->_left;
}
else
{
if (parent->_right == cur)
{
parent->_right = cur->_left;
}
else
{
parent->_left = cur->_left;
}
}
delete cur;
}
//处理左右子树都不为空时,选取左子树的最右节点或者右子树的最左节点
else
{
//这里选取的是左子树的最右节点
Node* LeftMax = cur->_left;
Node* LeftMaxParent = cur;
//找到左子树的最右节点
while (LeftMax->_right)
{
LeftMaxParent = LeftMax;
LeftMax = LeftMax->_right;
}
//替换节点
std::swap(cur->_kv, LeftMax->_kv);
//判断当前节点是他父节点的哪一个子树, 因为已经是最右子树了,所以这个节点的右子树为空,但是左子树可能还有数据,所以让父节点指向他的左子树
//并且删除最右节点
if (LeftMax == LeftMaxParent->_left)
{
LeftMaxParent->_left = LeftMax->_left;
}
else
{
LeftMaxParent->_right = LeftMax->_left;
}
delete LeftMax;
}
return true;
}
}
return false;
}
删除操作的实现(递归):
void DeleteNodeR(Node*& root, const K& val)
{
//删除前先递归找到该节点
if (root == nullptr)
return;
if (root->_val < val)
{
DeleteNodeR(root->_right, val);
}
else if (root->_val>val)
{
DeleteNodeR(root->_left, val);
}
else
{
Node* del = root;
if (root->_left == nullptr)
{
//情况1/2/3
//传引用的妙用
root = root->_right;
}
else if (root->_right == nullptr)
{
//情况1/2/3
root = root->_left;
}
else
{
//情况4
Node* cur = root->_right;
while (cur->_left)
{
cur = cur->_left;
}
//swap(cur->_val, root->_val); -->破坏了树的结构
root->_val = cur->_val;
DeleteNodeR(root->_right, cur->_val);
return;
}
delete del;
}
}
void DeleteNodeR(const K& val)
{
DeleteNodeR(_root, val);
}
递归与非递归对比:
在情况4当中,找到了替换节点,实际上一步就可以把他删除( 迭代写法一步就删除了),但是采用递归的话又需要重新在子树当中去找到新的删除的节点,所以实际上没有迭代的写法优。并且递归自带弊端:栈帧的开销,栈溢出的危险。
边栏推荐
- 【深度之眼吴恩达机器学习作业班第四期】逻辑回归编程实现
- qtcreator设置字符集
- 声波通讯 - 流式数据处理 - 窗口对齐
- Wechat applet learning notes (summer vacation)
- Using cdockablepane to realize floating window in MFC
- [FreeRTOS] interrupt mechanism
- 反思 - 完美主义
- Listen to textarea input through Keyup to change button style
- Simulation analysis of sailing dynamics
- 手把手系列---安装SpotBugs、并快速上手使用
猜你喜欢








随机推荐
Oracle 批量插入数据-插入民族数据
精选西门子PLC工程实例源码【共300套】
基于Sophus的Ceres优化
【深度之眼吴恩达机器学习作业班第四期】Linear Regression with One Variable,单变量线性回归
自动化测试 - uiautomator2框架应用 - 自动打卡
搭建jenkins环境并自动关联打包好的工程jar进行自动发布
SVM,人脸识别遇到的问题及解决方法
Kingbasees coping with transaction rollback caused by too fast growth of table age
tf. to_ int64
Kingbasees v8r6 cluster maintenance case -- single instance data migration to cluster case
Cartographer中的线程池操作
指针引用数组元素
How to solve the cross domain problem of mobile phone accessing the web in the web development scenario
Select distinct on statement in kingbasees
施努卡:3D视觉识别系统 3D视觉检测原理
呕心沥血总结出来的MySQL常见错误以及解决方法(二)
多态中的向上和向下转型
Concurrent idempotent anti shake
路由详解(九阳真经)
Software testing