当前位置:网站首页>[RNN] analyze the RNN from rnn- (simple|lstm) to sequence generation, and then to seq2seq framework (encoder decoder, or seq2seq)
[RNN] analyze the RNN from rnn- (simple|lstm) to sequence generation, and then to seq2seq framework (encoder decoder, or seq2seq)
2022-07-25 09:57:00 【Tobi_ Obito】
Preface
Recently, I am working on a multi label classification project , It is found that the difficulty of multi label classification can be transformed into sequence generation problem ( Here's the picture , Quoted from thesis 《Ensemble Application of Convolutional and Recurrent Neural Networks for Multi-label Text Categorization》[1]), The ideas in the paper are very thorough , The picture is also clear , however RNN We still need to figure out the specific implementation of , So the whole thinking process starts from the simplest RNN To seq2seq Have combed it all over , I wish to record .

For clarity , Let's expand around the above figure .
RNN
First, simplify the above figure to basic RNN structure :

Be clear at a glance , ~
~ It's the input sequence ,
It's the input sequence , ~
~ Is the output sequence ( Sometimes we only use the output of the last sequence , For example, I'll talk about it later Encoder - decoder Encoder in frame ),h0~h3 The horizontal arrow between is the state
Is the output sequence ( Sometimes we only use the output of the last sequence , For example, I'll talk about it later Encoder - decoder Encoder in frame ),h0~h3 The horizontal arrow between is the state  The transfer .
The transfer .
Simple-RNN
Simple-RNN It's simple , Is to put t The output of time  As t The state of the moment
As t The state of the moment  Pass on to the next moment t+1 Status input , In a word, the state passed between sequences is the output of the previous sequence .
Pass on to the next moment t+1 Status input , In a word, the state passed between sequences is the output of the previous sequence .
LSTM
Simple-RNN Simple though , But one problem is that the gradient disappears , Occurs when the sequence length is long , The specific analysis is not discussed here , Introduce LSTM Are basically involved , and LSTM It is proposed to solve this problem , Adopt door mechanism ( What a complicated look ), The gate mechanism can be simply understood as : Put two adjacent sequences  and
and  The state of transmission between
The state of transmission between  In two parts ( It doesn't have to be continuous ), Part of the last sequence is reserved
In two parts ( It doesn't have to be continuous ), Part of the last sequence is reserved  Status of transmission ( namely
Status of transmission ( namely  Partial value of ), The other part is the current timing Calculated state ( It's the original RNN It's like that ). The gate is the control state vector s Which dimensions in are reserved , Which dimensions are updated , An example that simply reflects the idea but is not accurate is shown in the following figure . So what is retained in the state , What has been updated ? The door chooses , So it can be understood visually that some doors are closed, and the newly calculated ones cannot pass , Thus retaining the old . Then how to choose the door , The answer is by multiplying each dimension by one 0~1 Between decimals to achieve opening and closing , It can be seen that the door is a state s Vectors with the same dimension , The value of the gate vector is learned ( As network parameters ). Said along while , In a word ,LSTM It's solved Simple-RNN Gradient vanishing problem in , Better is over .
Partial value of ), The other part is the current timing Calculated state ( It's the original RNN It's like that ). The gate is the control state vector s Which dimensions in are reserved , Which dimensions are updated , An example that simply reflects the idea but is not accurate is shown in the following figure . So what is retained in the state , What has been updated ? The door chooses , So it can be understood visually that some doors are closed, and the newly calculated ones cannot pass , Thus retaining the old . Then how to choose the door , The answer is by multiplying each dimension by one 0~1 Between decimals to achieve opening and closing , It can be seen that the door is a state s Vectors with the same dimension , The value of the gate vector is learned ( As network parameters ). Said along while , In a word ,LSTM It's solved Simple-RNN Gradient vanishing problem in , Better is over .

Sequence generation
It was all from RNN From the perspective of network structure , Now from the perspective of the task RNN, Have a look RNN The application mode of —— Sequence generation .
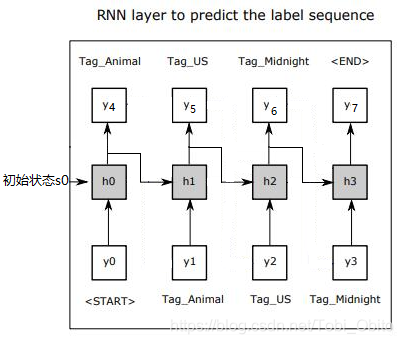
The problem of sequence generation is to give a sequence , Generate another sequence . For example, machine translation 、 The text generated . In order to lead to the core of this article , Consider such a text generation task : Give a word , Generate a sequence . The idea is simple : Give the word as RNN Of t=0 Time input , Predict the output , Then take the output as the input of the next moment , Make predictions in this cycle , Until the specified length is reached or the specified terminator is predicted . Here's the picture ( Is it more and more similar to the figure in the initial paper ?).

Clear thinking , But here's the problem , It's not easy to operate ! Think about training , Training data X It is often a predetermined direct input network , Now the situation is that the subsequent input should be obtained from the output , This requires settings closer to the bottom , Are some of the existing packaged RNN( such as Keras Inside LSTM/GRU And so on ) What cannot be achieved , Although it is said that , But in fact Keras or TensorFlow It can still be realized , Although in Keras You can't simply define a LSTM layer To achieve , But by definition RNN(rnn_cell, ...) layer Then customize rnn_cell Operate accordingly .( So-called cell Is the calculation unit of each time sequence , It's the h0/h1/h2/h3 Square box , Notice that they are essentially the same ! It seems that there are many diagrams that are only expanded according to time, which is easy to understand ). Of course, it can also be Tensorflow Medium tf.nn.raw_rnn To achieve , See me for details Another blog post .
Conditional generation framework
Now let's do something about the input of sequence generation , We no longer input simple words , Instead, we put the word vector and a meaningful vector c Splice up , So that the input contains more information , This vector c It is called conditional context vector . At this point, it may not be clear why such a vector should be spliced , Let's use the following figure to explain ( Take a step closer to the original picture of the paper , Oh dear , It's already here ).

In the picture  It can be regarded as a conditional context , It is input in every time sequence cell.Text feature vector It well explains the purpose of doing this : We can extract features from a long text , Use this feature to help us predict the subsequent network . How to help ? Now let's return to the problem of multi label classification mentioned at the beginning .
It can be regarded as a conditional context , It is input in every time sequence cell.Text feature vector It well explains the purpose of doing this : We can extract features from a long text , Use this feature to help us predict the subsequent network . How to help ? Now let's return to the problem of multi label classification mentioned at the beginning .
Sequence generation solve Multi label classification
First consider the problem of single label classification , It's very simple , According to the characteristics of X To predict the classification OK 了 , Can it be seen as the following figure ?

It may be a little clear to see here , What if you classify more times ? Here's the picture .

Why should we repeat the classification several times here ? By repeating , Created such an opportunity : For categories with similar characteristics , In the a The result of sub classification differ The first b The result of sub classification , Of course, this form alone cannot achieve the desired effect , Because the same input will basically get the same output ( It is basically because h0 h1 h2 h3 Different parameter weights , For approximate categories, the output may be different , But this difference is uncontrollable , So it can't meet expectations ). So how can we waver , Make in h0 Predict similar categories A, stay h1 Predict similar categories B Well ? Obviously, it's OK to add another input to shake , Look at the picture below ( Left ).


What is the difference between this picture and the picture in the paper ? There is no connection between shaking and predicted output . Think about what networking brings ? Compare the left and right pictures , Making connections means that the predicted tags will be related , This association can be between similar tags “ Near meaning ”. A practical example , For example, there are two similar labels, namely, campus safety and campus violence ( Generally, campus violence is often linked to campus security ), When using only h0 When making a single prediction ,y1 Both want to predict for campus safety , Also want to predict for campus violence , The two suppress each other in probability , As a result, no matter which confidence is predicted, it is not high ; When using the method shown in the right figure above , because y1 stay y2 In front of , In the training data, first y1 Predicted for campus safety , To y2 When predicting , because y1 The information that has been predicted as campus safety is conveyed to them , therefore y2 Will no longer be uncertain, but tend to predict campus violence .
To put it bluntly ,Text feature vector Set the basic tone ( Sift out those with low confidence ),RNN The information spread between time series learns the relationship between tags ( It is used to add left and right codes to labels that are left and right ).
Come here , The multi label problem seems to be solved , This is the end , But it seems that the picture is still different from the original picture of the paper , Look again. .
This comparison found some amazing things , All this should start from different points .
The difference between the graphs given in the paper is ,cell State transfer between (cell Horizontal arrow between ), And the above structure has reached the goal , Is it possible that adding another state transfer between sequences will improve the effect ? Is not clear , But my guess is possible :RNN Output at a certain time in  It is the state of the last moment
It is the state of the last moment  And the input of the current time
And the input of the current time  Determined by certain transformation , namely
Determined by certain transformation , namely  , This indicates that the state contains the information before the transformation , This may be useful ( If O() This leads to the loss of valid information between tags ).
, This indicates that the state contains the information before the transformation , This may be useful ( If O() This leads to the loss of valid information between tags ).
After guessing whether this repetition is effective , We should also consider whether we can remove one , Just use one ? Take a closer look at the picture with only one , Suddenly I found another wonderful thing , That's it Simple-RNN! Look at the picture below to compare :

The left and right diagrams only retain one kind of information transmission between time sequences , One is y One is s, So if y=s Well ? Isn't that what Simple-RNN Well ! Why think so , Because if you only keep one , That's direct use Simple-RNN It avoids the previous implementation problems —— The dynamic problem of taking the output of the previous moment as the input of the next moment . because Simple-RNN The state passed to the next in s It is the output of the previous moment , In the figure, it means that the broken line arrow in the left figure is equivalent to the horizontal arrow in the right figure .
seq2seq
The conditional generation framework was described earlier , Through the combination of specific examples of multi label classification RNN Deepen the understanding of sequence generation . Let's take it one step further seq2seq 了 ,seq2seq yes Sequence to sequence conditional generation For short , Also known as Encoder - decoder (encoder-decoder) frame . It's just Specifies the context condition vector in the condition generation framework c The source of the —— Get... Through the encoder . What is an encoder ? It can be said that the encoder is a RNN, It receives a sequence , Output a vector as the conditional context vector c, It encodes the sequence into a vector , Therefore, it is called encoder . As for the decoder , It is the main part of the condition generation framework . Here's the picture .
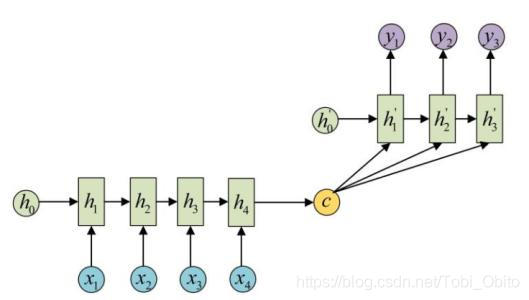
In fact, broadly speaking , The encoder is not necessarily RNN, For example, the text feature vector in the paper Text feature vector Is the CNN extracted , So the encoder is CNN. Again , The decoder is not necessarily CNN. let me put it another way , Encoder - decoder The framework should cover seq2seq Of .
Conclusion
This article only briefly introduces from RNN To seq2seq The main idea of , Among them, the problem of sequence generation is deeply analyzed , But there are still unmentioned problems , For example, in sequence generation teacher-forcing Training mode , It is also a training method to make the model learn the relationship between successive words , Different from the training mode mentioned in this article , Its training Y Namely X Move back one bit in time , Compared with the training mode in this article, it is more direct , But there are also non gold The problem of sequence , The specific details will not be discussed here , Interested parties can find relevant information .
reference
[1] G. Chen, D. Ye, Z. Xing, J. Chen and E. Cambria, "Ensemble application of convolutional and recurrent neural networks for multi-label text categorization," 2017 International Joint Conference on Neural Networks (IJCNN), 2017, pp. 2377-2383, doi: 10.1109/IJCNN.2017.7966144.
边栏推荐
- CDA Level1复盘总结
- 深度估计自监督模型monodepth2论文总结和源码分析【理论部分】
- MLX90640 红外热成像仪测温模块开发笔记(四)
- Get to know opencv4.x for the first time --- add salt and pepper noise to the image
- 无线振弦采集仪应用工程安全监测
- Data viewing and parameter modification of multi-channel vibrating wire, temperature and analog sensing signal acquisition instrument
- CCF 201509-3 模板生成系统
- Linked list -- basic operation
- OC -- Inheritance and polymorphic and pointer
- 单目深度估计自监督模型Featdepth解读(上)——论文理解和核心源码分析
猜你喜欢

BSP3 电力监控仪(功率监控仪)端子定义和接线
ESP32定时中断实现单、双击、长按等功能的按键状态机Arduino代码

Evolution based on packnet -- review of depth estimation articles of Toyota Research Institute (TRI) (Part 1)
![[deep learning] self encoder](/img/7e/c3229b489ec72ba5d527f6a00ace01.png)
[deep learning] self encoder

Coredata storage to do list

MLX90640 红外热成像仪测温模块开发笔记(五)
SOC芯片内部结构

SystemVerilog语法

Mlx90640 infrared thermal imaging sensor temperature measurement module development notes (II)

Creation of adjacency matrix of undirected connected graph output breadth depth traversal
随机推荐
数据分析业务核心
dp-851
SD/SDIO/EMMC
【Tensorflow2安装】Tensorflow2.3-CPU安装避坑指南!!!
低功耗和UPF介绍
ESP32定时中断实现单、双击、长按等功能的按键状态机Arduino代码
¥ 1-1 SWUST OJ 941: implementation of consolidation operation of ordered sequence table
OC -- Inheritance and polymorphic and pointer
FLASH read / write operation and flash upload file of esp8266
VScode配置ROS开发环境:修改代码不生效问题原因及解决方法
无线中继采集仪的常见问题
单目深度估计模型Featdepth实战中的问题和拓展
Evolution based on packnet -- review of depth estimation articles of Toyota Research Institute (TRI) (Part 1)
Chmod and chown invalidate the files of the mounted partition
Segmentation based deep learning approach for surface defect detection
CDA Level1知识点总结之业务分析报告与数据可视化报表
Connection and data reading of hand-held vibrating wire vh501tc collector sensor
BSP3 电力监控仪(功率监控仪)端子定义和接线
Mlx90640 infrared thermal imager temperature measurement module development notes (I)
从Anaconda到TensorFlow到Jupyter一路踩坑一路填平