stay CVPR2022 On , Shanghai University of science and technology and xiaohongshu multimodal algorithm team jointly proposed a novel action sequence verification task , It aims to verify whether the action sequences presented in the two videos are consistent . It is different from traditional video tasks that focus on a single action , We believe that a complex task needs a sequence of steps composed of multiple actions to complete , And these steps follow certain internal relations and influence each other .
This task can be applied to automatic scoring in the field of entertainment or sports . For example, in a diving competition , It can be detected according to the comparison with the standard video , Score the players' movements . For xiaohongshu, a business scenario with diversified note taking modes , This method is applied to video content 、 The understanding of the action process will help the platform to recommend relevant notes for users more accurately .

Thanks to the popularity of various video platforms and shooting equipment in recent years , Video data is springing up , It also provides an important data base for the study of video understanding . We found that , Most of the daily activities recorded in videos are completed through a series of steps rather than a single action . For this kind of video , We propose an action sequence verification task , The purpose is to distinguish between a positive video pair that performs the same action sequence and a negative video pair that has sub action level differences but still performs the same task , As shown in the figure below .

Such a challenging task can deal with the open set problem , And no event level or even frame level annotation supervised action detection or segmentation is required to provide prior knowledge .
This task can be applied to sports 、 Automatic scoring in the entertainment field , Or standard process detection in industrial production scenarios .

We designed a new script data set ,Chemical Sequence Verification (CSV) To support this mission .CSV It records many operation processes in the chemical experiment scene from the first person perspective , It fully includes all kinds of sub action level changes ( The increase of sub actions 、 defect 、 Disorder ), It can form a sufficient number of positive and negative sample pairs , Therefore, it is consistent with our task . The dataset contains about 2000 A video ,100 Residual steps ,18 Atomic like actions , With sufficient movement diversity . Refer to figure 1 for data examples . The following figure for CSV The proportion of various atomic actions and the distribution of video duration .

besides , We are right. COIN[2] and Diving48[3] Re planning , Make its annotation and segmentation more in line with our settings , We call the data set after re planning COIN-SV And Diving48-SV.

High requirements for step level differences in process validation tasks , We have put forward CosAlignment Transformer (CAT), From the overall process 、 Local steps are used to supervise model training from multiple angles .

Intra-step module: For each sampling frame, output the frame level characteristic graph , Extract sub action level features .
Inter-step module: Reference resources ViT [1] Methods , utilize Transformer Encoder To model the temporal relationship between sub actions , Get the global features of the video .
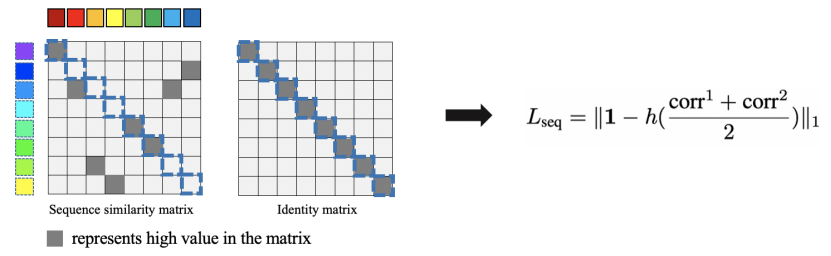
Alignment module: It is not enough to focus on the global features of the video , Our task focuses more on the difference of sub action levels between video pairs , So we propose sequence alignment loss (Sequence Alignment Loss) Align two feature map sequences from a positive video pair , It is required that the sub actions in the two input videos can correspond to each other in time sequence .

As a newly proposed task , There was no prior approach specifically for this task , Considering the similarity between our method and motion recognition method , And it is also trained with multi category classification tasks , In the experiment, we compare it with the traditional motion recognition algorithm .

Experiments show that our method surpasses the traditional motion recognition algorithm on the three data sets .

The above figure shows the results of Ablation Experiment , The left figure proves TE(Transformer Encoder) And SA(Sequence Alignment) The positive effect of the module on the quantitative results ; The visualization of the right figure and the intra class and inter class errors of different models prove that TE and SA The module is useful to refine the steps in the resolution process .

This task can be used for entertainment / Automatic scoring in the field of sports . Given a standard video , With multiple videos to be rated , According to the similarity of the two videos in the feature space, the scoring results are given .

Or abnormal action detection in the standardized process , When an action that is significantly different from the standard process occurs , The distance between the two videos in the feature space began to soar , At this point, we can stop the operation , To some extent, avoid the danger caused by non-standard actions .



This paper proposes a new action sequence verification task to judge whether the action sequences in two videos are consistent , It has a broad application prospect . For this task , We designed and collected the chemical experiment flow data set including the transformation of each seed action level CSV, A simple and effective flow verification algorithm is proposed CAT, Experiments show that it is superior to the existing methods .
This method can not only be directly used in the task of video sequence verification , It can also be used as a pre training model , For video retrieval , Video classification and other downstream tasks , Search in the video , Recommendation and other industrial application scenarios .
[1] Dosovitskiy A, Beyer L, Kolesnikov A, et al. An image is worth 16x16 words: Transformers for image recognition at scale[J]. arXiv preprint arXiv:2010.11929, 2020.
[2] Tang Y, Ding D, Rao Y, et al. Coin: A large-scale dataset for comprehensive
instructional video analysis[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2019: 1207-1216.
[3] Li Y, Li Y, Vasconcelos N. Resound: Towards action recognition without representation bias[C]//Proceedings of the European Conference on Computer Vision (ECCV). 2018: 513-528.

Qian Yicheng
Little Red Book Multimodal algorithm Team Intern , Now studying at Shanghai University of science and technology SVIP Lab, I studied under Professor gaoshenghua .
Main research direction : Video action understanding .
Tang Shen
Little red book team leader of multimodal Algorithm .
CVPR、ECCV、ICCV、TIFS、ACMMM And so on 20 Papers . Refresh many times WiderFace and FDDB International list world record ,ICCV Wider Challenge Champion of the international face detection competition ,ICCV VOT Single target tracking champion ,CVPR UG2+ runner-up .

Computer vision (CV) Algorithm engineer / The intern
1. Develop and deploy deep learning 、 Image video understanding 、 Multimode fusion 、 Large scale information retrieval 、 Content understanding and other advanced algorithms , Achieve industry-leading performance indicators .
2. Responsible for the research and development of computer vision related algorithms , For but not limited to : Multimodal classification 、 Fine grained classification 、 Face recognition 、 object detection 、 Division 、Metric Learning etc. , moment follow And explore cutting-edge technologies .
3. Responsible for the research and development of computer vision related projects , For but not limited to : Model lightweight 、 Vector recall engine 、 Sorting and other low-level optimization , Need to master C++.
4. Responsible for continuous iteration and evolution of relevant algorithms and systems ; At the same time, it can go deep into the rich business scenarios of little red book , Carry out technology implementation and innovation in combination with actual needs .
5. Complete the rapid implementation of the algorithm and large-scale industrial deployment , Participate in the research and development of innovative algorithms .
原网站版权声明
本文为[InfoQ]所创,转载请带上原文链接,感谢
https://yzsam.com/2022/172/202206211232319595.html