当前位置:网站首页>阻塞隊列 — DelayedWorkQueue源碼分析
阻塞隊列 — DelayedWorkQueue源碼分析
2022-06-11 00:36:00 【要有價值】

前言
線程池運行時,會不斷從任務隊列中獲取任務,然後執行任務。如果我們想實現延時或者定時執行任務,重要一點就是任務隊列會根據任務延時時間的不同進行排序,延時時間越短地就排在隊列的前面,先被獲取執行。
隊列是先進先出的數據結構,就是先進入隊列的數據,先被獲取。但是有一種特殊的隊列叫做優先級隊列,它會對插入的數據進行優先級排序,保證優先級越高的數據首先被獲取,與數據的插入順序無關。
實現優先級隊列高效常用的一種方式就是使用堆。關於堆的實現可以查看《堆和二叉堆的實現和特性》
ScheduledThreadPoolExecutor線程池
ScheduledThreadPoolExecutor繼承自ThreadPoolExecutor,所以其內部的數據結構和ThreadPoolExecutor基本一樣,並在其基礎上增加了按時間調度執行任務的功能,分為延遲執行任務和周期性執行任務。
ScheduledThreadPoolExecutor的構造函數只能傳3個參數corePoolSize、ThreadFactory、RejectedExecutionHandler,默認maximumPoolSize為Integer.MAX_VALUE。
工作隊列是高度定制化的延遲阻塞隊列DelayedWorkQueue,其實現原理和DelayQueue基本一樣,核心數據結構是二叉最小堆的優先隊列,隊列滿時會自動擴容,所以offer操作永遠不會阻塞,maximumPoolSize也就用不上了,所以線程池中永遠會保持至多有corePoolSize個工作線程正在運行。
public ScheduledThreadPoolExecutor(int corePoolSize,
ThreadFactory threadFactory,
RejectedExecutionHandler handler) {
super(corePoolSize, Integer.MAX_VALUE, 0, NANOSECONDS,
new DelayedWorkQueue(), threadFactory, handler);
}
DelayedWorkQueue延遲阻塞隊列
DelayedWorkQueue 也是一種設計為定時任務的延遲隊列,它的實現和DelayQueue一樣,不過是將優先級隊列和DelayQueue的實現過程遷移到本身方法體中,從而可以在該過程當中靈活的加入定時任務特有的方法調用。
工作原理
ScheduledThreadPoolExecutor之所以要自己實現阻塞的工作隊列,是因為 ScheduleThreadPoolExecutor 要求的工作隊列有些特殊。
DelayedWorkQueue是一個基於堆的數據結構,類似於DelayQueue和PriorityQueue。在執行定時任務的時候,每個任務的執行時間都不同,所以DelayedWorkQueue的工作就是按照執行時間的昇序來排列,執行時間距離當前時間越近的任務在隊列的前面(注意:這裏的順序並不是絕對的,堆中的排序只保證了子節點的下次執行時間要比父節點的下次執行時間要大,而葉子節點之間並不一定是順序的)。
堆結構如下圖: 可見,DelayedWorkQueue是一個基於最小堆結構的隊列。堆結構可以使用數組錶示,可以轉換成如下的數組:
可見,DelayedWorkQueue是一個基於最小堆結構的隊列。堆結構可以使用數組錶示,可以轉換成如下的數組: 在這種結構中,可以發現有如下特性: 假設“第一個元素” 在數組中的索引為 0 的話,則父結點和子結點的比特置關系如下:
在這種結構中,可以發現有如下特性: 假設“第一個元素” 在數組中的索引為 0 的話,則父結點和子結點的比特置關系如下:
- 索引為 的左孩子的索引是 ;
- 索引為 的右孩子的索引是 ;
- 索引為 的父結點的索引是 ;
為什麼要使用DelayedWorkQueue呢?
- 定時任務執行時需要取出最近要執行的任務,所以任務在隊列中每次出隊時一定要是當前隊列中執行時間最靠前的,所以自然要使用優先級隊列。
- DelayedWorkQueue是一個優先級隊列,它可以保證每次出隊的任務都是當前隊列中執行時間最靠前的,由於它是基於堆結構的隊列,堆結構在執行插入和删除操作時的最壞時間複雜度是 O(logN)。
源碼分析
定義
DelayedWorkQueue 的類繼承關系如下: 其包含的方法定義如下:
其包含的方法定義如下:
成員屬性
// 初始時,數組長度大小。
private static final int INITIAL_CAPACITY = 16;
// 使用數組來儲存隊列中的元素,根據初始容量創建RunnableScheduledFuture類型的數組
private RunnableScheduledFuture<?>[] queue = new RunnableScheduledFuture<?>[INITIAL_CAPACITY];
// 使用lock來保證多線程並發安全問題。
private final ReentrantLock lock = new ReentrantLock();
// 隊列中儲存元素的大小
private int size = 0;
//特指隊列頭任務所在leader線程
private Thread leader = null;
// 當隊列頭的任務延時時間到了,或者新線程可能需要成為leader,用來喚醒等待線程
private final Condition available = lock.newCondition();
DelayedWorkQueue是用數組來儲存隊列中的元素,核心數據結構是二叉最小堆的優先隊列,隊列滿時會自動擴容。
注意這裏的leader,它是Leader-Follower模式的變體,用於减少不必要的定時等待。什麼意思呢?
對於多線程的網絡模型來說:所有線程會有三種身份中的一種:leader和follower,以及一個幹活中的狀態:proccesser。它的基本原則就是,永遠最多只有一個leader。而所有follower都在等待成為leader。線程池啟動時會自動產生一個Leader負責等待網絡IO事件,當有一個事件產生時,Leader線程首先通知一個Follower線程將其提拔為新的Leader,然後自己就去幹活了,去處理這個網絡事件,處理完畢後加入Follower線程等待隊列,等待下次成為Leader。這種方法可以增强CPU高速緩存相似性,及消除動態內存分配和線程間的數據交換。
構造函數
DelayedWorkQueue 是 ScheduledThreadPoolExecutor 的靜態類部類,默認只有一個無參構造方法。
static class DelayedWorkQueue extends AbstractQueue<Runnable>
implements BlockingQueue<Runnable> {
// ...
}
入隊方法
DelayedWorkQueue 提供了 put/add/offer(帶時間) 三個插入元素方法。我們發現與普通阻塞隊列相比,這三個添加方法都是調用offer方法。那是因為它沒有隊列已滿的條件,也就是說可以不斷地向DelayedWorkQueue添加元素,當元素個數超過數組長度時,會進行數組擴容。
public void put(Runnable e) {
offer(e);
}
public boolean add(Runnable e) {
return offer(e);
}
public boolean offer(Runnable e, long timeout, TimeUnit unit) {
return offer(e);
}
offer添加元素
ScheduledThreadPoolExecutor提交任務時調用的是DelayedWorkQueue.add,而add、put等一些對外提供的添加元素的方法都調用了offer。
public boolean offer(Runnable x) {
if (x == null)
throw new NullPointerException();
RunnableScheduledFuture<?> e = (RunnableScheduledFuture<?>)x;
// 使用lock保證並發操作安全
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = size;
// 如果要超過數組長度,就要進行數組擴容
if (i >= queue.length)
// 數組擴容
grow();
// 將隊列中元素個數加一
size = i + 1;
// 如果是第一個元素,那麼就不需要排序,直接賦值就行了
if (i == 0) {
queue[0] = e;
setIndex(e, 0);
} else {
// 調用siftUp方法,使插入的元素變得有序。
siftUp(i, e);
}
// 錶示新插入的元素是隊列頭,更換了隊列頭,
// 那麼就要喚醒正在等待獲取任務的線程。
if (queue[0] == e) {
leader = null;
// 喚醒正在等待等待獲取任務的線程
available.signal();
}
} finally {
lock.unlock();
}
return true;
}
其基本流程如下:
- 其作為生產者的入口,首先獲取鎖。
- 判斷隊列是否要滿了(
size >= queue.length),滿了就擴容grow()。 - 隊列未滿,size+1。
- 判斷添加的元素是否是第一個,是則不需要堆化。
- 添加的元素不是第一個,則需要堆化
siftUp。 - 如果堆頂元素剛好是此時被添加的元素,則喚醒take線程消費。
- 最終釋放鎖。
offer基本流程圖如下:

擴容grow()
可以看到,當隊列滿時,不會阻塞等待,而是繼續擴容。新容量newCapacity在舊容量oldCapacity的基礎上擴容50%(oldCapacity >> 1相當於oldCapacity /2)。最後Arrays.copyOf,先根據newCapacity創建一個新的空數組,然後將舊數組的數據複制到新數組中。
private void grow() {
int oldCapacity = queue.length;
// 每次擴容增加原來數組的一半數量。
// grow 50%
int newCapacity = oldCapacity + (oldCapacity >> 1);
if (newCapacity < 0) // overflow
newCapacity = Integer.MAX_VALUE;
// 使用Arrays.copyOf來複制一個新數組
queue = Arrays.copyOf(queue, newCapacity);
}
向上堆化siftUp
新添加的元素先會加到堆底,然後一步步和上面的父親節點比較,若小於父親節點則和父親節點互換比特置,循環比較直至大於父親節點才結束循環。通過循環,來查找元素key應該插入在堆二叉樹那個節點比特置,並交互父節點的比特置。
向上堆化siftUp的詳細過程可以查看《堆和二叉堆的實現和特性》
private void siftUp(int k, RunnableScheduledFuture<?> key) {
// 當k==0時,就到了堆二叉樹的根節點了,跳出循環
while (k > 0) {
// 父節點比特置坐標, 相當於(k - 1) / 2
int parent = (k - 1) >>> 1;
// 獲取父節點比特置元素
RunnableScheduledFuture<?> e = queue[parent];
// 如果key元素大於父節點比特置元素,滿足條件,那麼跳出循環
// 因為是從小到大排序的。
if (key.compareTo(e) >= 0)
break;
// 否則就將父節點元素存放到k比特置
queue[k] = e;
// 這個只有當元素是ScheduledFutureTask對象實例才有用,用來快速取消任務。
setIndex(e, k);
// 重新賦值k,尋找元素key應該插入到堆二叉樹的那個節點
k = parent;
}
// 循環結束,k就是元素key應該插入的節點比特置
queue[k] = key;
setIndex(key, k);
}
代碼很好理解,就是循環的根據key節點與它的父節點來判斷,如果key節點的執行時間小於父節點,則將兩個節點交換,使執行時間靠前的節點排列在隊列的前面。
假設新入隊的節點的延遲時間(調用getDelay()方法獲得)是 5 ,執行過程如下:
- 先將新的節點添加到數組的尾部,這時新節點的索引k為7

- 計算新父節點的索引:parent = (k - 1) >>> 1,parent = 3,那麼queue[3]的時間間隔值為8,因為 5 < 8 ,將執行queue[7] = queue[3]

- 這時將k設置為3,繼續循環,再次計算parent為1,queue[1]的時間間隔為3,因為 5 > 3 ,這時退出循環,最終k為3

可見,每次新增節點時,只是根據父節點來判斷,而不會影響兄弟節點。
出隊方法
DelayedWorkQueue 提供了以下幾個出隊方法
- take(),等待獲取隊列頭元素
- poll() ,立即獲取隊列頭元素
- poll(long timeout, TimeUnit unit) ,超時等待獲取隊列頭元素
take消費元素
Worker工作線程啟動後就會循環消費工作隊列中的元素,因為ScheduledThreadPoolExecutor的keepAliveTime=0,所以消費任務其只調用了DelayedWorkQueue.take。take基本流程如下:
- 首先獲取可中斷鎖,判斷堆頂元素是否是空,空的則阻塞等待
available.await()。 - 堆頂元素不為空,則獲取其延遲執行時間
delay,delay <= 0說明到了執行時間,出隊列finishPoll。 delay > 0還沒到執行時間,判斷leader線程是否為空,不為空則說明有其他take線程也在等待,當前take將無限期阻塞等待。leader線程為空,當前take線程設置為leader,並阻塞等待delay時長。- 當前leader線程等待delay時長自動喚醒護著被其他take線程喚醒,則最終將
leader設置為null。 - 再循環一次判斷
delay <= 0出隊列。 - 跳出循環後判斷leader為空並且堆頂元素不為空,則喚醒其他take線程,最後是否鎖。
public RunnableScheduledFuture<?> take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
// 如果沒有任務,就讓線程在available條件下等待。
if (first == null)
available.await();
else {
// 獲取任務的剩餘延時時間
long delay = first.getDelay(NANOSECONDS);
// 如果延時時間到了,就返回這個任務,用來執行。
if (delay <= 0)
return finishPoll(first);
// 將first設置為null,當線程等待時,不持有first的引用
first = null; // don't retain ref while waiting
// 如果還是原來那個等待隊列頭任務的線程,
// 說明隊列頭任務的延時時間還沒有到,繼續等待。
if (leader != null)
available.await();
else {
// 記錄一下當前等待隊列頭任務的線程
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 當任務的延時時間到了時,能够自動超時喚醒。
available.awaitNanos(delay);
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null) // 喚醒等待任務的線程
available.signal();
ock.unlock();
}
}
take基本流程圖如下:

take線程阻塞等待
可以看出這個生產者take線程會在兩種情况下阻塞等待:
- 堆頂元素為空。
- 堆頂元素的delay > 0 。
take方法是什麼時候調用的呢?
在ThreadPoolExecutor中,getTask方法,工作線程會循環地從workQueue中取任務。但定時任務卻不同,因為如果一旦getTask方法取出了任務就開始執行了,而這時可能還沒有到執行的時間,所以在take方法中,要保證只有在到指定的執行時間的時候任務才可以被取走。
leader線程
再來說一下leader的作用,這裏的leader是為了减少不必要的定時等待。leader線程的設計,是Leader-Follower模式的變種,旨在於為了不必要的時間等待。當一個take線程變成leader線程時,只需要等待下一次的延遲時間,而不是leader線程的其他take線程則需要等leader線程出隊列了才喚醒其他take線程。
舉例來說,如果沒有leader,那麼在執行take時,都要執行available.awaitNanos(delay),假設當前線程執行了該段代碼,這時還沒有signal,第二個線程也執行了該段代碼,則第二個線程也要被阻塞。多個這時執行該段代碼是沒有作用的,因為只能有一個線程會從take中返回queue[0](因為有lock),其他線程這時再返回for循環執行時取的queue[0],已經不是之前的queue[0]了,然後又要繼續阻塞。
所以,為了不讓多個線程頻繁的做無用的定時等待,這裏增加了leader,如果leader不為空,則說明隊列中第一個節點已經在等待出隊,這時其它的線程會一直阻塞,减少了無用的阻塞(注意,在finally中調用了signal()來喚醒一個線程,而不是signalAll())。
finishPoll出隊列
堆頂元素delay<=0,執行時間到,出隊列就是一個向下堆化的過程siftDown。
// 移除隊列頭元素
private RunnableScheduledFuture<?> finishPoll(RunnableScheduledFuture<?> f) {
// 將隊列中元素個數减一
int s = --size;
// 獲取隊列末尾元素x
RunnableScheduledFuture<?> x = queue[s];
// 原隊列末尾元素設置為null
queue[s] = null;
if (s != 0)
// 因為移除了隊列頭元素,所以進行重新排序。
siftDown(0, x);
setIndex(f, -1);
return f;
}
堆的删除方法主要分為三步:
- 先將隊列中元素個數减一;
- 將原隊列末尾元素設置成為隊列頭元素,再將隊列末尾元素設置為null;
- 調用setDown(O,x)方法,保證按照元素的優先級排序。
向下堆化siftDown
由於堆頂元素出隊列後,就破壞了堆的結構,需要組織整理下,將堆尾元素移到堆頂,然後向下堆化:
- 從堆頂開始,父親節點與左右子節點中較小的孩子節點比較(左孩子不一定小於右孩子)。
- 父親節點小於等於較小孩子節點,則結束循環,不需要交換比特置。
- 若父親節點大於較小孩子節點,則交換比特置。
- 繼續向下循環判斷父親節點和孩子節點的關系,直到父親節點小於等於較小孩子節點才結束循環。
向下堆化siftDown的詳細過程可以查看《堆和二叉堆的實現和特性》
private void siftDown(int k, RunnableScheduledFuture<?> key) {
// 無符號右移,相當於size/2
int half = size >>> 1;
// 通過循環,保證父節點的值不能大於子節點。
while (k < half) {
// 左子節點, 相當於 (k * 2) + 1
int child = (k << 1) + 1;
// 左子節點比特置元素
RunnableScheduledFuture<?> c = queue[child];
// 右子節點, 相當於 (k * 2) + 2
int right = child + 1;
// 如果左子節點元素值大於右子節點元素值,那麼右子節點才是較小值的子節點。
// 就要將c與child值重新賦值
if (right < size && c.compareTo(queue[right]) > 0)
c = queue[child = right];
// 如果父節點元素值小於較小的子節點元素值,那麼就跳出循環
if (key.compareTo(c) <= 0)
break;
// 否則,父節點元素就要和子節點進行交換
queue[k] = c;
setIndex(c, k);
k = child;
}
queue[k] = key;
setIndex(key, k);
}
siftDown方法執行時包含兩種情况,一種是沒有子節點,一種是有子節點(根據half判斷)。
例如:沒有子節點的情况:
假設初始的堆如下: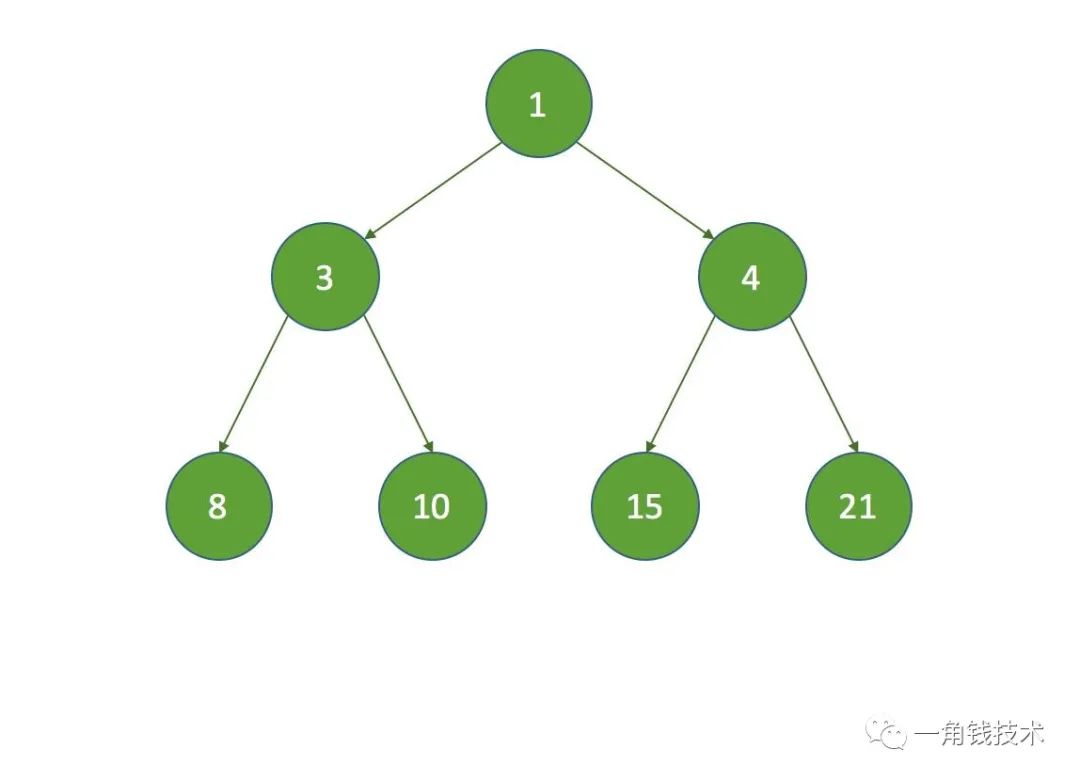
- 假設 k = 3 ,那麼 k = half ,沒有子節點,在執行siftDown方法時直接把索引為3的節點設置為數組的最後一個節點:

有子節點的情况:
假設 k = 0 ,那麼執行以下步驟:
- 獲取左子節點,child = 1 ,獲取右子節點, right = 2 :

- 由於 right < size ,這時比較左子節點和右子節點時間間隔的大小,這裏 3 < 7 ,所以 c = queue[child] ;
- 比較key的時間間隔是否小於c的時間間隔,這裏不滿足,繼續執行,把索引為k的節點設置為c,然後將k設置為child;

- 因為 half = 3 ,k = 1 ,繼續執行循環,這時的索引變為:

- 這時再經過如上判斷後,將k的值為3,最終的結果如下:

- 最後,如果在finishPoll方法中調用的話,會把索引為0的節點的索引設置為-1,錶示已經删除了該節點,並且size也减了1,最後的結果如下:
 可見,siftdown方法在執行完並不是有序的,但可以發現,子節點的下次執行時間一定比父節點的下次執行時間要大,由於每次都會取左子節點和右子節點中下次執行時間最小的節點,所以還是可以保證在take和poll時出隊是有序的。
可見,siftdown方法在執行完並不是有序的,但可以發現,子節點的下次執行時間一定比父節點的下次執行時間要大,由於每次都會取左子節點和右子節點中下次執行時間最小的節點,所以還是可以保證在take和poll時出隊是有序的。
poll()
立即獲取隊列頭元素,當隊列頭任務是null,或者任務延時時間沒有到,錶示這個任務還不能返回,因此直接返回null。否則調用finishPoll方法,移除隊列頭元素並返回。
public RunnableScheduledFuture<?> poll() {
final ReentrantLock lock = this.lock;
lock.lock();
try {
RunnableScheduledFuture<?> first = queue[0];
// 隊列頭任務是null,或者任務延時時間沒有到,都返回null
if (first == null || first.getDelay(NANOSECONDS) > 0)
return null;
else
// 移除隊列頭元素
return finishPoll(first);
} finally {
lock.unlock();
}
}
poll(long timeout, TimeUnit unit)
超時等待獲取隊列頭元素,與take方法相比較,就要考慮設置的超時時間,如果超時時間到了,還沒有獲取到有用任務,那麼就返回null。其他的與take方法中邏輯一樣。
public RunnableScheduledFuture<?> poll(long timeout, TimeUnit unit)
throws InterruptedException {
long nanos = unit.toNanos(timeout);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
for (;;) {
RunnableScheduledFuture<?> first = queue[0];
// 如果沒有任務。
if (first == null) {
// 超時時間已到,那麼就直接返回null
if (nanos <= 0)
return null;
else
// 否則就讓線程在available條件下等待nanos時間
nanos = available.awaitNanos(nanos);
} else {
// 獲取任務的剩餘延時時間
long delay = first.getDelay(NANOSECONDS);
// 如果延時時間到了,就返回這個任務,用來執行。
if (delay <= 0)
return finishPoll(first);
// 如果超時時間已到,那麼就直接返回null
if (nanos <= 0)
return null;
// 將first設置為null,當線程等待時,不持有first的引用
first = null; // don't retain ref while waiting
// 如果超時時間小於任務的剩餘延時時間,那麼就有可能獲取不到任務。
// 在這裏讓線程等待超時時間nanos
if (nanos < delay || leader != null)
nanos = available.awaitNanos(nanos);
else {
Thread thisThread = Thread.currentThread();
leader = thisThread;
try {
// 當任務的延時時間到了時,能够自動超時喚醒。
long timeLeft = available.awaitNanos(delay);
// 計算剩餘的超時時間
nanos -= delay - timeLeft;
} finally {
if (leader == thisThread)
leader = null;
}
}
}
}
} finally {
if (leader == null && queue[0] != null)
// 喚醒等待任務的線程
available.signal();
lock.unlock();
}
}
remove删除指定元素
删除指定元素一般用於取消任務時,任務還在阻塞隊列中,則需要將其删除。當删除的元素不是堆尾元素時,需要做堆化處理。
public boolean remove(Object x) {
final ReentrantLock lock = this.lock;
lock.lock();
try {
int i = indexOf(x);
if (i < 0)
return false;
//維護heapIndex
setIndex(queue[i], -1);
int s = --size;
RunnableScheduledFuture<?> replacement = queue[s];
queue[s] = null;
if (s != i) {
//删除的不是堆尾元素,則需要堆化處理
//先向下堆化
siftDown(i, replacement);
if (queue[i] == replacement)
//若向下堆化後,i比特置的元素還是replacement,說明四無需向下堆化的,
//則需要向上堆化
siftUp(i, replacement);
}
return true;
} finally {
lock.unlock();
}
}
假設初始的堆結構如下:[外鏈圖片轉存失敗,源站可能有防盜鏈機制,建議將圖片保存下來直接上傳(img-SqhXOn3E-1653913362599)(data:image/gif;base64,iVBORw0KGgoAAAANSUhEUgAAAAEAAAABCAYAAAAfFcSJAAAADUlEQVQImWNgYGBgAAAABQABh6FO1AAAAABJRU5ErkJggg==)]這時要删除8的節點,那麼這時 k = 1,key為最後一個節點: 這時通過上文對siftDown方法的分析,siftDown方法執行後的結果如下:
這時通過上文對siftDown方法的分析,siftDown方法執行後的結果如下: 這時會發現,最後一個節點的值比父節點還要小,所以這裏要執行一次siftUp方法來保證子節點的下次執行時間要比父節點的大,所以最終結果如下:
這時會發現,最後一個節點的值比父節點還要小,所以這裏要執行一次siftUp方法來保證子節點的下次執行時間要比父節點的大,所以最終結果如下:
總結
使用優先級隊列DelayedWorkQueue,保證添加到隊列中的任務,會按照任務的延時時間進行排序,延時時間少的任務首先被獲取。
- DelayedWorkQueue的數據結構是基於堆實現的;
- DelayedWorkQueue采用數組實現堆,根節點出隊,用最後葉子節點替換,然後下推至滿足堆成立條件;最後葉子節點入隊,然後向上推至滿足堆成立條件;
- DelayedWorkQueue添加元素滿了之後會自動擴容原來容量的1/2,即永遠不會阻塞,最大擴容可達Integer.MAX_VALUE,所以線程池中至多有corePoolSize個工作線程正在運行;
- DelayedWorkQueue 消費元素take,在堆頂元素為空和delay >0 時,阻塞等待;
- DelayedWorkQueue 是一個生產永遠不會阻塞,消費可以阻塞的生產者消費者模式;
- DelayedWorkQueue 有一個leader線程的變量,是Leader-Follower模式的變種。當一個take線程變成leader線程時,只需要等待下一次的延遲時間,而不是leader線程的其他take線程則需要等leader線程出隊列了才喚醒其他take線程。
边栏推荐
- canvas绘画折线段
- mysql 数据库 表 备份
- Shengteng AI development experience based on target detection and identification of Huawei cloud ECS [Huawei cloud to jianzhiyuan]
- How word inserts a guide (dot before page number) into a table of contents
- Word删除页眉横线的方法
- Yii2 ActiveRecord 使用表关联出现的 id 自动去重问题
- JVM garbage collection mechanism and common garbage collectors
- Décomposition détaillée du problème de chemin le plus court du graphique
- MD5Util
- yum源更新
猜你喜欢
String time sorting, sorting time format strings

Things about Bluetooth development (10) -- getting to know ble for the first time
![[network counting] 1.4 network delay, packet loss and throughput](/img/a8/74a1b44ce4d8b0b1a85043a091a91d.jpg)
[network counting] 1.4 network delay, packet loss and throughput

Yum source update

452. detonate the balloon with the minimum number of arrows

Word在目录里插入引导符(页码前的小点点)的方法

图的最短路径问题 详细分解版

unity 网格面片生成抛物线,折线

微信小程序实现OCR扫描识别

【JVM】内存模型
随机推荐
Pirate OJ 148 String inversion
[untitled] test
Njupt Nanyou Discrete Mathematics_ Experiment 3
[network planning] 2.2.3 user server interaction: cookies
数的奥秘之幂数与完全平方数
String time sorting, sorting time format strings
How word inserts a guide (dot before page number) into a table of contents
网络工程师必修课防火墙安全区域及安全策略基础操作
Yii2 activerecord uses the ID associated with the table to automatically remove duplicates
MP framework basic operation (self use)
MD5Util
763. 划分字母区间
文件缓存和session怎么处理?
JVM garbage collection mechanism and common garbage collectors
Bluetooth development (4) -- about flow control
Bluetooth development (6) -- literacy of Bluetooth protocol architecture
Unity自定义文件夹图标颜色 个性化Unity编译器
海贼oj#146.字符串
[database] MySQL index interview questions
海贼oj#448.抽奖