当前位置:网站首页>leetcode-每日一题745. 前缀和后缀搜索(哈希和字典树)
leetcode-每日一题745. 前缀和后缀搜索(哈希和字典树)
2022-07-31 05:10:00 【lin钟一】
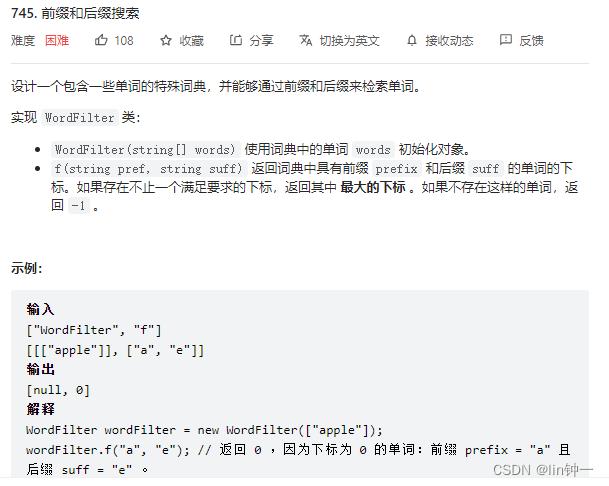
题目链接:https://leetcode.cn/problems/prefix-and-suffix-search/
思路
方法一、用哈希表记录每个单词的前缀和后缀组合
直接想法
如果我们用前缀 prefix 和 后缀 suff去暴力对比所有单词肯定会超时,我们可以先把单词里所有的前缀后缀组合,中间用特殊符号@连接,对应的最大下标存入哈希表中。搜索时,用特殊符号@连接前缀后缀,在哈希表中进行搜索
算法
- 把WordFilter类自定义为 map[string]int, 用于所有的前缀后缀组合的最大下标
- Constructor函数 遍历所有单词,把单词里所有的前缀后缀组合,中间用特殊符号@连接,对应的最大下标存入哈希表WordFilter中
- F方法用来判断前缀+ @ +后缀的组合是否存在于哈希表中
代码示例
type WordFilter map[string]int
func Constructor(words []string) WordFilter {
wf := WordFilter{
}
for i := range words{
for j, n := 1, len(words[i]); j <= n; j++{
for k := 0; k < n; k++{
wf[words[i][:j] + "@" + words[i][k:]] = i
}
}
}
return wf
}
func (wf WordFilter) F(pref, suff string) int {
if i, ok := wf[pref + "@" + suff]; ok{
return i
}
return -1
}
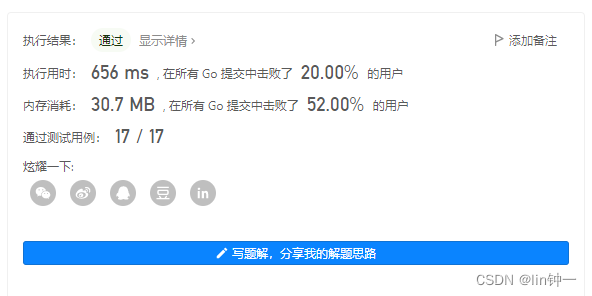
复杂度分析

方法二、字典树
直接想法
这道题首先想到的就是构造前缀、后缀字典树。其中树节点储存包含此前(后)缀的单词索引。在后续调用F方法时,一次遍历前后缀字典树,找到满足要求的前后缀单词索引集合,然后找出两个集合中最大的相同值,即为题解。
算法
- 构造前缀、后缀字典树
- Constructor函数 把所有单词的前缀、后缀下标存入当前前缀字典树和后缀字典树结点的idx数组
- F方法通过找到pref在前缀字典树的结点和suff在后缀字典树的结点,找到两个结点中idx数组中相同的最大下标输出
代码示例
type trie struct {
next []*trie
idx []int
}
type WordFilter struct {
pref,suff []*trie
}
func Constructor(words []string) WordFilter {
pref, suff := make([]*trie, 26), make([]*trie, 26)
for i, word := range words {
pf, sf, n := pref, suff, len(word)
for x, y := 0, n - 1; x < n && y >= 0; x, y = x + 1, y - 1 {
//构造前缀,把所有单词前缀组合下标在当前前缀字典树结点idx数组里
a := int(word[x] - 'a')
if pf[a] == nil {
pf[a] = &trie{
next: make([]*trie, 26),
idx: []int{
i},
}
} else {
pf[a].idx = append(pf[a].idx, i)
}
pf = pf[a].next
//构造后缀,把所有单词后缀组合下标在当前后缀字典树结点idx数组里
a = int(word[y] - 'a')
if sf[a] == nil {
sf[a] = &trie{
next: make([]*trie, 26), idx: []int{
i}}
} else {
sf[a].idx = append(sf[a].idx, i)
}
sf = sf[a].next
}
}
return WordFilter{
pref: pref, suff: suff}
}
func (this *WordFilter) F(pref string, suff string) int {
p := this.pref
var prefCandicates, suffCandicates []int
for i := range pref {
c := int(pref[i] - 'a')
if p[c] == nil {
return -1
}
//完全匹配前缀
if i == len(pref)-1 {
prefCandicates = p[c].idx
}
p = p[c].next
}
q := this.suff
for i := len(suff) - 1; i >= 0; i-- {
c := int(suff[i] - 'a')
if q[c] == nil {
return -1
}
//完全匹配后缀
if i == 0 {
suffCandicates = q[c].idx
}
q = q[c].next
}
i, j := len(prefCandicates)-1, len(suffCandicates)-1
for i > -1 && j > -1 {
//前缀和后缀存在于一个单词
if prefCandicates[i] == suffCandicates[j] {
return prefCandicates[i]
}
//尽量找到最大下标
if prefCandicates[i] < suffCandicates[j] {
j--
} else {
i--
}
}
return -1
}
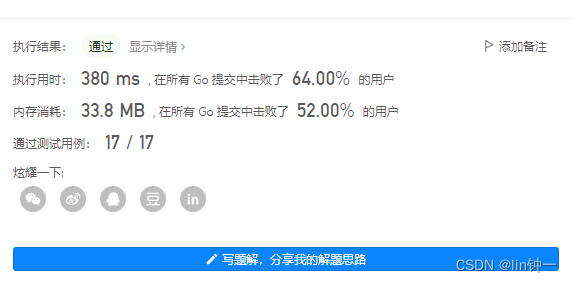
复杂度分析

边栏推荐
猜你喜欢
【一起学Rust】Rust的Hello Rust详细解析

13 【代理配置 插槽】

【MySQL8入门到精通】基础篇- Linux系统静默安装MySQL,跨版本升级

精解四大集合框架:List 核心知识总结

08 【生命周期 组件】

Sword Point Offer Special Assault Edition ---- Day 1
Interviewer: If the order is not paid within 30 minutes, it will be automatically canceled. How to do this?

剑指offer基础版 ---- 第27天
![【JS面试题】面试官:“[1,2,3].map(parseInt)“ 输出结果是什么?答上来就算你通过面试](/img/7a/c70077c7a95137aaeb49c344c82696.png)
【JS面试题】面试官:“[1,2,3].map(parseInt)“ 输出结果是什么?答上来就算你通过面试

太厉害了,终于有人能把文件上传漏洞讲的明明白白了

随机推荐
三次握手与四次挥手
Simple command of mysql
剑指offer基础版--- 第23天
MySQL-Explain详解
变量的解构赋值
第7章 网络层第1次练习题答案(第三版)
第7章 网络层第2次练习题答案(第三版)
wpf ScrowViewer水平滚动
一文了解大厂的DDD领域驱动设计
Sword Point Offer Special Assault Edition ---- Day 2
实验8 DNS解析
有了MVC,为什么还要DDD?
面试官,不要再问我三次握手和四次挥手
let和const命令
数据库上机实验1 数据库定义语言
Sword Point Offer Special Assault Edition ---- Day 1
docker安装postgresSQL和设置自定义数据目录
第7章 网络层第3次练习题答案(第三版)
Redis first meeting
tf.keras.utils.get_file()