当前位置:网站首页>A priori box (Anchor) in target detection
A priori box (Anchor) in target detection
2022-08-04 07:03:00 【hot-blooded chef】
什么是先验框?
Friends who have learned about the target detection algorithm must know the a priori frame(Anchor)的概念,So what is a prior box,Why have a priori box?若要解释这个问题,First we need to understand the principle of bounding box regression.
bounding box regression
如图所示,图中的狗子是我们要检测的目标,也即是红框(Ground Truth)圈住的物体.在通常情况下模型预测到的框是绿色框.但是由于绿色框不准,相当于没有正确的检测出狗子.所以我们希望有一个方法对绿色框进行调整,使得绿色框更接近红色框.

对于预测框我们一般使用 ( x , y , w , h ) (x,y,w,h) (x,y,w,h)来表示,其中 x , y x, y x,y代表预测框的中心点, w , h w,h w,h代表预测框的宽高.
现在设红框的坐标信息为:
G = [ G x , G y , G w , G h ] G = [G_x,G_y,G_w,G_h] G=[Gx,Gy,Gw,Gh]
绿框的坐标信息为:
G ′ = [ G x ′ , G y ′ , G w ′ , G h ′ ] G' = [G'_x,G'_y,G'_w,G'_h] G′=[Gx′,Gy′,Gw′,Gh′]
那么要经过怎么样的调整才能使得绿框变成红框呢?目标检测中的做法是:平移+缩放.
- 将预测框的中心点平移到与真实框的中心重合的位置.
- 再将预测框的高和宽缩小或放大到与真实框一样的长度.
众所周知,平移至重合位置需要两个偏移量 b x , b y b_x,b_y bx,by,缩放也需要两个系数 s w , s h s_w,s_h sw,sh
那么显然这个偏移量与缩放系数的大小与真实框实际的偏差有很大关联.若原本预测框与真实框就很接近,需要偏移和缩放的大小也就少一点,反之亦然.所以我们肯定希望预测框与真实框越接近越好.
但是真实的情况往往是不同的,数据中的真实框都是各种各样的,有的可能非常大,有的可能非常偏,数据分布非常不统一,而预测框就更不用说了.这就导致了学习到的偏移量和缩放系数变化大,模型难收敛的问题.所以为了解决这个问题,我们引入了Anchor机制.
Anchor
虽然我们不能约束预测框的位置,但是可以统一真实框的位置.我们将假设我们将所有真实框的长宽都设为128,把这个长宽都为128的框叫做先验框(Anchor),也就是图中蓝色的框.Then the coefficients learned by the model will be偏向这个先验框.那么有人就会问了,那这个预测框要如何转为真实框?很简单,也是将它进行平移+变换的操作变回真实框.
But only take128One scale to represent all ground-truth boxes is certainly not appropriate.所以在Faster RCNN中引入了9A priori box of various scales: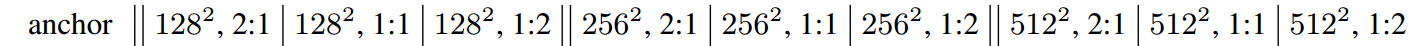
而加入了多个尺度之后,真实框如何选择合适的anchor又成了一个问题.一般我们选择IOU最大的作为先验框.
而这种固定尺度的anchor也会有缺陷,不能很好的适应所有数据集.例如coco数据集中就有很多小目标.所以后面也有YOLOv3这一类的目标检测模型使用k-means算法Filter all true boxes.选出最有代表性的几个尺度作为anchor.
在什么阶段进行先验框匹配?
一般来说,我们都会在经过骨干网络处理的特征层上进行先验框匹配.因为如果在一开始的图片上就进行先验框匹配,那就会有很多先验框,这样计算量就会激增.以Faster RCNN为例,输入图片是600x600的大小,And the feature layer is38x38的大小.If a prior box matching is performed on the input image,that produces 600 ∗ 600 ∗ 9 = 3 , 240 , 000 600 * 600*9 = 3,240,000 600∗600∗9=3,240,000个先验框,And on the feature layer it is 38 ∗ 38 ∗ 9 = 12996 38 * 38 *9 = 12996 38∗38∗9=12996个先验框.下图是Faster RCNNA demonstration of the prior box at a point in the feature layer(Other points are not drawn).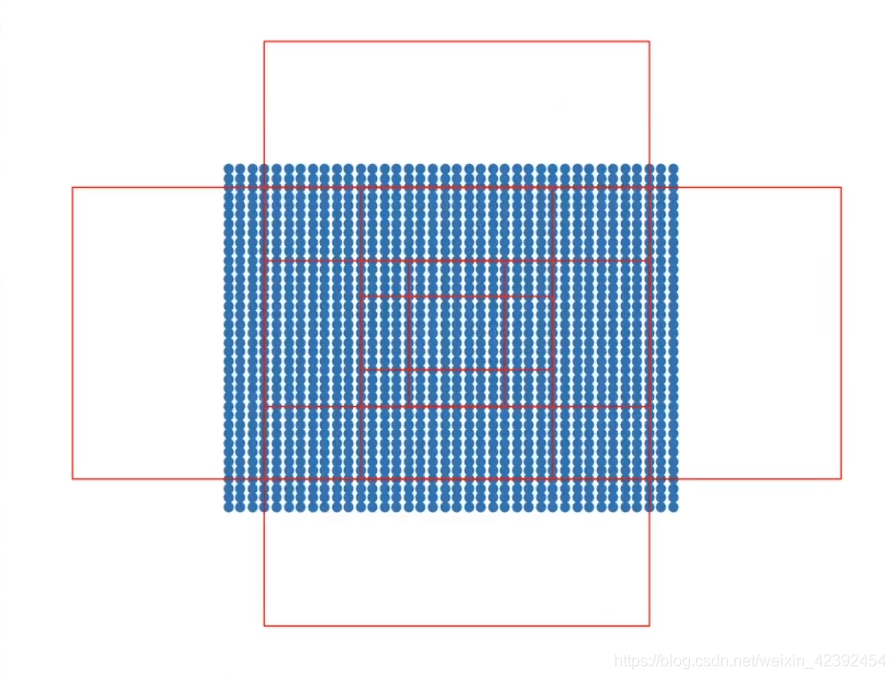
Of course for object detection,There may be feature layers of different sizes within a model,They are used to detect objects of different scales,The number of its center points is not the same.如YOLOv3There are a series of target detection networks52x52,26x26,13x13的特征层.
本文章只是对Anchor机制的一些理解,若有错误之处,敬请指正.
边栏推荐
猜你喜欢
数据库文档生成工具V1.0
JUC锁框架——基于AQS的实现,从ReentrantLock认识独占和共享
电脑软件:推荐一款磁盘空间分析工具——WizTree
【HIT-SC-MEMO7】哈工大2022软件构造 复习笔记7
CMDB 阿里云部分实现
Interpretation of EfficientNet: Composite scaling method of neural network (based on tf-Kersa reproduction code)
Unity Day01
FCN——语义分割的开山鼻祖(基于tf-Kersa复现代码)

用chrome dev tools 强制js注入
EfficientNet解读:神经网络的复合缩放方法(基于tf-Kersa复现代码)
随机推荐
网络端口大全
以太网 ARP
新冠病毒和网络安全的异同及思考
IE8 打开速度慢的解决办法
普通用户 远程桌面连接 服务器 Remote Desktop Service
Uos统信系统 Postfix-smtps & Dovecot-imaps
Unity Day03
天鹰优化的半监督拉普拉斯深度核极限学习机用于分类
安全漏洞是如何被发现的?
golang 坐标格式 转换 GCJ02ToWGS84
Multi-threaded sequential output
如何在Excel 里倒序排列表格数据 || csv表格倒序排列数据
QT 出现多冲定义问题
Uos统信系统 SSH
网络安全学习的三大不可取之处
bitnami/mongodb-sharded在AWS EKS扩展shard失败解决
Logical Address & Physical Address
YOLOv3详解:从零开始搭建YOLOv3网络
Nacos 原理
DenseNet详解及Keras复现代码