当前位置:网站首页>【HIT-SC-LAB2】哈工大2022软件构造 实验2
【HIT-SC-LAB2】哈工大2022软件构造 实验2
2022-08-04 05:32:00 【XMeow】

2022年春季学期
计算学部《软件构造》课程
Lab 2实验报告
姓名 | XMEOW |
学号 | 我不道啊 |
班号 | 应该是20啥的 |
电子邮件 | 222呃呃@qq.com |
手机号码 | 不告诉你 |
3.1.1 Get the code and prepare Git repository· 1
3.1.2 Problem 1: Test Graph <String>· 1
3.1.3 Problem 2: Implement Graph <String>· 1
3.1.3.1 Implement ConcreteEdgesGraph· 2
3.1.3.2 Implement ConcreteVerticesGraph· 2
3.1.4 Problem 3: Implement generic Graph<L>· 2
3.1.4.1 Make the implementations generic· 2
3.1.4.2 Implement Graph.empty()· 2
3.1.5 Problem 4: Poetic walks· 2
3.1.5.2 Implement GraphPoet· 2
本次实验训练抽象数据类型(ADT)的设计、规约、测试,并使用面向对象
编程(OOP)技术实现 ADT。具体来说:
针对给定的应用问题,从问题描述中识别所需的 ADT;
设计 ADT 规约(pre-condition、post-condition)并评估规约的质量;
根据 ADT 的规约设计测试用例;
ADT 的泛型化;
根据规约设计 ADT 的多种不同的实现;针对每种实现,设计其表示
(representation)、表示不变性(rep invariant)、抽象过程(abstraction
function)
使用 OOP 实现 ADT,并判定表示不变性是否违反、各实现是否存在表
示泄露(rep exposure);
测试 ADT 的实现并评估测试的覆盖度;
使用 ADT 及其实现,为应用问题开发程序;
在测试代码中,能够写出 testing strategy 并据此设计测试用例。
本次实验需要特殊配置的只有EclEmma,一般来说EclEmma会随着Eclipse附件下载,这一点可以在Eclipse Marketplace中验证。
https://github.com/ComputerScienceHIT/HIT-Lab2-120L020731
本任务基于有向图来达到“写诗”的目的。
图有两种实现,边图和点图,它们都继承了Graph接口。
在图的存储上,运用了泛型。
实现图的基本方法,如add/set/remove/targets/sources/vertices
要实现写诗,即实现GraphPoet类,需要判断两个相邻单词之间是否有桥接词。
git clone https://github.com/rainywang/Spring2020_HITCS_SC_Lab2.git
使用git bash来clone项目

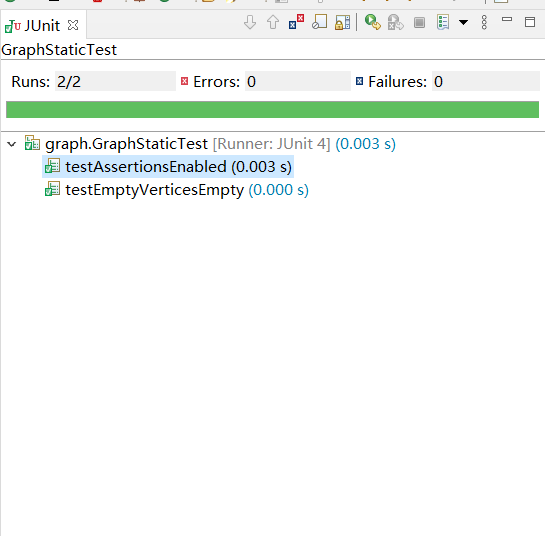
- Problem 1: Test Graph <String>
测试用静态方法生成String型的Graph
- Problem 2: Implement Graph <String>
- Implement ConcreteEdgesGraph
- Problem 2: Implement Graph <String>
首先,我们需要填写边图的元素“Edge”类,它包含三个变量 source target 以及weight
//fields
privatefinal String source, target;
privatefinalint weight;
根据edge类的约束条件,weight应该为非负整数,source和target不能够为同一个点。
//checkRep
privatevoidcheckRep(){
assert(weight >0&&!source.equals(target));
}
类内包含的几个方法,写出基本的取值方法和比较相同的sameEdge方法就行,没什么特别。
实现完Edge之后 只需要依次添加ConcreteEdgesGraph中的函数就可以了。
//constructor
ConcreteEdgesGraph(){
}
checkRep中需要检测图中的所有顶点不为空,边不为空
//checkRep
privatevoidcheckRep(){
for(String vertex : vertices)
assert(vertex !=null);
for(Edge edge : edges)
assert(edge !=null);
}
对于Graph的操作,这里着重讲解几个比较难写的函数。
set :设置一条新的边,它包含三个参数:source target weight,其中source不能等于target,因为一条边的两端点不能是同一点。同时,weight不能为负,为0时代表删除这条边。
@Override
publicintset(String source, String target,int weight){
if(weight <0)
thrownew RuntimeException("Negative weight");
if(!vertices.contains(source)||!vertices.contains(target)){
if(!vertices.contains(source))
this.add(source);
if(!vertices.contains(target))
this.add(target);
}
if(source.equals(target))//出入点相同,无法创建新的边
return0;
//遍历L邻接的所有边,找到相同的边
Iterator<Edge> it = edges.iterator();
while(it.hasNext()){
Edge edge = it.next();
if(edge.sameEdge(source, target)){
int lastEdgeWeight = edge.weight();
it.remove();
if(weight >0){
Edge newEdge =new Edge (source, target, weight);
edges.add(newEdge);
}
elseif(weight ==0)
return0;//若weight == 0 则不添加新的边
checkRep();
return lastEdgeWeight;
}
}
//建立新的边
Edge newEdge =new Edge (source, target, weight);
edges.add(newEdge);
checkRep();
return0;
}
sources/targets 锁定一点,查询所有边的另外一个端点,写一个遍历就可以找到。
@Override
public Map<String, Integer>sources(String target){
Map<String, Integer> sources =new HashMap<>();
for(Edge edge : edges){
if(target.equals(edge.target())){
sources.put((L) edge.source(), edge.weight());
}
}
checkRep();
return sources;
}
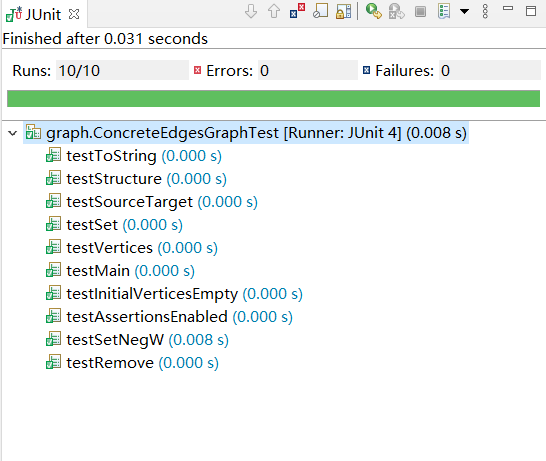
测试样例全部通过
- Implement ConcreteVerticesGraph
VerticesGraph和EdgesGraph的区别在于存储图的类不同。VerticesGraph的数据存储在节点内,节点包括这个点,以及与其邻接的所有边。
// fields
privatefinal String ThisVertex;
privatefinal Map<String, Integer> inEdges =new HashMap<>();
privatefinal Map<String, Integer> outEdges =new HashMap<>();
checkRep函数需要保证每条边的权值都为正整数
// checkRep
privatevoidcheckRep(){
for(String key : inEdges.keySet())
assert(inEdges.get(key)>0);
for(String key : outEdges.keySet())
assert(outEdges.get(key)>0);
}
方法部分需要特别提到的是这里的取值方法和EdgesGraph中的targets/sources类似
public Map<String, Integer>sources(){
Map<String, Integer> sources =new HashMap<>();
sources.putAll(inEdges);
return sources;
}
而在这里set和remove的方法被写入了单元类中,总体思路相同,先检测输入合理性,再建立新边,在建立后checkRep();
publicintsetInEdge(String source,int weight){
if(weight <=0)
return0;
Iterator it =inEdges.keySet().iterator();
while(it.hasNext()){
L key = it.next();
if(key.equals(source)){
int lastEdgeWeight = inEdges.get(key);
it.remove();
inEdges.put(source, weight);
return lastEdgeWeight;
}
}
inEdges.put(source, weight);
checkRep();
return0;
}
Ctrl + F调出查询窗口,将String参量换为L即可。
- Implement Graph.empty()
使Graph.empty()返回一个新的空示例
publicstatic Graph<String>empty(){
returnnew ConcreteEdgesGraph();
}
- Problem 4: Poetic walks
- Test GraphPoet
- Problem 4: Poetic walks
在基于预设的测试用例基础上,增加等价类划分的多种情况。
等价类划分:两个单词之间不存在连接词,两个单词之间只有一个连接词,两个单词之间有多个连接词。
此外还要注意句末的句号,测试当一个句子最后一个词是“桥”的一端。
- Implement GraphPoet
CheckRep
所有的点(单词)都不能为空。
// checkRep
privatevoidcheckRep(){
Set<String> vertices = graph.vertices();
for(String vertex : vertices)
assert(vertex !=null);
}
GraphPoet
将词库输入图的函数,主要思路为使用bufferedreader和split方法来将单词作为点存在图中,将单词之间的相邻关系作为边存入图中。
while((line = reader.readLine())!=null){
line = line.replace("."," ");
words = line.split(" ");
for(int i =0; i < words.length; i++){
graph.add(words[i].toLowerCase());
if(i >0){
int lastEdgeWeight = graph.set(words[i -1].toLowerCase(), words[i].toLowerCase(),1);
if(lastEdgeWeight !=0)
graph.set(words[i -1].toLowerCase(), words[i].toLowerCase(), lastEdgeWeight +1);
}
}
}
poem
检测相邻的两个单词之间是否有中间词,若单词不在图中则加入图中,若在图中则用targets和sources求两点的中间点中找路权重最大的加入answer。
找桥
targets = graph.targets(words[i -1].toLowerCase());
sources = graph.sources(words[i].toLowerCase());
intersection = sources.keySet();
intersection.retainAll(targets.keySet());
找最大桥
for(String key : intersection){
if(sources.get(key)+ targets.get(key)> maxBridge){
maxBridge = sources.get(key)+ targets.get(key);
bridge = key;
}
}
* <p>For example, given this corpus:
* <pre> This is a test of the Mugar Omni Theater sound system. </pre>
* <p>on this input:
* <pre> Test the system. </pre>
* <p>the output poem would be:
* <pre> Test of the system. </pre>
测试poem的样例 完全一致
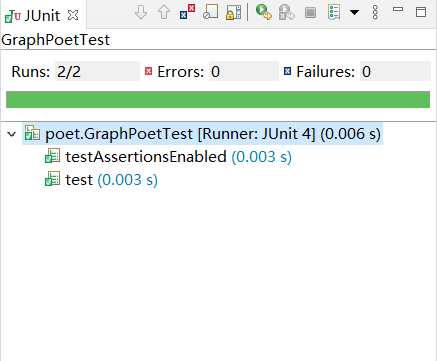
Junit测试 通过
请按照Problem Set 2: Poetic Walks的说明,检查你的程序。
如何通过Git提交当前版本到GitHub上你的Lab2仓库。
git不好用 这里为了节约时间 直接远程上传了。
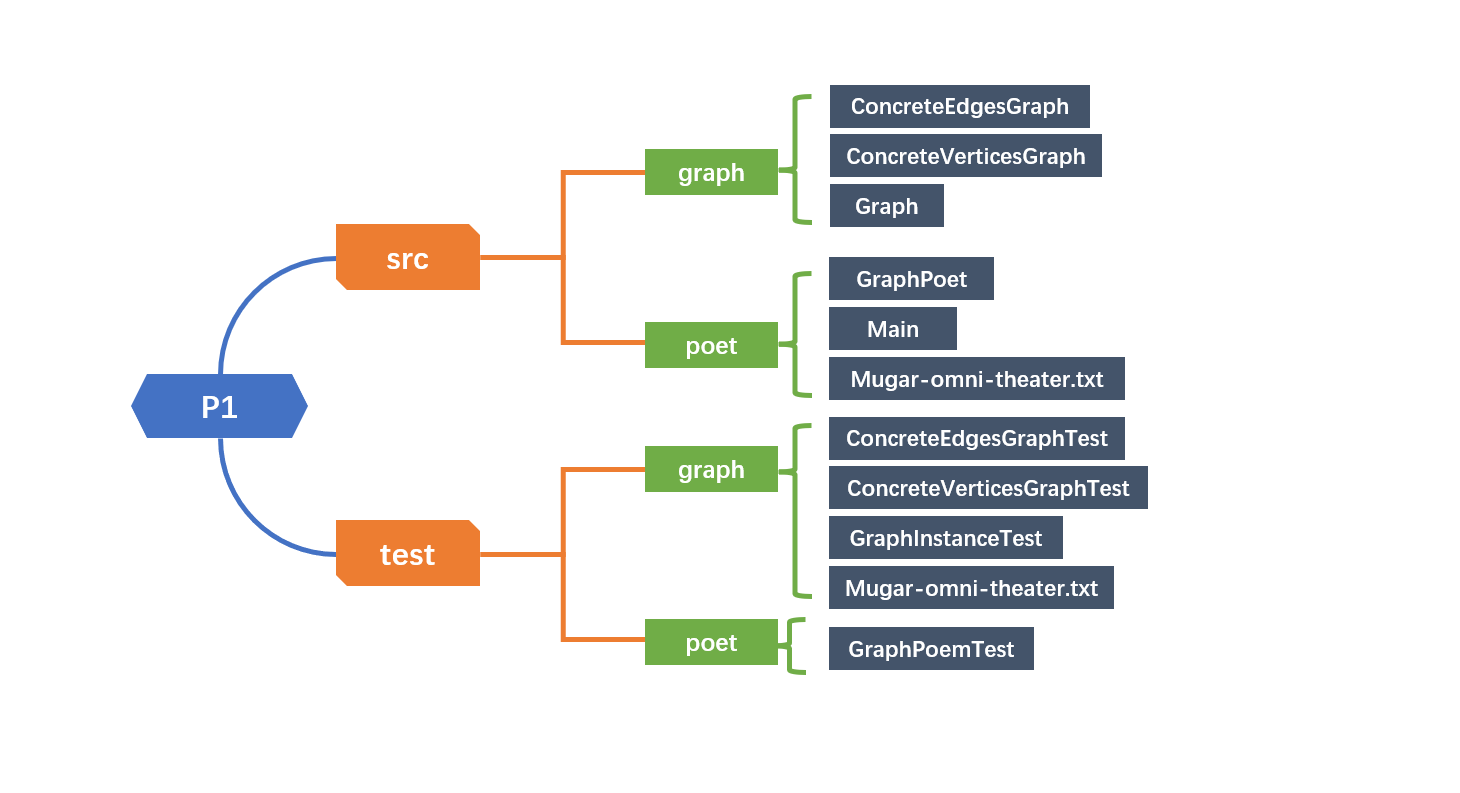
在这里给出你的项目的目录结构树状示意图。
将Lab1中实现Friendship的方法用Lab2中的Graph类重写一遍,其实影响不大,因为Lab1我也是用HashMap写的,所以几乎不需要修改。
具体算法和LAB1中没有变化 这里重新说明一次。
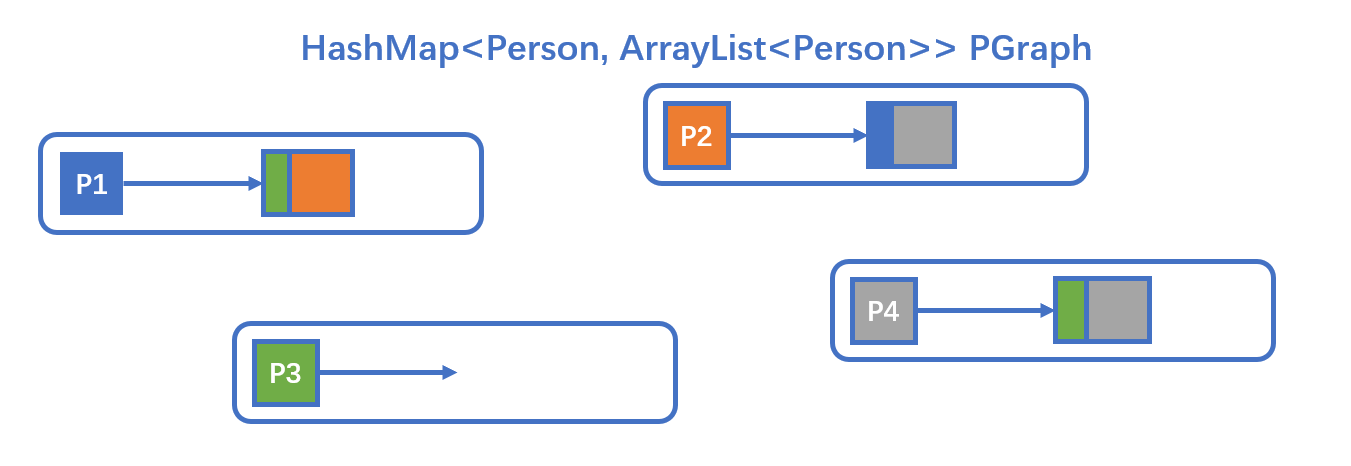
使用存储了人以及与人相邻的边的数据结构来储存数据,Lab1中为HashMap,Lab2中换成了Graph类。
addVertex
publicbooleanaddVertex(Person P){
return graph.add(P);
}
addEdge
publicintaddEdge(Person P1, Person P2){
int lastWeight;
lastWeight = graph.set(P1, P2,1);
lastWeight = graph.set(P2, P1,1);
return lastWeight;
}
getDistance
与Lab1一样 使用广度优先搜索,用HashMap来存储距离,输出时读取HashMap的值
publicintgetDistance(Person P1, Person P2){
if(graph.vertices().contains(P1)==false){
System.out.println("WHO IS"+P1.getName()+"? NEVER EXISTED BEFORE");
}
if(graph.vertices().contains(P2)==false){
System.out.println("WHO IS"+P2.getName()+"? NEVER EXISTED BEFORE");
}
if(graph.targets(P1).isEmpty()|| graph.targets(P2).isEmpty())
return-1;
if(P1 .equals(P2))
return0;
List<Person> list =new ArrayList<Person>();
LevelMap.put(P1,0);
list.add(P1);
while(!list.isEmpty()){
for(Person p : graph.targets(list.get(0)).keySet()){
if(p == P2){
int dist = LevelMap.get(list.get(0))+1;
list.clear();
LevelMap.clear();
return dist;
}
if(!LevelMap.containsKey(p)){
LevelMap.put(p, LevelMap.get(list.get(0))+1);
list.add(p);
list.remove(0);
}
}
}
return-1;
}
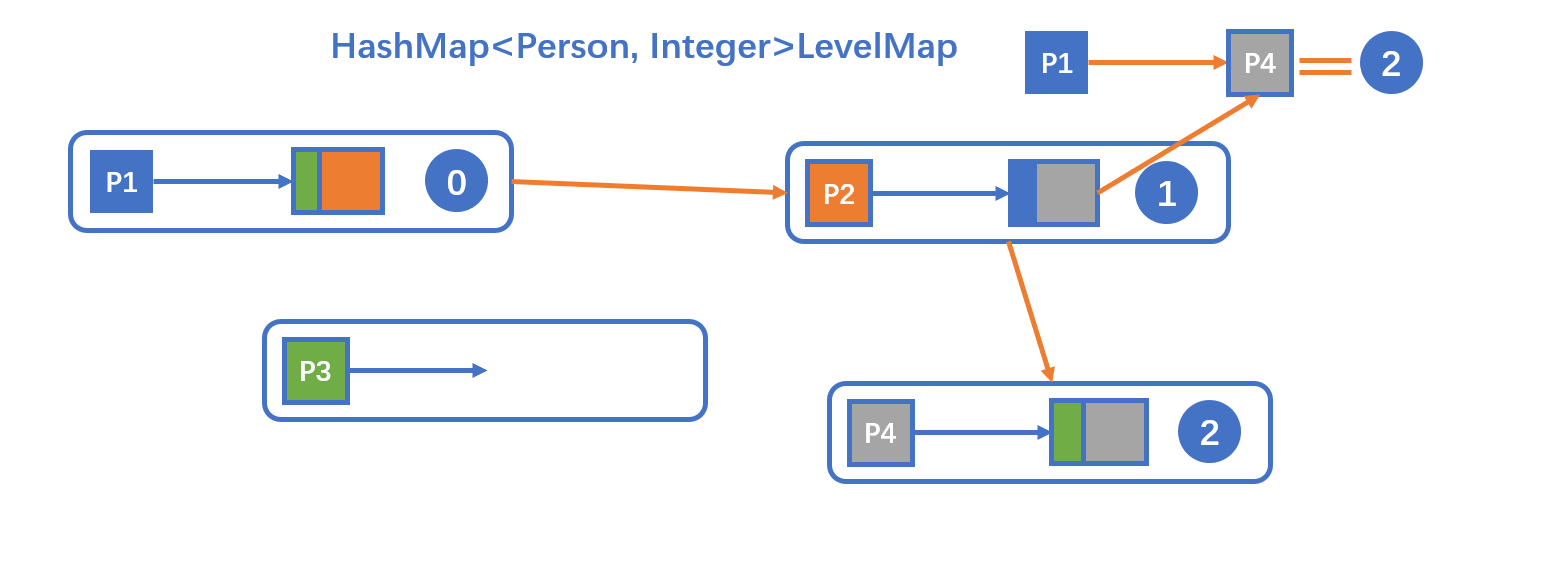
跟Lab1完全一致,不需要修改。
- 客户端main()
跟Lab1完全一致,不需要修改,因为本身是测试样例,不为实现方法所影响。
publicstaticvoidmain(String args[]){
FriendshipGraph graph =new FriendshipGraph();
Person rachel =new Person("Rachel");
Person ross =new Person("Ross");
Person ben =new Person("Ben");
Person kramer =new Person("Kramer");
graph.addVertex(rachel);
graph.addVertex(ross);
graph.addVertex(ben);
graph.addVertex(kramer);
graph.addEdge(rachel, ross);
graph.addEdge(ross, rachel);
graph.addEdge(ross, ben);
graph.addEdge(ben, ross);
System.out.println(graph.getDistance(rachel, ross));//should print 1.
System.out.println(graph.getDistance(rachel, ben));//should print 2.
System.out.println(graph.getDistance(rachel, rachel));//should print 0.
System.out.println(graph.getDistance(rachel, kramer));//should print ‐1
}
沿用了Lab1的测试样例,设计复杂一些的无向图,然后测试点之间的距离。

FriendshipGraph中没覆盖到的主要是会导致程序停止的输入检测语句。主要函数覆盖率均达标。
- 提交至Git仓库
如何通过Git提交当前版本到GitHub上你的Lab2仓库。
同上。。git不好用 连接不上
在这里给出你的项目的目录结构树状示意图。
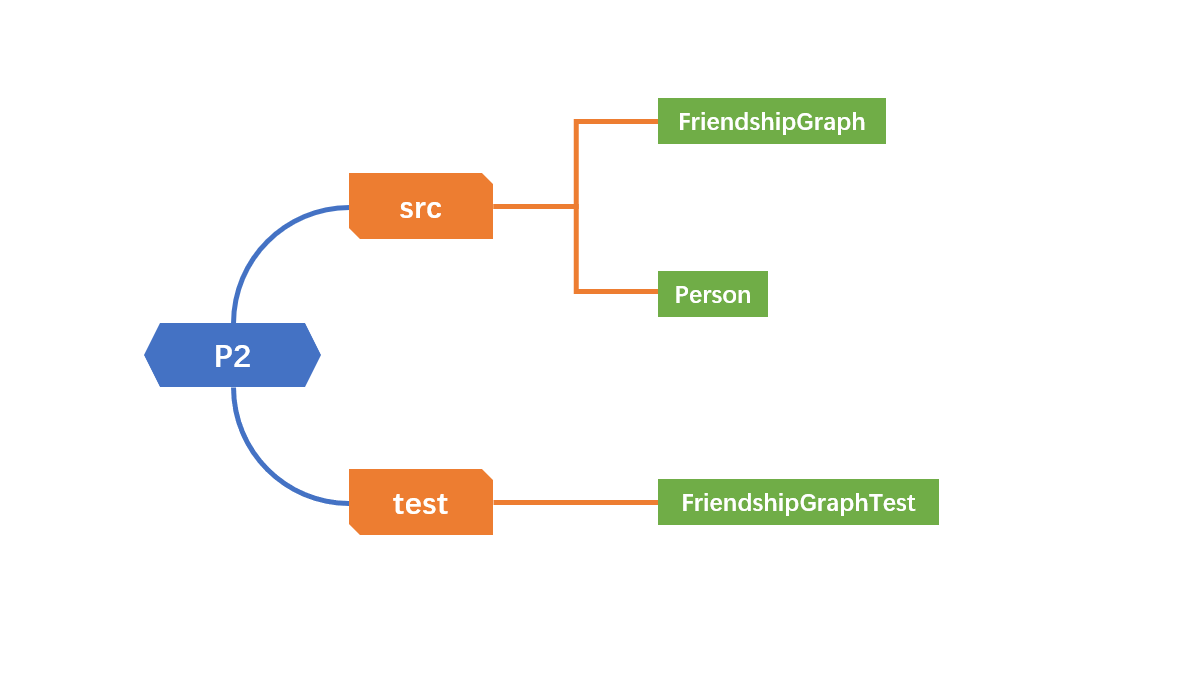
请使用表格方式记录你的进度情况,以超过半小时的连续编程时间为一行。
日期 | 时间段 | 计划任务 | 实际完成情况 |
5/18 | 13:00-15:00 | 准备实验预备代码,了解实验具体内容 | 按期完成 |
5/19 | 18:00-20:00 | 编写ConcreteEdgesGraph | 按期完成 |
5/19 | 19:00-23:00 | 编写ConcreteVerticesGraph并测试 | 按期完成 |
5/23 | 12:00-13:00 | 编写测试样例以及测试EclEmma | 按期完成 |
5/24 | 14:30-17:30 | 完成P1 Graph问题的收尾 | 按期完成 |
5/25 | 10:00-15:00 | 编写P1的Poem问题 | 按期完成 |
5/25 | 19:00-24:00 | 完成P1 以及编写P2的所有内容,撰写报告 | 按期完成 |
遇到的难点 | 解决途径 |
对Graph类的写法以及泛型的概念不太理解 | CSDN学习了一下,完全掌握了 |
测试Graph相关方法时缺少比较对象 | 在set和add等方法中添加了返回值,方便测试 |
编写Poet时单词的拆分有问题 | 在初始化字符串时,将‘,’改为‘ ’,之后再split(‘ ’)就可以了。 |
在设计一个完整的实现的过程中,底层的抽象类的设计非常重要,它决定了上层代码的整洁度和编写难度。
ADT和泛型的使用可以提升程序的泛用性。
测试时要尽量提高程序的覆盖率,这样才叫健全。
认真写注释很重要
按时总结很重要,量化工作指标。
- 面向ADT的编程和直接面向应用场景编程,你体会到二者有何差异?
面向ADT的设计思路和面向应用场景的编程不一样,面向ADT是从结构上去考虑问题,而非过程。它将具体的场景给具象化成模块,然后再抽象。更考验编程者的能力。
- 使用泛型和不使用泛型的编程,对你来说有何差异?
泛型向下兼容其它类型,对于编程者来说只是换了个符号而已,对于使用者来说是非常方便的东西。
- 在给出ADT的规约后就开始编写测试用例,优势是什么?你是否能够适应这种测试方式?
从底层开始debug,设计出合理的ADT,才能够继续后续的工作,不为未来埋下地雷。同时,也可以减轻后续代码的测试难度。
需要一些时间适应。。。
- P1设计的ADT在多个应用场景下使用,这种复用带来什么好处?
减少了工作量,降低了出底层bug的几率,提升了debug的效率。
- 为ADT撰写specification, invariants, RI, AF,时刻注意ADT是否有rep exposure,这些工作的意义是什么?你是否愿意在以后编程中坚持这么做?
这样做能够有效避免程序出一些原理性的错误,同时规避很多错误。还能够提升程序的可读性,非常不错。
有点麻烦,但是考虑到自己并非每天状态都很好,所以为了未来的自己,这么写也是有好处的
- 关于本实验的工作量、难度、deadline。
比上一个实验合理很多,这个实验的ddl和难度都很正常
- 《软件构造》课程进展到目前,你对该课程有何体会和建议?
实验很不错,但是感觉课程和实验的联系度略显不够。
边栏推荐
- How to get started with MOOSE platform - an example of how to run the official tutorial
- 调用时序错误导致webrtc无法建立链接
- 使用cef离屏渲染技术实现在线教育课件和webrtc视频回放融合录制
- const int * a 与 int * const a 的定义与区别
- Implementation of CAS lock-free queue
- Completely remove MySQL tutorial
- Deep learning, "grain and grass" first--On the way to obtain data sets
- IDEA中创建web项目实现步骤
- [Daily office][shell] Common code snippets
- Tencent and NetEase have taken action one after another. What is the metaverse that is so popular that it is out of the circle?
猜你喜欢




随机推荐
LeetCode_Dec_3rd_Week
[开发杂项][VS Code]remote-ssd retry failed
【C语言】数组名是什么
LeetCode_22_Apr_4th_Week
动态内存管理-C语言
Implementation of CAS lock-free queue
[daily office][ssh]cheatsheet
2022在 Go (Golang) 中使用微服务的系统课程
Pytest common plug-in
DRA821 环境搭建
MySQL存储过程学习笔记(基于8.0)
LeetCode_Dec_2nd_Week
用PPAPI插件技术在Web上显示会议视频、桌面、PPT等
常见的一些排序
Shell基础
2020-03-27
file permission management ugo
Deep Learning Theory - Overfitting, Underfitting, Regularization, Optimizers
Janus转发丢包导致音视频不同步原因分析
MySQL索引