当前位置:网站首页>You know AI, database and computer system
You know AI, database and computer system
2022-06-30 03:49:00 【Suzhou program Dabai】
You know AI、 Database and computer system
Blogger introduction
Personal home page : Suzhou program white Personal community :CSDN All over the country 🤟 The authors introduce : China DBA union (ACDU) member ,CSDN All over the country ( Yuan ) Gathering place Administrator . Currently engaged in industrial automation software development . Good at C#、Java、 Machine vision 、 Underlying algorithms and other languages .2019 Qiyue software studio was established in ,2021 Registered in Suzhou Kaijie Intelligent Technology Co., Ltd If you have any questions, please send a private letter , I will reply in time when I see it WeChat ID :stbsl6, WeChat official account : Suzhou program white If it helps you , Welcome to your attention 、 give the thumbs-up 、 Collection ( One key, three links ) Those who want to join the technical exchange group can add my friends , The group will share learning materials
2018 At the database summit in SIGMOD On ,MIT Of Tim Kraska Published a paper entitled 《The Case for Learned Index Structures》( The abbreviation “Learned Index The paper ”), Put forward “Learned Index( Learning index )” The concept of , The reason why this paper has aroused great concern in the industry is not only “Learned Index” The concept is novel , It's more about Google AI person in charge Jeff Dean He is also the author of this paper . stay AI field , All have Jeff Dean The paper whose name appears , Both have the significance of technical direction beyond the paper itself .
Index is the core technology to improve the performance of data access in database system , since 20 century 70 s , Researchers in the field of database have proposed various index structures , Used to meet different types of access performance requirements , For example, for range queries B-tree、B+tree And LSM-tree、 Hash index for point queries 、 For Bloom filters that have queries .
These traditional indexing techniques are used in TB It works well under the data volume of unit , But the current data volume enters PB Even higher units , Traditional indexing technology has caused three problems : First of all , The space cost is too high , For example, the balanced tree index needs the help of O(n) Scale the extra space to index the original data , The index cost is too high under the condition of big data ; second , Traditional index technology uses index depth to support index scale , When there is a large amount of data, each query requires multiple indirect searches , for example B+tree Each query in requires access to all nodes on the path from the tree root to the leaf node , This makes B+tree The search performance of will become worse in large data sets ; Third , For hash functions , Large scale data brings high conflict probability , The performance of hash function deteriorates sharply under the condition of high collision probability .
Algorithm engineering generally believes that , The problem that has been fully algorithmized is not AI Object of Technology , There is no need to use AI technology , Here is an example ,GPT-3 After the model was released, some people tested the model in a conversational way to multiply larger numbers , Results found GPT-3 Multiplication error , So I think so GPT-3 The defects of the model , To some extent, this understanding is right AI The misunderstanding of ,“ Multiplication ” Such explicit deductive algorithms should have been calculated directly by rules ,AI It is not meant to deal with such problems . Data structures and their algorithms in computer technology , Such as balanced tree algorithm and hash algorithm , It is generally considered to be a typical field that has been fully algorithmized , Researchers generally do not think that there are still... In the field of data structure AI Space to play .
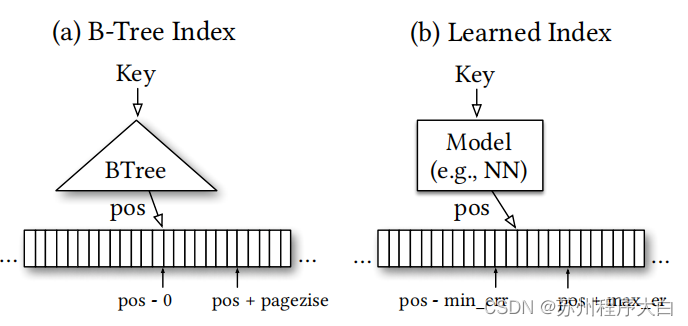
For the above questions ,“Learned Index The paper ” Put forward new ideas with depth and inspiration : The indexing technology of database is actually a model ( The first sentence of the thesis is “Indexes are models”), Such as range query , The model input is the key to query (key), The output is its value (value) Storage location , The minimum error range is 0( The target data is just at the beginning of page change )、 The maximum length is one page ( The target data is just at the end of the page ). If the model is described in a more algorithmic language , This model is actually predicting the cumulative distribution function of data (cumulative distribution function,CDF), But the traditional index technology is a universal data structure (general purpose data structures)—— The purpose of the model is to predict the cumulative distribution function of the data 、 The model does not consider the specific distribution of data in real applications —— This is the reason that affects the efficiency of traditional indexing technology . Let's take a simple example , If some part of the data key Is a continuous positive integer of fixed length , Then there is no need to use this part of data B-tree Indexes , Instead, you can directly record the first key Storage address , And then the query key Multiplying by a fixed length is the offset , In this way, you can use O(1) Complexity completes the query , instead of B-tree Indexed O(log n) Complexity , meanwhile , The storage cost of the index also goes from O(n) Down to O(1).
Through the above analysis , The problem is very clear ,“Learned Index The paper ” Put forward , If the traditional index model is replaced by the deep learning model , Let the model learn to fit the actual data , And then automatically generate indexes , It is possible to achieve higher efficiency than traditional indexing , This is it. “Learned Index” The concept of .
“Learned Index The paper ” A preliminary learning index framework is given (learning index framework,LIF) And recursive model index (recursive model index,RMI).LIF Is an index composition system , Used to generate index configuration 、 Automatically optimize and test indexes ,LIF Be able to learn simple models ( For example, linear regression model ), And rely on Tensorflow Training complex models ( For example, neural network model ). however ,LIF Do not use... When executing the model Tensorflow, Instead, the weight of the model is automatically extracted and an efficient C++ Index code .LIF Our code generation is designed for small models , It eliminated. Tensorflow All unnecessary overhead and tools for managing large models in .RMI It aims to solve the precision problem of learning index , It is inspired by the hybrid expert model ,RMI The structure of is a hierarchical model structure composed of multiple models ,RMI Each model in takes a key as input and returns a location , The output of the upper model is used to select the model of the next layer , The output of the last layer of model is RMI Output .
“Learned Index The paper ” The results of the experiment are impressive : Tested on multiple datasets ,“Learned Index” Search performance ratio B+tree fast 1.5 times ~3 times , And the required storage space is larger than B+ The tree is low 2 An order of magnitude .
Hash index of point query , It is a set of functional models and has O(1) Search performance of , therefore AI The optimization idea is different from the range query ,“Learned Index The paper ” It is proposed that a better hash function can be obtained by learning the distribution of keys (“Learned Hash-map”), That is, hash conflicts can be reduced .

For Bloom filters with queries ,“Learned Index The paper ” Then he put forward “ Learn about the bloom filter (Learned Bloom fifilters)”, Reduce the probability of hash collision by learning the data distribution , What needs to be noted here is ,“Learned Hash-map” And “Learned Bloom fifilters” Different ,“Learned Hash-map” The goal of is to reduce the probability of collision between existing keys , and “Learned Bloom fifilters” The goal of is to reduce the collision probability between existing and non-existent keys .“Learned Index The paper ” Proposed “Learned Bloom fifilters” The existential index is regarded as a binary probability classification task , And trained a RNN The model predicts the probability of the existence of the bond .

“Learned Index The paper ” yes “Learned Index” The beginning of the study , The solution is far from perfect , For example, the paper doesn't mention how to support data insertion , This is actually a very critical issue of indexing technology , Similar to data insertion can cause B-tree、B+tree And LSM-tree Readjustment of , Inserting a large amount of new data will change the distribution of keys , It makes the learning model need to be re learned , therefore ,“Learned Index The paper ” The realized technology is far from being practical .
“Learned Index The paper ” The most important value is to provide an enlightening analysis idea —— As long as one problem exists “ Predictability ”, Then it is possible to AI Reconsider the problem from the perspective of , And get new and better results . After decades of development, database indexing technology , It seems to have been well studied , But in “Learned Index The paper ” Before I remind you , It seems that no one has found that database indexing technology is actually a typical “ Predictability ” The problem also exists “ The purpose of index model is to predict the cumulative distribution function of data , However, the index model does not consider the specific distribution of data in real applications ” This obvious problem .
If from “ Predictability ” Further analysis from this perspective , There are a lot of problems in computer science “ Predictability ” Of , For example, widely used in computer systems Prefetching It's typical “ Predictability ” Mechanism 、 In the field of distributed big data “ Predictability ” There are many more questions , these “ Predictability ” The problem is AI Research has opened up a new space ,Google AI person in charge Jeff Dean stay 《The Case for Learned Index Structures》 Among the authors , It reflects this background .
边栏推荐
- 声网自研传输层协议 AUT 的落地实践丨Dev for Dev 专栏
- Redis is used in Windows system
- How to view Tencent's 2022 school recruitment salary, the total contract of cabbage is 40W?
- laravel9本地安装
- UML diagrams and list collections
- How to use Jersey to get the complete rest request body- How to get full REST request body using Jersey?
- What are the defaults for Binding. Mode=Default for WPF controls?
- 【笔记】AB测试和方差分析
- .NET 7 的 JWT 配置太方便了!
- Hisense A7 ink screen mobile phone cannot be started
猜你喜欢

How to view Tencent's 2022 school recruitment salary, the total contract of cabbage is 40W?

Linear interpolation of spectral response function

Implementation of property management system with ssm+ wechat applet

Number of students from junior college to Senior College (III)

MySQL performance optimization (5): principle and implementation of master-slave synchronization

【笔记】2022.5.23 MySQL

共124篇!墨天轮“高可用架构”干货文档分享(含Oracle、MySQL、PG)

(03).NET MAUI实战 基础控件
A GPU approach to particle physics

Node-RED系列(二八):基于OPC UA节点与西门子PLC进行通讯
随机推荐
Learning cyclic redundancy CRC check
[punch in - Blue Bridge Cup] day 4--------- split ('') cannot be used. There is a space after the last number of test cases. Split ()
【作业】2022.5.28 将CSV写入数据库
Pytorch Profiler+ Tensorboard + VS Code
绿色新动力,算力“零”负担——JASMINER X4系列火爆热销中
学校实训要做一个注册页面,要打开数据库把注册页面输入的内容存进数据库但是
dbt产品初体验
【论文阅读|深读】Role2Vec:Role-Based Graph Embeddings
How do college students make money by programming| My way to make money in College
Chapter 2 control structure and function (programming problem)
4-5 count words and spaces (15 points)
Litjson parses the generated JSON file and reads the dictionary in the JSON file
AppData文件夹下Local,Locallow和Roaming
利用反射整合ViewBinding和ViewHolder
How to use FME to create your own functional software
Number of students from junior college to Senior College (4)
C#【高级篇】 C# 接口(Interface)
【常见问题】浏览器环境、node环境的模块化问题
[Note] ab Test and Variance Analysis
SDS understanding in redis