当前位置:网站首页>MapReduce中ETL数据清洗案例
MapReduce中ETL数据清洗案例
2022-08-03 10:45:00 【QYHuiiQ】
在实际业务场景中,我们在对数据处理时会先对数据进行清洗,比如过滤掉一些无效数据;清洗数据只需要map阶段即可,不需要reduce阶段。
在该案例中我们要实现的是员工表数据中只留下部门编号为d01的数据。
- 数据准备
001,Tina,d03
002,Sherry,d01
003,Bob,d01
004,Sam,d02
005,Mohan,d01
006,Tom,d03
新建project:
- 引入pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>wyh.test</groupId>
<artifactId>TestETL</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
</properties>
<packaging>jar</packaging>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.3</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<minimizeJar>true</minimizeJar>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>- 自定义Mapper
package wyh.test;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class ETLMapper extends Mapper<LongWritable, Text, Text, NullWritable> {
@Override
protected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, NullWritable>.Context context) throws IOException, InterruptedException {
String[] split = value.toString().split(",");
if("d01".equals(split[2])){
//部门编号为d01,留下
context.write(value, NullWritable.get());
}else{
return;
}
}
}
- 自定义主类
package wyh.test;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.net.URI;
public class ETLJobMain extends Configured implements Tool {
@Override
public int run(String[] strings) throws Exception {
Job job = Job.getInstance(super.getConf(), "testETLJob");
//!!!!!!!!!! 集群必须要设置 !!!!!!!!
job.setJarByClass(ETLJobMain.class);
//配置job具体要执行的任务步骤
//指定要读取的文件的路径,这里写了目录,就会将该目录下的所有文件都读取到(这里只需要放employee.txt即可)
FileInputFormat.setInputPaths(job, new Path("D:\\test_hdfs"));
//指定map处理逻辑类
job.setMapperClass(ETLMapper.class);
//指定map阶段输出的k2类型
job.setMapOutputKeyClass(Text.class);
//指定map阶段输出的v2类型
job.setMapOutputValueClass(NullWritable.class);
//由于map端已经把预期的输出结果处理好了,不需要reduce端再处理,所以这里设置reduceTask个数为0
job.setNumReduceTasks(0);
//指定结果输出路径,该目录必须是不存在的目录(如已存在该目录,则会报错),它会自动帮我们创建
FileOutputFormat.setOutputPath(job, new Path("D:\\testETLouput"));
//返回执行状态
boolean status = job.waitForCompletion(true);
//使用三目运算,将布尔类型的返回值转换为整型返回值,其实这个地方的整型返回值就是返回给了下面main()中的runStatus
return status ? 0:1;
}
public static void main(String[] args) throws Exception {
Configuration configuration = new Configuration();
/**
* 参数一是一个Configuration对象,参数二是Tool的实现类对象,参数三是一个String类型的数组参数,可以直接使用main()中的参数args.
* 返回值是一个整型的值,这个值代表了当前这个任务执行的状态.
* 调用ToolRunner的run方法启动job任务.
*/
int runStatus = ToolRunner.run(configuration, new ETLJobMain(), args);
/**
* 任务执行完成后退出,根据上面状态值进行退出,如果任务执行是成功的,那么就是成功退出,如果任务是失败的,就是失败退出
*/
System.exit(runStatus);
}
}
- 运行程序并查看结果
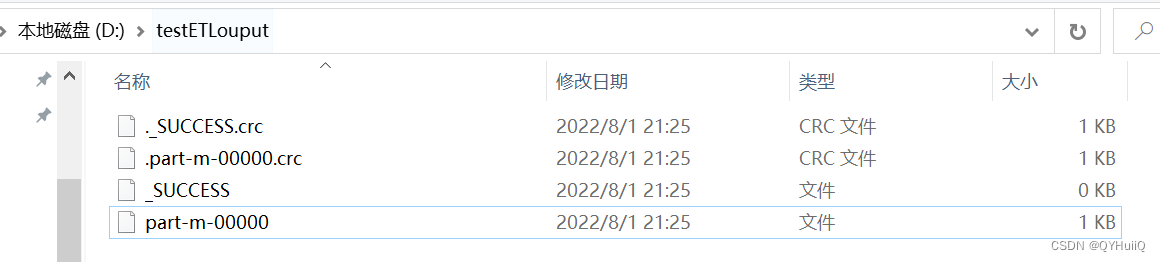
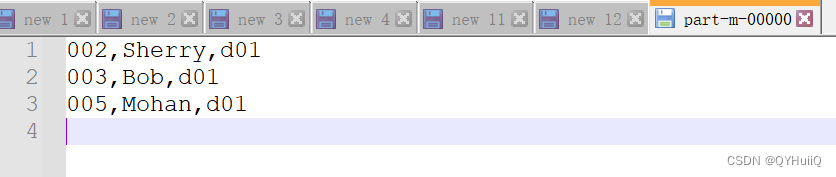
可以看到只有部门为d01的数据留下来了,符合预期结果。
这样就简单地实现了ETL中地数据清洗过程。
边栏推荐
猜你喜欢

白帽黑客与留守儿童破壁对“画”!ISC、中国光华科技基金会、光明网携手启动数字安全元宇宙公益展

聊天app开发——防炸麦以及节省成本的内容鉴定方法

QT with OpenGL(HDR)
ECCV2022 | RU&谷歌:用CLIP进行zero-shot目标检测!

迅为IMX6开发板QT系统创建AP热点基于RTL8723交叉编译hostapd

APENFT FOUNDATION官宣2022艺术梦想基金主题征集

投稿有礼,双社区签约博主名额等你赢!

消费者认可度较高 地理标志农产品为啥“香”

Leecode-SQL 1527. 模糊查询匹配(模糊查询用法)
LeetCode_多叉树_中等_429.N 叉树的层序遍历
随机推荐
科普大佬说 | 黑客帝国与6G有什么关系?
507. 完美数
混合型界面:对话式UI的未来
Pixel mobile phone system
开源一夏 | 教你快速实现“基于Docker快速构建基于Prometheus的MySQL监控系统”
如何检索IDC研究报告?
OS层面包重组失败过高,数据库层面gc lost 频繁
【Star项目】小帽飞机大战(九)
历史拉链数据处理有人做过吗
怎么在外头使用容器里php命令
嵌入式软件组件经典架构与存储器分类
创建C UDR时,指定的HANDLESNULLS的作用是什么?
优炫数据库在linux平台下服务启动失败的原因
后台图库上传功能
三大产品力赋能欧萌达OMODA5
迅为IMX6开发板QT系统创建AP热点基于RTL8723交叉编译hostapd
Apache Doris系列之:数据模型
MATLAB programming and application 2.7 Structural data and unit data
投稿有礼,双社区签约博主名额等你赢!
2022.8.2-----leetcode.622