当前位置:网站首页>Resource management, high availability and automation (medium)
Resource management, high availability and automation (medium)
2022-06-28 03:33:00 【Ultipa】
Closer to end users than resource management is a range of services , It can be an ordinary mail service 、 File service 、 Database services , It may also be aimed at big data analysis Hadoop Cluster and other services . For configuring these services , The unique advantage of software defined data centers is Automation . for example VMware Of vCAC(vCloud Automation Center) You can follow the steps preset by the administrator , Automatically deploy almost any traditional service , From database to file server . The vast majority of deployment details are predefined , The administrator only needs to adjust a few parameters to complete the configuration . Even if there are some special services ( For example, services developed by users themselves ), There is no pre-defined deployment process , You can also use graphical tools to edit workflow , And use it repeatedly .
From the underlying hardware to providing services to users , Resources have been partitioned ( virtualization )、 restructuring ( Resource pool )、 redistribution ( service ) The process of , It seems to add a lot of extra layers . Look at it this way ,“ Software definition ” It's not free . But hierarchical design , It is conducive to the parallel development and collaborative work of various technologies . This is very similar to the development of network protocols .TCP/IP The protocol cluster clearly defines the responsibilities and interfaces of each protocol layer , Only in this way can all parties involved develop in a coordinated way . Research on Ethernet can focus on improving transmission speed and maintaining link state , Research IP Layer can only care about IP Routing related issues . Let experts solve professional problems in their field , It is undoubtedly the most efficient .
Every level of data center defined by software involves many key technologies . Some technologies have a long history , But it has been redefined and developed , For example, software defined calculations 、 Unified resource management 、 Secure computing and high reliability ; Some technologies are new , And is still developing rapidly , For example, software defined storage 、 Software defined networks 、 Automated process control . These technologies are the key to the operation of software defined data centers , It is also the core advantage of software defined data center .
High availability (Availability) It means that a system can provide users with services that meet or exceed the agreed service level within the agreed time period , Such as access 、 Task scheduling 、 Task execution 、 Result feedback 、 Status query, etc . The service level is usually expressed as the time when the system is unavailable is lower than a certain threshold (Threshold). If any key link goes wrong or stops responding , The current system status is said to be unavailable . Generally, the time when the system is unavailable is called downtime ( Downtime ). Quantitative measurement of availability : Availability is usually expressed as the percentage of the available time of the system in the measured time period , Generally, one year or one month can be used as the measurement period , The choice depends on the service contract 、 Actual demand such as metering and charging . The following table shows the different availability indicators ( As can be seen from the table , Claim to achieve 7 individual 9 even to the extent that 11 individual 9 The system of , The annual downtime is as low as 3s—0.3ms, It's amazing , The industry will generally 5 individual 9 The above systems are called zero downtime systems ).
surface : System availability vs. downtime
Usability | Downtime / year | Downtime / month | Downtime / Japan |
90% | 36.5 God | 72 Hours | 16.8 Hours |
95% | 18.25 God | 36 Hours | 8.4 Hours |
Continuation table
Usability | Downtime / year | Downtime / month | Downtime / Japan |
99%(2 individual 9) | 3.65 God | 7.2 Hours | 1.68 Hours |
99.9%(3 individual 9) | 8.76 Hours | 43.8 minute | 10.1 minute |
99.99%(4 individual 9) | 52.6 minute | 4.3 minute | 1.0 minute |
99.999%(5 individual 9) | 5.26 minute | 25.9 second | 6.05 second |
99.9999%(6 individual 9) | 31.5 second | 2.59 second | 0.605 second |
… | … | ||
99.999999999% | 0.3 millisecond | 25 Microsecond | <1 Microsecond |
Zero downtime (Zero-Down-Time) System design means that the mean time between failures of a system greatly exceeds the maintenance cycle of the system ( Downtime ). In such a system , The mean time between failures is calculated by reasonable modeling and simulation . Zero downtime usually requires large-scale component redundancy , In the software 、 Hardware 、 Engineering is common . for example , We are familiar with the global positioning system (GPS) Usually use 5 Or more satellites to achieve positioning 、 Time and system redundancy is a typical example . There are similar suspension bridges (Suspension Bridge) Multiple vertical cables are typical high redundancy design .
High availability systems typically aim to minimize two metrics : System downtime (Down-Time) And data loss (Data-Loss). The high availability system must at least ensure that it fails at a single node / In case of shutdown , Be able to keep enough downtime and data loss ; And before the next possible single node failure , Use hot standby (Hot Standby) Node repair cluster , Restore the system to a high availability state .
Single point of failure or single point of bottleneck , That is, any independent hardware or software in the system has problems , It will lead to uncontrollable system downtime or data loss . A key responsibility of high availability system is to avoid single point of failure . So , All components in the system shall ensure sufficient redundancy , Including storage 、 The Internet 、 The server 、 Power supply 、 Applications, etc . In more complex cases , The system may have multiple points of failure , That is, more than two nodes in the system fail at the same time ( The expiration period overlaps , And independent of each other ). Many high availability systems cannot survive this situation ; When problems arise , Usually avoiding data loss has a higher priority , Relative to system downtime .
In order to achieve 99% Even higher availability , High availability systems require a fast error detection mechanism , And ensure relatively short recovery time . Of course, the mean time between failures should be as long as possible (MTBF) It is also crucial to ensure high availability . In short , Minimize the number of errors , Quick detection after error , Repair as soon as possible after detection .
The most common high availability cluster is a two node cluster , Including one primary node and one redundant node , That is to say 100% Redundancy ratio , This is also the minimum size for cluster construction . The primary node and the redundant node can be single active (Active-Passive), It can also be double living (Active-Active) Of , It depends on the characteristics and performance requirements of the application . There are many other clusters with multi node design , Sometimes it reaches the scale of tens or even hundreds of nodes ; Multi node cluster design is relatively complex . Common high availability cluster configurations are as follows .
· Single activity (Active-Passive): Redundant nodes are in standby state at ordinary times , No external services . Once the primary node fails , Redundant nodes go online and take over the remaining tasks in the shortest time . This configuration requires high equipment redundancy , Usually seen in a two node cluster . Common backup methods include hot standby (Hot Standby) And cold standby (Cold Standby) Two kinds of . With Hadoop Systematic NameNode For example , It is a typical Active-Passive Strategy , Two NameNode, The primary node is Active, Spare node Hot Standby.
· Double live or multi live (Active-Active): The load is replicated or distributed to all nodes ; All nodes are active nodes ( Or master node ). Relatively few nodes are required for a fully replicated pattern , In case of inconsistency in operation results, the principle of majority voting can be adopted (Vote Logic). The failure of any node will not cause performance degradation . This mode also takes into account the consideration of load balancing , When a node fails , Tasks will be reassigned to other active nodes . Node failure may cause a certain loss of system performance , The specific proportion depends on the number of downtime nodes , But it will not cause complete downtime . Take the storage system as an example ,EMC Of VPLEX And NetApp MetroCluster All of them realize Active-Active High availability .VPLEX Even three different modes are supported : Cross storage devices in the data center 、 Cross data center synchronous and cross data center asynchronous dual active / How to live 、 High availability and data mobility .
· Single node redundancy (N+1): Similar to the single active mechanism , Provide a redundant node in standby state . The difference is , There may be multiple primary nodes ; Once a primary node fails , Redundant nodes will be replaced immediately . This mode is mostly used in user systems where some services need multiple instances to run . The previous single live mode is actually a special case of this mode .
· Multi node redundancy (N+M): As an extension of the single node redundancy mechanism , Provide multiple redundant nodes in standby state . This pattern is applicable to multiple ( Multi instance running ) Service user system . The specific number of redundant nodes depends on the trade-off between cost and system availability .
There are other design patterns in theory , For example, double live or multiple live and single live / Combination of multi node redundancy , Based on the double consideration of redundancy rate and performance guarantee . However, as mentioned above , Add redundant components and adopt more complex system design , Not necessarily good news for overall availability , Sometimes the negative effects are even dominant . Therefore, when designing high reliability systems , We should follow the principle of simplicity .

边栏推荐
猜你喜欢

2022 safety officer-c certificate examination question bank simulated examination platform operation
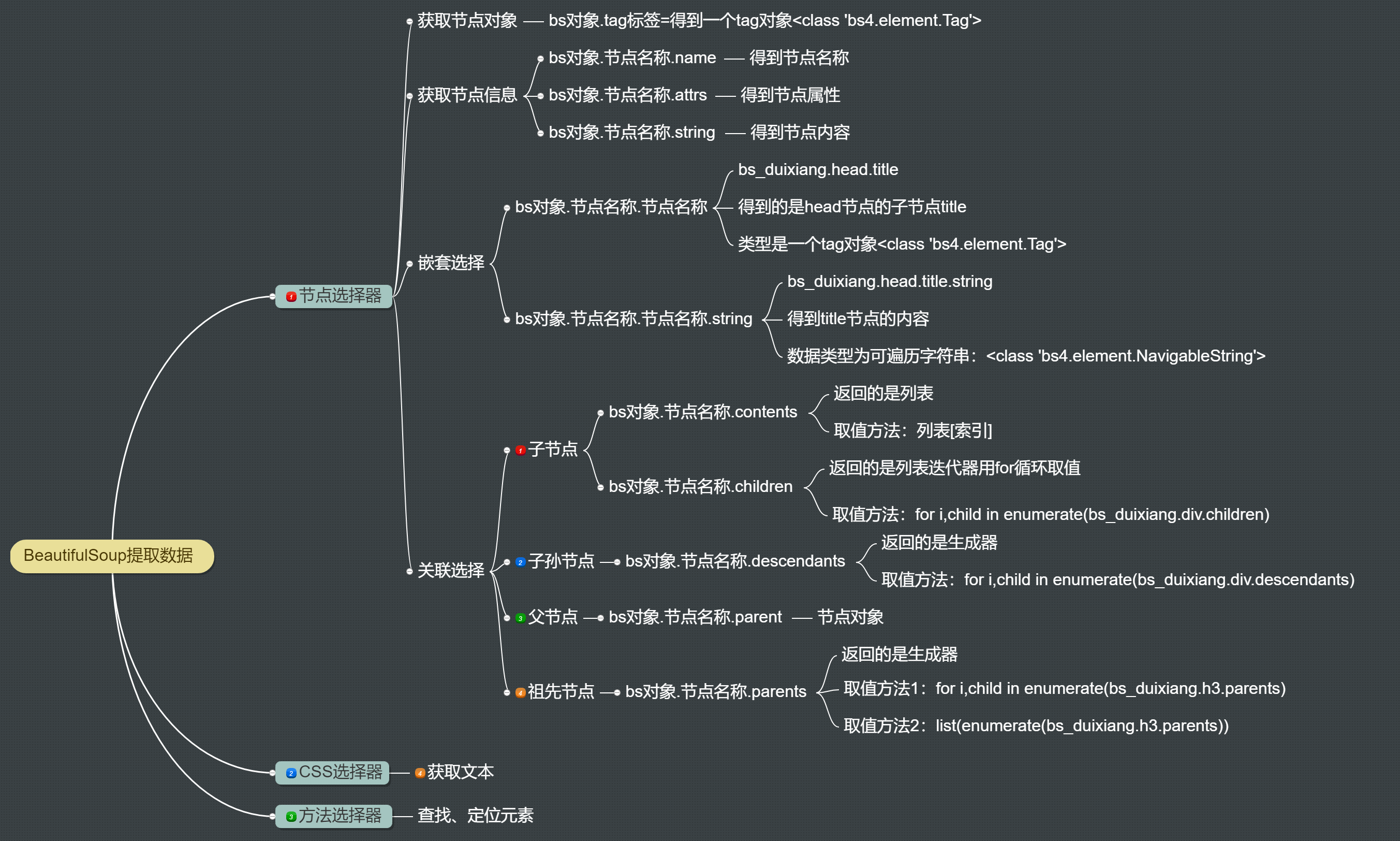
17 `bs对象.节点名h3.parent` parents 获取父节点 祖先节点

数据库系列之MySQL配置F5负载均衡

2022电工(初级)复训题库及在线模拟考试

栈的基本操作(C语言实现)

Tardigrade: Trino's solution to ETL scenarios
![Redis cluster setup [simple]](/img/20/9974a290f8c5d346e2b404b48b02e5.png)
Redis cluster setup [simple]
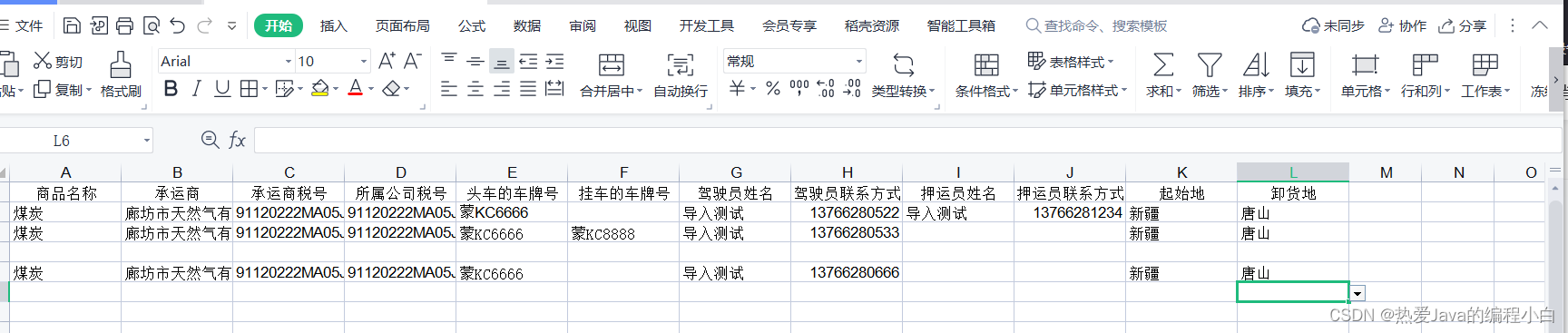
导入Excel文件,解决跳过空白单元格不读取,并且下标前移的问题,以及RETURN_BLANK_AS_NULL报红

GAMES104 作业2-ColorGrading

Object类,以及__new__,__init__,__setattr__,__dict__
随机推荐
数据库系列之MySQL中的执行计划
文档问题
Object class, and__ new__,__ init__,__ setattr__,__ dict__
Agileplm exception resolution session
[iptables & ICMP] description of ICMP Protocol in iptables default policy
在excel文件上设置下拉选项
【PaddleDetection】ModuleNotFoundError: No module named ‘paddle‘
How to automatically add author, time, etc. to eclipse
2022 safety officer-c certificate examination question bank simulated examination platform operation
数据库系列之MySQL和TiDB中慢日志分析
新手开哪家的证券账户是比较好?股票开户安全吗
Arm development studio build compilation error
Custom controls under WPF and adaption of controls in Grid
R1 Quick Open Pressure Vessel Operation Special Operation Certificate Examination Library and Answers in 2022
【PaddleDetection】ModuleNotFoundError: No module named ‘paddle‘
开口式霍尔电流传感器如何助力直流配电改造?
matlab习题 —— 符号运算相关练习
MySQL错误
GAMES104 作业2-ColorGrading
collections. Use of defaultdict()