当前位置:网站首页>MySQL - master-slave replication
MySQL - master-slave replication
2022-07-26 00:18:00 【Yan Zi】
MySQL—— Master slave copy
1、 Master slave replication overview
1.1 How to improve database concurrency
In practice , We often Redis As cache and MysQL Use together , When there is a request , First, it will look up from the cache , If it exists, take it out directly . If it doesn't exist, access the database again , This is the way to improve Read efficiency , It also reduces the need for back-end databases Access pressure .Redis The cache architecture is High concurrency architecture A very important part of .
Besides , General applications are for databases “ Read more and write less " In other words, the pressure on the database to read data is relatively large , One idea is to adopt the scheme of database cluster , do Master slave architecture 、 Read and write separation , This can also improve the concurrent processing ability of the database . But not all applications need to set the master-slave architecture of the database , After all, setting up the architecture itself has a cost .
If our goal is to improve the efficiency of highly concurrent database access , So the first consideration is how to Optimize SQL And index , It's simple and effective ; The second is to adopt Caching strategy , For example, use Redis Save hotspot data in memory database , Improve the efficiency of reading ; The last step is to adopt Master slave architecture , Read and write separation .
Optimize according to the above method , The cost of use and maintenance is from low to high .
1.2 The role of master-slave replication
The master-slave synchronization design not only improves the throughput of the database , And the following 3 All aspects of the role .
The first 1 A role : Read / write separation . We can use master-slave replication to Synchronous data , Then improve the concurrent processing ability of the database through the separation of reading and writing .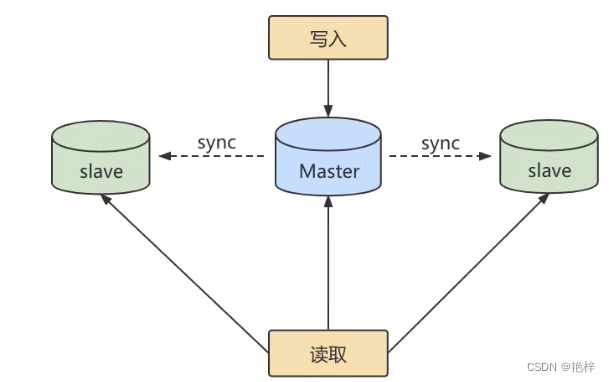
One of them is Master Main library , Write data , We call it : Write library .
Everything else is slave Slave Library , Read data , We call it : Read the library .
When the main database is updated , The data is automatically copied to the slave library , And when we read data from the client , Will read from the library . face “ Read more and write less " The needs of , Using read-write separation , Can achieve Higher concurrent access . meanwhile , We can also configure the slave server Load balancing , Let different read requests be evenly distributed to different slave servers according to policies , Give Way Reading is smoother . Another reason for smooth reading , Namely Reduced locking table Influence , For example, we let the main library be responsible for writing , When a write lock occurs in the main database , It will not affect the processing from the library SELECT The read .
The first 2 One function is data backup ." We copy the data from the master database to the slave database through master-slave replication , It is equivalent to a hot backup mechanism , That is, when the main database is running normally , Will not affect the service .
The first 3 One function is high availability . Data backup is actually a redundant mechanism , This redundancy can be exchanged for the high availability of the database , That is, when the server appears Failure or downtime Under the circumstances , Sure Switch To slave server , Ensure the normal operation of the service .
About the degree of high availability , We can measure it with one indicator , That is, the normal available time / Throughout the year . For example, to reach the whole year 99.999% All available time , This means that the system cannot be used for more than 365*24*60*(1-99.999%)=5.256 minute ( Including the time of system crash 、 Downtime caused by daily maintenance operation, etc ), It needs to be available at other times .
actually , Higher availability , It means a higher cost . In reality, we need to combine business needs and costs to make choices .
2 The principle of master-slave replication
slave From Master Read binlog To synchronize data .
2.1 Principle analysis
Three threads
In fact, the principle of master-slave synchronization is based on binlog For data synchronization . In the master-slave replication process , Will be based on 3 Threads To operate , A main library thread , Two slave threads .
Binary log dump thread (Binlog dump thread) It's a main library thread . When connecting from the library thread , The master library can send the binary log to the slave library , When the main library reads Events (Event) When , Will be in Binlog On Lock , After the read is complete , Release the lock .
Slave Library I/O Threads Will connect to the main library , Send request update to main library Binlog. At this point from the library I/O The thread can read the binary log of the main library and dump the data sent by the thread Binlog Update section , And copy it to the local relay log (Relay log) .
Slave Library SQL Threads The relay log from the library is read , And execute the events in the log , Keep the data in the slave library synchronized with the master library .


Copy three steps :
step 1: Master Log writes to binary log ( binlog ). These records are called Binary log events (binary log events);
step 2: slave take Master Of binary log events Copy to its relay logs ( relay log )
step 3: Slave Redo events in relay log , Apply the changes to your own database .MySQL Replication is asynchronous and serialized , And restart from Access point Start copying .
The problem of replication
The biggest problem with replication is : Time delay
2.2 The basic principle of reproduction
- Every
Slaveonly oneMaster - Every
SlaveThere can only be one uniqueThe server ID - Every
MasterThere can be multipleSlave
3、 One master and one slave architecture
One host is used to process all write requests , A slave is responsible for all read requests , The architecture is as follows :
3.1 preparation 
3.2 Host configuration file 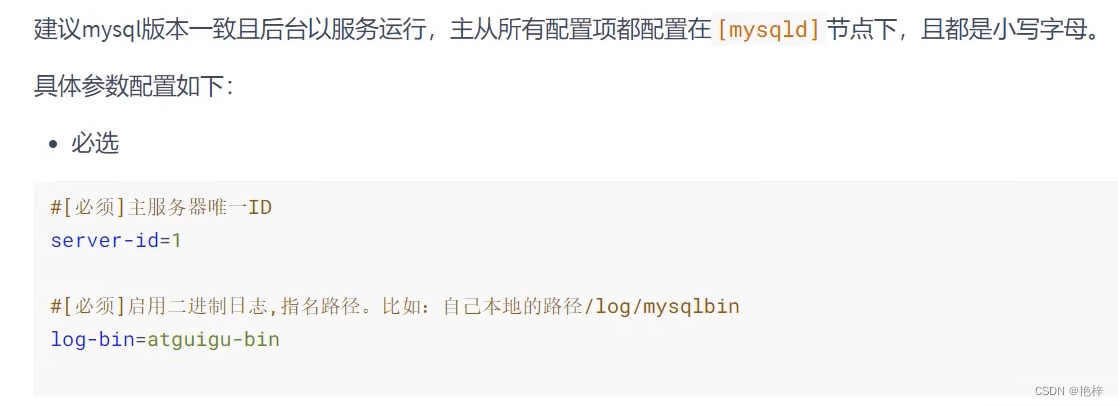

Restart the background mysql service , Make configuration effective .

3.3 Slave configuration 
3.4 host : Establish an account and authorize 


3.5 Slave : Configure the host to be replicated 


The above figure shows that the master-slave construction is successful .
4 Synchronization data consistency problem
Requirements for master-slave synchronization :
- The data of read library and write library are consistent ( Final agreement );
- Write data must be written to the write library ;
- To read data, you must go to the Reading Library ( not always );
How to solve the problem of consistency
If the data of the operation is stored in the same database , So when updating the data , You can write lock the record , In this way, data inconsistency will not occur when reading . But at this time, the function of slave library is Backup , It didn't work Read / write separation , Share the main library Reading pressure The role of .
In the case of separation of reading and writing , Solve the problem of inconsistent data in master-slave synchronization , Is to solve the problem between master and slave Data replication The problem of , If data consistency is followed from Weak to strong To divide , There are the following 3 Two replication methods .
Method 1: Asynchronous replication
Asynchronous mode is client submission COMMIT There is no need to wait for any results to be returned from the library , Instead, the results are returned directly to the client , The advantage of this is that it will not affect the efficiency of the main library , But there may be a main library outage , and Binlog It's not synchronized to the slave library yet , That is to say, the data of master database and slave database are inconsistent at this time . At this point, select one from the library as the new master , Then the new master may lack the committed transactions in the original master server . therefore , Data consistency in this replication mode is the weakest .
Method 2: Semi-synchronous replication
MySQL5.5 Semi synchronous replication is supported after version . The principle is to submit COMMIT After that, the result is not directly returned to the client , It's waiting for at least one to receive from the library Binlog, And write it to the relay log , And back to the client .
The advantage of this is to improve the consistency of the data , Of course, compared to asynchronous replication , At least one more network connection delay , It reduces the efficiency of the main library .
stay MySQL5.7 The version also adds a rpl_semi.syncmaster.wait.for_slave_count Parameters , You can set the number of slave libraries answered , The default is 1, That is to say, as long as there is 1 A slave library responded , You can return to the client . If you increase this parameter , It can improve the strength of data consistency , But it will also increase the time for the master database to wait for the response from the slave database .
Method 3: Group replication
Neither asynchronous replication nor semi synchronous replication can ultimately ensure data consistency , Semi synchronous replication determines whether to return to the client by judging the number of responses from the library , Although data consistency is improved compared with asynchronous replication , However, it is still unable to meet the scenarios with high requirements for data consistency , For example, in the financial sector .MGR It makes up for the shortcomings of these two replication modes .
Group replication technology , abbreviation MGR(MySQL Group Replication). yes MySQL stay 5.7.17 A new data replication technology introduced in version , This replication technology is based on Paxos Protocol state machine replication .
MGR How it works
First, we form a replication group with multiple nodes , stay Perform reading and writing 《RW) Business When , Need to pass the consistency protocol layer (Consensus layer ) Consent of , That is, the read-write transaction wants to commit , You have to go through the group “ Most people ”( Corresponding Node node ) Consent of , Most mean that the number of agreed nodes needs to be greater than (N/2+1), In this way, you can submit , Instead of the original sponsor has the final say. . And for the read-only (RO) Transactions do not need to be approved by the Group , direct COMMIT that will do .
There are multiple nodes in a replication group , Each maintains its own copy of the data , Atomic messages and globally ordered messages are implemented in the consistency protocol layer , So as to ensure the consistency of data in the group .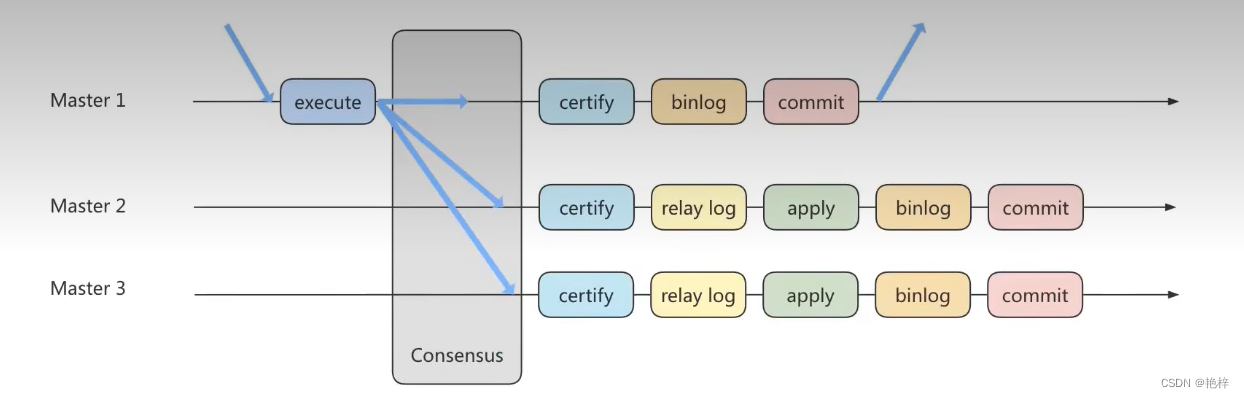
MGR take MysQL Into the era of strong data consistency , It is an epoch-making innovation , One of the important reasons is MGR Is based on Paxo$ Agreed .Paxos The algorithm is based on 2013 The winner of the Turing prize in Leslie Lamport On 1990 Put forward in , The decision-making mechanism of this algorithm can be searched . in fact ,Paxos After the algorithm was proposed, it was widely used as a distributed consistency algorithm , such as Apache Of ZooKeeper Is based on Paxos Realized .
边栏推荐
- LDP related knowledge
- Binary tree -- 222. Number of nodes of a complete binary tree
- “群魔乱舞”,牛市是不是结束了?2021-05-13
- 一个List到底能存多大的数据呢?
- After using MQ message oriented middleware, I began to regret
- Redirection and request forwarding
- [brother hero July training] day 24: linear tree
- 白蛋白纳米粒表面修饰低分子量鱼精蛋白LMWP/PEG-1900修饰牛血清白蛋白制备研究
- Js理解之路:Object.call与Object.create()实现继承的原理
- CountDownLatch
猜你喜欢

Redirection and request forwarding

J9 number theory: what is Dao mode? Obstacles to the development of Dao

OPENCV学习DAY6

MWEC:一种基于多语义词向量的中文新词发现方法
寻找命令find和locate

关于“DBDnet: A Deep Boosting Strategy for ImageDenoising“一文理解

Pinduoduo gets the usage instructions of the product details API according to the ID

Leetcode169 detailed explanation of most elements

栈的表示和实现(C语言)

IP核:PLL
随机推荐
Bond network card mode configuration
nodejs启动mqtt服务报错SchemaError: Expected `schema` to be an object or boolean问题解决
【redis】③ 数据淘汰策略、pipeline 管道命令、发布订阅
Binary tree - 110. Balanced binary tree
Binary tree - 404. Sum of left leaves
Redirection and request forwarding
VMware ESXI7.0版本的安装与配置
12.神经网络模型
Leetcode high frequency question 66. add one, give you an array to represent numbers, then add one to return the result
OPENCV学习DAY6
JSON data development
Stack and queue - 347. Top k high frequency elements
bond网卡模式配置
【论文笔记】—目标姿态估计—EPro-PnP—2022-CVPR
基于网络分析和文本挖掘的意见领袖影响力研究
京东按关键字搜索商品 API 的使用说明
牛血清蛋白修饰酚酸类及生物碱类小分子/偶联微球的蛋白/牛红细胞SOD的研究
Prometheus operation and maintenance tool promtool (II) query function
Getaverse,走向Web3的远方桥梁
Find the intermediate node of the linked list