当前位置:网站首页>[opengl] pre bake using computational shaders
[opengl] pre bake using computational shaders
2022-07-03 14:42:00 【ZJU_ fish1996】
reference: https://www.khronos.org/opengl/wiki/Compute_Shader
At this time a year ago, I made a volume cloud effect , At that time, I left a hole —— My noise is calculated in real time , Therefore, it will bring a certain jam ; The correct way is to bake the noise into a sheet 3D texture . Take advantage of a little time today , Fill this hole .
In fact, I did similar baking work a long time ago , For example IBL In effect , You need to bake an environment map , But because the desired result is just one 2D texture , So you can use vertices + The traditional way of slice element is to write texture , You can get around computational shaders . but 3D There is no way to apply a similar scheme to texture .
Of course , This can indeed be achieved through CPU To do the calculation , But considering the large amount of data 、 Discrete characteristics , Use GPU It is very appropriate to complete the calculation . actually CUDA It also provides a similar function , But for call graph API For rendering projects , Since the graph API It has integrated the solution of computational shaders , We tend to implement it with computational shaders .
Basic concepts
Compute Shader Does not belong to the rendering pipeline Part of , But a relatively independent process . Unlike vertex shaders, each vertex is executed once , The fragment shader executes once on each element of the rasterization , The space of computing shaders is abstract , Its execution times are defined by the function that calls the calculation .
As a whole , The implementation of computational shaders generally requires the following processes :
1. Assign texture / Buffer as input or output
2. Bind current shader
3. Bind the current input or output texture / buffer
4. Render instructions requesting calculation
5. Run multiple calculation shaders in parallel , And write the result
……
Input / Output
most important of all , The calculation shader has no user-defined input , No output ( notes : The so-called input and output here correspond to glsl In the code in/out). But we can input and output buffer / Texture data To read and write .
Here are some common examples that I can use , Please pay attention to the subtle differences of parameters in different situations :
(1) Bind the output with the calculation shader 2D texture
● Generate 2D texture
glGenTextures(1, &texId);
glBindTexture(GL_TEXTURE_2D, texId);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA32F, width, height, 0, GL_RGBA, GL_FLOAT, NULL);● binding 2D texture (C++ part )
glBindImageTexture(0, texId, 0, GL_FALSE,
0, GL_WRITE_ONLY, GL_RGBA32F);● binding 2D texture ( Shader section )
layout(binding = 0, rgba32f) uniform image2D texOut;
void main()
{
// texcoord : ivec2
// data : vec4
imageStore(texOut, texcoord, data); // How to write images
}(2) Bind the input with the calculation shader 2D texture
● Generate 2D texture
glGenTextures(1, &texId);
glBindTexture(GL_TEXTURE_2D, texId);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_2D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA32F, width, height, 0, GL_RGBA, GL_FLOAT, NULL);● binding 2D texture (C++ part )
glBindImageTexture(0, texId, 0, GL_FALSE,
0, GL_READ_ONLY, GL_RGBA32F);● binding 2D texture ( Shader section )
layout (binding = 0, rgba32f) uniform image2D texIn;
void main()
{
vec4 data = imageLoad(texIn, gl_GlobalInvocationID.xyz); // Read images
}(3) Bind the output with the calculation shader 3D texture
● Generate 3D texture
glGenTextures(1, &texId);
glBindTexture(GL_TEXTURE_3D, texId);
glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_WRAP_S, GL_REPEAT);
glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_WRAP_T, GL_REPEAT);
glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_WRAP_R, GL_REPEAT);
glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
glTexImage3D(GL_TEXTURE_3D, 0, GL_RGBA32F, width, height, depth, 0, GL_RGBA, GL_FLOAT, NULL);● binding 3D texture (C++ part )
glBindImageTexture(0, m_cloudTexId, 0, GL_TRUE,
0, GL_WRITE_ONLY, GL_RGBA32F);● binding 3D texture ( Shader section )
layout(binding = 0, rgba32f) uniform image3D texOut;
void main()
{
// texcoord : ivec3
// data : vec4
imageStore(texOut, texcoord, data); // How to write images
}
Several differences mainly lie in :
(1) Layered attribute of image .1D/2D by GL_FALSE, 3D by GL_TRUE
(2) The reading and writing nature of images .GL_READ_ONLY、GL_WRITE_ONLY、GL_READ_WRITE
(3) binding Specify the image slot . be used for CPU and GPU The corresponding image in .
Execute calculation instructions
The calculation can be performed by calling one of the following two functions , Act on the currently active program . Although these commands are not drawing instructions , But they also belong to rendering instructions , It can be executed conditionally ( reference Conditions apply colours to a drawing ).
The first function can perform calculations , Specify the three dimensions of the workgroup at the same time . These numbers cannot be zero , And the number of working groups that can be allocated is limited :
void glDispatchCompute(GLuint num_groups_x, GLuint num_groups_y, GLuint num_groups_z);The workgroup count of the second function is stored in Buffer Object in , among Indirect Parameter specifies the current binding to GL_DISPATCH_INDIRECT_BUFFER Offset bytes on object . Indirect allocation bypasses OpenGL General error checking , Attempting to call with a workgroup size that exceeds the range may result in a crash or GPU hard-lock. This method should generally be applied to data that needs to be output from other places as counts .
void glDispatchComputeIndirect(GLintptr indirect);Workgroup size and local size
(1) Workgroup size
We notice that we are calling cs when , We will carry out glDispatchCompute, It contains three parameters , We call it workgroup size .
We use working groups to describe the space for computing shaders , Workgroups are the minimum number of computing operations that users can perform .
The working group is three-dimensional , Users can define the number of workgroups , Any of these can be 1, So we can also 1D or 2D Arithmetic , Not just 3D operation . such , We can process two-dimensional image data or linear array particle system more conveniently .
When the system calculates the working group , It can be done in any order , Therefore, the calculation of calculating shaders should be discrete 、 independent , It should not depend on the execution order of each group .
(2) Local size
In the shader , We also need to specify the number of calls to calculate the shader , We call it local size :
layout(local_size_x = X, local_size_y = Y, local_size_z = Z) in;The default size is 1, When you only want one-dimensional or two-dimensional workgroup space , You can specify only x or x and y, They must be greater than 0 Integer constant expression of .
Shader size can take local size as compile time constant (compile-time constant variable) Use , So you don't need to define it yourself :
A single workgroup is not equivalent to a single compute shader call , In a working group , There may be multiple calculation shader calls .
The value of the workgroup count is not necessarily equal to the local size of the workgroup , The number of calls to the function corresponding to the calculation shader is the product of the two . Each call will have a set of unique identification inputs .
Such a design is useful for performing various forms of image compression or decompression ; The local size can be set to the size of the image data block , The group count can be set as the image size divided by the block size . Each block will be processed as a workgroup .
Each call in the workgroup will “ parallel ” perform . The main purpose of distinguishing between workgroup count and local size is : A workgroup within different computational shader calls can communicate through shared variables . And different working groups ( In the same calculation shader call ) Can not communicate effectively , It is not ruled out that there is also the possibility of causing system deadlock .
Built in input variables
The calculation shader has the following built-in input variables :
in uvec3 gl_NumWorkGroups; // Number of currently scheduled workgroups
in uvec3 gl_WorkGroupID; // Currently scheduled workgroup id
in uvec3 gl_LocalInvocationID; // Current scheduled local call id
in uvec3 gl_GlobalInvocationID; // All scheduled global calls id
// gl_WorkGroupID * gl_WorkGroupSize + int gl_LocalInvocationID
in uint gl_LocalInvocationIndex; // gl_LocalInvocationID Of 1D edition Shared variables
Shared variables are shared by all calls in the workgroup . Can't be sampler Declared as a shared variable , But the array 、 The structure is declared as a shared variable .
shared uint foo = 0; // No initializers for shared variables.If you need to initialize a shared variable to a specific value , The variable display should be set to this value in one of the calls . Only one call must do this .
Limit
The maximum number of workgroups for a single call is determined by GL_MAX_COMPUTE_WORK_GROUP_COUNT Definition . You can use glGetIntegeri_v Inquire about .
The local size of the workgroup is limited by GL_MAX_COMPUTE_WORK_GROUP_SIZE Definition .
The total storage size of all shared variables is determined by GL_MAX_COMPUTE_SHARED_MEMORY_SIZE Definition .
example : Volume cloud texture baking
The following is an example of my implementation , Texture baking of volume cloud , Execute only once before starting rendering , Assign a with two channels 3D texture , among x Channel storage value noise ,y Channel storage worley noise :
In this case , We don't need to deal with complicated logic , So there is no need to group in shaders , So directly in CPU Specify the total group , Set to 1,1,1 that will do , Use it directly gl_GlobalInvocationID Indexes .
Note that when writing image data here , Subscript is an integer , The specific subscript corresponds to the working group size .
C++ Code :
void RenderCommon::CreateCloudTexture()
{
int size = 500;
QOpenGLFunctions* gl = QOpenGLContext::currentContext()->functions();
QOpenGLExtraFunctions* extraGL = QOpenGLContext::currentContext()->extraFunctions();
gl->glGenTextures(1, &m_cloudTexId);
gl->glBindTexture(GL_TEXTURE_3D, m_cloudTexId);
gl->glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_WRAP_S, GL_REPEAT);
gl->glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_WRAP_T, GL_REPEAT);
gl->glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_WRAP_R, GL_REPEAT);
gl->glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_MAG_FILTER, GL_LINEAR);
gl->glTexParameteri(GL_TEXTURE_3D, GL_TEXTURE_MIN_FILTER, GL_LINEAR);
extraGL->glTexImage3D(GL_TEXTURE_3D, 0, GL_RG32F, size, size, size, 0, GL_RGBA, GL_FLOAT, NULL);
QOpenGLShaderProgram* program = CResourceInfo::Inst()->CreateCSProgram("genCloudTex.csh");
program->bind();
extraGL->glBindImageTexture(0, m_cloudTexId, 0, GL_TRUE,
0, GL_WRITE_ONLY, GL_RG32F);
extraGL->glDispatchCompute(size, size, size);
}Shader code ( Noise calculation function is not included ):
#version 430 core
layout(binding = 0, rg32f) uniform image3D cloudTex;
layout(local_size_x = 1, local_size_y = 1, local_size_z = 1) in;
void main()
{
vec3 pos;
pos.x = float(gl_GlobalInvocationID.x) / 100;
pos.y = float(gl_GlobalInvocationID.y) / 100;
pos.z = float(gl_GlobalInvocationID.z) / 100;
float x = value_fractal(pos);
float y = worley(pos);
imageStore(cloudTex, ivec3(gl_GlobalInvocationID.xyz),vec4(x,y,0,0));
}
After writing , The image is in video memory , Generally speaking, we seldom need to read back CPU in , We can use normal textures ( Bind the corresponding texture id), Pass it to the next shader , At this point (0~1) Between the subscript index of this generated texture .
( Empathy , Static shadows / Lightmap baking & Some particles / Physics / Cloth calculation can also be placed in cs in )
边栏推荐
- String reverse order
- 洛谷P5018 [NOIP2018 普及组] 对称二叉树 题解
- Four data flows and cases of grpc
- NOI OPENJUDGE 1.5(23)
- The mail function of LNMP environment cannot send mail
- Thread. Sleep and timeunit SECONDS. The difference between sleep
- US stock listing of polar: how can the delivery of 55000 units support the valuation of more than 20billion US dollars
- 556. The next larger element III
- PHP GD image upload bypass
- Find the sum of the elements of each row of the matrix
猜你喜欢

Use of constraintlayout

如何查询淘宝天猫的宝贝类目

Sub GHz wireless solution Z-Wave 800 Series zg23 SOC and zgm230s modules

adc128s022 ADC verilog设计实现

Tailing rushes to the scientific and Technological Innovation Board: it plans to raise 1.3 billion, and Xiaomi Changjiang is the shareholder

Tonybot humanoid robot checks the port and corresponds to port 0701
Code writing and playing method of tonybot humanoid robot at fixed distance
ConstraintLayout 的使用
![洛谷P4047 [JSOI2010]部落划分 题解](/img/7f/3fab3e94abef3da1f5652db35361df.png)
洛谷P4047 [JSOI2010]部落划分 题解
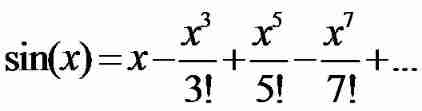
Zzuli:1053 sine function
随机推荐
Pyqt interface production (login + jump page)
光猫超级账号密码、宽带账号密码 获取
Sub GHz wireless solution Z-Wave 800 Series zg23 SOC and zgm230s modules
Four data flows and cases of grpc
Puzzle (016.4) domino effect
Zzuli:1048 factorial table
pyQt界面制作(登录+跳转页面)
NOI OPENJUDGE 1.5(23)
洛谷P5018 [NOIP2018 普及组] 对称二叉树 题解
Zzuli:1040 sum of sequence 1
Selective sorting
String substitution
Zhejiang University Edition "C language programming (4th Edition)" topic set reference ideas set
Niuke: crossing the river
The mail function of LNMP environment cannot send mail
洛谷P5194 [USACO05DEC]Scales S 题解
Talking about part of data storage in C language
分布式事务(Seata) 四大模式详解
Preliminary summary of structure
PHP GD image upload bypass