当前位置:网站首页>MySQL数据库实战(1)
MySQL数据库实战(1)
2022-08-03 10:41:00 【wrdoct】
一、数据库概述
(1)sql、DB、DBMS分别是什么,他们的关系?
DB:DataBase(数据库,数据库实际上在硬盘上以文件的形式存在)。
DBMS:DataBase Management System(数据库管理系统,常见的有:MySQL, Oracle, DB2, Sybase, SqlServer…)。
SQL:结构化查询语言,是一门标准通用的语言。标准的sql适合于所有的数据库产品。SQL属于高级语言。SQL语句在执行的时候,实际上内部也会先进行编译,然后再执行sql。(sql语句的编译由DBMS完成)。
DBMS负责执行sql语句,通过执行sql语句来操作DB当中的数据。
DBMS - (执行)->SQL -(操作)->DB
(2)什么是表?
表:table
是数据库的基本组成单元,所有的数据都以表格的形式组织,目的是可读性强。
【注】一个表包括行和列:
行:被称为数据/记录(data)
列:被称为字段(column)
(3)每一个字段应该包括哪些属性?
字段名、数据类型、相关的约束。
【注】数据类型:int、varchar、bigint…
(4)学习MySQL主要还是学习通用的SQL语句,包括增删改查,那么SQL怎么分类?
DQL(数据查询语言):查询语句,凡是select语句都是DQL。
DML(数据操作语言):insert、delete、update,对表当中的数据进行增删改。
DDL(数据定义语言):create、drop、alter,对表结构的增删改。
TCL(事务控制语言):commit提交事务,rollback回滚事务。
DCL(数据控制语言):grant授权、revoke撤销权限等。
(5)导入数据:
第一步:登录mysql数据库管理系统
命令:mysql -uroot -p
第二步:查看有哪些数据库
命令:show databases;
【注】这个不是SQL语句,属于MySQL的命令。
第三步:创建属于我们自己的数据库
命令:create database start;
【注】这个不是SQL语句,属于MySQL的命令。
第四步:使用start数据
命令:use start;
【注】这个不是SQL语句,属于MySQL的命令。
第五步:查看当前使用的数据库中有哪些表?
命令:show tables;
【注】这个不是SQL语句,属于MySQL的命令。
第六步:初始化数据
命令:source sql脚本;
【注】sql脚本:一个文件,以sql结尾,该文件中编写了大量的sql语句。使用source命令执行sql脚本。
(6)删除数据库 :drop database start;
(7)查看表结构:desc 表名;
(8)常用命令:
select database(); #查看当前使用的是哪个数据库
select version(); #查看mysql的版本号
\c #结束一条语句
exit #退出mysql
show create table 表名; #查看创建表的语句
二、简单查询、条件查询、模糊查询
(1)简单的查询语句(DQL):
语法格式:
select 字段名1,字段名2,......from 表名;
select 字段名1,字段名2,... as ... from 表名;
【注】任何一条sql语句以“;”结尾。
sql语句不区分大小写。
标准sql语句中要求字符串(汉字)(varchar)使用单引号。
查询所有字段:select * from 表名;
(2)条件查询
条件查询需要用到where语句,where必须放到from语句表的后面。
语法格式:
select 字段名1,字段名2,......from 表名 where 条件;
【注】条件:between ... and ...; 必须左小右大,可以使用在数字方面,也可以使用在字符串方面,为左闭右开。
【注】在数据库中,NULL不是一个值,代表什么也没有,为空(空不是一个值,不能用等号衡量,必须使用 is null 或者 is not null)。
【注】当运算符的优先级不确定的时候加小括号。
【注】in 等同于 or 。(in的后面是具体的值,不是区间)
(3)模糊查询like
在模糊查询中,必须掌握两个特殊的符号:一个是%,一个是_。% 代表任意多个字符,_代表任意1个字符。
【注】在%和_前面加上转义字符\,表示一个普通的%和_。
三、排序数据(升序、降序)
(1)默认是升序。若要指定:asc表示升序,desc表示降序。
select ... from ... order by ... asc, ... desc;
【注】越靠前的字段越能起到主导作用。只有当前面的字段无法完成排序的时候,才会启动后面的字段进行排序。
select ... from ... order by 1; #表示按照第1列的先后顺序进行排序
select ... from ... order by 4; #表示按照第4列的先后顺序进行排序
四、分组函数/聚合函数/多行处理函数
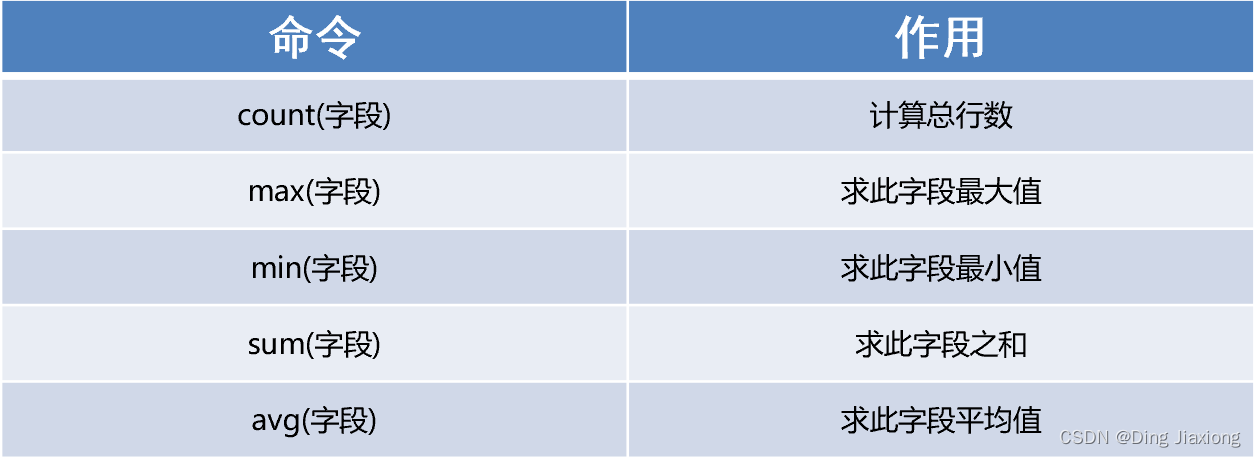
(1)分组函数一共5个。又叫:多行处理函数(输入多行输出一行)。
count 计数
sum 求和
avg 平均值
max 最大值
min 最小值
【注】所有分组函数都是对“某一组”数据进行操作的。
【注】分组函数自动忽略NULL。
(2)单行处理函数:输入一行输出一行。
【注】数据库中只要有NULL参与运算,最终结果一定是NULL。
ifnull(可能为NULL的数据, 被当做什么来处理); #属于单行处理函数
(3)使用分组函数时的注意事项:
分组函数不可以直接使用在where子句当中。
因为group by是在where执行之后才会执行,而分组函数必须在分组之后才能执行。
即:如果分组函数直接使用在where子句当中,代表还没有分组就执行了分组函数。
(4)count(*)和count(具体的某个字段)有什么区别?count(*):不是统计某个字段中数据的个数,而是统计总记录条数(与字段没关系);count(具体的某个字段):表示统计该字段中不为NULL的数据总数量。
(5)分组函数也能组合起来使用。
五、分组查询
(1)group by 和 havinggroup by :按照某个字段或某些字段进行分组;having:对分组之后的数据进行再次过滤。
select ... from 表名 group by ... having 条件; #效率较低
select ... from 表名 where 条件 group by ...; #效率较高(能使用where尽量使用where)
【注】分组函数一般都会和group by联合使用,这也是为什么它被称为分组函数的原因。
并且任何一个分组函数都是在group by语句执行结束之后才会执行的。
当一条sql语句没有group by的话,整张表的数据会自成一组。
(2)规则:当一条sql语句中出现group by时,select后面只能跟分组函数和参与分组的字段。
(3)多个字段联合分组:
select ... from ... group by 字段1, 字段2;
(4)一个完整的DQL语句:
函数的书写顺序和执行顺序:
select 5
...
from 1
...
where 2
...
group by 3
...
having 4
...
order by 6
...
六、关于查询结果集的去重
select distinct 字段 from 表名; # distinct 关键字
【注】distinct 只能出现在所有字段的最前面,表示后面所有的字段联合起来进行去重。
七、连接查询
(1)在实际开发中,大部分情况下都不是从单表中查询数据,一般都是多张表联合查询取出最终的结果。
(2)连接查询的分类:
根据年代划分:SQL92、SQL99。
根据表的连接方式来划分:
内连接:等值连接、非等值连接
外连接:左外/左连接、右外/右连接
全连接:
(3)笛卡尔积现象:当两张表进行连接查询时,没有过滤/条件限制,最终的连接查询结果会是两张表记录条数的乘积。
【注】避免笛卡尔积现象:加条件进行过滤。
但是不会减少记录的匹配次数,只不过显示的是有效记录(不会提高执行效率)。
【注】表的别名:执行效率高,可读性好。
(4)内连接之等值连接:
最大的特点:条件是等量关系。
#SQL92 (太老,不用了)
select e.ename, d.dname from emp e, dept d where e.deptno = d.deptno;
#SQL99 (常用的) (表的连接条件和where的数据过滤条件分离了,结构清晰)
#语法: ...A join B on 连接条件 where ...
select e.ename, d.dname from emp e join dept d on e.deptno = d.deptno;
select e.ename, d.dname from emp e inner join dept d on e.deptno = d.deptno; #inner可以省略,带着的话可读性好一些
(5)内连接之非等值连接:
最大的特点:条件是非等量关系。
(6)自连接:
最大的特点:一张表看做两张表,自己连接自己。
(7)外连接:
什么是外连接?和内连接的区别?
内连接:
假设A表和B表进行连接,使用内连接的话,凡是A表和B表能够匹配上的记录查询出来,这就是内连接。
A、B两张表没有主副之分,两张表是平等的。
外连接:
假设A表和B表进行连接,使用外连接的话,A、B两张表中有一张表是主表,一张表是副表,
主要查询主表当中的数据,捎带着查询副表,
当副表当中的数据没有和主表中的数据匹配上,副表自动模拟出NULL与之匹配。
外连接的分类?
左外/左连接:左边的这张表是主表;
右外/右连接:右边的这张表是主表。
左连接有右连接的写法,右连接也会有对应的左连接的写法。
#outer可以省略
select 表名 from ... left join ... on ...; #左连接 from后面的是左边的 主表
select 表名 from ... left outer join ... on ...; #左连接 from后面的是左边的 主表
select 表名 from ... right join ... on ...; #右连接 join后面的是右边的 主表
select 表名 from ... right outer join ... on ...; #右连接 join后面的是右边的 主表
【注】区分内连接和外连接的主要区别是left和right。
【注】外连接最重要的特点是:主表的数据无条件的全部查询出来。
(8)全连接
(9)三张表的连接查询
...
A
join
B
join
C
on
...
【注】navicat工具箱:可以更方便的操作MySQL。
边栏推荐
- 孙宇晨式“溢价逻辑”:不局限眼前,为全人类的“星辰大海”大胆下注
- MySQL 如何修改SQL语句,去掉语句中的or
- 数字藏品和ICP
- 集成学习、boosting、bagging、Adaboost、GBDT、随机森林
- With strong network, China mobile to calculate excitation surging energy network construction
- MATLAB programming and application 2.7 Structural data and unit data
- 面试官:工作两年了,这么简单的算法题你都不会?
- 什么是IDE?新手用哪个IDE比较好?
- C#+WPF 单元测试项目类高级程序员必知必会
- Unity笔记之简陋的第一人称漫游
猜你喜欢


随机推荐
Boolean 与numeric 无法互转
罕见的数学天才,靠“假结婚”才得到追求事业的机会
MATLAB programming and application 2.7 Structural data and unit data
有大佬用flink读取mysql binlog分表后再写入新表吗
三大产品力赋能欧萌达OMODA5
消费者认可度较高 地理标志农产品为啥“香”
如何优雅的消除系统重复代码
STM32入门开发 介绍SPI总线、读写W25Q64(FLASH)(硬件+模拟时序)
gbase在轨道交通一般都采用哪种高可用架构?
Matplotlib
Recursive training
Who is more popular for hybrid products, depending on technology or market?
鸿蒙第四次
机器学习(公式推导与代码实现)--sklearn机器学习库
进入 SQL Client 创建 table 后,在另外一个节点进入 SQL Client 查询不到
集成学习、boosting、bagging、Adaboost、GBDT、随机森林
混动产品谁更吃香,看技术还是看市场?
GBase 8c与openGauss是什么关系?
How to deal with this time of MySQL binlog??
servlet生命周期详解--【结合源码】