当前位置:网站首页>Zero sample and small sample learning
Zero sample and small sample learning
2022-06-30 22:41:00 【deephub】
In this article , We will discuss a hot topic in different fields of machine learning and deep learning : Zero sample and small sample learning (Zero and Few Shot learning), They have different application scenarios in naturallanguageprocessing and computer vision .
Study with fewer samples
In the supervised classifier , What all models try to learn is to distinguish the characteristics of different objects , No matter what form the data exists , Such as images 、 Both video and text are the same . and · The idea of small sample learning is to learn the area classification by comparing the data , This model uses less data , And it performs better than the classical model . Support sets are often used in small sample learning (support set) Instead of training sets .
Small sample learning is a meta learning technique . Meta learning means : Learn to learn . Meta learning is a branch of metacognition , It studies the methods and cognitive processes of self-learning and learning process .
Support set
The data of support set is the same as that of training set , However, due to different learning methods, we call it support set .
K-Way N-Shot Support set : Support set has K class , It's in every class N sample .N-Shot Means the number of samples provided for each class . If each alternative has more samples , Models can be learned better .

In fewer classes , Models make it easier to classify data . in general , We can say : Less k And more n Better .
Why make it a support set ? Remember SVM Support vectors in , Namely SVM Data that distinguishes classification boundaries in , That's what support sets mean .
Similarity function
The idea of less sample learning is a similarity function . This means that SIM(X,X’), among “ SIM” Is a similarity function , and X and X’ Is the sample . The first thing to do is to learn similarity functions from large data sets . Then the similarity function is applied to predict .
Twin networks
Twin networks use positive and negative samples for classification . The following are examples of positive and negative samples :
(Tiger1,Tiger2,1)| (CAR1,CAR2,1)
(Tiger1,Car2,0)| (Tiger1,Car1,0)
This is the network structure :

The twin network first uses two images in the dataset , Then use some layers ( Here is an example of image data , Use convolution layer ), Create the input encoding vector . Finally, we try to learn the similarity function by using the difference layer and different loss functions .
The data entered into this network is :
- XA: Anchor data : Select randomly from the data set
- X+: Positive data : Same class as anchor
- X-: Negative data : Different categories of anchors
F function (CNN) Used to create encoding vectors . After the encoding vector , We can use :
D+ = || f(x^+) - f(x^a)||²
d- = || f(x^a)-f(x^ - )||²
With the edge alpha And similarity value , We can decide the type of sample .
We hope d-> =(d +) + alpha, otherwise , The loss is (d +) + alpha-(d-).
So the loss function is :max {(d +) + alpha-(d-)}
Few-Shot
The basic idea of small sample learning is to give a k-way n-shot Support set for , Train a Siamese network on a large training set . Then use the way of query to predict the category of samples .
Before training few samples to learn , First of all, we pre - train CNN Feature extraction ( Also known as embedding ), Use standards to monitor learning or Siamese Network pair CNN pretraining .
In fine tuning ,(x_j, y_j) It supports marked samples in a set .f(x_j) It's pre trained CNN Extracted feature vector .P_j = Softmax(W.f(x_j)+b) As a prediction . This can be achieved by using fine tuning W = M,b = 0., This means supporting centralized learning W and b:

Examples

consider 3-way 2-shot Support set for . Apply a neural network to each image F For feature extraction . Because each class has two images , So each class has two eigenvectors . You can get the mean value of these two vectors . Because we have 3 Category , We will have 3 An average vector . Now let's standardize them . Each vector is a representation of each class . For forecasting , We enter a query image . Get the feature vector of the query image . We will standardize it , And then I'm going to compare this vector to 3 Compare the mean vectors .

By comparison, we get our prediction classification
Single sample learning
one-shot learning It is a special case of learning with few samples , That is to learn from a sample and recognize the object again .
One way to use a single sample is to use CNN And with (n+1) Of softmax To detect whether there is a new image in the image seen by the model . But when there are not enough samples in your training data set , He doesn't work very well . And in addition to the new category, it must also be in SoftMax Use in layer (M+1) Neuron retraining model .
But we can use similar functions .
d(img1, img2) = The degree of difference between images , if d(img1, img2) <= r: identical ; if d(img1, img2) > r: Different
Zero sample learning
First , Let's see why zero sample learning is important . We are facing a large and growing number of categories . It is difficult to collect and annotate instances . And new categories are emerging .
Zero sample learning is what human beings can do , But classical machine learning cannot . For example, cross language dictionary induction ( Every pair of languages , Each word is a category ).
Pattern recognition from supervised to zero samples
Our previous practice in the classic classification model is like this :

But when new categories appear , How do you do that ? The key is zero sample learning . The main idea of zero sample learning is to embed categories into vectors .
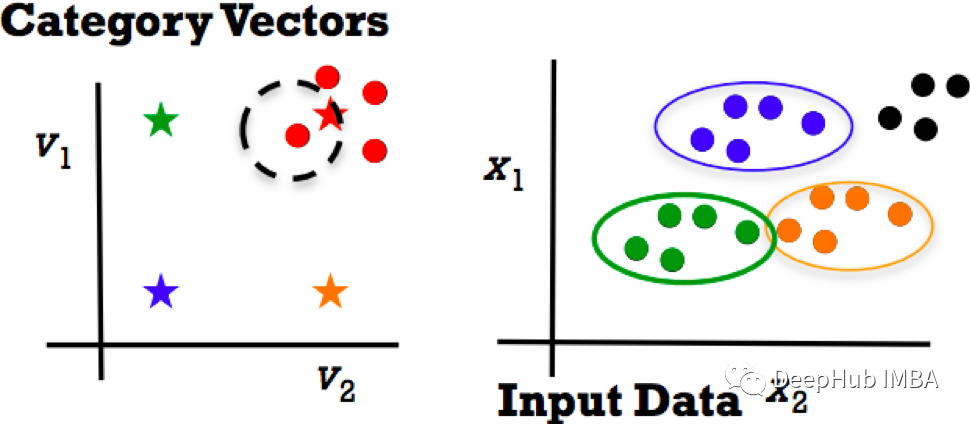
Feature category vector mapping :v = f(x)
If a new category appears , We can get its new class vector embedding , Then use the nearest neighbor and treat these vectors as labels . Data category vector graph can be extended to new categories . It means that we are learning from our past experience .
How zero sample learning works ?
In return / In the training steps of classification method , We will get some known classes - Category vector v And data x. What we want to learn is data attributes v=f(x). For example, using support vector machines (SVM).
In the test phase , We want to specify a vector for the new class v*. And then use f(x*) To find a new category . This method is simple and fast , And it also has the separability of categories .
In zero sample learning , Use energy Function to determine whether the category matches . set up x Is the data ,v Is a category vector . In the training phase , We train energy function E(x,v)=x 'Wv( This is called bilinear embedding of the return scalar ).
Data and task match (x=v) when E_w(x,v) It's going to get big , When the data does not match the task (x!=v),E_w(x,b) Very small . The goal of training is to maximize the edge spacing of this function .
And in the testing phase :
Classify new class instances x*, Specify v The vector computes each v Of E(x*, v*), Find the category with the largest margin , Maximum marginal separability means higher accuracy , But it is different from the classical machine learning model , It is complex and slow .
Where to get the category vector ?
“ supervise ” source :(1) Manual annotation of class attributes ,(2) Classification class level vector coding
“ Unsupervised ” source : Existing unstructured data (Word2Vec That's one example )
Some problems of zero sample learning
1、 Zero sample learning needs to be retrained in domain transfer / test

2、 Multi label zero-shot
Sometimes we want multi label classification , Instead of single label classification , This is dealing with classification vectors will be very troublesome , Then you can add every possible combination vector , for example : Trees , Trees + mountain , Trees + The beach ,…, But this has actually resulted in a doubling of the actual number of categories .
3、 Deep network can carry out zero sample learning

Taking many classical and latest transfer learning algorithms as special cases, it is still impossible to verify whether they are beneficial
The progress and application of zero sample learning at present
1、 Use it for audio recognition | UAV vision vector => Context vector , Generalize any new context through context vector, such as in UAV vision , Covariate context vector : distance 、 pitch 、 Speed 、 Rolling 、 Yaw, etc
2、 Cross language dictionary induction : Find the corresponding words in different languages
summary
Zero sample and small sample learning methods reduce the dependence on annotated data . So they are important for new areas and difficult areas of data collection . Few samples (Few-Shot Learning FSL) It's a machine learning problem ( from E, T and P Appoint ), among E Only a limited number of examples are included , With supervision information . The existing FSL The problem is mainly about supervising learning . Zero sample learning (Zero-shot learning, ZSL) It is a problem solution in machine learning , Learners observe samples from classes that are not observed in training during the test , And predict the class they belong to .
https://avoid.overfit.cn/post/129aa457af7b4dff9fa33dcaf0015968
author :Amirhossein Abaskohi
边栏推荐
- 手机上怎么开股票账户?另外,手机开户安全么?
- AtCoder Beginner Contest 255
- Architecture of IM integrated messaging system sharing 100000 TPS
- Doker的容器数据卷
- "Team training competition" Shandong multi university training 3
- [golang] golang实现截取字符串函数SubStr
- dba
- Classic case of multithreading
- What are the contents and processes of software validation testing? How much does it cost to confirm the test report?
- How to ensure the security of our core drawings by drawing encryption
猜你喜欢

What is the experience of pairing with AI? Pilot vs alphacode, Codex, gpt-3

Swift 5.0 - creation and use of swift framework

Based on the open source stream batch integrated data synchronization engine Chunjun data restore DDL parsing module actual combat sharing

2022-06-30: what does the following golang code output? A:0; B:2; C: Running error. package main import “fmt“ func main() { ints := make

机器学习编译入门课程学习笔记第二讲 张量程序抽象

Some memory problems summarized

实现多方数据安全共享,解决普惠金融信息不对称难题

"Paddle + camera" has become a "prefabricated dish" in the AI world, and it is easier to implement industrial AI quality inspection

As the public cloud market enters the deep water, can the calm Amazon cloud still sit still?

A new one from Ali 25K came to the Department, which showed me what the ceiling is
随机推荐
When unittest automatically tests multiple use cases, the logging module prints repeatedly to solve the problem
Redis的事务和锁机制
leetcode:104. 二叉树的最大深度
How to judge whether the JS object is empty
有孚网络混合云,加速企业数字化转型升级
AtCoder Beginner Contest 255
软件确认测试的内容和流程有哪些?确认测试报告需要多少钱?
What if the taskbar is blank after win11 update? Solution to blank and stuck taskbar after win11 update
Store Nagios monitoring information into MySQL
Failed to configure a DataSource: ‘url‘ attribute is not specified and no embedded datasource could
Deployment of microservices based on kubernetes platform
How to use filters in jfinal to monitor Druid for SQL execution?
Win11如何优化服务?Win11优化服务的方法
微信小程序通过点击事件传参(data-)
手机上怎么开股票账户?另外,手机开户安全么?
如何使用 DataAnt 监控 Apache APISIX
Is it difficult to get a certified equipment supervisor? What is the relationship with the supervising engineer?
零样本和少样本学习
The sandbox is being deployed on the polygon network
What does the software test report contain? How to obtain high quality software test reports?