当前位置:网站首页>翁恺C语言程序设计网课笔记合集
翁恺C语言程序设计网课笔记合集
2022-08-02 10:40:00 【InfoQ】
0. 前言
1. 背景
计算机和编程语言
//例:hello world!
#include<stdio.h>
int main()
{
printf("Hello World!\n");//输出“Hello World!(换行)”引号内的部分
return 0;
}
计算机的思维方式
- 枚举法代入x=1,不行;代入x=2,不行;代入……
- 二分法代入x=5,小了;代入x=7……
- 解释:借助一个程序,那个程序可以试图理解你的程序,然后按照你的要求执行
- 编译:借助一个程序把你的程序翻译成机器语言写的程序,然后计算机就可以直接执行了。
为什么编程入门从C学起?

- 在很多场合,C语言是唯一的选择
- 现代编程语言在语法上差异很小,基本都和C接近
- 语言的能力、适用领域主要是由库和传统决定的。
C的简单历史
编程软件用什么
2. 入门:从Hello World开始
第一个C程序
#include<stdio.h>
int main()
{
printf("Hello World!\n");
return 0;
}
详解第一个C程序
#include<stdio.h>
int main()
{
return 0;
}
简单计算
printf("%d",23+43);
printf("23+43=%d",23+43);
3. 变量
变量定义
- 有办法输入数字;
- 有地方放输入的数字;
- 输入的数字参与计算。
int price=0;//定义了整形变量price,类型是int,初始值=0
printf("请输入金额(元):");
int change=100-price;
printf("找您%d元。\n",change);
变量赋值与初始化
int price=0;//其中=是赋值运算符,把右边的值赋给左边的变量。
int a=0,b=1;
int charge=100-price;//C语言
int price=0;
printf("请输入金额(元):");
scanf("%d",&price);
int change=100-price;
printf("找您%d元。\n",change);
//传统的ANSI C只能在开头的地方定义变量
int price=0;
int change=0;
printf("请输入金额(元):");
scanf("%d",&price);
change=100-price;
printf("找您%d元。\n",change);
变量输入
scanf()常量vs变量
const int amount=100;
浮点数
int a,b;
printf("a/b*3");//改进为a/b*3.0
表达式
int hour1,min1;
int hour2,min2;
scanf("%d %d",&hour1,&min1);
scanf("%d %d",&hour2,&min2);
int t1=hour1*60+min1;//把小时转化为分钟单位
int t2=hour2*60+min2;
int t=t2-t1;
printf("时间差是%d小时%d分。“,t/60,t%60);//t/60是小时部分;t%60取余,是分钟部分
运算符优先级
%lf%fint c=1+(b=a)+-= result=a=b=3+c;
result=(result=result*2)*6*(result=3+result);
交换变量
a=b;
b=a;
c=a;
a=b;
b=c;
复合赋值
a+=5a=a+5-=*=/=a*=b+5a=a*(b+5)a=a*b++--a++++aa++++a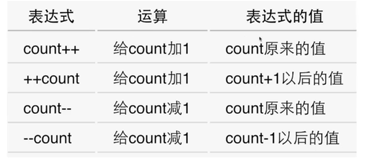
++--4. 判断(选择结构)
if(条件){
要执行的语句,只有条件成立时才会执行
}
判断的条件
printf("%d\n",5>3);
printf("%d\n",5==3);
int r=a>0;==!=5>3==6>41==16>5>41>4找零计算器
st=>start: 开始
i1=>inputoutput: 输入购买的金额
i2=>inputoutput: 输入支付的票面
o1=>operation: 计算找零
c=>condition: 判断余额是否充足
o2=>inputoutput: 打印找零
o3=>inputoutput: 告知用户余额不足以购买
e=>end: 结束
st->i1->i2->o1->c
c(yes)->o2->e
c(no)->o3->e
//初始化
int price=0;
int bill=0;
//读入金额和票面
printf("请输入金额:");
scanf("%d",&price);
printf("请输入票面:");
scanf("%d",&bill);
//计算找零
///* */否则
else{ }if int a,b;
printf("请输入两个整数:");
scanf("%d %d",&a,&b);
int max=0;
if(a>b)max=a;
else max=b;
printf("大的那个是%d\n",max);
int a,b;
printf("请输入两个整数:");
scanf("%d %d",&a,&b);
int max=b;
if(a>b)max=a;
printf("大的那个是%d\n",max);
没有大括号的if语句
if(a>b)
max=a;
;嵌套的if-else
if(a>b)
{
if(a>c)max=a;
else max=c;
}
else
{
if(b>c)max=b;
else max=c;
}
级联的if-else if
flowchat
st=>start: 开始
i=>inputoutput: 输入
o=>inputoutput: 输出
c1=>condition: 是否满足条件1
c2=>condition: 是否满足条件2
o1=>inputoutput: 输出条件1
o2=>inputoutput: 输出条件2
o3=>inputoutput: 输出条件3
en=>end: 结束
st->i->c1
c1(yes)->o1->en
c1(no)->c2
c2(yes)->o2->en
c2(no)->o3->en
else
{
if()
else
}
if(x<0)f=-1;
else if(x==0)f=0;
else f=1;
printf("%d",f);
if(x<0)printf("%d",-1);
else if(x==0)printf("%d",0);
else printf("%d",1);
if-else的常见错误
- 忘记写大括号的话,条件成立时只执行后面一句
- If后面无分号
- ==和=:if只要求括号里是0或非0
- 使人困惑的else尊重warning!大括号内的语句加tab缩进是代码风格。3.2.4 多路分支
switch(print){
case 1:
printf("1");
break;
case 2:
printf("2");
break;
case 3:
printf("3");
break;
default:
printf("0");
}
switchcasemon=1int i=1;
switch ( i%3 ) {
case 0: printf("zero");
case 1: printf("one");
case 2: printf("two");
}
5. 循环(循环结构)
if(n!=0)
{
n/=10;i++;
}
if(n!=0)
{
n/=10;i++;
}
while 循环
- 用户输入x;
- 初始化n为0;
- X/=10,去掉个位;
- cnt++;
- 如果x>0,回到3;
- 否则cnt就是结果。
do-while循环
循环计算
- While可以用do while吗?
- 为什么计数从0开始,可以从1开始吗?
- 为什么while判断条件是x>1?
- 循环最后输出的是多少?
#include<stdio.h>
int main()
{
int x,ret=0;
scanf("%d",&x);
int t=x;
while(x>1){
x/=2;
ret++;
}
printf("log2 of %d is %d.",t,ret);
return 0;
}
猜数游戏
- 因为要不断重复去猜,所以我们要用到循环
- 实际写出程序之前,我们可以先用文字描述出程序的思路。
- 核心重点是循环的条件。
- 人们往往会考虑循环终止的条件。
st=>start: 开始
i=>inputoutput: 用户输入猜的数
ocnt=>operation: count++
o=>operation: 计算机随机想一个数,记在number里
c=>condition: 判断a是否等于number
e=>end: 结束
o2=>inputoutput: 告诉用户大了还是小了
oe=>operation: 输出cnt猜的次数
st->o->i->ocnt->c
c(yes)->oe->e
c(no)->o2(right)->i
//先加入两个头文件#include<stdlib.h>和#include<time.h>
#include<stdio.h>
#include<stdlib.h>
#include<time.h>
int main()
{
srand(time(0));//Main里加上srand(time(0)); 先不用管什么意思
int a=rand();//如果想要a是100以内的整数:用取余即可(a%=100)
int number=rand()%100+1;//这样召唤出来的数范围是1~100
//不管怎样用户都要进入这个循环,输入至少一个数;所以应该用do-while循环。
}
算平均数
flowchat
st=>start: sum=0,cnt=0
i1=>inputoutput: 读num
c=>condition: num!=-1?
o=>operation: sum+=num, cnt++
op=>inputoutput: 计算和打印结果
e=>end: end
st->i1->c
c(yes)->o->i1
c(no,left)->op->e
整数逆序
for循环
n!=n*(n-1)*(n-2)*……*2*1i++i--for(int i=0;i<n;i++)循环的计算和选择
循环控制
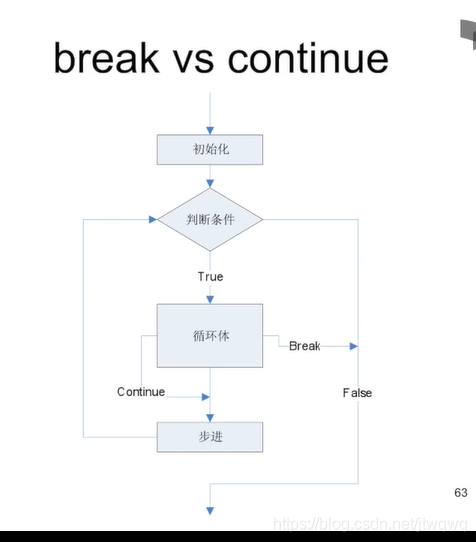
嵌套的循环
int x;//再scan x
int isprime=1;
for(int i=2;i<x;i++){
if(x%i==0){
isprime=0;
break;
}
}//再根据isprime是不是1判断x是不是素数
从嵌套的循环中跳出
for(one=1;one<x*10;one++)
{
for(two=1;two<x*10/2;two++)
{
for(five=1;five<x*10/5;five++)//break跳出的是这层循环,而没有跳出上面的两层循环
{
if(one+two*2+five*5==x*10)
{
printf("可以用%d个一角加%d个两角加%d个五角得到%d元\n",one,two,five,x);
break;
}
}
}
}
exit=0;exit=1;if(exit)break;//接力break
int x,one,two,five,x;
int exit=0;
scanf("%d",&x);
for(one=1;one<x*10;one++)
{
for(two=1;two<x*10/2;two++)
{
for(five=1;five<x*10/5;five++)
{
if(one+two*2+five*5==x*10)
{
printf("可以用%d个一角加%d个两角加%d个五角得到%d元\n",one,two,five,x);
exit=1;
break;
}
}
if(exit==1)break;
}
if(exit==1)break;
}
goto out//goto
int x,one,two,five,x;
int exit=0;
scanf("%d",&x);
for(one=1;one<x*10;one++)
{
for(two=1;two<x*10/2;two++)
{
for(five=1;five<x*10/5;five++)
{
if(one+two*2+five*5==x*10)
{
printf("可以用%d个一角加%d个两角加%d个五角得到%d元\n",one,two,five,x);
goto out;
}
}
}
}
out:
return 0;
补充:PTA 例题
前n项和
#include<stdio.h>
int main()
{
int n;
double sum=0.0;
scanf("%d",&n);
for(int i=1;i<=n;i++)
{
sum+=1.0/i;
}
printf("f(%d)=%f",n,sum);
return 0;
}
sign=1;sum+=sign*1.0/i;
sign=-sign;
double sign=1.0整数分解
- 先求x的逆序数t
- 逆序逐位输出t
求最大公约数
循环t++
if(u/t==0&&v/t==0)gcd=t;//不断刷新gcd
if(t==u||t==v)break;//并输出gcd;
- 如果b=0,计算结束,a就是最大公约数;
- 否则,让a=b,b=a%b;
- 回到第一步(可以使用之前提到过的变量表格法来人工运行)
求符合给定条件的整数集
int i,a,j,k,cnt=0;
scanf("%d",&a);
i=a;
//思路:i,j,k都从a开始,从小到大逐渐增加到a+3,三者不能相等
while(i<=a+3){
j=a;
while(j<=a+3){
k=a;
while(k<=a+3){
if(i!=j&&j!=k&&i!=k){
printf("%d%d%d",i,j,k);
cnt++;
if(cnt==6){
printf("\n");
cnt=0;
}
else printf(" ");
}
k++;
}
j++;
}
i++;
}

水仙花数
打印乘法口诀表

统计素数并求和
isprime=1;isprime=1if(m==1)m++;猜数游戏
n项求和
dividend=2;//分母
divisor=1;//分子
for(i=1;i<=n;i++){
sum+=dividend/divisor;
t=dividend;
dividend+=divisor;
divisor=t;
}
printf("%.2f/n",sum);
约分最简分式
- scanf("%d/%d")这样处理输入
- 辗转相除法寻找最大公约数;念数字:比如输入-12:fu yi er先判断-的情况之后switch case很好办。以后学会数组之后会有更优解。
求a的连续和
6. 数据类型
- C++和Java更强调类型,对类型的检查更加严格
- JavaScript、Python、PHP不着重类型,甚至不需要事先定义。支持强类型的观点认为明确的类型有助于尽早发现程序中的简单错误;反对强类型的观点认为过于强调类型,迫使程序员面对底层,实现而非事务逻辑
- 类型名称:int,long,double……
- 输入输出时的格式化(占位符):%d,%ld,%lf……
- 所表达的数的范围:char<short<int<float<double
- 内存中占据的大小:1~16个字节
sizeof(int)sizeof(i)int整数类型
sizeof(char)=1;//char1字节(8比特)
sizeof(short)=2;//short2字节
sizeof(int)=4;//由编译器决定,通常代表“1个字”
sizeof(long)=4;//由编译器决定,通常代表“1个字”
sizeof(long long)=8;//long long 8字节

sizeof(int)整数的内部表达
- 像十进制一样,有一种特殊的标志(类似符号)来表示负数(缺陷:计算机做加减法的时候,要像判断十进制的负号一样,我们需要一个东西去控制加号还是减号。不过每次计算机都要特别地去判断这个符号的正负,这样就会比较复杂。)
- 从0000 0000到1111 11111,取中间的数为0,如1000 0000表示0,比他小的是负数,比他大的是正数,各一半(缺陷:所有数都要和这个数做减法来计算其值,会比较复杂)
- 补码思路:本质上来看,(互为相反数的)负数+正数=0。这是提供思路的一种方法。比如我们希望-1+1→0,如何能够做到?如0→0000 0000,1→0000 0001,我们让一个数+1得到0。这个数字选谁?全1的数字1111 1111。因为0000 0001+1111 1111→1 0000 0000多出来的一位(溢出)那一位被丢掉了,相加结果即是00000000。妙啊或者换个角度:-1=0-1=(1)0000 0000-0000 0001→1111 1111(1111 1111被当作纯二进制看待时是255,被当做补码看待时是-1)所以对于-a来说,他的补码就是0-a,实际就是2^n^-a,n是该种类型的位数补码的意义就是拿补码和原码可以加出一个溢出的0。另一个好处是这样我们做计算的时候,不需要调整加减,全部都是加法(+补码就是-原码)。
整数的范围:如何推算整数类型所能表达的数的范围,越界了会怎样?
char c=255;
int i=255;
printf("%d%d",c,i);
-128~-1,0,1~127unsigned char c=255;
255Ul
char c=127;
c++;
unsigned char c=255;
c++;
c=0;
c--;

int a=0,b=1;
while(++a>0);
printf("int数据类型的最大数是:%d\n",a-1);
while((a/=10)!=0)b++;
printf("int数据类型最大的数的数位是:%d",b);
while(++a>0)printf("%d",a-1);while(a!=0);整数的格式化:如何格式化地输入输出整数,如何处理8进制/16进制
char c=012;
int i=0x12;
printf("c=%d,i=%d\n",c,i);
%o%O%x%Xprintf(“c=0%o,i=0x%x\n”,c,i);scanf整数类型的选择
char,short,int,long,long long- 现在CPU字长(CPU和内存之间的通道。如果char可能会从32位中先挑出来8个,可能会花费时间)普遍是32位/64位,一次内存读写、一次计算都是int,选择更短的类型不会更快,甚至可能会更慢
- 现代编译器一般会设计内存对齐,(比如这个东西虽然占据8bit,在内存中仍然占据了一个int。这个事等到结构再讲)所以更短的类型实际在内存中也可能占据一个int的大小。除非在做顶层的硬件,告诉你硬件多大你就要用多大去运算至于Unsigned与否,只是输出的形式不同,内部的计算还是一样的
浮点类型
float,double%.数字f浮点数的范围和精度
float a,b,c;
a=1.345f;
b=1.123f;
c=a+b;
if(c==2.468)printf("相等");
else printf("不相等,c=%.10f,或%f",c,c);
fabs(f1-f2)<1e-12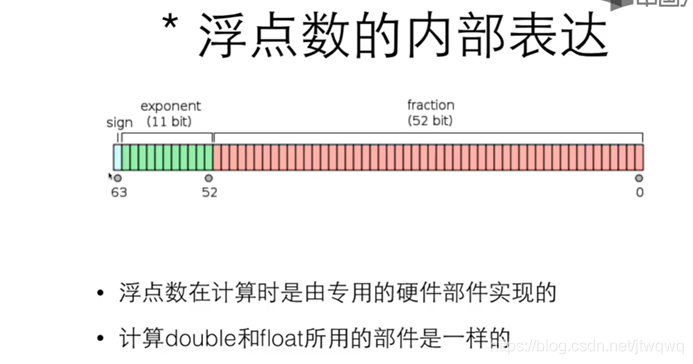
字符类型:char是整数也是字符
'a''1'''scanf("%c",&c);scanf("%d",&c);49=='1'scanf("%d%c",&i,&c);
scanf("%d %c",&i,&c);
int i='Z'-'A';'a'-'A''a'+('A'-'a')
逃逸字符
printf("请分别输入身高的英尺和英寸,""如输入\"5 7\"表示5英尺7英寸:");
printf("123\b\n456\n");
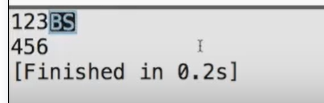
printf("123\t456\n");
printf("12\t456\n");

类型转换
char->short->int->long->long longint->float->double(int)10.2;
(short)32;
(short)32768int i=32768;
short s=(short)i;
printf("%d\n",i);
double a=1.0;
double b=2.0;
int i=(int)a/b;
int i=(int)(a/b);
(double)(a/b);
逻辑类型:表示关系运算和逻辑运算结果的量
bool b=6>5;
逻辑运算:对逻辑量进行与、或、非运算
x>4&&x<6x>=4&&x<=6c>='A'&&c<='Z'!done&&(count>MAX)count>MAXa==6&&b==1a!=6int a=-1;
if(a>0&&a++>1){
printf("OK\n");
}printf("%d\n",a);
条件运算符
cnt=(cnt>20)?cnt-10:cnt+10;
//格式:条件?条件满足时的值:条件不满足时的值
if(cnt>20)cnt-=10;
else cnt+=10;
?i=3+4,5+6;//编译时会提示warning。因为赋值的优先级也要高于逗号,该式子其实是
(i=3+4),(5+6);//右边编译错误,i=7
如果写作i=(3+4,5+6);//编译时同样会warning,因为3+4没有用到;i=11
for(i=0,j=10;i<j; i++,j--)
7. 函数
初见函数
isPrime=1sum+=iint isPrime(int i)
{
int ret=1;
int k;
for(k=2;k<i-1;k++){
if(i%k==0){
ret=0;
break;//有1~i-1间的因数就可以判断i不是素数了,break节约时间
}
}
return ret;
}
printfmainisPrime//闭区间内所有数求和的函数
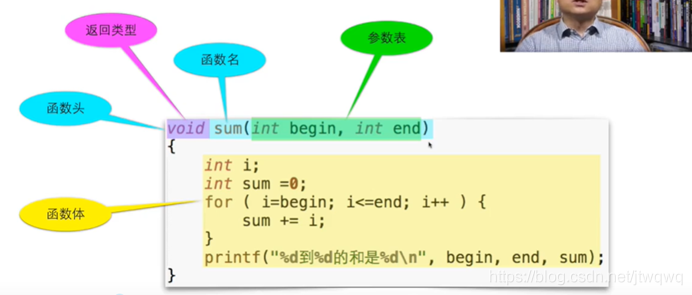
void sum(int begin,int end)
{
int i,sum=0;
for(i=begin;i<=end;i++){
sum+=i;
}
printf("%d到%d的和是%d\n",begin,end,sum);
}
int main()
{
sum(1,10);
return 0;
}
函数的定义和调用
从函数中返回
intreturnreturnreturn;return 一个值; c=函数()voidreturnreturn 函数原型:用来告诉编译器这个函数长什么样
y=f(x)sum()mainerrorvoid sum(int begin,int end);//声明
int main()
{
//略去不表,其中用到了sum(a,b)
}
void sum(int begin,int end)//定义
{
int i,sum=0;
for(i=begin;i<=end;i++){
sum+=i;
}
printf("%d到%d的和是%d\n",begin,end,sum);
}
double max(double a,double b);
Void sum(int ,int)
参数传递:调用哪个函数的时候,是用表达式的值来初始化函数的参数
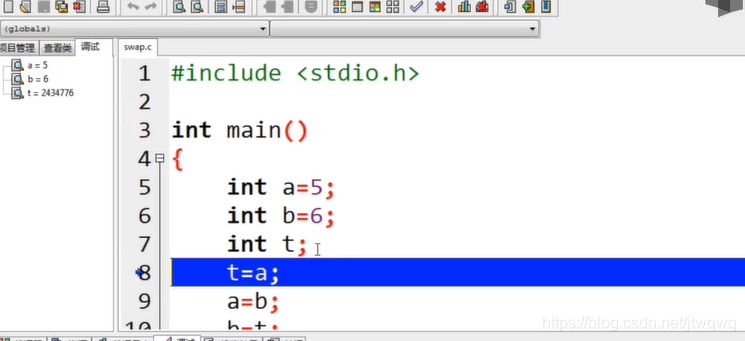
(max(a+b,c)) void swap(int a,int b)//形参
int main()
{
int a=5;
b=6;
swap(a,b);//实参
}
void swap(int a,int b)//形参
{
int t=a;
a=b;
b=t;
}
本地变量:定义在函数内部的变量是本地变量,参数也是本地变量
变量的生存期和作用域
void swap(int a,int b)//形参
int main()
{
int a=5;
b=6;
swap(a,b);//实参
}
void swap(int x,int y)//形参
{
int t=x;
x=y;
y=t;
}
- 本地变量定义在块内。可以是函数的块内,语句的块内,如:if (a<b)int i=10;离开if语句之后未定义使用i编译错误。(没声明)程序运行进入这个块前,其中的变量不存在。离开后就消失了。如果在块里定义了块外已经定义过的变量,就把块外的变量掩盖了;出来之后又回到块外的值。(C语言)但是不能在块里面定义同名变量(多次定义)本地变量不会被默认初始化,不会得到一个初始值。而参数进入函数的时候被初始化了。
函数庶事:一些细节,
main()
的解释
int main(void)return 0;8. 数组
初试数组
int number[100];//定义数组,表示数组可以放100个int
scanf(“%d”,&x);
while(x!=-1){
number[cnt]=x;//对数组中的元素赋值
cnt++;
scanf(“%d”,&x);
}
if(cnt>0){
int i;
double average=sum/cnt;
for(i=0;i<cnt;i++){
if(number[i]>average){//使用数组中的元素
printf("%d ",number[i]);//遍历数组
}
}
}
数组的使用:如何定义和使用数组,数组的下标和下标的范围
int grades[100];
double weight[20];
variable-sized object may not be initialized
segmentation faultnumber[cnt];//用户先输入cnt数组的例子:统计个数
for(int i=0;i<10;i++)count[i]=0;
for(int i=0;i<10;i++)printf(“%d\n”,count[i]);
- 确定数组大小;
- 定义数组;
- 初始化数组;
- 数组参与运算;
- 遍历数组输出。
数组运算
int a[]={2,4,6,7,1,3,5,9}
/*直接用大括号给出数组所有元素的初始值;
不需要给出数组的大小,编译器替你数了。*/
a[13]={2};a[13]={0};int a[0]={[0]=2,[2]=3,6};int a[]={[0]=2,[2]=3,6};数组的大小
b[]=a;遍历数组
数组例子:素数
for(int i=3;i<x;i+=2)
for(int i=3;i<=sqrt(x);i+=2)
int isPrime(int x,int knowsPrimes[],int numberofKnownPrimes)
int main()
{
const int number=100;
int prime[number]={2};
int count=1;
int i=3;
while(count<number){
if(isPrime(i,prime,count)){
prime[count++]=i;
}
i++;
}//prime数组装着所有素数
for(i=0;i<number;i++){
printf("%d",prime[i]);
if((i+1)%5)printf("\t");
else printf("\n");
}
return 0;
}
int isPrime(int x,int knowsPrimes[],int numberofKnownPrimes)
{
int ret=1;
int i;
for(i=0;i<numberofKnownPrimes;i++){
if(x%knownPrimes[i]==0){
ret=0;
break;
}
}
return ret;
}
prime[cnt++]=icnt++while(count<number){
if(isPrime(i,prime,count)){
prime[count++]=i;
}
{
printf("i=%d \tcnt=%d\t",i,count);
int i;
for(i=0;i<number;i++){
printf("%d\t",prime[i]);
}
printf("\n");
}
i++;
}
int i{
int i;
printf("\t\t\t\t");
for(i=0;i<number;i++){
printf("%d\t",i);
}
printf("\n");
}

- 令x=2
- 将2x,3x……直到ax<n的数标记为非素数
- 令x为下一个没有被标记为非素数的数,重复2;直到所有的数都已经被尝试完毕。(从2,3,4,5,6,7,8……删掉2的所有倍数,再删掉3的所有倍数,再删掉5的所有倍数……)
- 先开辟数组prime[n],初始化其所有元素为1,prime[x]=1表示x是素数,prime[x]=0表示x不是素数
- 令x=2
- 如果x是素数,则
for(int i=2;x*i<n;i++)令prime[i*x]=0
- x++,重复3直到x==n,否则结束。
int main()
{
const int maxNumber=25;
int isPrime[maxNumber];
int i,x;
for(i=0;i<maxNumber;i++)
{
isPrime[i]=1;
}
for(x=2;x<maxNumber;i++)
{
if(isPrime[x])
{
for(i=2;i*x<maxNumber;i++) isPrime[i*x]=0;
}
}
printf("\n");
return 0;
}
二维数组
int a[3][5];
int a[][5]={
{0,1,2,3,4},
{2,3,4,5,6},
};
a[i][j]a[i,j]a[j]const int size = 3;
int board[size][size];
int i,j;
int num0fX;//X是一方
int num0fO;//O是一方
int result=-1;//-1:平局,1:X方赢,0:O方赢
//读入矩阵
for(i=0;i<size;i++){
for(j=0;j<size;j++){
scanf("%d",&board[i][j]);
}
}
//检查行
for(i=0;i<size&&result==-1;i++){
num0fO=num0fX=0;
for(j=0;j<size;j++){
if(board[i][j]==1)num0fX++;
else num0fO++;
}
if(num0fO==size)result=0;//O方赢
else if(num0fX==size)result=1;//X方赢
}
board[i][i]board[i][2-i]9. 指针
取地址运算:&运算符取得变量的地址
printf("0x%x",&i);//%x是以16进制输出;&i是一个地址
printf("%p",&i);
p=(int)&i;
printf("0x%x",p);
%lusizeof(int)sizeof(&i)%p&(a+b)&(a++)&(++a)int a;
int b;
printf%p&aa&a[0]指针 就是记录地址的变量
scanf*int i;
int *p=&i;//(p指向了i)*p理解为指向p指针地址所存在的值=i的地址。
int* p,q;
int *p,q;
*pint **p*qvoid f(int*p);
int main()
{
int i=6;
printf("&i=%p\n",&i);
f(&i);
return 0;
}
void f(int *p)
{
printf("p=%p\n",p);
}//该函数在被调用的时候得到了某个变量的地址
//我们调用的时候可以这么写:
int i=0;f(&i);
*p=26;*&yptr->*(&yptr)->*(yptr的地址)->得到那个地址上的变量,即yptr&*yptr->&(*yptr)->&(y)->得到y的地址,即yptrint i; scanf("%d",i);指针的用处
- 现在在函数里利用指针就能使交换两个变量成为可能。可以直接对该地址的变量改变值。和之前的swap函数(传递的是两个值)不一样。
void swap(int *pa,int *pb)
{
int t=*pa;
*pa=*pb;
*pb=t;
}
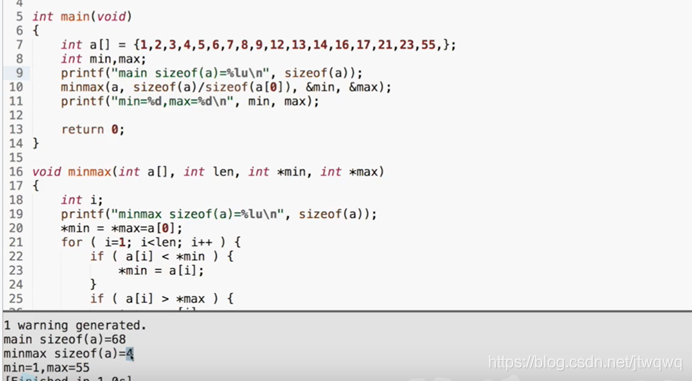
写一个求最大值最小值的函数,要返回最大值和最小值两个值。
int a[10],min,max;
minmax(a,sizeof(a)/sizeof(a[0]),&min,&max);
void minmax(int a[],int len,int *min,int *max)
/*
sizeof(a)/sizeof(a[0])是数组元素个数。
函数内部:一个len次的循环来比较每一个a[i]和*min,*max大小,然后令*min,*max不断改变主函数中min和max的值
- 函数要返回运算的状态,结果通过指针返回。
给你两个数做除法,当分母等于0时返回0,分母不等于0的时候要返回1和除法的结果。
int divide(int a,int b,int *result)
{
int ret=1;
if(b==0)ret=0;
else{
*result=a/b;
}
return ret;
}
如果返回1再输出a/b结果。
int *p=12;指针与数组:为什么数组函数之后的sizeof不对了
int a[]*aint sum(int *ar,int n);
int sum(int *,int);
int sun(int ar[],int n);
int sum(int [],int);
a==&a[0]P[0]*Ppritnf("min=%d,max=%d\n",min,max);
int *p=&min;
printf("*p=%d\n",*p);
printf("p[0]=%d\n",p[0]);//得到的是一样的结果。
*a=a[0]int b[]->int * const b;b=a;指针与const:指针本身和所指的变量都可能const(本节只适用于c99)
int * const q=&I;//q是const
*q=26//可以改变i的值
q++//error
const int *p=&I;
*p=26;//error!(*p)是const,不能通过p做赋值。
I=26;//可以直接改i
P=&j;//改变p指向的地址,可以
int I;
const int*p1=&I;
int const*p2=&I;
int *const p3=&I;
void f(const int*x);
int a=15;
f(&a);//可以
const int b=a;
f(&b);//可以
b=a+1;//不行!
Const int a[]={1,2,3,4,5,6};int sum(const int a[],int length);指针运算
char a[]={0,1,2,3,4,5,6}
char *p=ac;
printf("p的地址是%p\n",p);
printf("p+1的地址是%p\n",p+1);
charintsizeof(char)=1,sizeof(int)=4*(p+1)*p+1**p++*p=ac;
while(*p!=-1)
{
printf("%d\n",*p++);
}
*p++>,>=,<,<=,!=void*char*int *p=&i;void*q=(void*)p;
动态内存分配
int *a=(int*)malloc(n*sizeof(int));
#include<stdlib.h>
{
int n;
int *a;
scanf("%d",&n);
a=(int*)malloc(n*sizeof(int));
//用完之后
free a;
}
void *p=0;free(p)10. 字符串
char word[]={'H','e','l','l','o','!'};
char *str="Hello";//一个指针指向了一个字符数组
char word[]="Hello";//字符数组,结尾0
char line[10]="Hello";//字符数组,结尾0
printf" "" "printf("123456789"
"10111213");
printf("123456789\
10111213");
字符串变量
char *s="Hello";
s[0]='B';//尝试把H替换为B,然后输出s[0]
int i=0;
char *s="Hello";
char*s1="Hello";//两个一样的字符串变量
printf("i的地址是%p\n",&i);
printf("s的地址是%p\n",s);
printf("s1的地址是%p\n",s1);
const char*s;constchar s[]="Hello!";
- 字符串有确定的地址;
- 作为本地变量,空间会自动被回收。
- 只读的,不可写的字符串
- 处理函数的参数(前面知道如果数组作为指针,函数的参数实际上和指针是一样的);
- 动态分配空间malloc。
char*char*char*字符串输入输出
char *t="title";
char *s;
s=t;
%schar string[8];
scanf("%s",string);
printf("%s",string);
scanf()scanf("%s",str1);
scanf("%s",str2);
printf("%s%s",str1,str2);
scanf()char str1[8],str2[8];
scanf("%s",str1);
scanf("%s",str2);
scanf("%7s%7s",str,str1);char*char zero[100]="";
char zero[]="";字符串数组,以及程序参数
char **achar a[][]char a[][10]={
"hello",
"world"
};//每个字符串长度不要超过n,即10
char *a[]int main(int argc,char const*argv[])for(i=0;i<argc;i++){
printf("%d:%s\n",i,argv[i]);
}
./a.out./a.out 1230:./a.out 1:123./a.out 123 asd asd asd asd./a.outln -s a.out myls -l my./my 123./my./a.out字符、字符串操作
单字符输入输出
int ch;
while((ch=getchar())!=EOF){
putchar(ch);
}
printf("EOF\n");//这样来看读入什么会EOF
return 0;
字符串函数strlen
string.hstrlenstrcmpstrcpystrcatstrchrstrstrstrlen(const char*s)char line[]="Hello";
printf("%lu\n%lu",strlen(line),sizeof(line));
H,e,l,l,o,\0int cnt=0;
while(s[cnt]!='\0'){
cnt++;
}
return cnt;
字符串数组strcmp
int strcmp(const char*s1,const char*s2)s1[]="abc";
s2[]="bbc";
strcmps1[]="abc";
s2[]="Abc";
'a'-'A's1[]="abc";
s2[]="abc ";//多了个空格
\0-' 'while(s1[idx]!='\0'&&s1[idx]==s2[idx])//当出现不相等的字符或者字符串到了末尾时,返回差值
idx++;
return s1[idx]-s2[idx];
*s1==*s2
s1++;
s2++;
return *s1-*s2;
字符串函数strcpy
char*strcpy(char* restrict dst,char* restrict src);H E L L O \0空 空 空 H E L L O \0char *dst=(char*)malloc(strlen(src)+1);//不包含结尾的\0,所以+1
strcpy (dst,src);
char *mycpy(char*dst,const char*src)
{
int idx=0;
while(src[idx]!='\0')
{
dst[idx]=src[idx];
idx++;
}
dst[idx+1]='\0';
return dst;
char *ret=dst;
while(*src!='\0')
{
*dst=*src;
*dst++;
*src++;
}
*dst='\0';
return ret;
while(*src)*dst++ = *src++;
*dst++ = *src++;while(*dst++ = *src++);
字符串函数strcat
char*strcat(char* restrict s1,const char* restrict s2);strncpystrncatchar*strncpy(char* restrict s1,const char* restrict s2,size_t n);
char*strncat(char* restrict s1,const char* restrict s2,size_t n);
char*strncat(const char* s1,const char* s2,size_t n);
字符串搜索函数
char* strchr(const char* s,int c);char* strrchr(const char* s,int c);//从右边开始找char *s="hello";
char *p=strchr(s,'l');
printf("%s",p);
p=strchr(p+1,'l');
char *t=(char*)malloc(strlen(p)+1);
strcpy(t,p);
free(t);
char c=*p;
*p='\0';//把l的位置改成'\0'
char *t=(char*)malloc(strlen(s)+1);
strcpy(t,s);//只拷贝了第一个l前面的部分。
char* strchr(const char* s1,const char*s2);char* strcasestr(const char* s1,const char*s2);11. 枚举
const int red=0;
const int yellow=1;
const int green=2;
int main()
{
int color=-1;
char *colorname=NULL;
printf("请输入你喜欢的颜色的代码");
scanf("%d",&color);
switch(color){
case red:colorname="red";break;
case yellow:colorname="yellow";break;
case green:colorname="green";break;
default:colorname="unknown";break;
}
printf("%s",colorname);
return 0;
enum COLOR{RED,YELLOW,GREEN};
int main(){
int color=-1;
char *colorname=NULL;
printf("输入你喜欢的颜色代码:");
scanf("%d",&color);
switch(color){
case RED:colorname="red";break;//在case处就可以直接使用RED YELLOW和GREEN来取代0,1,2
case YELLOW:colorname="yellow";break;
case GREEN:colorname="green";break;
default:colorname="unknown";break;
}
printf("你喜欢的颜色是%s\n",colorname);
return 0;
}
enum 枚举类型名{名字0,名字1……名字n};enum color {red,yellow,green};
void f(enum color c);
int main()
{
enum color t= red;
scanf("%d",&t);
f(t);
return 0;
}
void f(enum color c)
{
printf("%d\n",c);
}
enum COLOR{RED,YELLOW,GREEN,numcolors};//结尾的numcolors表示数组的结尾,同时也可以表示enum中元素的个数。
int main()
{
int color=-1;
char *ColorNames[numcolors]={
"red","yellow","green",
};
char *colorname=NULL;
printf("请输入你喜欢的颜色的代码");
scanf("%d",&color);
if(color>=0&&color<numcolors) colorname=ColorNames[color];
else colorname="unknown";
printf("你喜欢的颜色是%s",colorname);
return 0;
}
enum color{red=1,yellow,green=5};enum color c=0;结构类型
int main()
{
struct date{
int day;
int month;
int year;
};//声明时,结尾有个分号!!
struct date today;//像枚举一样不要忘记开头,struct
today.day=12;
today.month=3;
today.year=2021;
printf("Today's date is %i-%i-%i.",today.year,today.month,today.day);
return 0;
}
struct{
int x;
int y;
}p1,p2;
struct point{
int x;
int y;
}p1,p2;
struct date={12,3,2021};//注意顺序
struct thismonth={.month=3,.year=2021};//剩下没有被赋值的部分都是0,和数组一样
.结构名字.成员名字p1=(struct point){5,10};
p1=p2;
struct date today,day;
today=(struct date){12,3,2021};
day=today;
struct date *pdate=&today;
结构与函数
int numberofdays(struct date d)
&date.month.&struct point p={0,0};
gtestruct(p);
void getstruct(struct point p){
scanf("%d",&p.x);
scanf("%d",&p.y);
}
struct point getstruct(void)
{
struct point p;
scanf("%d",&p.x);
scanf("%d",&p.y);
return p;
}
//main函数中:y=getstruct();
struct date myday;
struct date *p=&myday;
(*p).month=12;//正常应该这样写
p->month=12;//也可以简写成这样
#include<stdio.h>
struct point{
int x;
int y;
}p;
struct point *getstruct(struct point *p);
void print(const struct point *p);
int main()
{
struct point p={0,0};
print(getstruct(&p));
return 0;
}
struct point *getstruct(struct point *p)
{
scanf("%d",&p->x);
scanf("%d",&p->y);
return p;
}//像这样传入一个参数,对其做处理后再返回该参数的函数,可以直接套用在其他函数中。
void print(const struct point *p)//const
{
printf("%d %d",p->x,p->y);
}
结构中的结构
struct date dates[100];
struct date dates[]={
{3,21,2021},{3,22,2021}
};
printf("%.2i",dates[1].month);//不知道%.2i什么意思
struct point{
int x;
int y;
}
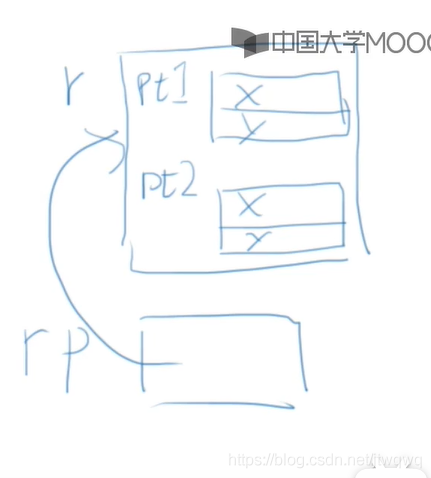
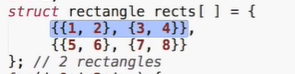
struct rectangle{
struct point pt1;
struct point pt2;
}
//如果有这样的定义:
struct rectangle r;
/*则可以有:
r.pt1.x;
r.pt1.y;
r.pt2.x;
r.pt2.y;
*/
//如果有这样的定义:
struct rectangle *rp;
rp=&r;
//那么下面的四种形式是等价的
r.pt1.x
rp->pt1.x
(r.pt1).x
(r->pt1).x
//但是不能写r->pt1->x,因为pt1不是指针而是结构。

类型定义
typedeftypedef int length;length a,b;length a[10];typedef struct ADate{
int month;
int day;
int year;
}Date;
Date a={3,24,2021};
typedef *char[10] String;//string是十个字符串的数组的类型。
联合
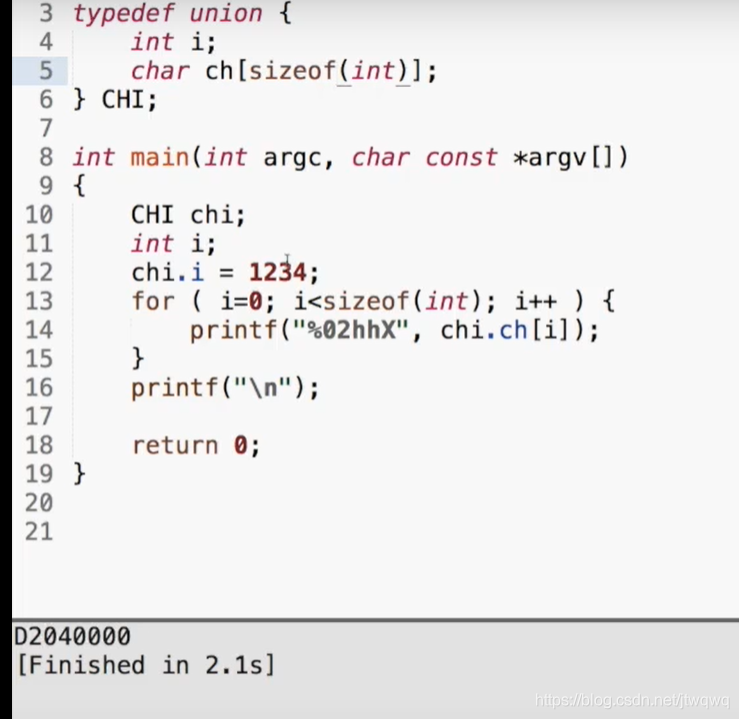
unit xxx{
int a;
char b;
}xxx1,xxx2;
xxx1.a=1;
xxx2.b='c';
12. 全局变量
全局变量:定义在函数之外的变量,全局的生存期和作用域
int gAll=12;
int main()
{
printf("in %s, gAll is %d",__func__,gAll);//__func__是输出当前函数名称
return 0;
}
int gAll=12; int g2=gAll;const int gAll=12; int g2=gAll;静态本地变量:能在函数结束后继续保持原值的本地变量
f(){
static int a=1;
a+=2;
}
后记:返回指针的函数,使用全局变量的贴士
int *f();
void g();
int main()
{
int *p=f();
printf("*p=%d",*p);
g();
printf("*p=%d",*p);
return 0;
}
int *f()
{
int i=12;
return &i;
}
void g()
{
int k=24;
printf("k=%d",k);
return 0;
}
宏定义
#define PI 3.14159
gcc xxx.c --save-temps
ls-l
xxx. c xxx. ixxx. sxxx. oxxx. outtail xxx.c;
tail xxx.i;
#define FORMAT "%f\n"printf(FORMAT,2*PI);#define 单词 值#define prt printf("123");\
printf("456");
#define -DEBUG__LINE__//行号
__FILE__//文件名
__DATE__//编译时日期
__TIME__//编译时时间
__STDC__
带参数的宏
#define cube (x)((x)*(x)*(x))printf("%d\n",cube(5));//输入tail 文件名,输出((5)*(5)*(5))
RADTODEG(x) (x*57.29578);
RADTODEG(x) (x)*57.29578;
RADTODEG(x) ((x)*57.29578);
#define MIN(a,b) ((a)>(b)? (b):(a))13. 文件和位运算
多个源代码文件
头文件
int max(int a,int b);int max(int a,int b);#include"max.h"
声明
extern int gAll;int x;extern int x;#ifndef __MAX_H__
#define __MAX_H__//如果没有定义过max.h则定义max.h
//中间是声明
#endif
格式化输入输出
%[flags][width][.prec][hIL]type文件输入输出

FILE* fp=fopen("file","r");//file是文件名,r表示读
if(fp){//如果没打开,会返回NULL
fscanf(fp,...);//读文件。省略号的东西和正常的scanf一样了。后面还可以printf
fclose(fp);
}else{}//无法打开的反馈。如:输出 无法打开文件
二进制文件
- 有配置(比如窗口大小、字体颜色)UNIX用文本文件就能编辑,Windows是用一个大文件:注册表编辑。
- 数据:保存数据,如学生成绩。稍微大一些的数据都放数据库那了。
- 媒体:如图片音频,这些不能是文本文件,只能是二进制文件。其实现在程序通过第三方库来读写文件,很少直接读写二进制文件了。对二进制的读写

- 第一个参数是指针,要读写的内存;第二个参数是那块内存(一个结构)的大小;第三个参数是有几个这样的内存,第四个参数是文件指针。返回成功读写的字节数。因为二进制文件的读写一半是通过对一个结构变量的操作来进行的,所以nitem就是用来说明这次读写了几个结构变量。这里老师做了一个非常有意思的东西,建议去看看(我懒了)fwrite可以把数据以二进制形式写到文件中,fread类似。定位:找出现在处在文件中的位置,或跳到指定位置。
long ftell(FILE *stream);
int fseek(FILE *stream, long offset, int whence);
/*whence:SEEK_SET 从头开始
SEEK_CUR 从当前位置开始
SEEK_END 从末尾开始*/
fseek(fp, 0L, SEEK_END);long size=ftell(fp);按位运算
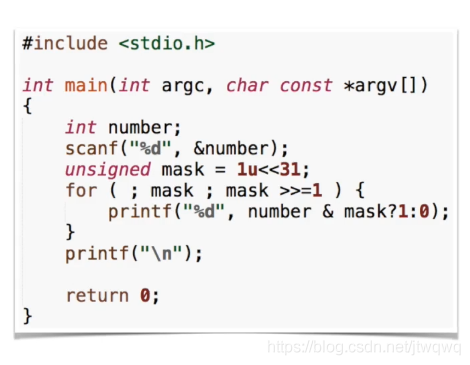
- 让某一位或某些位=0,如x & 0xFE(1111 1110) 会让最后一位变为0
- 取某个数中的某一段:如x & 0xFF (在32位int中是 0000 0000 0000 0000 0000 0000 1111 1111)这样只会留下最后8位按位或应用:
- 使得某一位/某几位变为1: x | 0x01
- 把两个数拼起来: 0x00FF | 0xFF00
移位运算
位运算例子

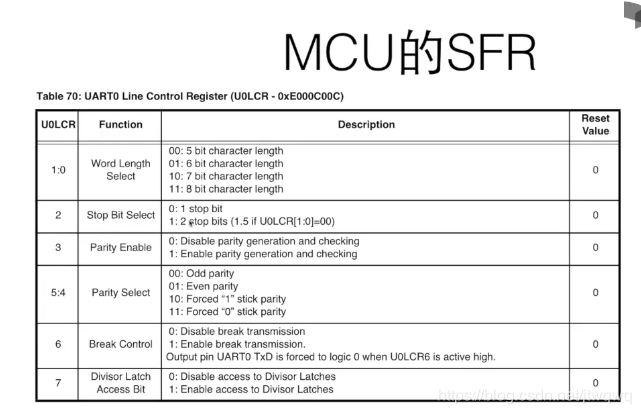

位段


14. 可变数组

Array array_create(int init_size){
Array a;
a.size=init_size;
a.array=(int*)malloc(sizeof(int)*init_size);
return a;
}
void array_free(Array *a)
{
free(a->array);
//保险起见,令a->size=0, a->array=NULL
}
可变数组的数据访问
int *array_at(Array *a, int index)
{
return &(a->array[index]);
}
*array_at(&a,0)=10**void array_get(const Array *a,int index)
{
return a->array[index];
}
void array_set(Array *a,int index,int value)
{
a->array[index]=value;
}
可变数组自动增长
void array_inflate(Array *a, int more_size)
{
int *p=(int*)malloc(sizeof(int)*(a->size+more_size);
int i;
for(i=0;i<a->size;i++)p[i]==a->array[i];//把老空间里的东西放到新空间里去。
free(a->array);
a->array=p;
a->size+=more_size;
}
array_inflate(a,(index/block_size+1)*block_size-a->size);while(number!=-1)
{
scanf("%d",&number);
*array_at(&a,cnt++)=number;
}
可变数组的缺陷
- 每次都要拷贝,很花时间
- 每次都是在之前的内存结尾申请空间,不断往后排,所以最后其实我们不需要那么多内存空间,但我们的内存空间不够了。
- 如果我们每次都只申请一块block大的内存,把他们链起来,不需要拷贝了节约时间,也可以充分利用给内存的每一块。
15. 链表

typedef struct _node{
int value;
struct _node *next;
}Node;
do{
scanf("%d",&number);
if(number!=-1)//add to linked-list
}while(number!=-1);
Node *head=NULL;
Node *p=(Node*)malloc(sizeof(Node));
p->value=number;
p->next=NULL;
//find the last, attach
Node *last=head;
if(last)//判断head是否为空
{
while(last->next)last=last->next;
last->next=p;
}else head=p;//即:p就是第一个结点
链表的函数
void add(Node *head,int number);last=head;
while(last->next)last=last->next;//找到结尾last结点
last->next=p;

&list链表的搜索
node *p;
for(p=list.head;p;p=p->next)printf("%d\t",p->value);//遍历
for(p=list.head;p;p=p->next)
{
if(p->value==number)printf("找到了!");
}
链表的删除


free(p)链表的清除
free(p),p=qfor(p=head;p;p=q)
{
q=p->next;
free(p);
}
完结
边栏推荐
- LeetCode每日一练 —— 20. 有效的括号
- LayaBox---TypeScript---Symbols
- 如何封装微信小程序的 wx.request() 请求
- 365天挑战LeetCode1000题——Day 047 设计循环队列 循环队列
- Unknown content monitoring
- How to choose a truly "easy-to-use, high-performance" remote control software
- 行为型模式-策略模式
- 太帅了!我用炫酷大屏展示爬虫数据!
- LayaBox---TypeScript---Decorator
- 阿里CTO程立:阿里巴巴开源的历程、理念和实践
猜你喜欢

牛客刷题——剑指offer(第三期)
保姆级教程:写出自己的移动应用和小程序(篇二)
Rear tube implements breadcrumb function
MSYS2 QtCreator Clangd code analysis can not find mm_malloc.h problem remedy

深度学习100例 —— 卷积神经网络(CNN)实现mnist手写数字识别

如何在技术上来保证LED显示屏质量?

The heavyweights are coming!Spoilers for the highlights of the Alibaba Cloud Life Science and Intelligent Computing Summit
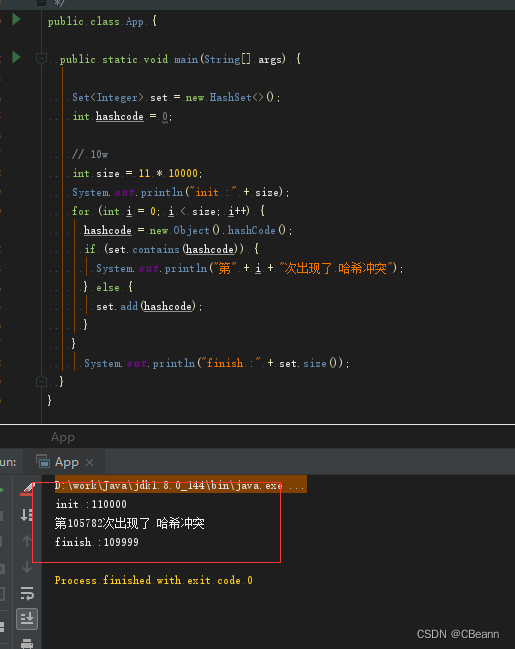
多大数量级会出现哈希碰撞

2022年8月初济南某外包公司全栈开发面试题整理
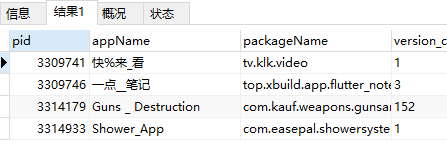
MySql模糊查询大全
随机推荐
LayaBox---TypeScript---命名空间和模块
众城优选系统开发功能
idea常用插件
21天学习挑战赛--第一天打卡(屏幕密度)
Rear tube implements breadcrumb function
3年测试在职,月薪还不足2w,最近被裁员,用亲身经历给大家提个醒...
WPF 截图控件之文字(七)「仿微信」
【面向校招】Golang面试题合集
LayaBox---TypeScript---Namespaces and modules
How to encapsulate the wx.request() request of WeChat applet
mysql清除binlog日志文件
超赞!发现一个APP逆向神器!
LeetCode每日一练 —— 20. 有效的括号
Spearman's correlation coefficient
从零开始Blazor Server(5)--权限验证
只问耕耘,不问收获,其实收获却在耕耘中
鸿星尔克再捐一个亿
LayaBox - TypeScript - merge statement
软件工程国考总结——选择题
LayaBox---TypeScript---Symbols