当前位置:网站首页>[reading point paper] deeplobv3 rethinking atlas revolution for semantic image segmentation ASPP
[reading point paper] deeplobv3 rethinking atlas revolution for semantic image segmentation ASPP
2022-06-13 02:20:00 【Shameful child】
Rethinking Atrous Convolution for Semantic Image Segmentation
- Cascade or parallel convolution module of multi-scale velocity To capture multiscale context , In order to solve the problem of multi-scale object segmentation
- Atrous Spatial Pyramid Pooling module:Atrous Space pyramid pool module
- The module detects convolution features of multiple scales , Use image level features to encode the global context , Further improve performance
tips: Proposed “DeepLabv3” The system is not DenseCRF In the case of post-processing, it significantly improves our previous DeepLab edition
Two challenges of deep convolution neural network in semantic segmentation task
- Caused by a continuous pool operation or convolution step Feature resolution is reduced , This makes dcnn Learn more and more abstract feature representation
- This invariance of local image transformation may hinder intensive prediction tasks , The intensive prediction task requires detailed spatial information
The existence of objects on multiple scales ( An optional architecture that captures multi-scale context 4 Kind of )
take DCNN Applied to the In the image pyramid , Extract the input features of each scale , Targets of different scales become prominent on different feature maps
- The same model , Usually have shared weights , Applied to multiscale input - The same model , Usually have shared weights , Applied to multiscale input - Large scale input preserves the details of small objects - > Example > > - Input image through Laplacian pyramid transform , Enter the input of each scale into DCNN in , And merge feature maps from all scales > - Use multi-scale input from coarse to fine > - Directly adjust the input of multiple scales , Integrate features of all scalesEncoder - The decoder structure utilizes Multi-scale feature of encoder part , from The decoder partially restores the spatial resolution
- In the encoder ,** The spatial dimension of the characteristic graph decreases gradually **, Thus, it is easier to capture longer distance information in the depth output by the encoder ;(b) In the encoder of , The target details and spatial dimensions are gradually restored .Additional modules are cascaded over the original network , For capturing remote information ( Context module )
- DenseCRF Pairwise similarity for encoding pixel level , adopt Cascade development of several additional convolution layers To gradually capture the remote context .

- The model contains additional modules arranged in a cascading fashion , To encode the remote context - An effective way is to DenseCRF( Combined with efficient high-dimensional filtering algorithm ) Add to dcnn - Put forward ** Joint training CRF and DCNN Components ** - stay DCNN Confidence graph of (** A confidence graph is a graph that ultimately contains output channels equal to the number of predicted classes DCNN Characteristics of figure **) Several additional convolution layers are used on to capture context informationSpace Pyramid pooling Through multi rate 、 Multiple effective field of view filters or pooling operations detect incoming feature map, So as to capture targets of multiple scales .
- On the characteristic graph 4 Different Atrous Rate parallelism Atrous Convolution - In cascaded modules and `SPP` Under the framework of , We use `Atrous Convolution` To increase the receptive field of the filter to fuse multi-scale contextual information . - It shows that it can effectively resample the features of different scales , So as to accurately and effectively classify regions of any scale , Using different rates of ASPP It can effectively capture multi-scale information - With the increase of sampling rate , Effective filter weights ( That is, the weight applied to the effective feature region , Instead of filling in zeros ) The number of will become smaller - 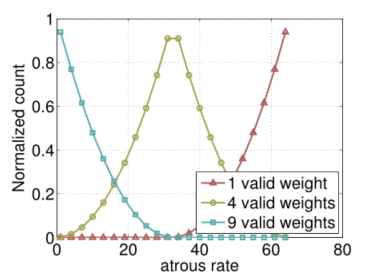- When atrous The rate is small , all 9 All filter weights are applied to feature map Most of the effective areas on , When atrous When the rate increases ,3×3filter Degenerate to a1×1filter, Because only the center weight is valid . - Atrous Space pyramid pool (ASPP) - problem : In the application a3×3 atrous Convolution , Due to image boundary effect , Unable to capture remote information , Effectively and simply degenerate to1×1convolution - programme : It is proposed to incorporate image level features into ASPP modular - The model uses a spatial pyramid pool to ** Capture context in multiple scopes ** - > Example > > - ParseNet Image level features are used to obtain global context information . > - DeepLabv2 Put forward atrous Space pyramid pool (ASPP), among ** Parallel with different rates atrous Convolution layer captures multi-scale information **. > - be based on LSTM To aggregate the global contextThe standard convolution is rater= 1 In special circumstances , and atrous Convolution allows us to adaptively modify the field of view of the filter by changing the rate value

The introduced stride can make it easier for us to obtain long-distance information in deeper blocks
Training strategy
Learning rate adjustment strategy :
- In this paper “ gather ” Learning rate strategy , Where the initial learning rate is multiplied by (1-iter/max_iter)**power. among power=0.9
Crop size(Caffe)
- utilize crop_size In this way, you can clip center concerns and corner features ,mirror Can produce a mirror image , Make up for the shortage of small data sets .
- In order to make large rate hole convolution effective , Need big Crop size; The filter weight with high filter rate is mostly applied to the filled zero region
Batch normalization
- Batch of standardized , Similar to ordinary data standardization , Is a way to unify scattered data , It is also a method to optimize neural network .
- Data with uniform specifications , It can make it easier for machine learning to learn the laws in the data .
Upsampling logits
- Odds(A)= What happened A frequency / Number of other events ( It doesn't happen A The number of times )
- probability P(A) and Odds(A) The range of values for is different .
- Logit The decomposition of the word , For it (it)Log( Take the logarithm ), here “it” Namely Odds.
- Usually , Let's start with Logit Transformation , Let's easily fit the data ( That's logical regression ), And then back to the familiar probability . That's the cycle , It provides convenience for data analysis . In a way , This kind of transformation , very Similar to the catalyst in chemistry .
Data augmentation
- In this paper, the input image is randomly scaled ( from 0.5 To 2.0) And random left-right flipping to apply data enhancement .
The improvement mainly comes from in the model Add and fine tune batch normalization parameters , And better coding for multiscale environments .
To encode multiscale information , Proposed Cascaded modules gradually make atrous Rate doubling
Proposed atrous The spatial pyramid pooling module enhances image level features , Using filters to detect features at multiple sampling rates and effective fields of view
A. Effect of hyper-parameters
- There are three main differences (77.21%, quantitative analysis )
- Bigger Corp size
- If we use smaller crop size values , The performance is significantly reduced to 67.22%, It shows that the boundary effect caused by small crop size affects atrous Spatial Pyramid Pooling (ASPP) Large... Is used in the module atrous Rate of DeepLabv3 Performance of .
- Upsampling during training logits
- If we don't sample up during training (instead downsample the groundtruths), Performance drops to 76.01%
- Fine tune batch normalization
- When training DeepLabv3 When batch normalization is not adjusted , Performance drops to 75.95%
- Bigger Corp size
- There are three main differences (77.21%, quantitative analysis )
DeepLabv3 The salient point of :
The use of void convolution , This allows us to , It can acquire a larger receptive field to obtain multi-scale information .
Improved ASPP modular : from Hole convolution sum with different sampling rates BN layers , We try to Cascade or parallel Layout modules in a way .
BN layer
Batch Normalization: Solve during training , The problem of changing the data distribution in the middle layer , With Prevent the gradient from disappearing or exploding 、 Speed up your training
- normalization (Normalized Data)( The reason why we need to do normalization preprocessing for all data ):
- The essence of neural network learning process is to learn data distribution , Once the distribution of training data and test data is different , Then the generalization ability of the network is greatly reduced ;
- Once the distribution of each batch of training data is different (batch gradient descent ), Then the network should learn to adapt to different distribution in each iteration , This will greatly reduce the speed of network training .
- The training of deep network is a complex process , As long as the first few layers of the network change slightly , Then the later layers will be magnified cumulatively .
- Once the distribution of input data at a certain layer of the network changes , So this layer of network needs to adapt to learning the new data distribution , So if during training , The distribution of training data has been changing , It will affect the training speed of the network .
- normalization (Normalized Data)( The reason why we need to do normalization preprocessing for all data ):
BN Training
- Random gradient descent method (SGD) It is simple and efficient for training depth network , We need to choose parameters artificially ( Learning rate 、 Parameter initialization 、 Weight attenuation coefficient 、Drop out Proportion, etc ), Use BN after , You don't need to adjust the parameters so deliberately .
- Once the neural network is trained , Then the parameters will be updated , In addition to the input layer data ( Because input layer data , We have artificially normalized each sample ), The input data distribution of each layer of the network is Is changing all the time , Because in training , The update of the training parameters of the front layer will lead to the change of the input data distribution of the back layer . Put the network middle layer in the training process , A change in the distribution of data is called :“Internal Covariate Shift”
- To solve the problem in the training process , The change of data distribution in the middle layer , So there was Batch Normalization, The birth of this algorithm .
- BN The status of : With the activation function layer 、 Convolution layer 、 Fully connected layer 、 The pool layer is the same ,BN(Batch Normalization) It also belongs to the network .
- BN The essence of the theory : When inputting at every layer of the network , Another Normalized layer , That is to do a normalization first ( Normalize to : mean value 0、 The variance of 1), Then go to the next layer of the network .
BN The role of
- Improve the gradient through the network
- Allow for a higher rate of learning , Speed up your training
- Reduce strong dependence on initialization
- Improve the regularization strategy : As a form of regularization , A slight decrease in the number of dropout The needs of
- The use of a local response normalization layer is no longer needed ( The local response normalization is Alexnet The way the Internet works , I'm familiar with visual estimation ), because BN It's a normalized network layer ;
- Regularization (Regularization: A technique to avoid over fitting )
The essence of neural network learning process is to : Learning data distribution , Once the distribution of training data and test data is different , Then the generalization ability of the network is greatly reduced , Therefore, the input data normalization method is required , Make the distribution of training data and test data the same . https://www.cnblogs.com/king-lps/p/8378561.html
Up sampling and down sampling
On the sampling : The simple understanding is to enlarge the picture . In the algorithm, , In the process of image recognition , The image needs to be classified at the pixel level , Therefore, after convolution to extract features, it is necessary to use up sampling to extract features feature map Restore To the original picture .
- Almost all of the image zooming is done by interpolation , That is, on the basis of the original image pixels New elements are inserted between pixels using appropriate interpolation algorithm .
- Common upsampling methods include bilinear interpolation and transpose convolution 、 On the sampling (unsampling) And upper pool (unpooling).
Down sampling :
background : Machine learning algorithm is to get some experience through calculation from a large number of data sets , And then determine whether some data are normal or not . however , Unbalanced data sets , Obviously, the number of minority classes is too small , The model will be more inclined to the majority set .
Common down sampling methods
Random down sampling
- Select some samples randomly from most classes and eliminate them . The disadvantage of this method is that the rejected samples may contain some important information , As a result, the effect of the learned model is not good .
EasyEnsemble and BalanceCascade
- EasyEnsemble and BalanceCascade Integrated learning mechanism is used to deal with the information loss in traditional random undersampling .
- EasyEnsemble Take most of the class samples Randomly divided into n A subset of , The number of each subset is equal to the number of samples of a few classes , This is equivalent to under sampling . Then each subset is combined with a few samples to train a model , The final will be n Model integration , In this way, although the sample of each subset is less than the total sample , However, the total amount of information after integration does not decrease .
- BalanceCascade It's using There is a combination of supervision Boosting The way (Boosting Method is a method used to improve the accuracy of weak classification algorithm , This is done by constructing a series of prediction functions , And then combine them into a prediction function in a certain way ).
- In the n In round training , Combine the subset sampled from the majority class samples with the minority class samples to train a Basic learner H, After training, most classes can be H Correctly classified samples will be rejected .
- In the next n+1 In the round , A subset is generated from the eliminated majority class samples for training with a few class samples , Last Integrate different base learners .
- BalanceCascade The supervised performance of the base learner in each round plays the role of selecting samples in most classes , And its Boosting The characteristic is to discard the correctly classified samples in each round , Further, the follow-up base learners will pay more attention to the samples with previous classification errors .
NearMiss
NearMiss In essence, it's a prototype choice (prototype selection) Method , That is to say, the most representative samples are selected from most kinds of samples for training , Mainly to alleviate the problem of information loss in random undersampling .
NearMiss Use some heuristic rules to select samples , According to the different rules, it can be divided into 3 class :
- NearMiss-1: Choose the nearest K The average distance of a few samples from the nearest most samples
- NearMiss-2: Select the farthest K The average distance of a few samples from the nearest most samples
- NearMiss-3: Select... For each small sample K Most recent samples , The purpose is to ensure that every minority sample is surrounded by the majority sample
https://blog.csdn.net/weixin_44451032/article/details/99974665



- Bilinear interpolation : Bilinear interpolation It's right linear interpolation In 2D Right angle grid Extension on , For bivariate functions ( for example x and y) Conduct interpolation . Its core idea is to do linear interpolation in two directions respectively .
- Transposition convolution
- One Convolution Operation is just a Many to one mapping .
- We want to map a value in the input matrix to a value in the output matrix 9 It's worth , This will be One to many (one-to-many) The mapping relation of . This is like the reverse of the convolution operation , Its core idea is to use transpose convolution .
- Global features or Context interaction It is helpful to correctly classify pixels for semantic segmentation
Its core idea is to do linear interpolation in two directions respectively .
- Transposition convolution
- One Convolution Operation is just a Many to one mapping .
- We want to map a value in the input matrix to a value in the output matrix 9 It's worth , This will be One to many (one-to-many) The mapping relation of . This is like the reverse of the convolution operation , Its core idea is to use transpose convolution .
- Global features or Context interaction It is helpful to correctly classify pixels for semantic segmentation
边栏推荐
- SWD debugging mode of stm32
- 传感器:SHT30温湿度传感器检测环境温湿度实验(底部附代码)
- C language complex type description
- Sensor: MQ-5 gas module measures the gas value (code attached at the bottom)
- How to solve the problem of obtaining the time through new date() and writing out the difference of 8 hours between the database and the current time [valid through personal test]
- Functional translation
- 16 embedded C language interview questions (Classic)
- Restrict cell input type and display format in CXGRID control
- Basic exercise of test questions Yanghui triangle (two-dimensional array and shallow copy)
- Bluetooth module: use problem collection
猜你喜欢

Mac使用Docker安装Oracle

Stm32 mpu6050 servo pan tilt support follow

Huawei equipment is configured with CE dual attribution
STM32F103 IIC OLED program migration complete engineering code

Why is Huawei matebook x Pro 2022 leading a "laptop" revolution

Ruixing coffee moves towards "national consumption"

Paper reading - jukebox: a generic model for music

Review the history of various versions of ITIL, and find the key points for the development of enterprise operation and maintenance

Deep learning the principle of armv8/armv9 cache

拍拍贷母公司信也季报图解:营收24亿 净利5.3亿同比降10%
随机推荐
CCF 201409-1: adjacent number pairs (100 points + problem solving ideas)
STM32 external interrupt Usage Summary
[single chip microcomputer] single timer in front and back platform program framework to realize multi delay tasks
C language compressed string is saved to binary file, and the compressed string is read from binary file and decompressed.
What are the differences in cache/tlb?
Microsoft Pinyin opens U / V input mode
cmake_ example
Understand HMM
speech production model
Uniapp preview function
Paper reading - beat tracking by dynamic programming
Paipai loan parent company Xinye quarterly report diagram: revenue of RMB 2.4 billion, net profit of RMB 530million, a year-on-year decrease of 10%
[keras] train py
JS get element
Leetcode 473. 火柴拼正方形 [暴力+剪枝]
ROS learning-8 pit for custom action programming
Leetcode 450. 删除二叉搜索树中的节点 [二叉搜索树]
Basic exercise of test questions decimal to hexadecimal
Parameter measurement method of brushless motor
Ruixing coffee 2022, extricating itself from difficulties and ushering in a smooth path