当前位置:网站首页>Interpretation of TPS motion (cvpr2022) video generation paper
Interpretation of TPS motion (cvpr2022) video generation paper
2022-07-26 06:10:00 【‘Atlas’】
List of articles
The paper : 《Thin-Plate Spline Motion Model for Image Animation》
github: https://github.com/yoyo-nb/Thin-Plate-Spline-Motion-Model
solve the problem
problem :
Although some current work uses unsupervised methods to carry out arbitrary target attitude transfer , But when there is a big difference between the source image and the target image , There are still challenges for the current unsupervised scheme .
Method :
This paper proposes unsupervised TPS Motion,
1、 Put forward thin-plate spline(TPS) motion estimation , To generate more flexible optical flow , Migrate source graph features to target graph features ;
2、 In order to complete the missing area , Use multi-resolution occlusion mask Carry out effective feature fusion .
3、 The additional auxiliary loss function is used to ensure the division of labor of each module of the network , Make it possible to generate high-quality pictures ;
Algorithm
TPS Motion The overall flow chart of the algorithm is shown in Figure 2 Shown ,
TPS Motion It mainly includes the following modules :
1、 Key point detection module E k p E_{kp} Ekp: Generate K ∗ N K*N K∗N Key points are used to generate K individual TPS Transformation ;
2、 Background motion prediction E b g E_{bg} Ebg: Estimate the background transformation parameters ;
3、 Dense motion network (Dense Motion Network): This is a hourglass The Internet , Use E b g E_{bg} Ebg Background transformation and E k p E_{kp} Ekp Of K Of K individual TPS Transform for optical flow estimation 、 Multiresolution occlusion mask forecast , Used to guide missing areas ;
4、 Repair the network (Inpainting Network): A fellow hourglass The Internet , Use the predicted optical flow to distort the original image feature , Repair missing areas of feature map at each scale ;
TPS motion estimation
1、 adopt TPS With minimum distortion , Transform the original image to the target image , Such as the type 1, P i X Diagram X Upper part i A key point P^X_i Diagram X Upper part i A key point PiX Diagram X Upper part i A key point ;
E k p E_{kp} Ekp Use K ∗ N K*N K∗N A key point , Calculation k individual tps Transformation , Each use N A key point (N=5),TPS The calculation is as follows 2, p It's coordinates , A And w It's a formula 1 Solved coefficient , U For the offset term p It's coordinates ,A And w It's a formula 1 Solved coefficient ,U For the offset term p It's coordinates ,A And w It's a formula 1 Solved coefficient ,U For the offset term ,
2、 The background transformation matrix is as follows 4, among A b g A_{bg} Abg By the background motion predictor E b g E_{bg} Ebg Generate ;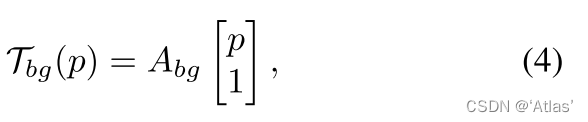
3、 adopt Dense Motion Network take K+1 Transform predictions contribution map M ~ ∈ R ( K + 1 ) × H × W \tilde M \in R^{(K+1)\times H \times W} M~∈R(K+1)×H×W, after softmax obtain M M M, Such as the type 5,
With the K+1 Three transformations are combined to calculate optical flow , Such as the type 6,
Because there are only some in the early stage of training TPS Transformation works , As a result contribution map Some places are 0, Therefore, it is easy to fall into local optimization during training ;
Author use dropout Make some contribution map by 0, Will type 5 Change to formula 7, b i Obey the Bernoulli distribution , The probability of 1 − P b_i Obey the Bernoulli distribution , The probability of 1-P bi Obey the Bernoulli distribution , The probability of 1−P, So that the network will not rely too much on some TPS Transformation , Train a few epoch after , The author removed it ;
4、 Repair the network (Inpainting Network) The encoder extracts the features of the original image for transformation , The decoder reconstructs the target graph ;
Multiresolution occlusion Mask
Some papers prove , The focus areas of different scale feature maps are different , Low resolution focuses on abstract forms , High resolution attention to detail texture ; Therefore, the author predicts occlusion at each layer mask;
Dense Motion Network In addition to predicting optical flow, it also predicts multi-resolution occlusion mask, By adding an additional convolution layer to each encoder layer ;
Inpaintting Network Fusion of multi-scale features to generate high-quality images , The details are as shown in the picture 3 Shown ;
1、 Put the original picture S Into the encoder , Optical flow T ~ \tilde T T~ Used to transform the feature map of each layer ;
2、 Use predicted occlusion mask Feature map after occlusion transformation ;
3、 Use skip connection Output with shallow decoder concat;
4、 Through two residual networks and upper sampling layer , Generate the final image ;
Training loss function
Refactoring loss : Use VGG-19 Calculate the reconfiguration loss , Such as the type 9;
CO transformation loss : Used for constraint key detection module , Such as the type 10;
Background loss : Used to constrain the background Motion predictor , Make sure the forecast is more accurate , A b g A_{bg} Abg From S To D Background affine transformation matrix ; A b g ′ A'_{bg} Abg′ Express D To S Background affine transformation matrix , Prevent the predictive output matrix from being 0,loss Unused 11, But form 12;

Distortion loss : Used to constrain Inpainting Network, Make the estimation of optical flow more reliable , Such as the type 13,Ei Indicates the second of the network i Layer encoder ;
The overall loss function is as follows 14
Testing phase
FOMM There are two patterns : standard 、 relevant ;
The former uses drive video D t D_t Dt Every frame and S, According to formula 6 It is estimated that motion, But when S And D When the difference is large ( such as S And D There are great differences in the body size of Chinese people ), Poor performance ;
The latter is used to estimate D 1 D_1 D1 to D t D_t Dt Of motion, Apply it to S, This requires D 1 D_1 D1 And S Of pose near ;
MRAA Propose a new model , Animation through decoupling , Additional training network for prediction motion, be applied to S, This article uses the same pattern ; Training shape And pose Encoder ,shape Key points of encoder learning S Of shape,pose Key points of encoder learning D t D_t Dt Of pose, Decoder reconstruction key points are reserved S Of shape And D t D_t Dt Of pose, Use the same video for two frames during training , The key points of one frame are randomly transformed to simulate the other individual pose;
For image animation , take S And D t D_t Dt The key points of shape And pose Encoder , Get the key points of reconstruction through the decoder , According to the type 6 It is estimated that motion.
experiment
Evaluation indicators
L1 Represents the pixels of the driving graph and the generated graph L1 distance ;
Average keypoint distance (AKD) Indicates the distance between the key points of the generated graph and the driving graph ;
Missing keypoint rate (MKR) Represents the ratio of key points that exist in the driving graph but do not exist in the generating graph ;
Average Euclidean distance (AED) Said the use of reid Model extraction generates graph and drive graph features , Compare the two L2 Loss ;
The video reconstruction results are shown in table 1;
chart 6 Show the image animation results , stay 4 Data sets with MRAA Compare ,
surface 2 Show real users' comments on continuity and authenticity ;
surface 4 Show the ablation results ;
surface 3 It's different K Impact on the results ,FOMM、MRAA Use K=5,10,20; This article is written in 2,4,8;
Conclusion
The unsupervised image animation method proposed by the author :
1、 adopt TPS Estimate the flow of light , Use at the beginning of training dropout, Prevent falling into local optimum ;
2、 Multiresolution occlusion mask For more effective feature fusion ;
3、 Design additional auxiliary losses ;
This method obtains SOTA, But when the identity of the characters in the source map and the driving map are extremely mismatched , The effect is not ideal ;
边栏推荐
- 招标信息获取
- Sequential search, half search, block search~
- Latex merges multiple rows and columns of a table at the same time
- 移动web
- Matlab 向量与矩阵
- 【(SV && UVM) 笔试面试遇到的知识点】~ phase机制
- Binary sort tree (BST)~
- CCTV dialogue ZTE: why must the database be in your own hands?
- PHP 多任务秒级定时器的实现方法
- Mysql45 talks about transaction isolation: why can't I see it after you change it?
猜你喜欢

Traversal of the first, middle, and last order of a binary tree -- Essence (each node is a "root" node)

Kingbasees SQL language reference manual of Jincang database (8. Function (10))
【(SV && UVM) 笔试面试遇到的知识点】~ phase机制

Etcd database source code analysis - cluster membership changes log

unity 像素画导入模糊问题

Interview difficulties: difficulties in implementing distributed session, this is enough!

招标信息获取

PHP 多任务秒级定时器的实现方法

Embedded sharing collection 15

移动web
随机推荐
Is the transaction in mysql45 isolated or not?
flex布局
Workflow activiti5.13 learning notes (I)
ament_cmake生成ROS2库并链接
Jincang database kingbasees SQL language reference manual (5. Operators)
Easycvr video square channel display and video access full screen display style problem repair
1.12 Web开发基础
分布式 | 实战:将业务从 MyCAT 平滑迁移到 dble
光量子里程碑:6分钟内解决3854个变量问题
Redis sentinel cluster setup
Kingbasees SQL language reference manual of Jincang database (9. Common DDL clauses)
Code Runner for VS Code,下载量突破 4000 万!支持超过50种语言
Latex同时合并表格的多行多列
【Day02_0419】C语言选择题
[Oracle SQL] calculate year-on-year and month on month (column to row offset)
Kingbasees SQL language reference manual of Jincang database (10. Query and sub query)
"Recursive processing of subproblems" -- judging whether two trees are the same tree -- and the subtree of another tree
Mobile web
L. Link with Level Editor I dp
Solutions to the failure of copy and paste shortcut keys