当前位置:网站首页>pytorch分类问题总结
pytorch分类问题总结
2022-06-10 23:56:00 【qq_45759229】
参考
https://blog.csdn.net/qq_39172845/article/details/123361945
iris数据集
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_iris
X,Y=load_iris(return_X_y=True)
# iloc按位置取值
print('X.shape:',X.shape)
print('Y.shape:',Y.shape)
from sklearn.model_selection import train_test_split
train_X,test_X,train_Y,test_Y = train_test_split(X,Y)
# 出现报错,RuntimeError:expected scaler type Long but found Float
# 这是,我们希望目标的数据类型是long tensor(int tensor),而不是float tensor。
# 目标值是0、1、2这种形式,要求是一个long tensor,64位的整形。
# ndarray转换为tensor
train_X = torch.from_numpy(train_X).type(torch.float32)
# train_Y = torch.from_numpy(train_Y).type(torch.float32)
train_Y = torch.from_numpy(train_Y).type(torch.int64)
test_X = torch.from_numpy(test_X).type(torch.float32)
# test_Y = torch.from_numpy(test_Y).type(torch.float32)
test_Y = torch.from_numpy(test_Y).type(torch.LongTensor)
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
batch = 8 #批次大小
train_ds = TensorDataset(train_X,train_Y) # Dataset
train_dl = DataLoader(train_ds,batch_size=batch,shuffle=True) # DataLoader
test_ds = TensorDataset(test_X,test_Y)
test_dl = DataLoader(test_ds,batch_size=batch) # 对于测试数据没有必要做shuffle
import torch.nn.functional as F
from torch import nn
class Model(nn.Module):
def __init__(self):
#首先要继承父类中所有的变量
super().__init__()
# 开始初始化所有的层
self.linear1 = nn.Linear(4,32 ) # 第一个线性层。将输入的4个特征输出到64个特征的隐藏层。
self.linear2 = nn.Linear(32,32)
self.linear3 = nn.Linear(32,3) # 输出层。因为是三分类,所以输出特征长度为3。
def forward(self,input):
# forward方法有一个input参数,你的输入是交给forward方法,然后forward方法调用这些层对输入数据处理。
# 线性层1,4 ---> 32
x1 = F.relu(self.linear1(input))
# 线性层2,32 ---> 32
x2 = F.relu(self.linear2(x1))
# 输出层,32 ----> 3
# x3 = F.sigmoid(self.linear3(x2)) # 用这个会有警告
# x3 = torch.sigmoid(self.linear3(x2))
x3 = self.linear3(x2)
return x3
""" 在输出层,我们不进行激活,因为我们这个是三分类,使用的损失函数是CrossEntropyLoss,它的输入是一个未激活的输出。 它会在函数内部进行一次 ...softmax 进行计算,然后与我们真实的概率分布计算一个损失。 所以在这里面是不需要对预测结果进行激活的。 如果不对预测结果进行激活,一样可以得到输出,使用softmax只是把它映射到了一个长度为1的概率分布上。 如果不激活,输出结果最大的值仍然是概率分布最高的值,也就是肯输出[1,50,2],虽然没有经过softmax进行激活, 但是它最大值所在的位置就明确指示了预测结果预测是几。 """
model = Model()
model

loss_fn = nn.CrossEntropyLoss() # 使用这个函数来计算softmax概率损失
# model(x)的输出是一个长度为3的张量,如何把预测值翻译成实际的预测结果呢?
# iter() 函数用来生成迭代器。next() 函数返回迭代器中的下一项。
input_batch,label_batch = next(iter(train_dl)) # 获得一个批次的数据
input_batch.shape # 结果是:torch.Size([8, 4])
label_batch.shape # 结果是:torch.Size([8])
y_pred = model(input_batch) # 返回8个长度为3的张量
y_pred


def accuracy(y_pred,y_true):
# y_true=y_true.int()
# y_true=y_true.long()
y_pred = torch.argmax(y_pred,dim=1)
acc = (y_pred == y_true).float().mean()
return acc
# 我们希望将每一次的epoch中的结果放入列表当中。
train_loss = []
train_acc = []
test_loss = []
test_acc = []
epochs = 500
opt = torch.optim.Adam(model.parameters(), lr=0.0001) # Adam优化器
for epoch in range(epochs): # 训练500次
for x,y in train_dl:
# y = torch.tensor(y,dtype=torch.long)
y_pred = model(x) # y_pred是经过sigmoid输出的一个介于0~1之间的值
loss = loss_fn(y_pred,y)
opt.zero_grad() # 将所有可训练参数的梯度置为0
loss.backward() # 反向传播
opt.step() # 优化参数
with torch.no_grad():
# 这一部分的计算不需要跟踪计算
epoch_acc = accuracy(model(train_X),train_Y) #每一个批次,对全部数据进行预测,得到的平均正确率
epoch_loss = loss_fn(model(train_X),train_Y).data
epoch_test_acc = accuracy(model(test_X),test_Y)
epoch_test_loss = loss_fn(model(test_X),test_Y).data
# 使用 .item 将单个的tensor输出值转化为了python的标量值
print("epoch:%d"%epoch)
print("loss:",round(epoch_loss.item(),3),",accuracy:",round(epoch_acc.item(),3))
print("test_loss:",round(epoch_test_loss.item(),3),",test_accuracy:",round(epoch_test_acc.item(),3))
print("——————————————————————————————")
train_loss.append(epoch_loss.item())
train_acc.append(epoch_acc.item())
test_loss.append(epoch_test_loss.item())
test_acc.append(epoch_test_acc.item())
plt.plot(range(1,epochs+1),train_loss,label='train_loss')
plt.plot(range(1,epochs+1),test_loss,label='test_loss')
plt.legend()
结果如下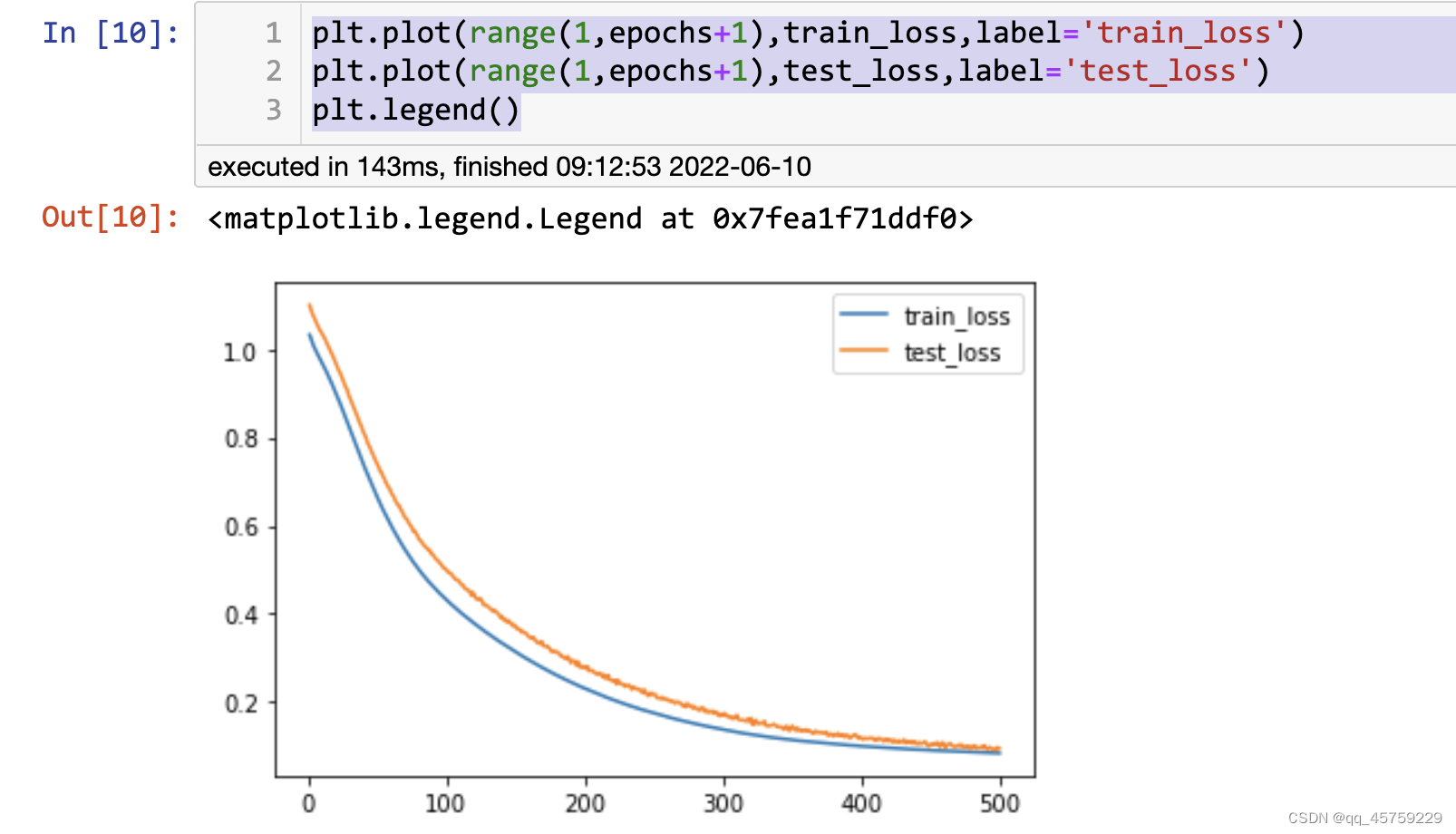
plt.plot(range(1,epochs+1),train_acc,label='train_acc')
plt.plot(range(1,epochs+1),test_acc,label='test_acc')
plt.legend()
结果如下
load digits训练集和验证集
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
X,Y=load_digits(return_X_y=True)
# iloc按位置取值
print('X.shape:',X.shape)
print('Y.shape:',Y.shape)
##############Normalization################
X=X/16.0
###########################################
from sklearn.model_selection import train_test_split
train_X,test_X,train_Y,test_Y = train_test_split(X,Y)
# 出现报错,RuntimeError:expected scaler type Long but found Float
# 这是,我们希望目标的数据类型是long tensor(int tensor),而不是float tensor。
# 目标值是0、1、2这种形式,要求是一个long tensor,64位的整形。
# ndarray转换为tensor
train_X = torch.from_numpy(train_X).type(torch.float32)
# train_Y = torch.from_numpy(train_Y).type(torch.float32)
train_Y = torch.from_numpy(train_Y).type(torch.int64)
test_X = torch.from_numpy(test_X).type(torch.float32)
# test_Y = torch.from_numpy(test_Y).type(torch.float32)
test_Y = torch.from_numpy(test_Y).type(torch.LongTensor)
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
batch = 32 #批次大小
train_ds = TensorDataset(train_X,train_Y) # Dataset
train_dl = DataLoader(train_ds,batch_size=batch,shuffle=True) # DataLoader
test_ds = TensorDataset(test_X,test_Y)
test_dl = DataLoader(test_ds,batch_size=batch) # 对于测试数据没有必要做shuffle
import torch.nn.functional as F
from torch import nn
class Model(nn.Module):
def __init__(self):
#首先要继承父类中所有的变量
super().__init__()
# 开始初始化所有的层
self.linear1 = nn.Linear(64,32) # 第一个线性层。将输入的4个特征输出到64个特征的隐藏层。
self.linear2 = nn.Linear(32,16)
self.linear3 = nn.Linear(16,10) # 输出层。因为是三分类,所以输出特征长度为3。
def forward(self,input):
x1 = F.relu(self.linear1(input))
x2 = F.relu(self.linear2(x1))
x3 = self.linear3(x2)
return x3
model = Model()
print(model)
loss_fn = nn.CrossEntropyLoss() # 使用这个函数来计算softmax概率损失
def accuracy(y_pred,y_true):
# y_true=y_true.int()
# y_true=y_true.long()
y_pred = torch.argmax(y_pred,dim=1)
acc = (y_pred == y_true).float().mean()
return acc
# 我们希望将每一次的epoch中的结果放入列表当中。
train_loss = []
train_acc = []
test_loss = []
test_acc = []
epochs = 200
opt = torch.optim.Adam(model.parameters(), lr=0.0001) # Adam优化器
for epoch in range(epochs): # 训练500次
for x,y in train_dl:
# y = torch.tensor(y,dtype=torch.long)
y_pred = model(x) # y_pred是经过sigmoid输出的一个介于0~1之间的值
loss = loss_fn(y_pred,y)
opt.zero_grad() # 将所有可训练参数的梯度置为0
loss.backward() # 反向传播
opt.step() # 优化参数
with torch.no_grad():
# 这一部分的计算不需要跟踪计算
epoch_acc = accuracy(model(train_X),train_Y) #每一个批次,对全部数据进行预测,得到的平均正确率
epoch_loss = loss_fn(model(train_X),train_Y).data
epoch_test_acc = accuracy(model(test_X),test_Y)
epoch_test_loss = loss_fn(model(test_X),test_Y).data
# 使用 .item 将单个的tensor输出值转化为了python的标量值
print("epoch:%d"%epoch)
print("loss:",round(epoch_loss.item(),3),",accuracy:",round(epoch_acc.item(),3))
print("test_loss:",round(epoch_test_loss.item(),3),",test_accuracy:",round(epoch_test_acc.item(),3))
print("——————————————————————————————")
train_loss.append(epoch_loss.item())
train_acc.append(epoch_acc.item())
test_loss.append(epoch_test_loss.item())
test_acc.append(epoch_test_acc.item())
fig=plt.figure()
plt.plot(range(1,epochs+1),train_loss,label='train_loss')
plt.plot(range(1,epochs+1),test_loss,label='test_loss')
plt.legend()
plt.show()
fig=plt.figure()
plt.plot(range(1,epochs+1),train_acc,label='train_acc')
plt.plot(range(1,epochs+1),test_acc,label='test_acc')
plt.legend()
plt.show()


load_digits 数据集(仅训练集)
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import load_digits
X,Y=load_digits(return_X_y=True)
# iloc按位置取值
print('X.shape:',X.shape)
print('Y.shape:',Y.shape)
##############Normalization################
X=X/16.0
###########################################
# ndarray转换为tensor
train_X = torch.from_numpy(X).type(torch.float32)
# train_Y = torch.from_numpy(train_Y).type(torch.float32)
train_Y = torch.from_numpy(Y).type(torch.int64)
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
batch = 32 #批次大小
train_dataset = TensorDataset(train_X,train_Y) # Dataset
train_dataloader = DataLoader(train_dataset,batch_size=batch,shuffle=True) # DataLoader
import torch.nn.functional as F
from torch import nn
class Model(nn.Module):
def __init__(self):
#首先要继承父类中所有的变量
super().__init__()
# 开始初始化所有的层
self.linear1 = nn.Linear(64,32) # 第一个线性层。将输入的4个特征输出到64个特征的隐藏层。
self.linear2 = nn.Linear(32,16)
self.linear3 = nn.Linear(16,10) # 输出层。因为是三分类,所以输出特征长度为3。
def forward(self,input):
x1 = F.relu(self.linear1(input))
x2 = F.relu(self.linear2(x1))
x3 = self.linear3(x2)
return x3
model = Model()
print(model)
loss_fn = nn.CrossEntropyLoss() # 使用这个函数来计算softmax概率损失
def accuracy(y_pred,y_true):
# y_true=y_true.int()
# y_true=y_true.long()
y_pred = torch.argmax(y_pred,dim=1)
acc = (y_pred == y_true).float().mean()
return acc
train_loss = []
train_acc = []
epochs = 200
opt = torch.optim.Adam(model.parameters(), lr=0.0001) # Adam优化器
for epoch in range(epochs): # 训练500次
for x,y in train_dataloader:
# y = torch.tensor(y,dtype=torch.long)
y_pred = model(x) # y_pred是经过sigmoid输出的一个介于0~1之间的值
loss = loss_fn(y_pred,y)
opt.zero_grad() # 将所有可训练参数的梯度置为0
loss.backward() # 反向传播
opt.step() # 优化参数
with torch.no_grad():
# 这一部分的计算不需要跟踪计算
epoch_acc = accuracy(model(train_X),train_Y) #每一个批次,对全部数据进行预测,得到的平均正确率
epoch_loss = loss_fn(model(train_X),train_Y).data
# 使用 .item 将单个的tensor输出值转化为了python的标量值
print("epoch:%d"%epoch)
print("loss:",round(epoch_loss.item(),3),",accuracy:",round(epoch_acc.item(),3))
print("——————————————————————————————")
train_loss.append(epoch_loss.item())
train_acc.append(epoch_acc.item())
fig=plt.figure()
plt.plot(range(1,epochs+1),train_loss,label='train_loss')
plt.legend()
plt.show()
fig=plt.figure()
plt.plot(range(1,epochs+1),train_acc,label='train_acc')
plt.legend()
plt.show()

mnist数据集
参考
https://nextjournal.com/gkoehler/pytorch-mnist
import torch
import torchvision
n_epochs = 3
batch_size_train = 64
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5
log_interval = 10
random_seed = 1
torch.backends.cudnn.enabled = False
torch.manual_seed(random_seed)
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('/Users/xiaokangyu/Desktop/dataset/DL/MNIST_digit/', train=True, download=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('/Users/xiaokangyu/Desktop/dataset/DL/MNIST_digit/', train=False, download=False,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
print(example_data.shape)
import matplotlib.pyplot as plt
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
train_losses = []
train_counter = []
test_losses = []
test_counter = [i*len(train_loader.dataset) for i in range(n_epochs + 1)]
def train(epoch):
network.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item())
train_counter.append(
(batch_idx*64) + ((epoch-1)*len(train_loader.dataset)))
torch.save(network.state_dict(), './results/model.pth')
torch.save(optimizer.state_dict(), './results/optimizer.pth')
def test():
network.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
test()
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
fig


with torch.no_grad():
output = network(example_data)
fig = plt.figure()
for i in range(6):
plt.subplot(2,3,i+1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Prediction: {}".format(
output.data.max(1, keepdim=True)[1][i].item()))
plt.xticks([])
plt.yticks([])
fig

重新加载训练
continued_network = Net()
continued_optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
model_pth='./results/model.pth'
optimizer_pth='./results/optimizer.pth'
network_state_dict = torch.load(model_pth)
continued_network.load_state_dict(network_state_dict)
optimizer_state_dict = torch.load(optimizer_pth)
continued_optimizer.load_state_dict(optimizer_state_dict)
for i in range(4,9):
test_counter.append(i*len(train_loader.dataset))
train(i)
test()

fig = plt.figure()
plt.plot(train_counter, train_losses, color='blue')
plt.scatter(test_counter, test_losses, color='red')
plt.legend(['Train Loss', 'Test Loss'], loc='upper right')
plt.xlabel('number of training examples seen')
plt.ylabel('negative log likelihood loss')
fig

mnist训练集和测试集
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
data=np.load("/Users/xiaokangyu/Desktop/dataset/DL/MNIST_digit/mnist.npz")
print(data["x_train"].shape) # (60000, 28, 28)
print(data["y_train"].shape) # (60000,)
print(data["x_test"].shape) # (10000, 28, 28)
print(data["y_test"].shape) # (10000,)
x_train=data["x_train"]
y_train=data["y_train"]
x_test =data["x_test"]
y_test =data["y_test"]
x_train=x_train.reshape(x_train.shape[0],-1) #reshape
x_test=x_test.reshape(x_test.shape[0],-1) #reshape
########## 最简单的标准化############
x_train=x_train/255.0
x_test=x_test/255.0
########## 最简单的标准化############
print(x_train.shape)
print(x_test.shape)
train_X=x_train.copy()
train_Y=y_train.copy()
test_X=x_test.copy()
test_Y=y_test.copy()
# from sklearn.model_selection import train_test_split
# train_X,test_X,train_Y,test_Y = train_test_split(X,Y)
# 出现报错,RuntimeError:expected scaler type Long but found Float
# 这是,我们希望目标的数据类型是long tensor(int tensor),而不是float tensor。
# 目标值是0、1、2这种形式,要求是一个long tensor,64位的整形。
# ndarray转换为tensor
train_X = torch.from_numpy(train_X).type(torch.float32)
# train_Y = torch.from_numpy(train_Y).type(torch.float32)
train_Y = torch.from_numpy(train_Y).type(torch.int64)
test_X = torch.from_numpy(test_X).type(torch.float32)
# test_Y = torch.from_numpy(test_Y).type(torch.float32)
test_Y = torch.from_numpy(test_Y).type(torch.LongTensor)
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
batch = 128 #批次大小
train_ds = TensorDataset(train_X,train_Y) # Dataset
train_dl = DataLoader(train_ds,batch_size=batch,shuffle=True) # DataLoader
test_ds = TensorDataset(test_X,test_Y)
test_dl = DataLoader(test_ds,batch_size=batch) # 对于测试数据没有必要做shuffle
import torch.nn.functional as F
from torch import nn
class Model(nn.Module):
def __init__(self):
#首先要继承父类中所有的变量
super().__init__()
# 开始初始化所有的层
self.linear1 = nn.Linear(784,256) # 不要写成768,我也不知道为啥我脑袋里会出现这个数字,可能是28*28我记错了
self.linear2 = nn.Linear(256,64)
self.linear3 = nn.Linear(64,10) # 输出层。因为是三分类,所以输出特征长度为3。
def forward(self,input):
x1 = F.relu(self.linear1(input))
x2 = F.relu(self.linear2(x1))
x3 = self.linear3(x2)
return x3
model = Model()
print(model)
loss_fn = nn.CrossEntropyLoss() # 使用这个函数来计算softmax概率损失
def accuracy(y_pred,y_true):
# y_true=y_true.int()
# y_true=y_true.long()
y_pred = torch.argmax(y_pred,dim=1)
acc = (y_pred == y_true).float().mean()
return acc
# 我们希望将每一次的epoch中的结果放入列表当中。
train_loss = []
train_acc = []
test_loss = []
test_acc = []
epochs = 20
opt = torch.optim.Adam(model.parameters(), lr=0.001) # Adam优化器
for epoch in range(epochs): # 训练500次
for x,y in train_dl:
# y = torch.tensor(y,dtype=torch.long)
y_pred = model(x) # y_pred是经过sigmoid输出的一个介于0~1之间的值
loss = loss_fn(y_pred,y)
opt.zero_grad() # 将所有可训练参数的梯度置为0
loss.backward() # 反向传播
opt.step() # 优化参数
with torch.no_grad():
# 这一部分的计算不需要跟踪计算
epoch_acc = accuracy(model(train_X),train_Y) #每一个批次,对全部数据进行预测,得到的平均正确率
epoch_loss = loss_fn(model(train_X),train_Y).data
epoch_test_acc = accuracy(model(test_X),test_Y)
epoch_test_loss = loss_fn(model(test_X),test_Y).data
# 使用 .item 将单个的tensor输出值转化为了python的标量值
print("epoch:%d"%epoch)
print("loss:",round(epoch_loss.item(),3),",accuracy:",round(epoch_acc.item(),3))
print("test_loss:",round(epoch_test_loss.item(),3),",test_accuracy:",round(epoch_test_acc.item(),3))
print("——————————————————————————————")
train_loss.append(epoch_loss.item())
train_acc.append(epoch_acc.item())
test_loss.append(epoch_test_loss.item())
test_acc.append(epoch_test_acc.item())
fig=plt.figure()
plt.plot(range(1,epochs+1),train_loss,label='train_loss')
plt.plot(range(1,epochs+1),test_loss,label='test_loss')
plt.legend()
plt.show()
fig=plt.figure()
plt.plot(range(1,epochs+1),train_acc,label='train_acc')
plt.plot(range(1,epochs+1),test_acc,label='test_acc')
plt.legend()
plt.show()

mnist仅训练集
import torch
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import numpy as np
data=np.load("/Users/xiaokangyu/Desktop/dataset/DL/MNIST_digit/mnist.npz")
print(data["x_train"].shape) # (60000, 28, 28)
print(data["y_train"].shape) # (60000,)
print(data["x_test"].shape) # (10000, 28, 28)
print(data["y_test"].shape) # (10000,)
x_train=data["x_train"]
y_train=data["y_train"]
x_test =data["x_test"]
y_test =data["y_test"]
x_train=x_train.reshape(x_train.shape[0],-1) #reshape
x_test=x_test.reshape(x_test.shape[0],-1) #reshape
########## 最简单的标准化############
x_train=x_train/255.0
x_test=x_test/255.0
########## 最简单的标准化############
print(x_train.shape)
print(x_test.shape)
X=x_train.copy()
Y=y_train.copy()
# ndarray转换为tensor
train_X = torch.from_numpy(X).type(torch.float32)
# train_Y = torch.from_numpy(train_Y).type(torch.float32)
train_Y = torch.from_numpy(Y).type(torch.int64)
from torch.utils.data import TensorDataset
from torch.utils.data import DataLoader
batch = 128 #批次大小
train_dataset = TensorDataset(train_X,train_Y) # Dataset
train_dataloader = DataLoader(train_dataset,batch_size=batch,shuffle=True) # DataLoader
import torch.nn.functional as F
from torch import nn
class Model(nn.Module):
def __init__(self):
#首先要继承父类中所有的变量
super().__init__()
# 开始初始化所有的层
self.linear1 = nn.Linear(784,256) # 不要写成768,我也不知道为啥我脑袋里会出现这个数字,可能是28*28我记错了
self.linear2 = nn.Linear(256,64)
self.linear3 = nn.Linear(64,10) # 输出层。因为是三分类,所以输出特征长度为3。
def forward(self,input):
x1 = F.relu(self.linear1(input))
x2 = F.relu(self.linear2(x1))
x3 = self.linear3(x2)
return x3
model = Model()
print(model)
loss_fn = nn.CrossEntropyLoss() # 使用这个函数来计算softmax概率损失
def accuracy(y_pred,y_true):
# y_true=y_true.int()
# y_true=y_true.long()
y_pred = torch.argmax(y_pred,dim=1)
acc = (y_pred == y_true).float().mean()
return acc
train_loss = []
train_acc = []
epochs = 10
opt = torch.optim.Adam(model.parameters(), lr=0.001) # Adam优化器
for epoch in range(epochs): # 训练500次
for x,y in train_dataloader:
# y = torch.tensor(y,dtype=torch.long)
y_pred = model(x) # y_pred是经过sigmoid输出的一个介于0~1之间的值
loss = loss_fn(y_pred,y)
opt.zero_grad() # 将所有可训练参数的梯度置为0
loss.backward() # 反向传播
opt.step() # 优化参数
with torch.no_grad():
# 这一部分的计算不需要跟踪计算
epoch_acc = accuracy(model(train_X),train_Y) #每一个批次,对全部数据进行预测,得到的平均正确率
epoch_loss = loss_fn(model(train_X),train_Y).data
# 使用 .item 将单个的tensor输出值转化为了python的标量值
print("epoch:%d"%epoch)
print("loss:",round(epoch_loss.item(),3),",accuracy:",round(epoch_acc.item(),3))
print("——————————————————————————————")
train_loss.append(epoch_loss.item())
train_acc.append(epoch_acc.item())
fig=plt.figure()
plt.plot(range(1,epochs+1),train_loss,label='train_loss')
plt.legend()
plt.show()
fig=plt.figure()
plt.plot(range(1,epochs+1),train_acc,label='train_acc')
plt.legend()
plt.show()
结果如下
温馨提示
我应用到别的数据集时,出了一个很小的问题,就是一定要注意标签Y的类型,我当时没注意用的是int8,结果就报错了
正确的用法是
train_Y = torch.from_numpy(train_Y).type(torch.int64)
不管你原始的Y是什么类型,最终输入到crossentropy函数中计算的,一定要提前转换成torch.int64类型,否则报错
边栏推荐
- MySQL
- [network planning] 3.2 transport layer - UDP: connectionless service
- [network planning] 2.2.3 user server interaction: cookies
- 如何保证消息的顺序性、消息不丢失、不被重复消费
- Pirate OJ 148 String inversion
- 【NVIDIA驱动的顽固问题】---- /dev/sdax:clean,xxx/xxx files,xxx/xxx blocks ---- 最全解决方法
- 跳转页面后回不去默认页面
- How word inserts a guide (dot before page number) into a table of contents
- STM32 cannot download again after downloading the code
- [network planning] 2.4 DNS: directory service of the Internet
猜你喜欢

Using solrj to add, delete, modify, and query Solr is too simple

非重叠矩形中的随机点

循环结构语句

MESI cache consistency protocol for concurrent programming

如何保证消息的顺序性、消息不丢失、不被重复消费
Alicloud configures SLB (load balancing) instances

Pirate OJ 448 luck draw

How to guarantee the quality of real-time data, the cornerstone of the 100 million level search system (Youku Video Search)? v2020

How to install mathtype6.9 and related problem solutions in office2016 (word2016)

"Past and present" of permission management
随机推荐
System interpretation: Authority Design Guide
C language implementation setting desktop wallpaper
自动化测试系列
招聘 | 南京 | TRIOSTUDIO 三厘社 – 室内设计师 / 施工图深化设计师 / 装置/产品设计师 / 实习生等
大厂是面对深度分页问题是如何解决的(通俗易懂)
The principle and source code interpretation of executor thread pool in concurrent programming
ts+fetch实现选择文件上传
Deploy netron services through kubernetes and specify model files at startup
文件“Setup”不存在,怎么办?
Objects as points personal summary
【ROS入门教程】---- 01 ROS介绍
Dynamic programming classical topic triangle shortest path
How to ensure the sequence of messages, that messages are not lost or consumed repeatedly
The JVM determines whether an object can be recycled
启牛商学院中信建投账户怎么样?安全吗
lucene思维导图,让搜索引擎不再难懂
WIN11卸载小组件
Pirate OJ 148 String inversion
QT program plug-in reports an error plugin xcb
[network planning] 2.5 brief introduction to P2P architecture