当前位置:网站首页>ML - natural language processing - Key Technologies
ML - natural language processing - Key Technologies
2022-07-25 15:23:00 【sword_ csdn】
Catalog
Reference resources
Huawei cloud College
participle
Chinese word segmentation (Chinese Word Segmentation): It refers to the segmentation of a Chinese character sequence into a single word . Word segmentation is the process of recombining consecutive word sequences into word sequences according to certain norms .
for example : 1998 / China / Realization / Import and export / Gross value / reach / 109.82 billion / dollar
Regular participle
Regular participle : A mechanical word segmentation method , Mainly through the maintenance of dictionaries , When cutting sentences , Match each string in the statement with the words in the thesaurus one by one , If you find it, cut it , Otherwise, it can't be divided . According to the way of matching and segmentation , There are mainly :
(1) Forward maximum matching (Maximum Match Method,MM Law )
(2) Reverse maximum matching (Reverse Maximum Match Method,RMM Law )
(3) Two way maximum matching (Bi-direction Match Method,MM Law )
characteristic : A simple and efficient , Dictionary maintenance is difficult . Network neologisms emerge in endlessly , It is difficult for a dictionary to cover all words .
Statistical analysis
The word segmentation is realized as the sequence annotation task of words in the string . Each word occupies a certain word formation position when constructing a specific word , If the connected words appear more frequently in different texts , It proves that the connected word is probably a word .
step :
(1) Build statistical language model
(2) Divide sentences into words , Then calculate the probability of the result , Get the word segmentation with the greatest probability . Such as hidden Markov (HMM)、 Conditional random field (CRF) etc. .
Deep learning word segmentation
Use word2vec Embed the words of the word material , Get word embedding , Use word embedding feature input to two-way LSTM, Add a linear layer to the hidden layer of the output , And then add one CRF Get the final implementation model .
Mixed participle
In practical engineering applications , Most of them are based on a word segmentation algorithm , The most common way is to segment words based on dictionaries , Then use statistical word segmentation to assist .
Definition of part of speech tagging
Part of speech tagging refers to the process of tagging a correct part of speech for each word in the word segmentation result . For example, a word is a noun 、 Verb 、 Adjectives or other parts of speech .
The part of speech : Basic grammatical attributes of vocabulary .
Purpose : A lot NLP Task preprocessing steps , Such as parsing 、 Information extraction , The text marked with part of speech will bring great convenience , But it is not indispensable .
Method : A rule-based approach 、 Statistical based methods 、 Methods based on deep learning .
Named entity recognition
Named entity recognition (Named Entities Recognition,NER): Also known as “ Proper name recognition ”, It refers to the recognition of entities with specific meaning in the text , Mainly including people's names 、 Place names 、 Organization name 、 Proper nouns, etc . for example : metallurgy /n Ministry of industry /n luoyang /ns Refractories /l research institute /n.
NER The named entities studied are generally divided into 3 Categories: ( Entity class 、 Time class and number class ) and 7 Subclass ( The person's name 、 Place names 、 Organization name 、 Time 、 date 、 Currency and percentage ).
And automatic word segmentation 、 Part of speech tagging , Named entity recognition is also a basic task in natural language , It's information extraction 、 Information retrieval 、 Machine translation 、 Q & a system and other essential components of Technology .
step :(1) Entity boundary recognition .(2) Determine the entity class ( The person's name 、 Place names 、 Organization name )
difficulty :(1) There are many kinds of named entities .(2) The composition of named entities is complex .(3) Nesting is complex .(4) The length is uncertain
Deep learning NER

Keywords extraction
Keywords are a group of words that represent the important content of an article , In reality, a large number of texts do not contain keywords , Therefore, automatic keyword extraction technology can make people browse and obtain information conveniently , Clustering text 、 classification 、 Automatic summarization plays an important role .
Keyword extraction algorithms can also be divided into supervised and unsupervised .
Supervised : By classification , By building a relatively rich and perfect The vocabulary of , Then by judging the matching degree between each document and each word in the Thesaurus , In a manner similar to labeling , Achieve the effect of extracting keywords .
Unsupervised : No need to manually generate 、 Maintain a vocabulary , Don't train with the help of manual standard corpus . for example ,TF-IDF Algorithm 、TextRank Algorithm 、 Topic model algorithm (LSA、LSI、LDA)
TF-IDF Algorithm
Word frequency - Inverse document frequency algorithm (Term Frequency-Inverse Document Frequency,TF-IDF): It is a calculation method based on Statistics , It is often used to evaluate the importance of a word to a document in a document set .
TextRank Algorithm
TextRank The basic idea of the algorithm comes from Google Of PageRank Algorithm .PR Algorithm is a method to evaluate the importance of web pages covered by search system . There are two basic ideas :
(1) Number of links . A web page is linked by more other web pages , The more important this page is .
(2) Link quality . A web page is linked by a higher weight web page , It also shows that this webpage is important .
LSA/LSI/LDA Algorithm
The topic model believes that there is no direct connection between words and documents , They should also have a dimension that connects them , This dimension is called theme . Each document should correspond to one or more topics , And each topic will have a corresponding word distribution , The word distribution of each document can be obtained through the topic .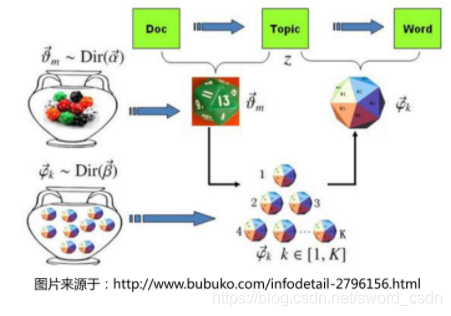
LSA\LSI Algorithm

LDA Algorithm


边栏推荐
- The implementation process of inheritance and the difference between Es5 and ES6 implementation
- How much memory can a program use at most?
- 期货在线开户是否安全?去哪家公司手续费最低?
- 基于OpenCV和YOLOv3的目标检测实例应用
- Spark SQL common time functions
- What is the Internet of things
- Spark提交参数--files的使用
- JVM parameter configuration details
- 记一次Spark foreachPartition导致OOM
- JVM-动态字节码技术详解
猜你喜欢

MySQL之事务与MVCC

Yan required executor memory is above the max threshold (8192mb) of this cluster!
Idea远程提交spark任务到yarn集群
防抖(debounce)和节流(throttle)

Spark提交参数--files的使用

How much memory can a program use at most?
Spark submission parameters -- use of files
一个程序最多可以使用多少内存?

Introduction to raspberry Pie: initial settings of raspberry pie
解决DBeaver SQL Client 连接phoenix查询超时
随机推荐
用setTimeout模拟setInterval定时器
简易轮播图和打地鼠
ice 100G 网卡分片报文 hash 问题
UIDocumentInteractionController UIDocumentPickerViewController
Args parameter parsing
npm的nexus私服 E401 E500错误处理记录
Scala111-map、flatten、flatMap
期货在线开户是否安全?去哪家公司手续费最低?
The development summary of the function of fast playback of audio and video in any format on the web page.
spark分区算子partitionBy、coalesce、repartition
记一次Spark报错:Failed to allocate a page (67108864 bytes), try again.
ios 面试题
golang复习总结
How to understand the maximum allowable number of errors per client connection of MySQL parameters in Seata?
Use the command to check the WiFi connection password under win10 system
JVM garbage collector details
Xcode添加mobileprovision证书文件报错:Xcode encountered an error
记一次Spark foreachPartition导致OOM
图片的懒加载
Spark-SQL UDF函数