Hello,
I am playing with the internals of scatter text to utilize Bokeh as the front end visualization. I found for larger corpus's the time for the javascript to load to be excessive. With Bokeh I can serve up the text on the fly and dynamically re-parse the document based on filtering and such. Right now I am using several of the internal functions to generate the term document matrix to populate the graph data.
In my case I am playing with patent text documents. The results are looking very nice so far but I have encountered an issue shown below with the set of 5 documents (I get the same error for a larger set of documents as well). I replicated the problem in Juptyer notebook with a dump of the problematic document set (embedded in issue below as well).
corpus = CorpusFromPandas(df,
category_col='category',
text_col='DESCRIPTION',
clean_function = clean_text,
nlp=nlp).build()
sc = ScatterChartBokeh(corpus)
chart_dict = sc.to_dict(category='a', category_name='a', not_category_name='b',)
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\scipy\stats\_distn_infrastructure.py:1732: RuntimeWarning: invalid value encountered in true_divide
x = np.asarray((x - loc)/scale, dtype=dtyp)
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\scipy\stats\_distn_infrastructure.py:879: RuntimeWarning: invalid value encountered in greater
return (self.a < x) & (x < self.b)
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\scipy\stats\_distn_infrastructure.py:879: RuntimeWarning: invalid value encountered in less
return (self.a < x) & (x < self.b)
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\scipy\stats\_distn_infrastructure.py:1735: RuntimeWarning: invalid value encountered in greater_equal
cond2 = (x >= self.b) & cond0
ValueError Traceback (most recent call last)
<ipython-input-284-557009ffbd72> in <module>()
1 chart_dict = sc.to_dict(category='a',
2 category_name='a',
----> 3 not_category_name='b',)
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\scattertext\ScatterChart.pyc in to_dict(self, category, category_name, not_category_name, scores, transform)
473 if self.scatterchartdata.term_significance:
474 json_df['p'] = df['p']
--> 475 self._add_term_freq_to_json_df(json_df, df, category)
476 json_df['s'] = percentile_min(df['color_scores'])
477 json_df['os'] = df['color_scores']
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\scattertext\ScatterChart.pyc in _add_term_freq_to_json_df(self, json_df, term_freq_df, category)
512 json_df['ncat25k'] = (((term_freq_df['not cat freq'] * 1.
513 / term_freq_df['not cat freq'].sum()) * 25000)
--> 514 .apply(np.round).astype(np.int))
515
516 def _get_category_names(self, category):
C:WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\pandas\util\_decorators.pyc in wrapper(*args, **kwargs)
89 else:
90 kwargs[new_arg_name] = new_arg_value
---> 91 return func(*args, **kwargs)
92 return wrapper
93 return _deprecate_kwarg
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\pandas\core\generic.pyc in astype(self, dtype, copy, errors, **kwargs)
3408 # else, only a single dtype is given
3409 new_data = self._data.astype(dtype=dtype, copy=copy, errors=errors,
-> 3410 **kwargs)
3411 return self._constructor(new_data).__finalize__(self)
3412
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\pandas\core\internals.pyc in astype(self, dtype, **kwargs)
3222
3223 def astype(self, dtype, **kwargs):
-> 3224 return self.apply('astype', dtype=dtype, **kwargs)
3225
3226 def convert(self, **kwargs):
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\pandas\core\internals.pyc in apply(self, f, axes, filter, do_integrity_check, consolidate, **kwargs)
3089
3090 kwargs['mgr'] = self
-> 3091 applied = getattr(b, f)(**kwargs)
3092 result_blocks = _extend_blocks(applied, result_blocks)
3093
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\pandas\core\internals.pyc in astype(self, dtype, copy, errors, values, **kwargs)
469 def astype(self, dtype, copy=False, errors='raise', values=None, **kwargs):
470 return self._astype(dtype, copy=copy, errors=errors, values=values,
--> 471 **kwargs)
472
473 def _astype(self, dtype, copy=False, errors='raise', values=None,
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\pandas\core\internals.pyc in _astype(self, dtype, copy, errors, values, klass, mgr, **kwargs)
519
520 # _astype_nansafe works fine with 1-d only
--> 521 values = astype_nansafe(values.ravel(), dtype, copy=True)
522 values = values.reshape(self.shape)
523
C:\WinPython-64bit-2.7.10.3\python-2.7.10.amd64\lib\site-packages\pandas\core\dtypes\cast.pyc in astype_nansafe(arr, dtype, copy)
618
619 if not np.isfinite(arr).all():
--> 620 raise ValueError('Cannot convert non-finite values (NA or inf) to '
621 'integer')
622
ValueError: Cannot convert non-finite values (NA or inf) to integer
corpus.get_texts().tolist()
[u" The invention may be more completely understood in consideration of the following detailed description of various embodiments of the invention in connection with accompanying figures, in which: is a perspective view of a conventional manual wheelchair with manually operated brake mechanism. is a front view of a conventional manual wheelchair with manually operated brake mechanism. is a rear view of a wheelchair brake mechanism according to an example embodiment of the present invention is a partial exploded rear view of a wheelchair brake mechanism according to an example embodiment of the present invention. is a side view of a wheelchair brake mechanism in an engaged position according to an example embodiment of the present invention. is a side view of a wheelchair brake mechanism in a disengaged position according to an example embodiment of the present invention. is a side view of a wheelchair brake mechanism in an engaged position and showing how portions of said mechanism move to a disengaged position according to an example embodiment of the present invention. is rear partial cross section view of a wheelchair brake mechanism in an engaged position according to an example embodiment of the present invention. is rear partial cross section view of a wheelchair brake mechanism in an engaged position and showing how portions of said mechanism move to a disengaged position according to an example embodiment of the present invention. is a side view of a wheelchair brake mechanism in an engaged position showing how portions of said mechanism move to a disengaged position according to an example embodiment of the present invention. is an enlarged view of according to an example embodiment of the present invention. is a side view of another embodiment of a wheelchair brake mechanism in a disengaged position according to an example embodiment of the present invention. is a side view of another embodiment of a wheelchair brake mechanism in an engaged position according to an example embodiment of the present invention. is a side view of an attendant controlled brake release assembly of a wheelchair brake mechanism according to an example embodiment of the present invention. is an end view of an attendant brake release assembly of a wheelchair brake mechanism according to an example embodiment of the present invention. is a cross section view of an attendant brake release assembly of a wheelchair brake mechanism according to an example embodiment of the present invention. is a side view of an attendant brake release assembly of a wheelchair brake mechanism according to an example embodiment of the present invention. is a side view of a wheelchair brake mechanism according to an example embodiment of the present invention. is a side view of a wheelchair brake mechanism according to an example embodiment of the present invention. is a rear view of a wheelchair brake mechanism according to an example embodiment of the present invention. is a top view of a wheelchair brake mechanism according to an example embodiment of the present invention. is an enlarged view of a portion of . is a side view of an attendant break release assembly and a friction brake assembly according to an example embodiment of the present invention. is a side view of an attendant break release assembly and a friction brake assembly according to an example embodiment of the present invention. is an end view of an attendant break release assembly and a friction brake assembly according to an example embodiment of the present invention. While the present invention is amenable to various modifications and alternative forms, specifics thereof have been shown by way of example in the drawings and will be described in detail. It should be understood, however, that the intention is not to limit the invention to the particular embodiments described. On the contrary, the intention is to cover all modifications, equivalents, and alternatives falling within the spirit and scope of the invention as defined by the appended claims. collectively illustrate a wheelchair with a weight-actuated brake mechanism, indicated by numeral 100, to control the free movement of the wheelchair. Referring generally to , and particularly to , typically two wheelchair brake mechanisms 100(in an exploded view) and 100are attached to a wheelchair 102. Each wheelchair brake mechanism 100and 100controls the rotational movement of each of drive wheels 110and 110respectively. The following description of the wheelchair brake mechanisms 100and 100will be discussed singularly, but it should be noted that it applies equally to both mechanisms 100and 100 The wheelchair brake mechanism 100includes at least one support structure 200 comprising an elongate bar that is pivotally coupled to a portion of the foldable frame 108. Although an elongate bar is shown and discussed as one of the example embodiments, it should also be noted that the support structure 200 may also comprise a rod or other similar component. The support structure 200 is preferably disposed generally between a respective drive wheel 110110and the foldable frame 108. At least a portion of the support structure 200 is disposed generally proximate the drive wheel 110such that it may engage the drive wheel 110and prevent rotational movement thereof as a user enters or leaves the seat 104. Referring to , 5B and 5C, the support structure 200 includes first 202 and second 204 opposed ends. Referring to , the support structure 200 is pivotally couplable to a support bracket 210 that is mountable to a portion of the foldable frame 108 of the wheelchair. In an example embodiment, the support bracket 210 is disposed on a rear portion of the foldable frame 108 defining the backrest of the wheelchair 106. The support bracket 210 is disposed generally proximate a juncture between the backrest 106 and the seat 104 (shown in ). The support bracket 210 includes a plate portion 212 that is mountable to the foldable frame 108 with at least one fastener 214, such as a screw, bolt, or like device. Fastener 214 preferably replaces existing fasteners fastened to the wheelchair 102. By using the pre-existing mounting holes or fastening points on an existing wheelchair, the present invention is easily and quickly retro-fittable to variety of wheelchairs without the need to make modifications such as drilling holes. In one example embodiment, plate portion 212 may have a generally arcuate or curved shape to accommodate the foldable frame 108 of the wheelchair 102. The support bracket 210 also includes a flange portion 216 traversing away from an outer surface of the plate portion 212. A fastener 218 and coupler 219 pivotally couples the support structure 200 to the flange portion 216 of the support bracket 210. Any fastener may be used, such as a bolt and nut that would permit pivotal movement between the support structure 200 and the flange portion 216. To facilitate locking and unlocking the drive wheels 110and 110of the wheelchair 102, the support structure 200 includes at least one braking lever 250 and at least one sensing lever assembly 300 extending away from the first 202 and second 204 ends respectively. Only one brake mechanism 100or 100is necessary to accomplish the desired braking function of the wheelchair 102. However, it is most common to pair a first 100and a second 100braking mechanism with the opposing wheels 110and 110It should be noted that the operation of braking mechanism 100is separate and not dependant on operation of braking mechanism 100and vise-versa. The independent operation is facilitated, in part, by each brake mechanism 100and 100having its own respective sensing lever assembly 300. The braking assembly has a default engaged position, as illustrated in , and disengaged position, as illustrated in . shows the engaged position with the disengaged position superimposed along with directional arrows indicating the direction of movement of the indicated components. In the engaged position, braking lever 250 is disposed adjacent to and confronts a portion of the drive wheel 110preventing it from rotating freely. In the disengaged position, the braking lever 250 is disposed sufficient distance away from the drive wheel 110to allow it to freely rotate. Sensing lever assembly 300 facilitates rotational movement or pivoting of the support structure 200 from the engaged position toward the disengaged position when a user is entering or leaving the wheelchair 102. Referring back to , braking lever 250 traverses away from the support structure 200 and extends generally toward the drive wheel 110In one example embodiment, the braking lever 250 extends away from the support structure 200 at generally a ninety-degree angle, such that the support structure 200 has a generally L-shape. Other angles and shapes such as C-shaped, J-shaped, S-shaped and other similar shapes are also envisioned to be within the spirit and scope of the invention. In one example embodiment of the invention, the braking lever 250 is integral to the support structure 200. In other embodiments of the invention the braking lever 250 may be detachably coupled to the support structure 200 to permit modification according to the wheelchair 102 being outfitted with the brake mechanism 100 Braking lever 250 comprises a generally rectangular plate or bar having a length generally greater than a width of the drive wheel 110The braking lever 250 also has an upper peripheral edge portion 252 and a lower peripheral edge portion 254. The lower peripheral edge portion 254 engages or confronts the drive wheel 110when the support structure 200 is in the engaged position. In an example embodiment, the lower peripheral edge portion 254 is generally linear however; it may also have a generally curvilinear or arcuate shape such that it mimics the arcuate shape of the drive wheel 110The generally arcuate shape provides more surface contact between the braking lever 250 and the drive wheel 110thereby increasing rotational resistance. Continuing with , the brake mechanisms 100and 100include a biasing or tension member 260 such as a coiled spring or adjustable elastomeric strap that is coupled to and extends generally between either the support structure 200 and a portion of the foldable frame 108 or between the braking lever 250 and a portion of the foldable frame 108. The biasing member 260 maintains support structure 200 in the default engaged position, as illustrated in , when a user is not seated in the seat 104 of the wheelchair 102. By having the engaged position as the default position, the drive wheels 110and 110remain locked when the user is not seated, thereby immobilizing the wheelchair 102 and providing a stable structure for the user. Since the wheelchair 102 is immobilized, a user entering or leaving the seat 104 of the wheelchair 102 will have a significantly reduced chance of falling due to the wheelchair 102 coming out from under them. Referring back to , the biasing member 260 includes a first end 262 and a second end 264. The first end 262 is detachably coupled to either the braking lever 250 or the support structure 200. In one example embodiment, the second end 264 is detachably coupled to a portion of the foldable frame 108 such as illustrated in . In this example embodiment, the second end 264 of the biasing member 260 includes a hook or S-shape hook member 265 attached thereto to facilitate detachable coupling of the biasing member 260 to a portion of the foldable frame 108. The second end 264 of the biasing member 260 may be detachably coupled to a portion of the axle assembly 275 of the drive wheel 110extending through a portion of the foldable frame 108 and secured thereto by a coupler 276 such as a nut or similar component. However, the second end 264 of the biasing member 260 may be attached anyplace on the wheelchair 102 that facilitates its ability to maintain the support structure 200 in the engaged position. In other example embodiments of the invention, the second end 264 of the biasing member 260 is coupled to an adjustable coupler 270 that is coupled to a portion of the foldable frame 108 to permit a user to adjust its length and thereby the tension that the biasing member 260 exerts upon the support structure 200. In one example embodiment of the invention, as illustrated in , the adjustable coupler 270 may include a turnbuckle portion 272 and a threaded eyelet or hook portion 274. Rotation of the threaded eyelet portion 274 in a clockwise direction shortens the length of the adjustable coupler 270, thereby requiring the biasing member 260 to be stretched in order for the threaded eyelet portion 274 to be coupled to the foldable frame 108. In another example embodiment, the biasing member 260 comprises an elongate generally elastomeric strap 260 having a plurality of spaced apertures or holes extending along a length thereof. In this example embodiment, adjustment is accomplished by changing the engagement point of the S-shaped hook 265 (or similar engagement device) to different apertures provided in the elastomeric strap. Other types of adjustable couplers 270 are also contemplated and considered to be within the spirit and scope of the present invention. As the user is seated, the support structure 200 moves from the engaged position to the disengaged position. Returning to though 5C, the sensing lever assembly 300 is operably coupled to the support structure 200 and positionable beneath the seat 104 to sense when a user is entering or leaving the wheelchair 102. In one example embodiment, as a user enters the wheelchair 102 the seat 104 travels in a downward vertical direction until it confronts and vertically displaces the sensing lever assembly 300. The downward movement of the sensing lever 300 assembly causes the support structure 200 to pivot or rotate from the engaged position toward the disengaged position. In the engaged position, the drive wheel 110is locked and not freely rotatable. With the user is seated, the support structure 200 in the disengaged position and the wheelchair 102 is freely moveable. Various configurations are contemplated for actuating the sensing lever assembly 300. In one example embodiment, as illustrated in , 6C and 7, the sensing lever assembly 300 comprises a sensor bracket 310 having leg portion 312 pivotally coupled to the support structure 200 and a foot portion 314 transversely extending therefrom that is in operable communication with the seat 104 of the wheelchair 102. The leg portion 312 is generally vertically or perpendicularly oriented with respect to a longitudinal axis of the support structure 200. The foot portion 314 is oriented at a generally ninety degree angle with respect to the leg portion 312 such that the sensor bracket 310 has a generally L-shape. However, other shapes are also contemplated for the sensor bracket 310, including but not limited to C-shaped, U-shaped, and J-shaped. Regardless of the shape utilized, the sensor bracket 310 is oriented such that the foot portion 314 extends generally beneath a portion of the foldable frame 108 defining the seat 104 of the wheelchair 102. Depending upon the weight of the user, it may be advantageous to be able to adjust the distance between the seat 104 of the wheelchair 102 and the foot portion 314. For example, a smaller user weighing less may need to decrease the distance to facilitate the seat 104 of the wheelchair 102 engaging the foot portion 314. A larger user weighing more may increase the distance to permit the user to become fully seated in the wheelchair 102 before the support structure 200 moves from the engaged position to the disengaged position. In one example embodiment of the invention, as illustrated in , 6C and 7, a seat engagement assembly 350 is operably disposed on the foot portion 314 to facilitate adjustment of the distance between the seat 104 of the wheelchair 102 and the foot portion 314. As particularly illustrated in the example embodiment of , the seat engagement assembly 350 comprises a stop 352 having a saddle portion 354 and a shaft portion 356 adjustably disposed on the foot portion 314. The saddle portion 354 has a generally arcuate or curvilinear shape to accommodate a tubular shape of the foldable frame 108. The shaft portion 356 may be threadedly coupled to the foot portion 314, such that rotation of the shaft portion 356 adjusts the height of the stop 352 and thus the distance between the seat 104 of the wheelchair 102 and the foot portion 314. At least one threaded nut, bolt or similar component 358 may be disposed on the shaft portion 356 to secure the stop 352 at a particular height with respect to the foot portion 314. As particularly illustrated in , a plurality of threaded nuts is utilized to secure the stop 352 to the foot portion 314. Other embodiments of the seat engagement assembly 350 may also be utilized. For example, a cable having a pair of opposed ends coupled to the support structures 200 of the braking mechanisms 100and 100may be used. An adjustable pneumatic cylinder and piston rod may also be utilized. shows the sensing lever assembly 300 in the position where the wheel is engaged and no movement is possible. This position corresponds with an absence of a patient seated in the chair. When the patient sits on the seat, the rails 107 of the foldable frame 108 move downward as indicated by the arrows in . The downward movement of the rails causes the seat engagement assembly 350 to move the sensing lever assembly 300 downward as shown, which, in turn, causes the wheel to be released for free movement. A wheelchair 102 with brake mechanisms 100and 100may be further enhanced by providing a means for bypassing the brake mechanism 100and 100when a user is not seated in the wheelchair 102. Such bypass means makes it easier for an attendant to transport an empty wheelchair that would otherwise have the brake mechanisms 100and 100engaged. In example embodiments, as illustrated in , 5B, 5C, 8A-12, and 17-18, a brake release assembly 400 is coupled to the foldable frame 108 and operably coupled to the support structure 200. In one of the example embodiments, the brake release assembly 400 comprises at least one hand release lever 402 pivotally couplable to handles of the wheelchair 102. A linkage 403 is coupled to and extends between the hand release lever 402 and the support structure 200 or braking lever 250. The hand release lever 402 is pivotable between a depressed position or state and released position or state. As an attendant depresses the hand release lever 402 toward the depressed state it pivots the support structure 200 from the engaged position toward the disengaged position. As an attendant releases the hand release lever 402 from the depressed state toward the released stated, the support structure 200 pivots from the disengaged position toward the engaged position. Referring now to and particularly to , the hand release lever 402 includes at least one flange 404 having an aperture or hole 405 for attaching at least one end of the linkage 403. A second end of the linkage 403 is detachably coupled to the support structure 200 or braking lever 250. In one example embodiment, the hand release lever 402 is preferably disposed generally above the handle of the wheelchair 102 to allow gravity to assist an attendant in applying the hand release lever 402. In one example embodiment of the invention, the hand release lever 402 may be manufacture from stainless steel. Additionally, the hand release lever 402 may have a generally textured outer surface and/or a contoured surface to facilitate gripping and/or comfort for an attendant grasping the hand release lever 402. Other configurations, materials and texturing are also contemplated by the present invention. Other materials may include aluminum, composite, polymer, or similar materials. The linkage 403 comprises a generally rigid rod or wire according to one embodiment. Linkage 403 may be manufactured from various other materials such as steel, aluminum, titanium, composite polymer, or fabric. Any device that would link the hand release lever 402 and the support structure 200 may be used and is contemplated by the present invention. A length adjustor 408 may be desirably disposed between a pair of linkage portions 406and 406to adjust an overall length of the linkage 403. The length adjustor 408 is used because the distance between the handles of the wheelchair 102 and the placement of the support structure 200 may vary depending upon the manufacturer of the wheelchair 102. The length adjustor 408 may comprise an elongate tube or cylinder having opposed open ends extending into an interior space thereof. Free ends of the linkage portions 406and 406may extend into the open ends of the length adjustor 408. Fasteners 410, such as screws, bolts or similar components may extend into the length adjustor 408 to engage and secure the linkage portions 406and 406in the interior of the length adjustor 408. Other devices such as turnbuckles may also be used to adjust the overall length of the linkage 403. In another example embodiment, a brake release coupling assembly 450 is provided to facilitate coupling the brake release assembly 400 to the wheelchair 102 without having to modify the wheelchair 102. In this example embodiment, as illustrated in and particularly , the brake release coupling assembly 450 comprises a pair of coupling members 460and 460detachably coupled together about the handle of the wheelchair 102. Referring to , each of the coupling members 460and 460includes a groove, recess or channel 462and 462extending into an inner surface thereof for receiving the foldable frame 108 defining the handles of the wheelchair 102. As illustrated in , when the coupling members 460and 460are coupled together grooves 462and 462define an aperture extending through at least a portion of the coupling members 460and 460As particularly illustrated in , each of the grooves 462and 462has a generally arcuate shape to accommodate the arcuate shape of the foldable frame 108. The grooves 462and 462may have various shapes, such as a generally linear or an approximately right angle depending upon the shape of the foldable frame 108. In another example embodiment, as illustrated in , each of the coupling members 460and 460may include a shoulder portion 466and 466respectively extending generally curvilinearly away therefrom. The grooves 462and 462of the coupling members 460and 460may extend along an inner surface of the shoulder portions 466and 466to accommodate a generally arcuate shape of the foldable frame 108. The coupling members 460and 460may be machined from steel, aluminum, polymers, composites and similar materials. Additionally, the hand release lever 402 and the coupling members 460and 460may have a silver ion coating, which has been shown to kill bacteria, viruses and other pathogens. To assemble the brake release assembly 400 each coupling member 460and 460is positioned adjacent to respective side of the foldable frame 108, such that the handles of the wheelchair 102 extend through the aperture defined by the coupling members 460and 460Referring again to , fasteners 424, such as screws, bolts and similar components, are utilized to couple the coupling members 460and 460together. The hand release lever 402 is pivotally coupled to the coupling members 460and 460with a fastener 426, such as a screw, bolt and similar components. Referring generally to and 8A-10B, and in particular, brake release assembly 400 may include a break release locking mechanism 500 operably coupled thereto to permit an attendant to maintain the support structure 200 in the disengaged position. In one example embodiment, a switch 510 is movably disposed to the coupling members 460and 460to selectively confront and prevent pivoting of the hand release lever 402 from the depressed state toward the released state. As discussed above, the support structure 200 is in the disengaged position when the hand release lever 402 is in the depressed state. Referring particularly to , an end of the switch is pivotally disposed in a notch 631 extending into a lower surface or bottom 632 of each of the coupling members 460and 460 Referring back to , the switch 510 is positionable between a first locked position at A, a second locked position at B, and a released position at C. While the switch 510 is in the released position C, the hand release lever 402 will move freely from the depressed state toward the released state. An attendant can temporarily hold the hand release lever 402 in the depressed state by moving the switch 510 to the first locked position A and letting the flange 404 confront the switch 510. The force exerted on the flange 404 by the biasing member 260 acting on the support structure 200 and the linkage 403 keeps the switch 510 in the first locked position A and prevents the hand release lever 402 from pivoting toward the released position. There are at least two methods for moving the switch 510 from the first locked position to the released C position. The first method occurs when a user sits in the seat 104 of the wheelchair 102. As a user sits down, the support structure 200 pivots from the engaged position toward the disengaged position causing the linkage 403 to at least slightly displace the hand release lever 402. The displacement of the hand release lever 402 reduces the pressure on the switch 510, thereby permitting gravity to act on the switch 510 and move it to the released C position. Permitting movement of switch 510 from the locked position A to the released position C when a user sits in the seat 104 ensures brake mechanism 100will move from the disengaged position toward the engaged position once the user attempts to rise up from the wheelchair 102. The second method of moving the switch 510 from the first locked position A to the released position C occurs when an attendant depresses hand release lever 402. Once the force created by the biasing member 260 acting on the support structure 200 and linkage 403 is removed from the switch 510, gravity freely moves it toward the released position C. An attendant can also keep the hand release lever 402 in the depressed stated by moving the switch 510 to the second locked position B and letting the hand release lever 402 confront switch 510. Once switch 510 is placed in the second locked position B, hand release lever 402 will not be able to move toward the released stated even if it is depressed again or a user sits in the seat 104 of the wheelchair 102. The switch 510 is maintained in the second locked position B, by a securing assembly 560 operably disposed in at least one of the coupling members 460or 460 In one example embodiment, as illustrated in , the securing assembly 560 comprises a coiled spring or other biasing member 562 disposed in a bore 566 extending through the coupling member 460or 460and into the notch 631. An engagement member 564, such as a ball bearing or similar device, is also disposed in the bore 566 and is biased against a portion of the switch 510 when it is in the second locked position B. The bore 566 may have a diameter slightly smaller than a diameter of the engagement member 564 or it may taper toward the notch 631, such that the engagement member 564 is prevented from completely escaping from the bore 566 when the switch 510 in not in the second locked position B. A fastener 568 may also be threadedly disposed in the bore 566 to facilitate removably retaining the securing assembly 560 in the bore 566. To permit the hand release lever 402 to move from the depressed state toward the released state, and simultaneously move the support structure from the disengaged position toward the engaged position, an attendant forces or pivots switch 510 toward release position C, whereby the biasing member 260 and linkage 403 force the hand release lever 402 to move from the depressed state toward the released state. In another embodiment, as illustrated in , a locking collar 570 may be tethered by a strap 572, chain or similar structure to the coupling portions 460and/or 460The locking collar 570 is operably couplable about the hand release lever 402 and the handle of the wheelchair 102 when the hand release lever 402 is in the depressed state. The locking collar 570 may comprise an annular ring or plate having an aperture extending therethrough for receiving the hand release lever 402 and the handle of the wheelchair 102. In other embodiments, the locking collar 570 may comprise a plate or ring having a C-shape, U-shape or similar shapes. In some instances it may not be advisable to have a wheelchair that can move freely when a user or patient is seated; for example, if the patient is suffering from Alzheimer's or other similar diseases that affects a patient's memory. In this instance, as illustrated in , the brake mechanisms 100and 100include only a support structure 200 and a braking lever 250 pivotally coupled to the foldable frame 108. There is no sensing lever assembly 300 to pivot the support structure 200 from the engaged position toward the disengaged position. As discussed above, the biasing member 260 extends between the support structure 200 or braking lever 250 and a portion of the foldable frame 108 to maintain the support structure 200 in the engaged position. When a user sits in the seat 104 of the wheelchair 102 it does not move the support structure 200 and braking lever 250 to the disengaged position. The brake release assembly 400 may be utilized to facilitate transport of either the patient seated in the wheelchair 102 or an empty wheelchair 102. In this example embodiment, the relationship of a user or patient's position in the seat 104 of the wheelchair 102 does not affect the brake mechanisms 100and/or 100In this particular example embodiment, securing assembly 560 may not be disposed in the bore 566 of one of the coupling members 460or 460Instead, a pin or similar structure may be securely or removably disposed therein to prevent the hand release lever 402 from being secured in the depressed state. This arrangement ensures that the wheelchair 102 is always locked unless an attendant is present. An attendant can still temporarily lock hand release lever 402 in position A to transport the wheelchair 102. However, as discussed above, as soon as a user is seated in the wheelchair 102 the switch 510 automatically moves to the released position C to ensure that the wheelchair 102 will be secured if the user attempts to rise up from the wheelchair 102. Occasionally, attendants transporting patients in wheelchairs 102 have to maneuver the wheelchairs 102 down an incline, such as a long sloping driveway, or a wheelchair access ramp of a building. Referring to , a friction brake assembly 600 may be coupled to a wheelchair 102 in conjunction with the brake mechanisms 100and 100Additionally, the friction brake assembly 600 may be used with () or without () the sensing lever assembly 300 pivotally coupled to the support structures 200. In one example embodiment, as illustrated in , the friction brake assembly 600 includes a control lever 610 comprising a plate portion 612 disposed adjacent to a top of the drive wheel 110and/or 110and an anchor portion 614. The plate portion 612 is oriented in a generally horizontal plane such that a lower surface of the plate portion 612 confronts the drive wheel 110and/or 110to slow rotation thereof while the wheelchair 102 is moving either on a flat surface or down an incline. In one embodiment, the anchor portion 614 is disposed between the drive wheel 110or 110and the foldable frame 108 and is oriented at a generally right angle to the plate portion 612. However, it is contemplated that the anchor portion 614 may be oriented at any angle with respect to the plate portion 612. As particularly illustrated in , the anchor portion 614 may be pivotally coupled to the support bracket 210, such that the support structure 200 and the anchor portion 614 have generally the same pivot point. A spacer (not shown) comprising a cylinder, washer or a similar structure, may be disposed between the anchor portion 614 and the support structure 200 to prevent operational interference. The plate portion 612 may have a front edge 620 and rear edge 622 corresponding with a front and rear of the wheelchair 102. The rear edge 622 of the plate portion 612 may have a generally smaller width than the front edge 620 such that the plate portion 612 has a generally triangular shape. The plate portion 612 may have any shape such as generally curvilinear or arcuate to accommodate the curvature of the drive wheels 110and 110Other shapes and configurations such as C-shaped, U-shaped, V-shaped are also contemplated and considered to be within the spirit and scope of the invention. As illustrated in and particularly , an attendant operated friction brake actuation lever 630 is pivotally coupled to the coupling members 460and 460to actuate the control lever 610. The brake actuation lever 630 is positioned generally below the handle of the wheelchair 102 and oriented generally parallel to the handle of the wheelchair 102. As shown in , the brake actuation lever 630 is pivotally disposed in an aperture 632 defined by grooves 634and 634extending into inner surfaces of the coupling members 460and 460 Referring to , a linkage 640 is coupled to and extends between the brake actuation lever 630 and either the plate portion 612 or the anchor portion 614 of the control lever 610. A length adjuster 408 may be disposed between a pair of linkage portions 642and 642to adjust an overall length of the linkage 640. The adjustment of the linkage 640 is identical to the adjustment of the linkage 403 described in detail above. In operation, as the wheelchair 102 accelerates down the incline, the attendant can squeeze the friction brake actuation lever 630 toward the handle of the wheelchair 102, and concurrently the linkage 640 pivots the control lever 610 causing the plate portion 612 to engage the drive wheel 110and/or 110By releasing the brake actuation lever 630, the plate portion 612 pivots away from and disengages the drive wheel 110and/or 110 In one embodiment, some or all of the components of the present invention are made from materials capable of withstanding the temperatures or harsh chemicals associated with autoclaving or sterilization. The materials capable of being autoclaved or sterilized include, but are not limited to, stainless steel, aluminum, composite polymers, and other materials known to one skilled in the art. Details of the present invention may be modified in numerous ways without departing from the spirit or scope of the present invention. For example, adjustable turnbuckles that adjust spring tension for different weight users could be replaced with a metal strap with a series of holes for different weight settings. Also, the hand release handles could utilize a clamp mounting mechanism to mount the handle on the back of the chair so that there would be no holes to drill to mount the brake system to the wheelchair. Various components of the present invention may be altered in shape or size without affecting the functionality of the device. Those skilled in the art will recognize other modifications or alternatives of the present invention without departing from the spirit or scope thereof. Although the present invention has been described with reference to particular embodiments, one skilled in the art will recognize that changes may be made in form and detail without departing from the spirit and scope of the invention. Therefore, the illustrated embodiments should be considered in all respects as illustrative and not restrictive. ",
u" The advantages of this invention will become apparent upon consideration of the following detailed disclosure of the invention, especially when taken in conjunction with the accompanying drawings wherein: is a schematic elevational view of a first embodiment of a powered running board for use on automotive vehicles, the lowered operating position of the running board and associated linkage being shown in phantom; is a schematic elevational view of a second embodiment of a powered running board for use on automotive vehicles depicting the range of movement available to such running board configurations, the lowered operating position being shown in phantom; is a schematic representation of the control mechanism for use with automotive powered running boards; and is a logic flow diagram for the process of controlling a powered running board. Referring to , a control mechanism for a powered running board on an automotive vehicle incorporating the principles of the instant invention can be seen. The powered running board 10 can be manufactured in a number of different configurations. One representative configuration for the powered running board apparatus 10 is shown in . This configuration of running board is pivotally movable between a raised stored position 12 (shown in solid lines) and a lowered operating position 13 (shown in phantom), thus defining a range of operating movement 14 therebetween. The running board 15 is connected to a pivot mechanism 17, shown in as a four bar linkage 18, to pivotally support the running board 15 throughout the range of movement 14. An actuator 19 powers the pivotal movement of the four bar linkage 18, and is typically a linear actuator 19, or an electric motor configured to convert rotary motion of the motor into linear movement of the four bar linkage 18. The four bar linkage 18 keeps the tread or step surface of the running board 15 level throughout the range of operation. Referring now to , a different embodiment of a powered running board is depicted. In this configuration, the running board 15 is supported on threaded upright members 21 that are received within corresponding threaded receivers 22. An actuator 25, typically in the form of an electric motor 26, rotates the threaded receiver to transmit translational movement of the threaded upright member 21, thus raising and lowering the running board 15 between the raised stored position 12 (shown in solid lines) and the lowered operating position 13 (shown in phantom lines), defining the range of operating movement 14 therebetween. As one of ordinary skill in the art will recognize, the threaded receivers 22 must be rotationally supported on the frame 5 of the automotive vehicle by bearings or the like (not shown) and coupled to the actuator 25. To effect parallel movement of the running board 15, all of the threaded receivers 22 will simultaneously rotated to cause translational movement of the corresponding upright members 21. The use of an electric motor 26 for the actuator 19, 25 provides the ability to have significant control of the operation of the powered running board 15. Electronic sensors can sense the position or the extent of rotation of the electric motor 26 and, thus, provide consistent repeatability of the position of the electric motor 26 whenever the actuator 19, 25 is engaged. Accordingly, the vertical position of the running board 15 within the operating range 14 can be repeated with great accuracy, irrespective of the configuration of the apparatus permitting vertical movement of the running board 15. Referring now to , a schematic diagram of the control system 30 incorporating the principles of the instant invention can best be seen. The control system 30 includes a central control module 31 operable to receive and transmit signals to the other components of the system 30. The control module 31 is electrically connected to the drive mechanism 19, 25, 26 for each of the left and right side running boards 15 independently to permit individual operation thereof. The control module 31 is also electrically connected to a position switch mechanism 33 that is used to manually operate each of the left and right side motors 26 for the corresponding running boards 15. The switch mechanism 33 can include individual switches for the left and right side operation or a single switch with a cooperative left/right operational switch. Typically, this switch mechanism 33 will include a toggle switch or the equivalent to permit use thereof in the up and down directions. The control module 30 is also connected to a memory module 35 which can be a part of the existing memory module (not shown) in modern automotive vehicle to control positions of mirrors and seats, or the memory module 35 can be a separate memory bank that is incorporated into the control module 31. Ancillary to the memory module 35 can be an optional selector switch 37 that is operative to store in the memory module 35 selected positions for multiple users or other pre-set positions that can be stored in the memory module 35. During operation, the control module 30 can provide a drive signal 41 to each respective left and right drive motor 26 to effect operation thereof to move the corresponding running board 15 in the desired direction. Each drive motor 26 is also operative to provide a feedback signal 43 to the control module 31 to indicate the rotated position of the drive motor 26 being operated, and consequently, the operating position (vertical height) of the corresponding running board 15. The control module 31 is also operable to receive input signals from various components of the vehicle to indicate status of the component to provide an operative interlock system through the control module 31. For example, the opening of a door (not shown) can initiate power to the drive motor 26 for the corresponding running board 10. A sensor can provide an input signal 44 to the control module 31 to be indicative of whether the vehicle is moving or if the transmission is in a predetermined position, thus controlling the transmission of the drive signal 41. In operation, as reflected in the logic flow diagram of , the input signal from one or more vehicle sensors at step 51, such as the signaling of the opening of a vehicle door at step 52, initiates the query as to whether all conditions permit the deployment of the running boards at step 55. For example, the opening of the door at step 52 would normally initiate the deployment of the running board 10 on the corresponding side of the vehicle; however, should another sensor indicate that the vehicle is moving, deployment of the running board 10 should not be started. Accordingly, if all of the sensed vehicle conditions at step 55 indicates that deployment should not occur, then changing vehicle conditions at step 53 would be repeated until all the preselected sensor criteria is met. At step 57, the subsequent query is whether a memory position has already been stored in memory. If not, the running board 10 would have to be manually deployed through the switch 33 at step 58 until a desired position is established and that position is then automatically stored in the memory module 35 at step 59. If the memory module 35 already has a position stored, the next query at step 60 is whether multiple positions are stored. If so, user identification needs to be inputted prior to step 61 and deployment of the running board 10 is then accomplished at step 62 according to the position selected from the memory module 35. If multiple positions are not stored in the memory module 35, the running board 10 is deployed to the last stored position at step 65. Once the vehicle door is closed at step 67, the running board 10 is then returned to the retracted position 12 at step 68. The control system 30 will also be operative to deploy the running board to the last deployed position when the vehicle door is opened from the outside, assuming that all other conditions at step 51 are satisfied. Assuming that the vehicle is parked and is not being operated, the driver would approach the vehicle and open the door in a normal manner. The process would go through the steps from step 52 with the sensor indicating the opening of the vehicle door. Since the vehicle is parked and not operating, all of the other preselected conditions should be satisfied at steps 51 and 55. Assuming further that the vehicle had been previously operated or otherwise has a pre-stored position of deployment in the memory module 35, the query at step 57 is positively answered. At step 60, no user identification would have been provided so the running board 10 would then be deployed to the previously deployed position at step 65. One skilled in the art will realize that the memory module 35 could also be used to store pre-set deployment positions, such as 50% or 100% of the movement range 14, being used in deployment of the running board 10. Such pre-established deployment positions could be used in lieu of the user defined positions inputted by the control 37 and the process at step 61. The last stored position will be saved in the memory module 35 until a new position is stored therein. Accordingly, once the position of the running board 15 is stored in the memory module 35, the control module 31 will send a drive signal 41, when properly initiated, until the feedback signal 43 indicative of the return of the running board 15 to the pre-selected position has been obtained from the corresponding drive motor 26. With the utilization of the proper vehicle input signals 44, the control module 31 can be operative to return the running board 15 to the raised stored position 12 whenever the door (not shown) is closed and automatically back to the last selected stored operative position whenever the door is opened. One skilled in the art will recognize that this control system 30 can be utilized to operate the running boards 15 on both sides of the vehicle or, alternatively, on just the driver's side of the vehicle with the passenger side being a conventional mechanical or normal powered movable running board 15. The position switches 33, 37 can be appropriately positioned for access by the proper occupant of the vehicle. It will be understood that changes in the details, materials, steps and arrangements of parts which have been described and illustrated to explain the nature of the invention will occur to and may be made by those skilled in the art upon a reading of this disclosure within the principles and scope of the invention. The foregoing description illustrates the preferred embodiment of the invention; however, concepts, as based upon the description, may be employed in other embodiments without departing from the scope of the invention. ",
u' shows a perspective view of a split bench seat incorporating the subject invention; is a view similar to but showing one seat portion in a tumbled position; is a view similar to but showing the entire seat in a tumbled position; shows a perspective view of an alternate seat configuration incorporating the subject invention; is a perspective rear view, partially broken away, of a cantilever mounted split bench seat; is a perspective view of a seat attachment structure incorporating the subject invention; is a perspective view of a striker/latch mechanism as utilized in the seat attachment structure of ; and is a perspective view of a cross member from the seat attachment structure of positioned over a fuel tank. shows a seat assembly 10 having a seat attachment structure 12 for mounting the seat assembly 10 to a vehicle underbody 14. The seat attachment structure 12 includes a seat bracket assembly that provides a common bracket configuration that can be used to mount any type of seat configuration. For example, in a second row of vehicle seats, the common bracket configuration can be used to mount either a pair of seats 16, 16separated by an aisle 18 (see ) or a split bench seat 20, as shown in . In either of these configurations, seats are unlatched and pivoted to a tumbled position to increase cargo space within a vehicle as needed. While the seat attachment structure 12 is described has being particularly beneficial to a second row configuration, it should be understood that seat attachment structure 12 could also be beneficial to other seating row configurations. The split bench seat 20 of , also referred to as a 60/40 split option, includes a first seat portion 20positioned on one lateral vehicle side, a second seat portion 20positioned on an opposite lateral vehicle side, and a third seat portion 20positioned between the first 20and second 20seat portions and supported by the second seat portion 20. As shown, the first seat portion 20is split from the second 20and third 20seat portions at 22. The first seat portion 20can be tumbled separately (see ) from the second 20and third 20seat portions to allow access to a third row of seating. The second 20and third 20seat portions can also be tumbled along with the first seat portion 20to increase cargo space, as shown in . The third seat portion 20is cantilevered mounted to the second seat portion 20at one lateral seat side 24 and is unsupported at an opposite lateral seat side 26 as indicated by gap 28. This feature allows the common bracket configuration to be used. In other words, the same bracket is used to mount a pair of seats 16, 16to the vehicle underbody 14 as is used to mount the split bench seat 20 to the vehicle underbody 14. This feature will be discussed in greater detail below. The third seat portion preferably has seat integrated restraints (SIR) 30 (see ). The SIR 30 includes a seat belt assembly having a lap belt portion and a shoulder belt portion. The SIR 30 has both lap belt and shoulder belt attachment points going directly to the third seat portion 20. This configuration makes installation of the split bench seat 20 into the vehicle more efficient and more cost effective, as well as providing an aesthetically pleasing appearance. The first 20and second 20seat portions preferably have seat restraint assemblies with attachment points supported by a vehicle frame member. The bench seat 20 with SIR 30 should include a very robust seat attachment structure 12. The seat attachment structure 12 can accommodate high seat loads including all seat loading for the third seat portion 20. The seat attachment structure 12 includes a unique seat bracket assembly 32 that effectively transfers the loads to vehicle body structures. The seat bracket assembly 32 includes a rear cross member 34 that extends in a generally lateral direction between first 36 and second 38 side rails. The first 36 and second 38 side rails extend in a generally longitudinal direction with the first side rail 36 being positioned on one lateral vehicle side 40 and the second side rail 38 being positioned at an opposite lateral vehicle side 42. The rear cross member 34 is fastened and/or welded at opposing ends to each of the first 36 and second 38 side rails. The rear cross member 34 includes a main body 50 with at least first 52 and second 54 extensions that are integrally formed within the main body 50. The first 52 and second 54 extensions extend in the longitudinal direction. A front cross member 56 extends in the lateral direction and is longitudinally spaced apart from the rear cross member 34. Thus, the front 56 and rear 34 cross members are generally parallel to each other, while the first 52 and second 54 extensions and the first 36 and second 38 side rails are generally parallel to each other. The seat bracket assembly 32 also includes first 60 and second 62 longitudinal members extending between the front 56 and rear 34 cross members. The first 60 and second 62 longitudinal members are generally parallel to the first 36 and second 38 side rails and are generally perpendicular to the front 56 and rear 34 cross members. The first longitudinal member 60 is attached at one end 64 to the first extension 52 and at an opposite end 66 to the front cross member 56. The second longitudinal member 62 is attached at one end 68 to the second extension 54 and at an opposite end 70 to the front cross member 56. A first striker 72 is mounted to the first extension 52 and a second striker 74 is mounted to the second extension 54. A third striker 76 is mounted to the first side rail 36 and a fourth striker 78 is mounted to the second side rail 38. As shown in , latches 80 (only one is shown) are mounted on the seats 16, 16, or 20, 20, 20and cooperate with the first 72, second 74, third 76, and fourth 78 strikers to selectively release the seats 16, 16or 20, 20, 20from the strikers 72, 74, 76, 78, allowing the seats 16, 16or 20, 20, 20to be moved to a tumbled position. A front mount provides pivotal movement to facilitate tumbling as known. The first extension 52 includes first 82 and second 84 mount portions that are separated by a first opening 86 and the second extension 54 includes third 88 and fourth 90 mount portions that are separated by a second opening 92. The first 86 and second 92 openings each include an apex 94 that extends into the main body 50. The first striker 72 extends across the first opening 86 and has one striker end mounted to the first mount portion 82 and an opposite striker end mounted to the second mount portion 84. The second striker 74 extends across the second opening 92 and has one striker end mounted to the third mount portion 88 and an opposite striker end mounted to the fourth mount portion 90. A transversely extending flange 96 is formed about a perimeter that defines the openings 86, 92. The transversely extending flange 96 increases structural strength. The first 86 and second 92 openings are preferably horseshoe or U-shaped openings; however, other opening shapes could also be used. The transversely extending flanges 96 preferably extend continuously about the perimeter that defines the U-shaped openings. Optionally, straps 98 could be mounted to the first 52 and second 54 extensions, respectively. shows an example of a strap 98. In this embodiment, one strap 98 would extend underneath the first longitudinal member 60. One strap end is mounted to the first mount portion 82 and an opposite strap end is mounted to the second mount portion 84. The strap ends are positioned on an opposite face of the first extension 52 from the first striker 72. A similar strap configuration would be used with the second longitudinal member 62 and second extension 54. Each strap end, as well as each striker end, is preferably bolted to the respective first 82, second 84, third 88, or fourth 90 mount portion with a single bolt 100, however, other attachment methods could also be used. The bolts 100 are also used to attach the first 72 and second 74 strikers to the first 52 and second 54 extensions. The straps 98 are preferably made from steel. The straps 98 provide an extra metal stack-up that prevents the bolts 100 that are used to attach the first 72 and second 74 strikers to the first 52 and second 54 extensions from pulling through a floor structure under high seat loads. As shown in , the rear cross member 34 is positioned vertically above, i.e. extends laterally over, a fuel tank 102. The fuel tank 102 is preferably a saddle type fuel tank that has a first lateral tank portion 104 and a second lateral tank portion 106 in fluid communication with each other via a narrower center tank portion 108. The first extension 52 is positioned on one side of the center tank portion 108 and the second extension 54 is positioned on an opposite side of the center tank portion 108. This configuration results in improved energy absorption properties. In order to further enhance the energy absorption properties of the rear cross member 34, the rear cross member 34 and first 52 and second 54 extensions are preferably formed from an ultra-high strength steel grade DP600 material. DP600 has excellent mechanical hardening properties. DP600 also has higher deformability, higher yield strength, and higher ultimate strength properties than steel materials traditionally used to form seating brackets. The high energy absorption, excellent work hardening and bake hardening properties of DP600 in combination with the structural configuration of the rear cross member provides excellent system integrity. Energy absorption is further enhanced by the vehicle underbody 14, i.e. the vehicle floor 14. The vehicle floor 14 is preferably formed from a front portion at the front of the seat assembly 10, shown most clearly in , and a rear portion at the rear of the seat assembly 10, shown most clearly in . The front portion of the vehicle floor 14 is preferably thicker than the rear portion, which assists in preventing forward seat travel during seat pull and which also minimizes local buckling. As discussed above, the seat attachment structure 12 includes the third striker mounted 76 to the first side rail 36 at one lateral vehicle side 40 and the fourth striker 78 mounted to the second side rail 38 at an opposite lateral vehicle side 42. The first 72 and second 74 strikers are positioned between the third 76 and fourth 78 strikers. In the split bench seat configuration, the first 72 and third 76 strikers provide the tumble feature for the first seat portion 20and the second 74 and fourth 78 strikers provide the tumble feature for the second 20and third 20seat portions. In the seat configuration with two separate seats 16, 16, the first 72 and third 76 strikers provide the tumble feature for one seat 16and the second 74 and fourth 78 strikers provide the tumble feature for the other seat 16 Thus, in either seating configuration, the seat bracket assembly 32 includes eight total attachment points for attaching seats 16, 16or 20, 20, 20to the vehicle underbody 14. There are four striker attachment points located at the rear of the seats 16, 16or 20, 20, 20and four pivot attachment points located at the front of the seats 16, 16or 20, 20, 20. The four striker attachment points comprise a first striker attachment point at the first strike 72, a second striker attachment point at the second striker 74, a third striker attachment point at the third striker 76, and a fourth striker attachment point at the fourth striker 78. The four pivot attachment points comprise a first pivot attachment point between one end of the front cross member 56 and the vehicle underbody 14, a second pivot attachment point between an opposite end of the front cross member 56 and the vehicle underbody, a third pivot attachment point between the front cross member 56 and the first longitudinal member 60, and a fourth pivot attachment point between the front cross member 56 and the second longitudinal member 62. As discussed above, in the split bench seat configuration, the third seat portion 20is cantilevered mounted at one lateral seat side 24 to the second seat portion 20and is unsupported at an opposite lateral seat side 26. In the configuration shown, the third seat portion 20is mounted at the one lateral seat side 24 at the second striker attachment point and at the fourth pivot attachment point. In other words, the third seat portion 20is only supported along the second longitudinal member 62. The third seat portion 20is supported at the second striker 74 mounted to the second extension 54 of the rear cross member 34, and at a pivot mount where the second longitudinal member attaches to the front cross member 56. The third seat portion 20is unsupported at the opposite lateral seat side 26 as indicated by the gap 28 between a seat bottom 110 of the third seat portion 20and a floor structure. The combination of a cantilevered SIR seat with a tumble option is very unique in the industry. Further, having the rear cross member 34 and first 52 and second 54 extensions formed from DP600 used in combination with the first 60 and second 62 longitudinal members provides a very robust seat/underbody joint that can accommodate high seating loads for this unique seating combination. It should be understood that various alternatives to the embodiments of the invention described herein may be employed in practicing the invention. It is intended that the following claims define the scope of the invention and that the method and apparatus within the scope of these claims and their equivalents be covered thereby. ',
u" is a rear perspective view of a vehicle incorporating a tailgate, with the tailgate shown in a generally horizontal open position, in accordance with the present invention. is a rear perspective view of the tailgate as it would be oriented in a generally vertical closed position on a vehicle, and with the pivotable molding in its latch engaged position, in accordance with the present invention. is a rear perspective view similar to , but with the pivotable molding in its latch disengaged position. is a rear perspective view of the tailgate, but with the tailgate frame outer panel not shown, in accordance with the present invention. is a rear exploded perspective view of the tailgate frame, without side moldings shown, in accordance with the present invention. is a rear perspective, partially sectioned view of the supplemental tailgate in accordance with the present invention. is a view, on an enlarged scale, illustrating encircled area 7 in . is a rear perspective, partially sectioned view similar to , but with the section cut taken at a different location. is a view, on an enlarged scale, illustrating encircled area 9 in . is a perspective view of a release lever in accordance with the present invention. is a rear perspective view of a movable frame portion of the supplemental tailgate, but without the guide brackets illustrated, in accordance with the present invention. is a rear perspective view of the movable frame portion, similar to , but without the lock rod assemblies illustrated. is a side sectional view of the supplemental tailgate in accordance with the present invention. is a partial cutaway, perspective view similar to , but illustrating the supplemental tailgate retracted into the closed tailgate according to a second embodiment of the present invention. is a perspective view illustrating the second embodiment of , but with the tailgate open and the supplemental tailgate in a partially extended position. is a perspective view of a guide rail, support tube, and latch assembly in accordance with the second embodiment of the present invention. is a view similar to , but without the guide tube shown. is a perspective view, on an enlarged scale, of a roller assembly, taken from encircled area 18 in is an end view, on an enlarged scale, of the guide rail, support tube, and latch assembly as taken along line 19-19 in . illustrate a tailgate 20 that mounts to a vehicle 24\u2014preferably a pickup truck. The tailgate 20 includes a supplemental tailgate 22 mounted therein. The vehicle 24 includes a box 26 that is defined by a left rear quarter panel 28, which forms a first vertical surface of the box 26; a right rear quarter panel 30, which forms a second vertical surface of the box 28; a bed 32, which extends between the two panels 28, 30 to form a cargo floor; and the tailgate 20, which is pivotable between a generally vertical closed position and a generally horizontal open position. The tailgate 20 includes a pair of conventional tailgate hinges 34 that preferably cooperate with the side panels 28, 30, and a pair of tailgate supports 36, which support the tailgate 20 when in its horizontal position. A tailgate handle 35 mounts to an outer panel 38, and functions in a conventional manner. The tailgate release mechanism connected to the handle 35, as well as tailgate latches, are conventional and well known in the art and so are not shown herein for clarity in describing the present invention. The tailgate 20 is comprised of a tailgate frame 37 including the outer panel 38, which forms the outer finished surface of the tailgate 20, and a tailgate frame inner panel 40, which mounts to the outer panel 38 and forms the inner surface and sides 42 of the tailgate 20. The outer panel 38 and inner panel 40 combine to form a pair of upper surfaces 41 with a gap 43 therebetween. A tailgate reinforcement strainer 44, tailgate reinforcement panel 46, and tailgate reinforcement channel 48 mount and provide structural support to the frame outer and inner panels 38, 40. Preferably, a left tailgate molding 50 and a right tailgate molding 52 mount on top of the upper surfaces 41. They may be made of colored plastic that is the desired color of the parts; this eliminates the need to paint them. In this way, the tailgate moldings 50, 52 will help to prevent paint scratches on metal parts when cargo is being loaded over the top of a closed tailgate 20. The components that make up the tailgate frame 37 are formed so that a hollow internal cavity is created. Within this cavity, the supplemental tailgate 22 is retained. The supplemental tailgate 22 includes a handle 54, a movable frame portion 56, and guide rails 58. The handle 54 shown is a pivotable molding 54. However, a variety of handles may be used with the supplemental tailgate 22. The guide rails 58 are hollow, and may be generally rectangular tubes that are fixed to the tailgate frame 37 and support the movable frame portion 56 as it is telescopically extended from and retracted into the guide rails 58. Each guide rail 58 includes pivot brackets 64 securely mounted on top that cooperate with the movable frame portion 56 to allow for both pivoting of the movable frame portion 56 relative to the tailgate 20 and preventing the movable frame portion 56 from being separated from the guide rails 58. The pivot brackets 64 may be fastened to the reinforcement channel 48, and the bottoms of the guide rails 58 may be fastened to the inner panel 40, in order to help secure the guide rails 58 to the tailgate 20. The movable frame portion 56 includes a pair of support tubes 62 that are each received telescopically in a respective one of the guide rails 58. Each of the guide rails 58 may include a block spacer 55 mounted therein against which the support tubes 62 can slide. The block spacers 55 may be formed of plastic to minimize potential scratching of the support tubes 62 as they slide relative to the guide rails 58. Each of the support tubes 62 includes a hinge pin 66 that cooperates with slots 65 in the pivot brackets 64, when fully extended, in order to allow for pivoting of the movable frame portion 56 relative to the guide rails 58 while still allowing the guide rails 58 to retain and support the support tubes 62. The hinge pins 66 may be secured to the support tubes by welding, interference fit, or some other suitable means. Each of the support tubes 62 also connects to a corresponding one of the latching assemblies 60. The latching assemblies 60 releasably fix the support tubes 62 to a certain limited number of telescopically extended positions relative to the guide rails 58. When extended out partially, the guide rails 58 will hold the support tubes 62 parallel to it, thus creating a longer effective bed for the truck when the tailgate 20 is in its horizontal position. Each of the movable frame portion's support tubes 62 are hollow so they can receive a respective one of the two latching assemblies 60 therein. More specifically, latch housings 78 extend through each of the support tubes 62 and connect, at their upper ends, to the lower ends of latch actuation rods 80 via retainer barrels 81. The upper ends of the latch actuation rods 80 are secured, via retaining clips 83, to release levers 82, which may be affixed to the pivotable molding 54, in order to form a release hinge 84. Even though, for some features of the supplemental tailgate 22, only the feature on the left or right side is shown, the supplemental tailgate 22 is generally symmetrical right to left, so the opposite side is just the mirror image of the feature shown on that first side. Accordingly, for the description herein, if the feature is shown on only a first side, the feature on the second, opposite side is presumed to be the mirror image of the feature shown on the first side. The lower ends of the latch housings 78 connect to latch return springs 85, which, in turn, are connected to the hinge pins 66. Also connected to the hinge pins 66 are linear guides 89. The linear guides 89 include sliders 91, which provide for surface contact with the inside of the guide rails 58. Each of the latch housings 78 also includes a longitudinally extending slot 93, within which is mounted a respective one of two latch blades 87. Each latch blade 87 is biased into its corresponding slot 93 by a latch blade spring 95. The springs 95 cause retention tabs 96, protruding from the latch blades 87, to extend through corresponding holes 97 in the support tubes 62. Also, when aligned, the retention tabs 96 are biased by the springs 95 to extend through engagement slots 98 in the guide rails 58 and through engagement slots 61 in insert plates 59. The insert plates may be secured to their respective guide rails 58 by detent covers 57. The engagement slots 61, 98 may be longer than the width of the corresponding retention tabs 96 and the insert plates 59 adjustable relative to their corresponding detent covers 57 in order to allow for small adjustments in the position of the support tubes 62 relative to the guide rails 58. This small adjustability may allow one to make sure that the top of the pivotable molding 54 is flush with the tops of the tailgate moldings 50, 52 when the supplemental tailgate 22 is in its stowed position. Each latch housing 78 also includes internal flanges 99, located within the slot 93, that engage with release ramps 100 on the latch blade 87. The movable frame portion 56 also includes a cross member assembly 68 that connects to the tops of the support tubes 62. The cross member assembly 68 may also include a pair of cross members 69and 69, post brackets 71 and lock rod brackets 67 that form a support frame 70. The cross member assembly 68 also includes a pair of hollow tubes 72 and six pivot mounts 73 mounted on the support frame 70. The support frame 70 may be formed strong enough to support the weight of one or more people standing on it. This way, when the movable frame portion 56 is extended out and pivoted downward toward the ground, the support frame 70 can be used as a step. The hollow tubes 72 may each telescopically receive a respective one of two lock rod assemblies 74, which each have pivot hinges 75 at one end of a rod 126 and lock rod latches 76 at the far ends. The pivot hinges 75 allow the lock rod assemblies 74 to be extended toward the truck so that the lock rod latches 76 can hook to supports 79 on the truck box 26 in order to allow the movable frame portion 56 to be held in its upright position, thus creating a box extender. Where the handle is a pivotable molding 54, the pivot mounts 73 connect to and mount the pivotable molding 54 about a pivot axis 77. More specifically, the pivotable molding 54 may be formed from plastic, or other suitable material, such as, for example, a thirty percent glass filled polypropylene. The release levers 82 may be molded into the pivotable molding 54 while it is being formed or affixed thereto after forming by, for example, friction welding. Each release lever 82 includes a base 86 that is adjacent to the pivotable molding 54, a pivot flange 88 extending from one end of the base 86, and a release flange 90 extending from the other end. Each pivot flange 88 pivotally mounts about one of the pivot mounts 73 and is secured with a hinge rod 92. The pivot flange 88, then, will allow the pivotable molding 54 to pivot about the pivot axis 77. Each release flange 90 is offset from the pivot axis 77 and is connected to one of the latch actuation rods 80. Thus, when the pivotable molding 54 is pivoted, the release flanges 90 will pull up on the latch actuation rods 80. The latching assemblies 60 unlatch, allowing the support tubes 62 to slide relative to the guide rails 58, when the latch actuation rods 80 are pulled upwards, and re-engage when the latch actuation rods 80 are released. The pivotable molding 54 may be molded with the plastic being the desired final color so that it does not have to be painted. The pivotable molding 54 may also include a handle pocket 94 that is molded into the rear surface of the pivotable molding 54. The handle pocket 94 provides for ease of gripping and pivoting the pivotable molding 54 when deploying the supplemental tailgate 22. The pivotable molding 54 may also have an overall width that is just smaller than the gap 43 formed between the two tailgate moldings 50, 52, and has a top surface that is flush with the top surfaces of the two tailgate moldings 50, 52. Additionally, if so desired, the two tailgate moldings 50, 52 may include recessed flanges (not shown) that nest under the edges of the pivotable molding 54. Accordingly, the supplemental tailgate 22, when using a pivotable molding type handle and when in its fully retracted position, will blend-in with the tailgate 20, having an appearance that is very similar to a tailgate that does not include a supplemental tailgate. Thus, the supplemental tailgate 22 can be included without detracting from the esthetically pleasing look of the vehicle, and, moreover, the pivotable molding 54 will still allow for cargo to be slid into and out of the box 26 over the top of a closed tailgate 20 without creating paint scratch concerns. The operation of the supplemental tailgate 22 will now be described. The supplemental tailgate 22 may be easily released from its stowed position within the tailgate 20 while the tailgate 20 is in its open or closed position. Although, for the most advantageous use of the supplemental tailgate functions, the tailgate 20 will be in its horizontal open position. One may, if so desired, employ an extra latching mechanism (not shown) that may only allow release of the supplemental tailgate 22 when the tailgate is in its horizontal position. To deploy the supplemental tailgate 20 from its stowed position, one grasps the pivotable molding 54 and pivots it relative to the pivot axis 77. This will cause the release flanges 90 to pull up on the latch actuation rods 80, which, in turn, will pull up on the latch housings 78 against the bias of the latch return springs 85. As the latch housings 78 move upward, the internal flanges 99 slide along the release ramps 100, which causes the latch blades 87 to begin sliding against the bias of the latch blade springs 95. As the latch blades 87 slide outward, the retention tabs 96 slide out of the engagement slots 61, 98, thus releasing the movable frame portion 56 and allowing it to slide relative to the guide rails 58. Springs (not shown) may be provided to bias the movable frame portion 56 away from the tailgate frame 37 when the latching assemblies 60 are released, but are not necessary for operation of this invention. One then pulls on the supplemental tailgate 22 to telescopically slide the support tubes 62 relative to the guide rails 58, while allowing the pivotable molding 54 to pivot back into its latch engaged position. Once the movable frame portion 56 is slid out to a predetermined extended position relative to the tailgate 20, the retention tabs 96 on the lower end of the latch blades 87 will engage an engagement slot 53 or engagement slot 61 (depending upon how far the support tubes 62 are slid prior to releasing the pivotable molding 54), thus fixing the movable frame portion 56 relative to the guide rails 58. Also, at these extended positions, the support tubes 62 still remain partially within the guide rails 58 so that the two will not pivot relative to one another. With the tailgate 20 in its horizontal open position, the supplemental tailgate 22 is now in its bed extender position. While only a limited number of bed extender positions are discussed herein, the supplemental tailgate 22 may have additional bed extender positions by providing additional engagement slots, if so desired. The pivotable molding 54 may then be pivoted again to release the latching assemblies 60 once more. One may then pull the supplemental tailgate 22 out to its fully extended position relative to the open tailgate 20. In this fully extended position, the support tubes 62 will be pulled out of the guide rails 58, with the hinge pins 66 engaged in the slots 65 of the pivot brackets 64. The movable frame portion 56, from its fully extended position, can be pivoted into a downward extending vertical position to serve as a step, with the support frame 70 acting as the step. In this downward position, the pivotable molding 54 is on the underside of the movable frame portion 56, so it will not be stepped-on and damaged by the operator. Also, the support tubes 62 may be short enough that the pivotable molding 54 is spaced above the ground upon which the vehicle is standing. In this way, the molding 54 will not be scraped or damaged by contact with the ground, and the support frame 70, being higher off of the ground, will provide a better assist step function. The movable frame portion 56, from its fully extended position, can also be pivoted upward into an upward extending vertical position, to serve as a box extender. The lock rod assemblies 74 are deployed and latched onto the hook supports 79 on the box 26 in order to hold the movable frame portion 56 in the upright position. The hook supports 79 may be just the existing pin strikers that are normally used to hold the tailgate 20 in its closed position. In this way, the vehicle 24 is essentially the same, with the only difference being whether a conventional tailgate or the tailgate 20 of the present invention is mounted on the vehicle 24. Additionally, when the tailgate 20 is closed and the movable frame portion 56 is in its partially extended position, the supplemental tailgate 22 can serve a supplemental roof rack function. The top of the pivotable molding 54 will work in conjunction with the roof of the cab (not shown) in order to provide support for very long objets, such as ladders, canoes, etc. Performing the deployment operation generally in reverse will allow one to easily stow and latch the supplemental tailgate 22 back into the tailgate 20. Hence, a robust, easy to operate and ergonomic supplemental tailgate 22 is provided for the vehicle 24. While the latching assemblies 60 are shown connected to and actuated by the pivotable molding 54, they may be connected to and actuated by a more conventional handle instead, if so desired. illustrate a second embodiment of the present invention. This embodiment is similar to the first embodiment, except that the guide rails 58\u2032, support tubes 62\u2032, and latching assemblies 60\u2032 of the supplemental tailgate 22\u2032 are modified. The guide rails 58\u2032 are still mounted within the tailgate 20 of the vehicle 24, preferably with the pivotable molding 54 still employed for releasing the latching assemblies 60\u2032. The movable frame portion 56\u2032 now includes a pair of roller assemblies 178, one each pivotally connected to a respective one of the support tubes 62\u2032. Each roller assembly 178 includes a linear guide 184 having a pin boss 188 extending from a first end. Each pin boss 188 includes a bore that receives a respective one of the hinge pins 66\u2032. This arrangement translationally couples the roller assemblies 178 to their respective support tubes 62\u2032 while still allowing the support tubes 62\u2032 to pivot relative to the roller assemblies 178. The roller support assemblies 178 also include a pair of upper roller guides 182 mounted to the linear guides 184, and a pair of lower roller guides 180 also mounted to the linear guides 184. Preferably, the lower roller guides 180 include some type of fastener mechanism, such as rivet pins, that extend through the linear guide 184 and upper roller guide 182 and hold the three components together. The upper and lower roller guides 182 and 180 help maintain the proper orientation of each support tube 62\u2032 within its respective guide rail 58. Each roller support assembly 178 also includes a roller 186 that is mounted to its respective linear guide 184 with some type of fastener mechanism, such as a rivet pin, which allows each roller 186 to rotate relative to its linear guide 184. These rollers 186 will also help maintain the proper orientation of the support tubes 62\u2032 relative to the guide rails 58\u2032. Also, mounted to each pivot bracket 64\u2032 is a first guide block 174 and a second guide block 176. These guide blocks 174 and 176 help to support and to maintain the support tubes 62\u2032 in the proper orientation as they are slid into and out of the guide rails 58\u2032. Moreover, the second guide blocks 176 are generally U-shaped and receive respective lower roller guides 180 within the U-shape when support tubes 62\u2032 are almost fully extended. This arrangement further reduces the chances for binding of the support tubes 62\u2032 in the guide rails 58\u2032. The roller assembly 178 disclosed in this second embodiment provides for improved travel smoothness over the first embodiment. That is, as the support tubes 62\u2032 are being slid into and out of the guide rails 58\u2032, the operator will generally feel a smoother telescoping motion. Moreover, the guide assembly 178, along with the first and second guide blocks 174 and 176, reduces the risk that the movable frame portion 56\u2032 will bind relative to the guide rails 58\u2032. Otherwise, the second embodiment operates the same as the first embodiment, and so will not be discussed further. While certain example embodiments of the present invention have been described in detail, those familiar with the art to which this invention relates will recognize various alternative designs and embodiments for practicing the invention as defined by the following claims. ",
u" The above features and advantages will be readily apparent from the following detailed description of example embodiment(s). Further, these features and advantages will also be apparent from the following drawings. is a block diagram of a vehicle illustrating various components of the powertrain system; show a partial engine view; show various schematic system configurations; FIGS. 3A1-3A2 are graphs representing different engine operating modes at different speed torque regions; , 4-5, 7-11, 12A-12B, 13A, 13C1-C2, and 16-20 and 34 are high level flow charts showing example routines and methods; FIGS. 6A-D, 13B1-13B2 and 13D1-13D2 are graphs show example operation; show a bifurcated catalyst; contains graphs showing a deceleration torque request being clipped via a torque converter model to keep engine speed above a minimum allowed value; show engine torque over an engine cycle during a transition between different cylinder cut-out modes; show Fourier diagrams of engine torque excitation across various frequencies for different operating modes, and when transitioning between operating modes. Referring to , internal combustion engine 10, further described herein with particular reference to , is shown coupled to torque converter 11 via crankshaft 13. Torque converter 11 is also coupled to transmission 15 via turbine shaft 17. Torque converter 11 has a bypass, or lock-up clutch 14 which can be engaged, disengaged, or partially engaged. When the clutch is either disengaged or partially engaged, the torque converter is said to be in an unlocked state. The lock-up clutch 14 can be actuated electrically, hydraulically, or electro-hydraulically, for example. The lock-up clutch 14 receives a control signal (not shown) from the controller, described in more detail below. The control signal may be a pulse width modulated signal to engage, partially engage, and disengage, the clutch based on engine, vehicle, and/or transmission operating conditions. Turbine shaft 17 is also known as transmission input shaft. Transmission 15 comprises an electronically controlled transmission with a plurality of selectable discrete gear ratios. Transmission 15, also comprises various other gears, such as, for example, a final drive ratio (not shown). Transmission 15 is also coupled to tire 19 via axle 21. Tire 19 interfaces the vehicle (not shown) to the road 23\u2032. Note that in one example embodiment, this powertrain is coupled in a passenger vehicle that travels on the road. show one cylinder of a multi-cylinder engine, as well as the intake and exhaust path connected to that cylinder. As described later herein with particular reference to , there are various configurations of the cylinders and exhaust system, as well as various configuration for the fuel vapor purging system and exhaust gas oxygen sensor locations. Continuing with , direct injection spark ignited internal combustion engine 10, comprising a plurality of combustion chambers, is controlled by electronic engine controller 12. Combustion chamber 30 of engine 10 is shown including combustion chamber walls 32 with piston 36 positioned therein and connected to crankshaft 40. A starter motor (not shown) is coupled to crankshaft 40 via a flywheel (not shown). In this particular example, piston 36 includes a recess or bowl (not shown) to help in forming stratified charges of air and fuel. Combustion chamber, or cylinder, 30 is shown communicating with intake manifold 44 and exhaust manifold 48 via respective intake valves 52and 52(not shown), and exhaust valves 54and 54(not shown). Fuel injector 66A is shown directly coupled to combustion chamber 30 for delivering injected fuel directly therein in proportion to the pulse width of signal fpw received from controller 12 via conventional electronic driver 68. Fuel is delivered to fuel injector 66A by a conventional high pressure fuel system (not shown) including a fuel tank, fuel pumps, and a fuel rail. Intake manifold 44 is shown communicating with throttle body 58 via throttle plate 62. In this particular example, throttle plate 62 is coupled to electric motor 94 so that the position of throttle plate 62 is controlled by controller 12 via electric motor 94. This configuration is commonly referred to as electronic throttle control (ETC), which is also utilized during idle speed control. In an alternative embodiment (not shown), which is well known to those skilled in the art, a bypass air passageway is arranged in parallel with throttle plate 62 to control inducted airflow during idle speed control via a throttle control valve positioned within the air passageway. Exhaust gas sensor 76 is shown coupled to exhaust manifold 48 upstream of catalytic converter 70 (note that sensor 76 corresponds to various different sensors, depending on the exhaust configuration as described below with regard to . Sensor 76 may be any of many known sensors for providing an indication of exhaust gas air/fuel ratio such as a linear oxygen sensor, a UEGO, a two-state oxygen sensor, an EGO, a HEGO, or an HC or CO sensor. In this particular example, sensor 76 is a two-state oxygen sensor that provides signal EGO to controller 12 which converts signal EGO into two-state signal EGOS. A high voltage state of signal EGOS indicates exhaust gases are rich of stoichiometry and a low voltage state of signal EGOS indicates exhaust gases are lean of stoichiometry. Signal EGOS is used to advantage during feedback air/fuel control in a conventional manner to maintain average air/fuel at stoichiometry during the stoichiometric homogeneous mode of operation. Conventional distributorless ignition system 88 provides ignition spark to combustion chamber 30 via spark plug 92 in response to spark advance signal SA from controller 12. Controller 12 causes combustion chamber 30 to operate in either a homogeneous air/fuel mode or a stratified air/fuel mode by controlling injection timing. In the stratified mode, controller 12 activates fuel injector 66A during the engine compression stroke so that fuel is sprayed directly into the bowl of piston 36. Stratified air/fuel layers are thereby formed. The strata closest to the spark plug contain a stoichiometric mixture or a mixture slightly rich of stoichiometry, and subsequent strata contain progressively leaner mixtures. During the homogeneous mode, controller 12 activates fuel injector 66A during the intake stroke so that a substantially homogeneous air/fuel mixture is formed when ignition power is supplied to spark plug 92 by ignition system 88. Controller 12 controls the amount of fuel delivered by fuel injector 66A so that the homogeneous air/fuel mixture in chamber 30 can be selected to be at stoichiometry, a value rich of stoichiometry, or a value lean of stoichiometry. The stratified air/fuel mixture will always be at a value lean of stoichiometry, the exact air/fuel being a function of the amount of fuel delivered to combustion chamber 30. An additional split mode of operation wherein additional fuel is injected during the exhaust stroke while operating in the stratified mode is also possible. Nitrogen oxide (NOx) adsorbent or trap 72 is shown positioned downstream of catalytic converter 70. NOx trap 72 is a three-way catalyst that adsorbs NOx when engine 10 is operating lean of stoichiometry. The adsorbed NOx is subsequently reacted with HC and CO and catalyzed when controller 12 causes engine 10 to operate in either a rich homogeneous mode or a near stoichiometric homogeneous mode such operation occurs during a NOx purge cycle when it is desired to purge stored NOx from NOx trap 72, or during a vapor purge cycle to recover fuel vapors from fuel tank 160 and fuel vapor storage canister 164 via purge control valve 168, or during operating modes requiring more engine power, or during operation modes regulating temperature of the omission control devices such as catalyst 70 or NOx trap 72. (Again, note that emission control devices 70 and 72 can correspond to various devices described in FIGS. 2A-R). Also note that various types of purging systems can be used, as described in more detail below with regard to FIGS. 2A-R. Controller 12 is shown in as a conventional microcomputer, including microprocessor unit 102, input/output ports 104, an electronic storage medium for executable programs and calibration values shown as read only memory chip 106 in this particular example, random access memory 108, keep alive memory 110, and a conventional data bus. Controller 12 is shown receiving various signals from sensors coupled to engine 10, in addition to those signals previously discussed, including measurement of inducted mass air flow (MAF) from mass air flow sensor 100 coupled to throttle body 58; engine coolant temperature (ECT) from temperature sensor 112 coupled to cooling sleeve 114; a profile ignition pickup signal (PIP) from Hall effect sensor 118 coupled to crankshaft 40; and throttle position TP from throttle position sensor 120; and absolute Manifold Pressure Signal MAP from sensor 122. Engine speed signal RPM is generated by controller 12 from signal PIP in a conventional manner and manifold pressure signal MAP from a manifold pressure sensor provides an indication of vacuum, or pressure, in the intake manifold. During stoichiometric operation, this sensor can give and indication of engine load. Further, this sensor, along with engine speed, can provide an estimate of charge (including air) inducted into the cylinder. In a one example, sensor 118, which is also used as an engine speed sensor, produces a predetermined number of equally spaced pulses every revolution of the crankshaft. In this particular example, temperature Tcat1 of catalytic converter 70 and temperature Tcat2 of emission control device 72 (which can be a NOx trap) are inferred from engine operation as disclosed in U.S. Pat. No. 5,414,994, the specification of which is incorporated herein by reference. In an alternate embodiment, temperature Tcat1 is provided by temperature sensor 124 and temperature Tcat2 is provided by temperature sensor 126. Continuing with , camshaft 130 of engine 10 is shown communicating with rocker arms 132 and 134 for actuating intake valves 52, 52and exhaust valve 54. 54. Camshaft 130 is directly coupled to housing 136. Housing 136 forms a toothed wheel having a plurality of teeth 138. Housing 136 is hydraulically coupled to an inner shaft (not shown), which is in turn directly linked to camshaft 130 via a timing chain (not shown). Therefore, housing 136 and camshaft 130 rotate at a speed substantially equivalent to the inner camshaft. The inner camshaft rotates at a constant speed ratio to crankshaft 40. However, by manipulation of the hydraulic coupling as will be described later herein, the relative position of camshaft 130 to crankshaft 40 can be varied by hydraulic pressures in advance chamber 142 and retard chamber 144. By allowing high pressure hydraulic fluid to enter advance chamber 142, the relative relationship between camshaft 130 and crankshaft 40 is advanced. Thus, intake valves 52, 52and exhaust valves 54, 54open and close at a time earlier than normal relative to crankshaft 40. Similarly, by allowing high pressure hydraulic fluid to enter retard chamber 144, the relative relationship between camshaft 130 and crankshaft 40 is retarded. Thus, intake valves 52, 52, and exhaust valves 54, 54open and close at a time later than normal relative to crankshaft 40. Teeth 138, being coupled to housing 136 and camshaft 130, allow for measurement of relative cam position via cam timing sensor 150 providing signal VCT to controller 12. Teeth 1, 2, 3, and 4 are preferably used for measurement of cam timing and are equally spaced (for example, in a V-8 dual bank engine, spaced 90 degrees apart from one another) while tooth 5 is preferably used for cylinder identification, as described later herein. In addition, controller 12 sends control signals (LACT, RACT) to conventional solenoid valves (not shown) to control the flow of hydraulic fluid either into advance chamber 142, retard chamber 144, or neither. Relative cam timing is measured using the method described in U.S. Pat. No. 5,548,995, which is incorporated herein by reference. In general terms, the time, or rotation angle between the rising edge of the PIP signal and receiving a signal from one of the plurality of teeth 138 on housing 136 gives a measure of the relative cam timing. For the particular example of a V-8 engine, with two cylinder banks and a five-toothed wheel, a measure of cam timing for a particular bank is received four times per revolution, with the extra signal used for cylinder identification. Sensor 160 provides an indication of both oxygen concentration in the exhaust gas as well as NOx concentration. Signal 162 provides controller a voltage indicative of the O2 concentration while signal 164 provides a voltage indicative of NOx concentration. Alternatively, sensor 160 can be a HEGO, UEGO, EGO, or other type of exhaust gas sensor. Also note that, as described above with regard to sensor 76, sensor 160 can correspond to various different sensors depending on the system configuration, as described in more detail below with regard to . As described above, (and 1B) merely show one cylinder of a multi-cylinder engine, and that each cylinder has its own set of intake/exhaust valves, fuel injectors, spark plugs, etc. Referring now to , a port fuel injection configuration is shown where fuel injector 66B is coupled to intake manifold 44, rather than directly cylinder 30. Also, in the example embodiments described herein, the engine is coupled to a starter motor (not shown) for starting the engine. The starter motor is powered when the driver turns a key in the ignition switch on the steering column, for example. The starter is disengaged after engine start as evidence, for example, by engine 10 reaching a predetermined speed after a predetermined time. Further, in the disclosed embodiments, an exhaust gas recirculation (EGR) system routes a desired portion of exhaust gas from exhaust manifold 48 to intake manifold 44 via an EGR valve (not shown). Alternatively, a portion of combustion gases may be retained in the combustion chambers by controlling exhaust valve timing. The engine 10 operates in various modes, including lean operation, rich operation, and \u201cnear stoichiometric\u201d operation. \u201cNear stoichiometric\u201d operation refers to oscillatory operation around the stoichiometric air fuel ratio. Typically, this oscillatory operation is governed by feedback from exhaust gas oxygen sensors. In this near stoichiometric operating mode, the engine is operated within approximately one air-fuel ratio of the stoichiometric air-fuel ratio. This oscillatory operation is typically on the order of 1 Hz, but can vary faster and slower than 1 Hz. Further, the amplitude of the oscillations are typically within 1 a/f ratio of stoichiometry, but can be greater than 1 a/f ratio under various operating conditions. Note that this oscillation does not have to be symmetrical in amplitude or time. Further note that an air-fuel bias can be included, where the bias is adjusted slightly lean, or rich, of stoichiometry (e.g., within 1 a/f ratio of stoichiometry). Also note that this bias and the lean and rich oscillations can be governed by an estimate of the amount of oxygen stored in upstream and/or downstream three way catalysts. As described below, feedback air-fuel ratio control is used for providing the near stoichiometric operation. Further, feedback from exhaust gas oxygen sensors can be used for controlling air-fuel ratio during lean and during rich operation. In particular, a switching type, heated exhaust gas oxygen sensor (HEGO) can be used for stoichiometric air-fuel ratio control by controlling fuel injected (or additional air via throttle or VCT) based on feedback from the HEGO sensor and the desired air-fuel ratio. Further, a UEGO sensor (which provides a substantially linear output versus exhaust air-fuel ratio) can be used for controlling air-fuel ratio during lean, rich, and stoichiometric operation. In this case, fuel injection (or additional air via throttle or VCT) is adjusted based on a desired air-fuel ratio and the air-fuel ratio from the sensor. Further still, individual cylinder air-fuel ratio control could be used, if desired. Also note that various methods can be used to maintain the desired torque such as, for example, adjusting ignition timing, throttle position, variable cam timing position, exhaust gas recirculation amount, and a number of cylinders carrying out combustion. Further, these variables can be individually adjusted for each cylinder to maintain cylinder balance among all the cylinder groups. Referring now to , a first example configuration is described using a V-8 engine, although this is simply one example, since a V-10, V-12, I4, I6, etc., could also be used. Note that while numerous exhaust gas oxygen sensors are shown, a subset of these sensors can also be used. Further, only a subset of the emission control devices can be used, and a non-y-pipe configuration can also be used. As shown in , some cylinders of first combustion chamber group 210 are coupled to the first catalytic converter 220, while the remainder are coupled to catalyst 222. Upstream of catalyst 220 and downstream of the first cylinder group 210 is an exhaust gas oxygen sensor 230. Downstream of catalyst 220 is a second exhaust gas sensor 232. In this example, groups 210 and 212 each have four cylinders. However, either group 210 or group 212 could be divided into other groups, such as per cylinder bank. This would provide four cylinder groups (two on each bank, each with two cylinders in the group). In this way, two different cylinder groups can be coupled to the same exhaust gas path on one side of the engine's bank. Similarly, some cylinders of second combustion chamber group 212 are coupled to a second catalyst 222, while the remainder are coupled to catalyst 220. Upstream and downstream are exhaust gas oxygen sensors 234 and 236 respectively. Exhaust gas spilled from the first and second catalyst 220 and 222 merge in a Y-pipe configuration before entering downstream under body catalyst 224. Also, exhaust gas oxygen sensors 238 and 240 are positioned upstream and downstream of catalyst 224, respectively. In one example embodiment, catalysts 220 and 222 are platinum and rhodium catalysts that retain oxidants when operating lean and release and reduce the retained oxidants when operating rich. Further, these catalysts can have multiple bricks, and further these catalysts can represent several separate emission control devices. Similarly, downstream underbody catalyst 224 also operates to retain oxidants when operating lean and release and reduce retained oxidants when operating rich. As described above, downstream catalyst 224 can be a group of bricks, or several emission control devices. Downstream catalyst 224 is typically a catalyst including a precious metal and alkaline earth and alkaline metal and base metal oxide. In this particular example, downstream catalyst 224 contains platinum and barium. Note that various other emission control devices could be used, such as catalysts containing palladium or perovskites. Also, exhaust gas oxygen sensors 230 to 240 can be sensors of various types. For example, they can be linear oxygen sensors for providing an indication of air-fuel ratio across a broad range. Also, they can be switching type exhaust gas oxygen sensors that provide a switch in sensor output at the stoichiometric point. Also, the system can provide less than all of sensors 230 to 240, for example, only sensors 230, 234, and 240. In another example, only sensor 230, 234 are used with only devices 220 and 222. Also, while shows a V-8 engine, various other numbers of cylinders could be used. For example, an I4 engine can be used, where there are two groups of two cylinders leading to a common exhaust path with and upstream and downstream emission control device. When the system of is operated in an AIR/LEAN mode, first combustion group 210 is operated at a lean air-fuel ratio (typically leaner than about 18:1) and second combustion group 212 is operated without fuel injection. Thus, in this case, and during this operation, the exhaust air-fuel ratio is a mixture of air from the cylinders without injected fuel, and a lean air fuel ratio from the cylinders combusting a lean air-fuel mixture. In this way, fuel vapors from valve 168 can be burned in group 210 cylinders even during the AIR/LEAN mode. Note that the engine can also operate in any of the 5 various modes described below with regard to 1, for example. Note that, as described in more detail below, the mode selected may be based on desired engine output torque, whether idle speed control is active, exhaust temperature, and various other operating conditions. Referring now to , a system similar to that in is shown, however a dual fuel vapor purge system is shown with first and second purge valves 168A and 168B. Thus, independent control of fuel vapors between each of groups 210 and 212 is provided. When the system of is operated in an AIR/LEAN mode, first combustion group 210 is operated at a lean air-fuel ratio (typically leaner than about 18:1), second combustion group 212 is operated without fuel injection, and fuel vapor purging can be enabled to group 210 via valve 168A (and disabled to group 212 via valve 168B). Alternatively, first combustion group 210 is operated without fuel injection, second combustion group 212 is operated at a lean air-fuel ratio, and fuel vapor purging can be enabled to group 212 via valve 168B (and disabled to group 210 via valve 168A). In this way, the system can perform the AIR/LEAN mode in different cylinder groups depending on operating conditions, or switch between the cylinder groups to provide even wear, etc. Referring now to , a V-6 engine is shown with first group 250 on one bank, and second group 252 on a second bank. The remainder of the exhaust system is similar to that described above in . The fuel vapor purge system has a single control valve 168 fed to cylinders in group 250. When the system of is operated in an AIR/LEAN mode, first combustion group 250 is operated at a lean air-fuel ratio (typically leaner than about 18:1) and second combustion group 252 is operated without fuel injection. Thus, in this case, and during this operation, the exhaust air-fuel ratio is a mixture of air from the cylinders without injected fuel, and a lean air fuel ratio from the cylinders combusting a lean air-fuel mixture. In this way, fuel vapors from valve 168 can be burned in group 250 cylinders even during the AIR/LEAN mode. Note that the engine can also operate in any of the 5 various modes described below with regard to 1, for example. Referring now to , a system similar to that in is shown, however a dual fuel vapor purge system is shown with first and second purge valves 168A and 168B. Thus, independent control of fuel vapors between each of groups 250 and 252 is provided. When the system of is operated in an AIR/LEAN mode, first combustion group 250 is operated at a lean air-fuel ratio (typically leaner than about 18:1), second combustion group 252 is operated without fuel injection, and fuel vapor purging can be enabled to group 250 via valve 168A (and disabled to group 212 via valve 168B). Alternatively, first combustion group 250 is operated without fuel injection, second combustion group 252 is operated at a lean air-fuel ratio, and fuel vapor purging can be enabled to group 252 via valve 168B (and disabled to group 250 via valve 168A). In this way, the system can perform the AIR/LEAN mode in different cylinder groups depending on operating conditions, or switch between the cylinder groups to provide even wear, etc. Note that the engine can also operate in any of the 5 various modes described below with regard to 1, for example. Referring now to , a V-6 engine is shown similar to that of , with the addition of an exhaust gas recirculation (EGR) system and valve 178. As illustrated in , the EGR system takes exhaust gasses exhausted from cylinders in cylinder group 250 to be fed to the intake manifold (downstream of the throttle). The EGR gasses then pass to both cylinder groups 250 and 252 via the intake manifold. The remainder of the exhaust system is similar to that described above in . Note that, as above, the engine can also operate in any of the 5 various modes described below with regard to 1, for example. Referring now to , a system similar to that in is shown, however a dual fuel vapor purge system is shown with first and second purge valves 168A and 168B. Further, EGR gasses are taken from group 252, rather than 250. Again, the engine can also operate in any of the 5 various modes described below with regard to 1, for example. Referring now to , a system similar to that in is shown, however an exhaust gas recirculation system and valve 178 is shown for introducing exhaust gasses that are from some cylinders in group 210 and some cylinders in group 212 into the intake manifold downstream of the throttle valve. Again, the engine can also operate in any of the 5 various modes described below with regard to 1, for example. Referring now to , a system similar to that in is shown, however a dual fuel vapor purge system is shown with first and second purge valves 168A and 168B. Again, the engine can also operate in any of the 5 various modes described below with regard to 1, for example. Referring now to , a V-6 engine is shown with first cylinder group 250 on a first bank, and second cylinder group 252 on a second bank. Further, a first exhaust path is shown coupled to group 250 including an upstream emission control device 220 and a downstream emission control device 226. Further, an exhaust manifold sensor 230, an intermediate sensor 232 between devices 220 and 226, and a downstream sensor 239 are shown for measuring various exhaust gas air-fuel ratio values. In one example, devices 220 and 226 are three way catalysts having one or more bricks enclosed therein. Similarly, a second exhaust path is shown coupled to group 252 including an upstream emission control device 222 and a downstream emission control device 228. Further, an exhaust manifold sensor 234, an intermediate sensor 236 between devices 222 and 228, and a downstream sensor 241 are shown for measuring various exhaust gas air-fuel ratio values. In one example, devices 222 and 228 are three way catalysts having one or more bricks enclosed therein. Continuing with , both groups 250 and 252 have a variable valve actuator (270 and 272, respectively) coupled thereto to adjust operation of the cylinder intake and/or exhaust valves. In one example, these are variable cam timing actuators as described above in . However, alternative actuators can be used, such as variable valve lift, or switching cam systems. Further, individual actuators can be coupled to each cylinder, such as with electronic valve actuator systems. Note that , as well as the rest of the figures in are schematic representations. For example, the purge vapors from valve 168 can be delivered via intake ports with inducted air as in , rather than via individual paths to each cylinder in the group as in . And as before, the engine can also operate in various engine modes, such as in 1, or as in the various routines described below herein. Referring now to , a system similar to that of is shown with an alternative fuel vapor purge delivery to the intake manifold, which delivery fuel vapors from valve 168. Note that such a system can be adapted for various systems described in above and below, as mentioned with regard to , although one approach may provide advantages over the other depending on the operating modes of interest. Referring now to , a V-8 engine is shown with a first group of cylinders 210 spanning both cylinder banks, and a second group of cylinders 212 spanning both cylinder banks. Further, an exhaust system configuration is shown which brings exhaust gasses from the group 212 together before entering an emission control device 260. Likewise, the gasses exhausted from device 260 are mixed with untreated exhaust gasses from group 210 before entering emission control device 262. This is accomplished, in this example, via a cross-over type exhaust manifold. Specifically, exhaust manifold 256 is shown coupled to the inner two cylinders of the top bank of group 212; exhaust manifold 257 is shown coupled to the outer two cylinders of the top bank of group 210; exhaust manifold 258 is shown coupled to the inner two cylinders of the bottom bank of group 210; and exhaust manifold 259 is shown coupled to the outer two cylinders of the bottom bank of group 212. Then, manifolds 257 and 258 are fed together and then fed to mix with gasses exhausted from device 250 (before entering device 262), and manifolds 256 and 259 are fed together and fed to device 260. Exhaust gas air-fuel sensor 271 is located upstream of device 260 (after manifolds 256 and 259 join). Exhaust gas air-fuel sensor 273 is located upstream of device 262 before the gasses from the group 210 join 212. Exhaust gas air-fuel sensor 274 is located upstream of device 262 after the gasses from the group 210 join 212. Exhaust gas air-fuel sensor 276 is located downstream of device 276. In one particular example, devices 260 and 262 are three way catalysts, and when the engine operates in a partial fuel cut operation, group 212 carries out combustion oscillating around stoichiometry (treated in device 260), while group 210 pumps are without injected fuel. In this case, device 262 is saturated with oxygen. Alternatively, when both cylinder groups are combusting, both devices 260 and 262 can operate to treat exhausted emissions with combustion about stoichiometry. In this way, partial cylinder cut operation can be performed in an odd fire V-8 engine with reduced noise and vibration. Note that there can also be additional emission control devices (not shown), coupled exclusively to group 210 upstream of device 262. Referring now to , another V-8 engine is shown with a first group of cylinders 210 spanning both cylinder banks, and a second group of cylinders 212 spanning both cylinder banks. However, in this example, a first emission control device 280 is coupled to two cylinders in the top bank (from group 212) and a second emission control device 282 is coupled to two cylinders of the bottom bank (from group 212). Downstream of device 280, manifold 257 joins exhaust gasses from the remaining two cylinders in the top bank (from group 210). Likewise, downstream of device 282, manifold 258 joins exhaust gasses from the remaining two cylinders in the bottom bank (from group 210). Then, these two gas streams are combined before entering downstream device 284. In one particular example, devices 280, 282, and 284 are three way catalysts, and when the engine operates in a partial fuel cut operation, group 212 carries out combustion oscillating around stoichiometry (treated in devices 280 and 282), while group 210 pumps are without injected fuel. In this case, device 284 is saturated with oxygen. Alternatively, when both cylinder groups are combusting, devices 280, 282, and 284 can operate to treat exhausted emissions with combustion about stoichiometry. In this way, partial cylinder cut operation can be performed in an odd fire V-8 engine with reduced noise and vibration. Note that both shows a fuel vapor purge system and valve 168 for delivering fuel vapors to group 210. Referring now to , two banks of a V8 engine are shown. The odd fire V8 engine is operated by, in each bank, running two cylinders about stoichiometry and two cylinders with air. The stoichiometric and air exhausts are then directed through a bifurcated exhaust pipe to a bifurcated metal substrate catalyst, described in more detail below with regard to . The stoichiometric side of the catalyst reduces the emissions without the interference from the air side of the exhaust. The heat from the stoichiometric side of the exhaust keeps the whole catalyst above a light-off temperature during operating conditions. When the engine is then operated in 8-cylinder mode, the air side of the catalyst is in light-off condition and can reduce the emissions. A rich regeneration of the air side catalyst can also be performed when changing from 4 to 8 cylinder mode whereby the 2 cylinders that were running air would be momentarily operated rich to reduce the oxygen storage material in the catalyst prior to returning to stoichiometric operation, as discussed in more detail below. This regeneration can achieve 2 purposes: 1) the catalyst will function in 3-way operation when the cylinders are brought back to stoichiometric operation and 2) the regeneration of the oxygen storage material will result in the combustion of the excess CO/H2 in the rich exhaust and will raise the temperature of the catalyst if it has cooled during period when only air was pumped through the deactivated cylinders. Continuing with , exhaust manifold 302 is shown coupled to the inner two cylinders of the top bank (from group 212). Exhaust manifold 304 is shown coupled to the outer two cylinders of the top bank (from group 210). Exhaust manifold 308 is shown coupled to the inner two cylinders of the bottom bank (from group 210). Exhaust manifold 306 is shown coupled to the outer two cylinders of the bottom bank (from group 212). Exhaust manifolds 302 and 304 are shown leading to an inlet pipe (305) of device 300. Likewise, exhaust manifolds 306 and 308 are shown leading to an inlet pipe (307) of device 302, which, as indicated above, are described in more detail below. The exhaust gasses from devices 300 and 302 are mixed individually and then combined before entering device 295. Further, a fuel vapor purge system and control valve 168 are shown delivering fuel vapors to group 212. Again, as discussed above, an I-4 engine could also be used, where the engine has a similar exhaust and inlet configuration to one bank of the V-8 engine configurations shown above and below in the various Figures. , and 2P are similar to , and 2M, respectively, except for the addition of a first and second variable valve actuation units, in this particular example, variable cam timing actuators 270 and 272. Referring now to , an example V-6 engine is shown with emission control devices 222 and 224. In this example, there is no emission control device coupled exclusively to group 250. A third emission control device (not shown) can be added downstream. Also, shows an example V-6 engine, however, others can be used in this configuration, such as a V-10, V-12, etc. Referring now to , an example system is shown where fuel vapors are passed to all of the cylinders, and in the case of cylinder fuel cut operation, fuel vapor purging operating is suspended. Referring now to , still another example system is shown for an engine with variable valve operation (such as variable cam timing from devices 270 and 272), along with a fuel vapor purging system having a single valve 168 in 2S, and dual purge valves 168A, B in 2T. There are various fuel vapor modes for , some of which are listed below: \n\n Each of these modes can include further variation, such as different VCT timing between cylinder banks, etc. Also note that operation at a cylinder cut condition provides a practically infinite air-fuel ratio, since substantially no fuel is being injected by the fuel injectors for that cylinder (although there may be some fuel present due to fuel around the intake valves and in the intake port that will eventually decay away). As such, the effective air-fuel ratio is substantially greater than about 100:1, for example. Although, depending on the engine configuration, it could vary between 60:1 to practically an infinite value. Regarding the various systems shown in FIGS. 2A-R, different system configurations can present their own challenges that are addressed herein. For example, V-8 engines, such as in , for example, can have uneven firing order, so that if it is desired to disable a group of 4 cylinders, then two cylinders on each bank are disabled to provide acceptable vibration. However, this presents challenges since, as shown in , some exhaust system configurations treat emissions from the entire bank together. Further, as shown in , a single valve actuator can be used to adjust all of the valves of cylinders in a bank, even though some cylinders in the bank are disabled, while others are operating. Unlike such V-8 engines, some V-6 engines can be operated with a cylinder bank disabled, thus allowing an entire cylinder bank to be a group of cylinders that are operated without fuel injection. Each of these different types of systems therefore has its own potential issues and challenges, as well as advantages, as discussed and addressed by the routines described in more detail below. Note a bifurcated induction system (along firing order groups) can also be used for the fresh air. Such a system would be similar to the system of , except that the valves 168A and 168B would be replaced by electronically controlled throttles. In this way, fuel vapor purge could be fed to these two bifurcated induction systems, along with airflow, so that separate control of fuel vapor purge and airflow could be achieved between groups 210 and 212. However, as discussed above with regard to , for example, the VCT actuators can be used to obtain differing airflows (or air charges) between the cylinders of groups 250 and 252, without requiring a split induction system. Several control strategies may be used to take advantage of the ability to provide differing air amounts to differing cylinder groups, as discussed in more detail below. As one example, separate control of airflow to different cylinder groups (e.g., via VCT actuators 270 and 272 in ), can be used in split ignition operation to allow more (or less) air flow into a group of cylinders. Also, under some conditions there may be no one air amount that satisfies requirements of combustion stability, heat generation, and net power/torque. For example, the power producing cylinder group may have a minimum spark advance for stability, or the heat producing cylinder group may have a maximum heat flux due to material constraints. Bank-VCT and/or bifurcated intake could be used to achieve these requirements with different air amounts selected for different cylinder groups. Another control strategy example utilizing a bifurcating inlet (or using VCT in a V6 or V10) would allow lower pumping losses in cylinder cut-out mode by changing the air flow to that group, where VCT is not solely associated with a firing group. Further details of control routines are included below which can be used with various engine configurations, such as the those described in . As will be appreciated by one of ordinary skill in the art, the specific routines described below in the flowcharts may represent one or more of any number of processing strategies such as event-driven, interrupt-driven, multi-tasking, multi-threading, and the like. As such, various steps or functions illustrated may be performed in the sequence illustrated, in parallel, or in some cases omitted. Likewise, the order of processing is not necessarily required to achieve the features and advantages of the example embodiments of the invention described herein, but is provided for ease of illustration and description. Although not explicitly illustrated, one of ordinary skill in the art will recognize that one or more of the illustrated steps or functions may be repeatedly performed depending on the particular strategy being used. Further, these figures graphically represent code to be programmed into the computer readable storage medium in controller 12. Referring now to 1, a graph is shown illustrating engine output versus engine speed. In this particular description, engine output is indicated by engine torque, but various other parameters could be used, such as, for example: wheel torque, engine power, engine load, or others. The graph shows the maximum available torque that can be produced in each of five operating modes. Note that a percentage of available torque, or other suitable parameters, could be used in place of maximum available torque. Further note that the horizontal line does not necessarily correspond to zero engine brake torque. The five operating modes in this embodiment include: \n\n Described above is one exemplary embodiment where an 8-cylinder engine is used and the cylinder groups are broken into two equal groups. However, various other configurations can be used, as discussed above and below. In particular, engines of various cylinder numbers can be used, and the cylinder groups can be broken down into unequal groups as well as further broken down to allow for additional operating modes. For the example presented in 1 in which a V-8 engine is used, lines 3A1-16 shows operation with 4 cylinders operating with air and substantially no fuel, line 3A1-14 shows operation with four cylinders operating at stoichiometry and four cylinders operating with air, line 3A1-12 shows 8 cylinders operating lean, line 3A1-10 shows 8 cylinders operating at stoichiometry, and line 3A1-18 shows all cylinders operating without injected fuel. The above described graph illustrates the range of available torques in each of the described modes. In particular, for any of the described modes, the available engine output torque can be any torque less than the maximum amount illustrated by the graph. Also note that in any mode where the overall mixture air-fuel ratio is lean of stoichiometry, the engine can periodically switch to operating all of the cylinders stoichiometric or rich. This is done to reduce the stored oxidants (e.g., NOx) in the emission control device(s). For example, this transition can be triggered based on the amount of stored NOx in the emission control device(s), or the amount of NOx exiting the emission control device(s), or the amount of NOx in the tailpipe per distance traveled (mile) of the vehicle. To illustrate operation among these various modes, several examples of operation are described. The following are simply exemplary descriptions of many that can be made, and are not the only modes of operation. As a first example, consider operation of the engine along trajectory A. In this case, the engine initially is operating with all cylinders in the fuel-cut mode. Then, in response to operating conditions, it is desired to change engine operation along trajectory A. In this case, it is desired to change engine operation to operating with four cylinders operating lean of stoichiometry, and four cylinders pumping air with substantially no injected fuel. In this case, additional fuel is added to the combusting cylinders to commence combustion, and correspondingly increase engine torque. Likewise, it is possible to follow the reverse trajectory in response to a decrease in engine output. As a second example, consider the trajectory labeled B. In this example, the engine is operating with all cylinders combusting at substantially stoichiometry. In response to a decrease in desired engine torque, 8 cylinders are operated in a fuel cut condition to provide a negative engine output torque. As a third example, consider the trajectory labeled C. In this example, the engine is operating with all cylinders combusting at a lean air-fuel mixture. In response to a decrease in desired engine torque, 8 cylinders are operated in a fuel cut condition to provide a negative engine output torque. Following this, it is desired to change engine operation to operating with four cylinders operating lean of stoichiometry, and four cylinders pumping air with substantially no injected fuel. Finally, the engine is again transitioned to operating with all cylinders combusting at a lean air-fuel mixture. As a fourth example, consider the trajectory labeled D. In this example, the engine is operating with all cylinders combusting at a lean air-fuel mixture. In response to a decrease in desired engine torque, 8 cylinders are operated in a fuel cut condition to provide a negative engine output torque. Likewise, it is possible to follow the reverse trajectory in response to an increase in engine output Continuing with 1, and lines 3A1-10 to 3A1-18 in particular, an illustration of the engine output, or torque, operation for each of the exemplary modes is described. For example, at engine speed N1, line 3A1-10 shows the available engine output or torque output that is available when operating in the 8-cylinder stoichiometric mode. As another example, line 3A1-12 indicates the available engine output or torque output available when operating in the 8-cylinder lean mode at engine speed N2. When operating in the 4-cylinder stoichiometric and 4-cylinder air mode, line 3A1-14 shows the available engine output or torque output available when operating at engine speed N3. When operating in the 4-cylinder lean, 4-cylinder air mode, line 3A1-16 indicates the available engine or torque output when operating at engine speed N4. Finally, when operating in the 8-cylinder air mode, line 3A1-18 indicates the available engine or torque output when operating at engine speed N5. Referring now to 2, another graph is shown illustrating engine output versus engine speed. The alternative graph shows the maximum available torque that can be produced in each of 3 operating modes. As with regard to 1, note that the horizontal line does not necessarily correspond to zero engine brake torque. The three operating modes in this embodiment include: \n\n Referring now to , a routine for controlling the fuel vehicle purge is described. In general terms, the routine adjusts valve 168 to control the fuel vapor purging supplied to the cylinder group 210 to be combusted therein. As illustrated in , the fuel vapor can be purged to cylinders in group 210 while these cylinders are carrying out stoichiometric, rich, or lean combustion. Furthermore, the cylinders in group 212 can be carrying out combustion at stoichiometric, rich, or lean, or operating with air and substantially no injector fuel. In this way, it is possible to purge fuel vapor while operating in the air-lean mode. Further, it is possible to purge fuel vapors while operating in a stoichiometric-air mode. Referring now specifically to , in step 310, the routine determines whether fuel vapor purging is requested. This determination can be based on various parameters, such as whether the engine is in a warmed up state, whether the sensors and actuators are operating without degradation, and/or whether the cylinders in group 210 are operating under feedback air-fuel ratio control. When the answer to step 310 is yes, the routine continues to step 312 to activate valve 168. Then, in step 314, the routine estimates the fuel vapor purge amount in the fuel vapors passing through valve 168. Note that there are various ways to estimate fuel vapor purging based on the valve position, engine operating conditions, exhaust gas air-fuel ratio, fuel injection amount and various other parameters. One example approach is described below herein with regard to . Next, in step 316, the routine adjusts the opening of valve 168 based on the estimated purge amount to provide a desired purge amount. Again, there are various approaches that can be used to produce this control action such as, for example: feedback control, feed-forward control, or combinations thereof. Also, the desired purge amount can be based on various parameters, such as engine speed and load, and the state of the charcoal canister in the fuel vapor purging system. Further, the desired purge amount can be based on the amount of purge time completed. From step 316, the routine continues to step 318 to determine whether the estimated purge amount is less than a minimum purge value (min_prg). Another indication of whether fuel vapor purging is substantially completed is whether the purge valve 168 has been fully opened for a predetermined amount of operating duration. When the answer to step 318 is no, the routine continues to end. Alternatively, when the answer to step 318 is yes, the routine continues to step 320 to disable fuel vapor purging and close valve 168. Also, when the answer to step 310 is no, the routine also continues to step 322 to disable the fuel vapor purging. In this way, it is possible to control the fuel vapor purging to a subset of the engine cylinders thereby allowing different operating modes between the cylinder groups. Referring now to , an example routine for controlling the system as shown in is described. In general, the routine controls the fuel vapor purge valves 168and 168to selectively control fuel vapor purge in cylinder groups 210, or 212, or both. In this way, different sets of cylinders can be allowed to operate in different operating modes with fuel vapor purging, thereby providing for more equalized cylinder operation between the groups. Referring now specifically to , in step 322, the routine determines whether fuel vapor purging is requested as described above with regard to step 310 of . When the answer to step 322 is yes, the routine continues to step 324 to select the cylinder group, or groups, for purging along with selecting the purge valve or valves to actuate. The selection of cylinder groups to provide fuel vapor purging is a function of several engine and/or vehicle operating conditions. For example, based on the quantity of fuel vapor purge that needs to be processed through the cylinders, the routine can select either one cylinder group or both cylinder groups. In other words, when greater fuel vapor purging is required, both cylinder groups can be selected. Alternatively, when lower amounts of fuel vapor purging are required, the routine can select one of groups 210 and 212. When it is decided to select only one of the two cylinder groups due to, for example, low fuel vapor purging requirements, the routine selects from the two groups based on various conditions. For example, the decision of which group to select can be based on providing equal fuel vapor purging operation for the two groups. Alternatively, the cylinders operating at the more lean air-fuel ratio can be selected to perform the fuel vapor purging to provide improved combustion stability for the lean operation. Still other selection criteria could be utilized to select the number and which groups to provide fuel vapor purging. Another example is that the when only a single cylinder group is selected, the routine alternates between which group is selected to provide more even wear between the groups. For example, the selection could attempt to provide a consistent number of engine cycles between the groups. Alternatively, the selection could attempt to provide a consistent amount of operating time between the groups. When the first group is selected, the routine continues to step 326 to actuate valve 168. Alternatively, when the second group is selected, the routine continues to step to actuate valve 168in step 328. Finally, when both the first and second groups are selected, the routine continues to step 330 to actuate both valves 168and 168 From either of steps 326, 328, or 330, the routine continues to step 332 to estimate the fuel vapor purging amount. As described above, there are various approaches to estimate fuel vapor purge amount, such as described below herein with regard to . Next, in step 334, the routine continues to adjust the selected purge valve (or valves) based on the estimated purge amount to provide the desired purge amount. As described above, there are various approaches to providing feedback and/or feedforward control to provide the desired purge amount. Further, the desired purge amount can be selected based on various operating conditions, such as, for example: engine speed and engine load. Continuing with , in step 336, the routine determines whether the estimated purge amount is less than the minimum purge amount (min_prg). As discussed above herein with regard to step 318 of . As discussed above, when the answer to step 336 is yes, the routine ends. Alternatively, when the answer to step 336 is no, the routine also continues to step 338 to disable fuel vapor purging. When the answer to step 336 is no, the routine continues to the end. In this way, it is possible to provide both cylinder groups with the ability to operate in the air/lean, or air/stoichiometric mode and combust fuel vapors, or the other group operates with air and substantially no injected fuel. Note also that the routines of could be modified to operate with the configurations of . Referring now to , a routine for estimating fuel vapor purge amounts is described. Note that this example shows calculations for use on a V8 type engine with four cylinders per bank and with two cylinders purging and two cylinders without purge on a bank as illustrated in , for example. However, the general approach can be expanded to other system configurations as is illustrated in detail below. The following equations describe this example configuration. The measured air-fuel ratio in the exhaust manifold (\u03bb) can be represented as: \n\n\u03bb=(0.50.5)/(0.5) \n\n where: \n\n When operating in with two cylinders inducting air with substantially no injected fuel, and fuel vapors delivered only to two cylinders carrying out combustion in that bank, this reduces to: \n\n\u03bb=(0.50.5)/(0.5) \n Then, using an estimate of dm/dt based on manifold pressure and purge valve position, the commanded values for dm/dt and dm/dt, the measured air-fuel ratio from the sensor for \u03bb, and the measure airflow from the mass air flow sensor for dm/dt, an estimate of dm/dt can be obtained. As such, the concentration of fuel vapors in the purge flow can then be found as the ratio of dm/dt to dm/dt. Also, as discussed in more detail below, the fuel injection is adjusted to vary dm/dt and dm/dt to provide a desired air-fuel ratio of the exhaust gas mixture as measured by \u03bb. Finally, in the case where cylinders 1 and 4 are combusting injected fuel, the commanded injection amounts can be used to determine the amount of fuel injected so that the first equation can be used to estimate fuel vapors. In this way, it is possible to estimate the fuel vapor purge content from a sensor seeing combustion from cylinders with and without fuel vapor purging. Referring now specifically to , first in step 410, the routine calculates a fresh air amount to the cylinders coupled to the measurement sensor from the mass air flow sensor and fuel vapor purging valve opening degree. Next, in step 412\u2032, the routine calculates the fuel flow from the fuel injectors. Then, in step 414, the routine calculates concentration of fuel vapors from the air and fuel flows. Note that if there are two fuel vapor purge valves, each providing vapors to separate cylinder banks and sensor sets, then the above calculations can be repeated and the two averaged to provide an average amount of vapor concentration from the fuel vapor purging system. Referring now to , a routine is described for controlling a mixture air-fuel ratio in an engine exhaust during fuel vapor purging. Specifically, the example routine of can be used when a sensor measures exhaust gases that are mixed from cylinders with and without fuel vapor purging. First, in step 510, the routine determines a desired air-fuel ratio (\u03bb) for the cylinders. Then, in step 512, the routine calculates an open loop fuel injection amount based on the estimated purge flow and estimated purge concentration to provide an air-fuel mixture in the cylinders with fuel vapor purging at the desired value. Then, in step 514, the routine adjusts fuel injection to the cylinders receiving fuel vapor purging to provide the desired mixture air-fuel ratio that is measured by the exhaust air-fuel ratio sensor. In this way, the adjustment of the fuel injection based on the sensor feedback can not only be used to maintain the mixture air-fuel ratio at a desired value, but also as an estimate of fuel vapor purging in the cylinders receiving fuel vapors. Further, the cylinders without fuel vapors can be operated either with air and substantially no injected fuel, or at a desired air-fuel ratio independent of the fuel vapors provided to the other cylinders. As described above herein, there are various operating modes that the cylinders of engine 10 can experience. In one example, the engine can be operated with some cylinders combusting stoichiometric or lean gases, with others operating to pump air and substantially no injected fuel. Another operating mode is for all cylinders to be combusting stoichiometric or lean gases. As such, the engine can transition between these operating modes based on the current and other engine operating conditions. As described below, under some conditions when transitioning from less than all the cylinders combusting to all the cylinders combusting, various procedures can be used to provide a smooth transition with improved engine operation and using as little fuel as possible. As illustrated in the graphs of FIGS. 6A-D, one specific approach to transition from four cylinder operation to eight cylinder operation is illustrated. Note that the particular example of four cylinder to eight cylinder operation could be adjusted based on the number of cylinders in the engine such as, for example: from three cylinders to six cylinders, from five cylinders to ten cylinders, etc. Specifically, shows total engine air flow, shows the fuel charge per cylinder, shows ignition (spark) angle, and shows the air-fuel ratio of combusting cylinders. As shown in FIGS. 6A-D, before time T1, four cylinders are initially combusting a lean air-fuel ratio and providing a desired engine output torque. Then, as engine airflow is decreased, the air-fuel ratio approaches the stoichiometric value and the engine is operating with four cylinders combusting a stoichiometric air-fuel ratio and pumping air with substantially no injected fuel. Then, at time T1, the engine transitions to eight cylinders combusting. At this time, the desire is to operate all engine cylinders as lean as possible to minimize the torque increase by doubling the number of combusting cylinders. However, since the engine typically has a lean combustion air-fuel ratio limit (as indicated by the dashed dot line in ), it is not possible to compensate all the increased torque by combusting a lean air-fuel ratio in all the cylinders. As such, not only is the fuel charge per cylinder decreased, but the ignition angle is also decreased until the airflow can be reduced to the point at which all the cylinders can be operated at the lean limit. In other words, from time T1 to T2, engine torque is maintained by decreasing engine airflow and retarding ignition timing until the engine can be operated with all the cylinders at the air-fuel ratio limit to provide the same engine output as was provided before the transition from four cylinders to eight cylinders. In this way, it is possible to provide a smooth transition, while improving fuel economy by using lean combustion in the enabled cylinders, as well as the previously stoichiometric combusting cylinders and thus reducing the amount of ignition timing retard after the transition that is required. This improved operation can be compared to the case where the transition is from four cylinders to eight cylinders, with the eight cylinders combusting at stoichiometry. In this case, which is illustrated by the dashed lines in , a greater amount of ignition timing retard for a longer duration, is required to maintain engine torque substantially constant during the transition. As such, since this requires more ignition timing retard, over a longer duration, more fuel is wasted to produce engine output than with the approach of the solid lines in , one example of which is described in the routine of . Referring now to , a routine is described for controlling a transition from less than all the cylinders combusting to all the cylinders combusting, such as the example from four cylinders to eight cylinders illustrated in FIGS. 6A-D. First, in step 710, the routine determines whether a transition has been requested to enable the cylinders operating to pump air and substantially no injected fuel. When the answer to step 710 is yes, the routine continues to step 712 to determine whether the system is currently operating in the air-lean mode. When the answer to step 712 is yes, the routine transitions the engine to the air-stoichiometric mode by decreasing engine airflow. Next, from step 714, or when the answer to step 712 is no, the routine continues to step 716. In step 716, the routine calculates a lean air-fuel ratio with all cylinders operating (\u03bb) at the present airflow to provide the current engine torque. In the example of transitioning from four cylinders to eight cylinders, this air-fuel ratio is approximately 0.5 if the current operating conditions are in the air-stoichiometric mode. In other words, all the cylinders would require half the fuel to produce the same torque as half the cylinders at the current amount of fuel. Next, in step 718, the routine calculates the lean limit air-fuel ratio (\u03bb) for the conditions after the transition. In other words, the routine determines the combustion stability lean limit which is available after the transition for the operating conditions present. Then, in step 720, the routine determines whether the calculated lean air-fuel ratio to maintain engine torque (\u03bb) is greater than the lean limit air-fuel ratio. If the answer to step 720 is no, the transition is enabled without ignition timing retard. In this case, the routine transitions the cylinders to the new air-fuel ration calculated in step 716 to maintain engine torque. However, the more common condition is that the required air-fuel ratio to maintain engine torque is greater than the lean limit for the operating conditions. In this case, the routine continues to step 722 to transition the air-fuel ratio at the lean air-fuel limit and compensate the torque difference via the ignition timing retard. Further, the airflow is reduced until the engine can operate at the lean air-fuel ratio limit (or within a margin of the limit) without ignition timing retard. In this way, the transition to enabling cylinders with lean combustion can be utilized to improve fuel economy and maintain engine torque during the transition. Thus, not only is the torque balanced over the long term, but also over the short term using air-fuel enleanment in addition to ignition timing retard, if necessary. Further, this transition method achieves the a synergistic effect of rapid catalyst heating since the ignition timing retard and enleanment help increase heat to the exhaust system to rapidly heat any emission control devices coupled to deactivated cylinders. Note that various modifications can be made to this transition routine. For example, if transitioning to enable purging of NOx stored in the exhaust system, rich operation can follow the enleanment once airflow has been reduced. Referring now to , a routine is described for controlling engine cylinder valve operation (intake and/or exhaust valve timing and/or lift, including variable cam timing, for example) depending on engine conditions and engine operating modes. In general terms, the routine of allows engine cylinder valve operation for different groups of cylinders during engine starting to help compensate for variations in ignition timing between the groups. First, in step 810, the routine determines whether the present conditions represent an engine starting condition. This can be determined by monitoring if the engine is being turned by a starting motor. Note however, that engine starting can include not only the initial cranking by the starter, but also part of the initial warm up phase from a cold engine condition. This can be based on various parameters, such as engine speed, time since engine start, or others. Thus, when the answer to step 810 is yes, the routine then determines whether the engine is already in a warmed up condition in step 812. This can be based on, for example, engine coolant temperature. When the answer to step 812 is no, the routine sets the flag (flag_LS) to one. Otherwise, the flag is set to zero at 816. Next, the routine continues to step 818 where a determination is made as to whether split ignition operation is requested. One example of split ignition operation includes the following method for rapid heating of the emission control device when an emission control device(s) is below a desired operating temperature. Specifically, in this approach, the ignition timing between two cylinders (or two or more cylinder groups) is set differently. In one example, the ignition timing for the first group (spk_grp1) is set equal to a maximum torque, or best, timing (MBT_spk), or to an amount of ignition retard that still provides good combustion for powering and controlling the engine. Further, the ignition timing for the second group (spk_grp2) is set equal to a significantly retarded value, for example \u221229\xb0. Note that various other values can be used in place of the 29\xb0 value depending on engine configuration, engine operating conditions, and various other factors. Also, the power heat flag (ph_enable) is set to zero. The amount of ignition timing retard for the second group (spk_grp2) used can vary based on engine operating parameters, such as air-fuel ratio, engine load, and engine coolant temperature, or catalyst temperature (i.e., as catalyst temperature rises, less retard in the first and/or second groups, may be desired). Further, the stability limit value can also be a function of these parameters. Also note, as described above, that the first cylinder group ignition timing does not necessarily have to be set to maximum torque ignition timing. Rather, it can be set to a less retarded value than the second cylinder group, if such conditions provide acceptable engine torque control and acceptable vibration. That is, it can be set to the combustion stability spark limit (e.g., \u221210 degrees). In this way, the cylinders on the first group operate at a higher load than they otherwise would if all of the cylinders were producing equal engine output. In other words, to maintain a certain engine output (for example, engine speed, engine torque, etc.) with some cylinders producing more engine output than others, the cylinders operating at the higher engine output produce more engine output than they otherwise would if all cylinders were producing substantially equal engine output. An advantage to the above aspect is that more heat can be created by operating some of the cylinders at a higher engine load with significantly more ignition timing retard than if operating all of the cylinders at substantially the same ignition timing retard. Further, by selecting the cylinder groups that operate at the higher load, and the lower load, it is possible to minimize engine vibration. Thus, the above routine starts the engine by firing cylinders from both cylinder groups. Then, the ignition timing of the cylinder groups is adjusted differently to provide rapid heating, while at the same time providing good combustion and control. Also note that the above operation provides heat to both the first and second cylinder groups since the cylinder group operating at a higher load has more heat flux to the catalyst, while the cylinder group operating with more retard operates at a high temperature. Note that in such operation, the cylinders have a substantially stoichiometric mixture of air and fuel. However, a slightly lean mixture for all cylinders, or part of the cylinders, can be used. Also note that all of the cylinders in the first cylinder group do not necessarily operate at exactly the same ignition timing. Rather, there can be small variations (for example, several degrees) to account for cylinder to cylinder variability. This is also true for all of the cylinders in the second cylinder group. Further, in general, there can be more than two cylinder groups, and the cylinder groups can have only one cylinder. Further note that, as described above, during operation according to one example embodiment, the engine cylinder air-fuel ratios can be set at different levels. In one particular example, all the cylinders can be operated substantially at stoichiometry. In another example, all the cylinders can be operated slightly lean of stoichiometry. In still another example, the cylinders with more ignition timing retard are operated slightly lean of stoichiometry, and the cylinders with less ignition timing retard are operated slightly rich of stoichiometry. Further, in this example, the overall mixture of air-fuel ratio is set to be slightly lean of stoichiometry. In other words, the lean cylinders with the greater ignition timing retard are set lean enough such that there is more excess oxygen than excess rich gasses of the rich cylinder groups operating with less ignition timing retard. Continuing with , when the answer to step 818 is yes, the routine enables the split ignition operations in step 820 by setting the flag (PH_ENABLE_Flg) to one. Then, in step 822, the desired valve operation (in this case valve timing) for the first and second group of cylinders is calculated separately and respectively based on the conditions of the cylinder groups, including the air flow, air/fuel ratio, engine speed, engine torque (requested and actual), and ignition timing. In this way, an appropriate amount of air charge and residual charge can be provided to the different cylinder groups to better optimize the conditions for the respective ignition timing values used in the cylinders. The desired variable cam timings for the cylinder groups can also be based on various other parameters, such as catalyst temperature(s) and/or whether flag_CS is set to zero or one. When operating in the split ignition operation, at least during some conditions, this results in different VCT settings between different cylinder groups to provide improved engine operation and catalyst heating. In this way, the air flow to the cylinder with more advanced ignition timing can be used to control engine output torque, as well as the torque imbalance between the cylinder groups. Further, the airflow to the cylinder with more retarded ignition timing can be used to control the combustion stability, or heat flux produced. Also, if the engine is not equipped with VCT, but rather variable valve lift, or electrically actuated valves, then different airflow can be provided to different cylinders via valve lift, or variation of timing and/or lift of the electrically actuated valves. Furthermore, if the engine is equipped with multiple throttle valves (e.g., one per bank), then airflow to each group can be adjusted via the throttle valve, rather than via variations in VCT. Continuing with , when the answer to step 818 is no, the routine continues to step 824 where a determination is made as to whether fuel injector cut-out operation of a cylinder, or cylinder groups, is enabled. When the answer to step 824 is yes, the routine continues to step 826 to calculate the desired cam timing (s) for operating cylinder group(s) taking into account the cylinder cut-out operation. In other words, different valve timings can be selected, at least during some conditions, based on whether cylinder cut-out operation is engaged. Thus, the VCT timing for the respective cylinder groups is based on the air-fuel ratio of combustion in the group combusting air and injected fuel, while the VCT timing for the group without fuel injection is selected to, in one example, minimize engine pumping losses. Alternatively, when transitioning into, or out of, the partial or total cylinder cut-out operation, the VCT timing for the respective cylinder groups is adjusted based on this transition. For example, when enabling combustion of cylinder previous in cylinder cut-out operation, the VCT timing is adjusted to enable efficient and low emission re-starting of combustion, which can be a different optimal timing for the cylinders which were already carrying out combustion of air and injected fuel. This is described in more detail below with regard to , for example. Alternatively, when the answer to step 824 is no, the valve timing for the cylinder groups is selected based on engine speed and load, for example. In this way, it is possible to select appropriate valve timing to improve cylinder cut-out operation. When firing groups coincide with VCT (or bifurcated intake groups), it is possible to optimize the amount of catalyst heating (or efficient engine operation) depending on the vehicle tolerance to different types of excitation (NVH) given the operating conditions. Specifically, in one example, NVH performance can be improved by reducing the airflow to cylinders with significantly retarded ignition timing to reduce any effect of combustion instability that may occur. Likewise, in another example, engine torque output can be increased, without exacerbating combustion instability, by increasing airflow to the cylinder(s) with more advanced ignition timing. This can be especially useful during idle speed control performed via an idle bypass valve, or via the electronic throttle, where even though total airflow is being increased, that increased airflow can be appropriately allocated to one cylinder group or another depending on the ignition timing split used. Note that an alternative starting routine is described in . Referring now to , a routine is described for identifying pedal tip-out conditions, and using such information to enable or disable fuel injection to cylinders, or cylinder groups, of the engine. First, in step 910, the routine identifies whether a tip-out condition has been detected. Note that there are various approaches to detecting a tip-out condition, such as, for example: detecting if whether the pedal has been released by the vehicle driver's foot, whether a requested engine output has decreased below a threshold value (for example, below zero value engine brake torque), whether a requested wheel torque has decreased below a threshold level, or various others. When the answer to step 910 is yes and a tip-out condition has been detected, the routine continues to step 912. In step 912, the routine determines whether the requested engine output is less than threshold T1. In one example, this threshold is the minimum negative engine output that can be achieved with all the cylinders combusting. This limit can be set due to various engine combustion phenomena, such as engine misfires, or significantly increased emissions. Also note that various types of requested engine output can be used, such as, for example: engine torque, engine brake torque, wheel torque, transmission output torque, or various others. When the answer to step 912 is yes, the routine continues to step 914. In step 914, the routine enables a fuel cut operation, which is discussed in more detail below with regard to . Alternatively, when the answer to either step 910 or 912 is no, the routine continues to step 916 in which combustion in all the cylinders of the engine is continued. Note that the fuel cut operation enabled in step 914 can be various types of cylinder fuel cut operation. For example, only a portion of the engine's cylinders can be operated in the fuel cut operation, or a group of cylinders can be operated in the fuel cut operation, or all of the engine cylinders can be operated in the fuel cut operation. Furthermore, the threshold T1 discussed above with regard to step 912 can be a variable value that is adjusted based on the current engine conditions, including engine load and temperature. Referring now to , an example routine is described for controlling fuel cut operation, which can be used with a variety of system configurations, such as, for example, . First, in step 1010, the routine determines whether fuel cut operation has been enabled as discussed above with regard to step 914 of . When the answer to step 1010 is yes, the routine continues to step 1012. In step 1012, the routine determines the number of cylinder groups to disable based on the requested engine output and current engine and vehicle operating conditions. These operating conditions include the catalyst operating conditions, temperature (engine temperature and/or catalyst temperature) and engine speed. Next, in step 1014, the routine determines the number of cylinders in the groups to be disabled based on the requested engine output and engine and vehicle operating conditions. In other words, the routine first determines the number of cylinder groups to be disabled, and then determines within those groups, the number of cylinders of the groups to be disabled. These determinations are also selected depending on the engine and exhaust catalyst configuration. For example, in cases using a downstream lean NOx trap, in addition to disabling cylinders, the remaining active cylinders can be operated at a lean air-fuel ratio. Continuing with , in step 1016, the routine determines whether the requested engine output is greater than a threshold T2, such as when a vehicle driver tips-in to the vehicle pedal. When the answer to step 1016 is no, the routine continues to step 1018 to determine whether temperature of the emission control devices coupled to disabled cylinders is less than a minimum temperature (min_temp). As such, the routine monitors the requested engine output and the temperature of the emission control devices to determine whether to re-enable cylinder combustion in the activated cylinders. Thus, when the answer to either step 1016 or 1018 is yes, the routine continues to step 1020 to disable fuel cut operation and enable combustion. This enabling can enable all the cylinders to return to combustion or only a part of the activated cylinders to return to combustion. Whether all or only a portion of the cylinders are reactivated depends on various engine operating conditions and on the exhaust catalyst configuration. For example, when three-way catalysts are used without a lean NOx trap, all of the cylinders may be enabled to carry out combustion. Alternatively, when a downstream lean NOx trap is used, all or only a portion of the cylinders may be re-enabled at a lean air-fuel ratio, or some of the cylinders can be re-enabled to carry out stoichiometric combustion. Note that before the fuel cut operation is enabled, the engine can be operating with all the cylinders carrying out lean, stoichiometric, or rich engine operation. Referring now to , a routine is described for performing idle speed control of the engine, taking into account fuel vapor purging. First, in step 1110, the routine determines whether idle speed control conditions are present. Idle speed conditions can be detected by monitoring whether the pedal position is lower than a preselected threshold (indicating the driver's foot is off the pedal) and the engine speed is below a threshold speed (for example 1000 RPM). When the answer to step 1110 is yes, the routine continues to step 1112. In step 1112, the routine determines whether lean combustion is enabled based on the current engine operating conditions, such as exhaust temperature, engine coolant temperature, and other conditions, such as whether the vehicle is equipped with a NOx trap. When the answer to step 1112 is no, the routine continues to step 1114. In step 1114, the routine maintains the desired idle speed via the adjustment of air flow to the engine. In this way, the air flow is adjusted so that the actual speed of the engine approaches the desired idle speed. Note that the desired idle speed can vary depending on operating conditions such as engine temperature. Next, in step 1116, the routine determines whether fuel vapors are present in the engine system. In one example, the routine determines whether the purge valve is actuated. When the answer to step 1116 is yes, the routine continues to step 1118. In step 1118, the routine adjusts the fuel injection amount (to the cylinders receiving fuel vapors) to maintain the desired air-fuel ratio, as well as compensate for the fuel vapors, while fuel injected to cylinders combusting without fuel vapors (if any) can be set to only a feed-forward estimate, or further adjusted based on feedback from the exhaust gas oxygen sensor. Thus, both cylinders with and without fuel vapor are operated at a desired air-fuel ratio by injecting less fuel to the cylinders with fuel vapors. In one example, the desired combustion air-fuel ratio oscillates about the stoichiometric air-fuel ratio, with feedback from exhaust gas oxygen sensors from the engine's exhaust. In this way, the fuel injection amount in the cylinders with fuel vapors is compensated, while the fuel injection amount to cylinders operating without fuel vapors is not affected by this adjustment, and all of the cylinders combusting are operated about stoichiometry. Next, in step 1120, the routine determines whether the fuel injection pulse width (to the cylinders with fuel vapors) is less than a minimum value (min_pw). When the answer to step 1120 is yes, the routine continues to step 1122 to disable fuel vapor purging and close the purge valve (s). In this way, the routine prevents the fuel injection pulse width from becoming lower than a minimum allowed pulse width to operate the injectors. When the answer to either step 1116, or 1120 is no, the routine continues to the end. When the answer to step 1112 is yes, the routine continues to step 1124. Then, in step 1124, the routine maintains the desired idle speed via adjustment of fuel injection. In this way, the fuel injection amount is adjusted, so that the actual speed of the engine approaches the desired idle speed. Note that this lean combustion conditions includes conditions where some cylinders operate with a lean air-fuel ratio, and other cylinders operate without injected fuel. Next, in step 1126, the routine determines whether fuel vapors are present in the engine (similar to that in step 1116). When the answer is yes, the routine continues to step 1128 where air flow is adjusted to maintain the air-fuel ratio in the combusting cylinders and compensate for the fuel vapors. Note that there are various ways to adjust the air flow to the cylinders carrying out combustion, such as by adjusting the throttle position of the electronically controlled throttle plate. Alternatively, air flow can be adjusted by changing valve timing and/or lift, such as by adjusting a variable cam timing actuator. Next, in step 1130, a routine determines whether the cylinder air-fuel ratio (of cylinders carrying out combustion) is less than a minimum value (afr_min). In one example, this is a minimum lean air-fuel ratio, such as 18:1. In addition, the routine monitors whether air flow is at the maximum available air flow for the current engine operating conditions. If not, the engine first attempts to increase air flow by further opening the throttle, or adjusting valve timing and/or lift. However, when air flow is already at a maximum available amount, the routine continues to step 1132 to disable lean combustion. The routine may still allow continued cylinder fuel cut-out operation since this operation provides for maximum fuel vapor purging in a stoichiometric condition as will be discussed below. When the answer to either step 1110, 1126, or 1130, is no, the routine continues to the end. In this way, it is possible to operate with fuel vapor purging and improve operation of both lean and stoichiometric combustion. Specifically, by using fuel injection to maintain idle speed during lean conditions, and air flow to maintain idle speed during non-lean conditions, it is possible to provide accurate engine idle speed control during both conditions. Also, by disabling lean operation, yet continuing to allow cylinder fuel cut-out operation, when the fuel vapors are too great to allow lean combustion, it is possible to improve the quantity of fuel vapor purge that can be processed. In other words, during cylinder fuel cut-out operation, all the fuel vapors are fed to a portion of the cylinders, for example as shown in . However, since less than all the cylinders are carrying out the combustion to generate engine output, these cylinders operate at a higher load, and therefore a higher total requirement of fuel to be burned. As such, the engine is less likely to experience conditions where the fuel injectors are less than the minimum pulse width than compared if all the cylinders were carrying out combustion with fuel vapors. In this way, improved fuel vapor purging capacity can be achieved. Referring now to , routines are described for controlling cylinder valve adjustment depending, in part, on whether some or all of the cylinders are operating an a fuel-cut state. In general, the routine adjusts the cylinder valve timing, and/or valve lift, based on this information to provide improved operation. Also, the routine of is an example routine that can be used for system configurations such as those shown in , 2P, 2S and/or 2T. The routine of is an example routine that can be used for system configurations such as those shown in . First, in step 1210, the routine determines whether the engine is operating in a full or partial fuel injector cut-out operation. When the answer to step 1210 is yes, the routine continues to step 1212. In step 1212, the routine determines a desired cylinder valve actuation amount for a first and second actuator. In this particular example, where a first and second variable cam timing actuator are used to adjust cam timing of cylinder intake and/or exhaust valves, the routine calculates a desired cam timing for the first and second actuator (VCT_DES1 and VCT_DES2). These desired cam timing values are determined based on the cylinder cut-out condition, as well as engine operating conditions such as the respective air-fuel ratios and ignition timing values between different cylinder groups, throttle position, engine temperature, and/or requested engine torque. In one embodiment, the operating conditions depend on operating mode. Specifically, in addition to engine speed versus torque, the following conditions are considered in an idle speed mode: engine speed, closed pedal, crank start, engine temperature, and air charge temperature. In addition to engine speed versus torque, the following conditions are considered in a part throttle or wide open throttle condition: rpm, desired brake torque, and desired percent torque. In one example, where the routine is applied to a system such as in or 2T, the routine can further set a cam timing per bank of the engine, where the cylinder groups have some cylinders from each bank in the group. Thus, a common cam timing is used for both cylinders with and without combustion from injected fuel. As such, the desired cam timing must not only provide good combustion in the cylinders carrying out combustion, but also maintain a desired manifold pressure by adjusting airflow though the engine, along with the throttle. Note that in many conditions, this results in a different cam timing for the combusting cylinders than would be obtained if all of the cylinders were carrying out combustion in the cylinder group. Alternatively, when the answer to step 1210 is no, the routine continues to step 1214 to calculate the desired valve actuator settings (VCT_DES1 and VCT_DES2) based on engine conditions, such as engine speed, requested engine torque, engine temperature, air-fuel ratio, and/or ignition timing. From either of steps 1212 or 1214, the routine continues to step 1216 where a determination is made as to whether the engine is transitioning into, or out of, full or partial fuel injector cut-out operation. When the answer to step 1216 is no, the routine continues to step 1218 where no adjustments are made to the determined desired cylinder valve values. Otherwise, when the answer to step 1216 is yes, the routine continues to step 1220 where the routine determines whether the transition is to re-enable fuel injection, or cut fuel injection operation. When it is determined that a cylinder, or group of cylinders, is to be re-enabled, the routine continues to step 1222. Otherwise, the routine continues to the end. In step 1222, the routine adjusts the desired cam timing values (VCT_DES1 and/or VCT_DES2) of cylinder valves coupled to cylinders being re-enabled to a re-starting position (determine based on engine coolant temperature, airflow, requested torque, and/or duration of fuel-cut operation). In this way, it is possible to have improved re-starting of the cylinders that were in fuel-cut operation. In the case where both cylinders are operated in a fuel cut operation, all of the cylinders can be restarted at a selected cam timing that provides for improved starting operation. Note that due to different system configurations, this may also adjust cam timing of cylinders already carrying out combustion. As such, additional compensation via throttle position or ignition timing can be used to compensate for increases or decreases engine output due to the adjustment of cam timing before the transition. The details of the transition are discussed in more detail above and below, such as regarding , for example. Referring now to , an alternative embodiment for controlling cylinder valve actuation based on fuel-cut operation is described. First, in step 1230, the routine determines whether the engine is operating in a full or partial fuel injector cut-out operation. When the answer to step 1230 is yes, the routine continues to step 1232. In step 1232, the routine determines a desired cylinder valve actuation amount for an actuator coupled to a group of cylinders in which fuel injection is disabled. In one example, this is a desired cam timing value. Further, the routine also calculates an adjustment to throttle position, along with the cam timing, to adjust the engine output to provide a requested engine output. In one example, the requested engine output is a negative (braking) engine torque value. Further, in step 1232, the routine adjusts the cam timing for the combusting cylinders (if any) based on conditions in those combusting cylinders. Alternatively, the routine can set the desired cylinder valve actuation amount for deactivated cylinders to provide a desired engine pumping loss amount, since adjusting the cam timing of the cylinders will vary the intake manifold pressure (and airflow), thus affecting engine pumping losses. Note that in some cases, this results in a different cam timing being applied to the group of cylinders combusting than the group of cylinders in fuel-cut operation. Alternatively, when the answer to step 1230 is no, the routine continues to step 1234 to calculate the desired valve actuator settings (VCT_DES1 and VCT_DES2) based on engine conditions, such as engine speed, requested engine torque, engine temperature, air-fuel ratio, and/or ignition timing as shown in step 1214. From either of steps 1232 or 1234, the routine continues to step 1236 where a determination is made as to whether the engine is transitioning into, or out of, full or partial fuel injector cut-out operation. When the answer to step 1236 is no, the routine continues to step 1238 where no adjustments are made to the determined desired cylinder valve values. Otherwise, when the answer to step 1236 is yes, the routine continues to step 1240 where the routine determines whether the transition is to re-enable fuel injection, or cut fuel injection operation. When it is determined that a cylinder, or group of cylinders, is to be re-enabled, the routine continues to step 1242. Otherwise, the routine continues to the end. In step 1242, the routine adjusts the cam timing actuators coupled to disabled cylinders to a re-starting position. Note that the cylinders can re-start at a lean air-fuel ratio, a rich air-fuel ratio, or at stoichiometry (or to oscillate about stoichiometry). In this way, by moving the cam timing that provides for improved starting, while optionally leaving the cam timing of cylinders already combusting at its current condition, it is possible provide improved starting operation. Referring now to , routines and corresponding example results are described for controlling partial and full cylinder cut operation to reestablish the oxygen storage amount in the downstream three-way catalyst, as well as to reestablish the fuel puddle in the intake manifold to improve transient fuel control. Note that the routines can be carried out with various system configurations as represented in . For example, the routine of can be utilized with the system of , for example. Likewise, the routine of can be utilized with the system of . Referring now specifically to FIG. 13A, in step 1302, the routine determines whether partial cylinder fuel cut-out operation is present. When the answer to step 1302 is yes, the routine continues to step 1304. In step 1304, the routine determines whether the cylinders carrying out combustion are operating about stoichiometry. When the answer to step 1304 is yes, the routine continues to step 1306. In step 1306, the routine determines whether transition to operate both cylinder groups to combust an air-fuel ratio that oscillates about stoichiometry has been requested by the engine control system. When the answer to any of steps 1302, 1304, or 1306 are no, the routine continues to the end. When the answer to step 1306 is yes, the routine continues to step 1308. In step 1308, the routine enables fuel injection in the disabled cylinder group at a selected rich air-fuel ratio, while continuing operation of the other cylinder carrying out combustion about stoichiometry. The selected rich air-fuel ratio for the re-enabled cylinders is selected based on engine operating conditions such as, for example: catalyst temperature, engine speed, catalyst space velocity, engine load, and such or requested engine torque. From step 1308, the routine continues to step 1310, where a determination is made as to whether the estimated actual amount of oxygen stored in the downstream three-way catalyst (O2_d_act) is greater than a desired amount of oxygen (O2_d_des). When the answer to step 1310 is yes, the routine continues to step 1312 to continue the rich operation of the re-enabled cylinder group at a selected rich air-fuel ratio, and the oscillation about stoichiometry of the air-fuel ratio of the already combusting cylinders. As discussed above with regard to step 1308, the rich air-fuel ratio is selected based on engine operating conditions, and various depending upon them. From step 1312, the routine returns to step 1310 to again monitor the amount of oxygen stored in the downstream three-way catalyst. Alternatively, the routine of can also monitor a quantity of fuel in the puddle in the intake manifold of the cylinders that are being re-enabled in step 1310. When the answer to step 1310 is no, the routine continues to step 1314 which indicates that the downstream three-way catalyst has been reestablished at a desired amount of stored oxygen between the maximum and minimum amounts of oxygen storage, and/or that the fuel puddle in the intake manifold of the various enabled cylinders has been reestablished. As such, in step 1314, the routine operates both groups about stoichiometry. In this way, it is possible to re-enable the cylinders from a partial cylinder cut-out operation and reestablish the emission control system to a situation in which improved emission control can be achieved. The operation of is now illustrated via an example as shown in FIGS. 13B1 and 13B2. 1 shows the air-fuel ratio of group 1, while 2 shows the air-fuel ratio of group 2. At time T0, both cylinder groups operate to carry out combustion about the stoichiometric value. Then, at time T1, it is requested to transition the engine to partial cylinder cut operation, and therefore the cylinder group 1 is operating at a fuel cut condition. As shown in 1, the air-fuel ratio is infinitely lean and designated via the dashed line that is at a substantially lean air-fuel ratio. Then, at time T2, it is desired to re-enable the partially disabled cylinder operation, and therefore the cylinder group 1 is operated at a rich air-fuel ratio as shown in 1, this rich air-fuel ratio varies as engine operating conditions change. The rich operation of group 1 and the stoichiometric operation of group 2 continues until time T3, at which point it is determined that the downstream emission control device has been reestablished to an appropriate amount of oxygen storage. As described elsewhere herein, the identification of when to discontinue the rich regeneration operation can be based on estimates of stored oxygen, and/or based on when a sensor downstream of the downstream emission control device switches. At time T3, both cylinder groups are returned to stoichiometric operation, as shown in FIGS. 13B1 and 13B2. As such, improved engine operation is achieved since the second cylinder group can remain combusting at stoichiometry throughout these transitions, yet the downstream emission control device can have its oxygen storage reestablished via the rich operation of the first cylinder group. This reduces the amount of transitions in the second cylinder group, thereby further improving exhaust emission control. Referring now to , a routine is described for controlling cylinder cut-out operation where both cylinder groups are disabled. First, in step 1320, the routine determines whether all cylinders are presently in the cylinder cut operation. When the answer to step 1320 is yes, the routine continues to step 1322 to determine whether the cylinders will be carrying out stoichiometric combustion when enabled. When the answer to step 1322 is yes, the routine continues to step 1324 to determine whether the transition of one or two groups is requested to be enabled. In other words, the routine determines whether it has been requested to enable only one cylinder group, or to enable two cylinder groups to return to combustion. When the answer to step 1324, or step 1322, or step 1320, is no, the routine ends. Alternatively, when in step 1324, it is requested to enable both cylinder groups, the routine continues to step 1326. In step 1326, the routine operates fuel injection in both cylinder groups at a selected rich air-fuel ratio. Note that the groups can be operated at the same rich air-fuel ratio, or different rich air-fuel ratios. Likewise, the individual cylinders in the groups can be operated at different rich air-fuel ratios. Still further, in an alternative embodiment, only some of the cylinders are operated rich, with the remaining cylinders operating about stoichiometry. From step 1326, the routine continues to step 1328. In step 1328, the routine determines whether the estimated amount of oxygen stored in the upstream three-way catalyst coupled to the first group (O2_u1_act) is greater than a desired amount of stored oxygen for that catalyst (O2_u1_des). When the answer to step 1320 is no, indicating that the oxygen storage amount has not yet been reestablished in that device, the routine continues to step 1330 to calculate whether the estimated actual amount of oxygen stored in the emission upstream three-way catalyst coupled to the second group (O2_u2_act) is greater than its desired amount of stored oxygen (O2_u2_des). When the answer to step 1330 is no, indicating that neither upstream three-way catalyst coupled to the respective first and second groups' cylinders has been reestablished to their respective desired amounts of stored oxygen, the routine continues to step 1326, where rich operation in both cylinder groups is continued at the selected air-fuel ratio. Also note that the selected rich air-fuel ratio is adjusted based on engine operating conditions as described above herein with regard to step 1308, for example. When the answer to step 1328 is yes, indicating that the upstream three-way catalyst coupled to the first cylinder group has had its oxygen amount reestablished, the routine continues to step 1332 to transition the first group to operate about stoichiometry. Next, the routine continues to step 1334 where it continues operation of the second a t the selected rich air-fuel ratio and the second group to combust an air-fuel mixture that oscillates about stoichiometry. Then, the routine continues to step 1336, where a determination is made as to whether the estimated amount of stored oxygen in a downstream three-way catalyst (which is coupled to at least one of the upstream three-way catalysts, if not both) is greater than its desired amount of stored oxygen. When the answer to step 1336 is no, the routine returns to step 1334 to continue the rich operation in the second group, and the stoichiometric operation in the first group. Alternatively, when the answer to step 1336 is yes, the routine continues to step 1338 to transition both cylinder groups to operate about stoichiometry. Continuing with , when the answer to step 1330 is yes, indicating that the oxygen amount has been reestablished in the emission upstream three-way catalyst coupled to the second group, the routine transitions the second group to stoichiometry in step 1342. Then, in step 1344, the routine continues to operate the first cylinder group at the rich air-fuel ratio and the second cylinder group about stoichiometry. Then, the routine continues to step 1346 to again monitor the oxygen storage amount in the downstream three-way catalyst. From step 1346, when the downstream fuel catalyst has not yet had enough oxygen depleted to reestablish the oxygen amount, the routine returns to step 1344. Alternatively, when the answer to step 1346 is yes, the routine also transitions to step 1338 to have both cylinder groups operating about stoichiometry. From step 1324, when it is desired to transition only one cylinder group to return to combustion, the routine continues to step 1350 to enable fuel injection in one cylinder group at the selected rich air-fuel ratio and continue fuel cut operation in the other cylinder group. This operation is continued in step 1352. Note that for this illustration, it is assumed that in this case the first cylinder group has been enabled to carry out combustion, while the second cylinder group has continued operating at fuel cut operation. However, which cylinder group is selected to be enabled can vary depending on engine operating conditions, and can be alternated to provide more even cylinder ware. From step 1352, the routine continues to step 1354, where a determination is made as to whether the estimated actual amount of stored oxygen in the upstream three-way catalyst coupled to the first cylinder group (O2u1_act) is greater than the desired amount (O2_u1_des). When the answer to step 1354 is no, the routine returns to step 1352. Alternatively, when the answer to step 1354 is yes, the routine continues to step 1356 to operate a first cylinder group about stoichiometry and continue the operation of the second cylinder group in the fuel cut operation. Finally, in step 1358, the routine transfers to to monitor further requests to enable the second cylinder group. In this way, it is possible to allow for improved re-enablement of cylinder fuel cut operation to properly establish the oxygen storage not only in the upstream three-way catalyst, but also in the downstream three-way catalyst without operating more cylinders rich than is necessary. As described above, this can be accomplished using an estimate of stored oxygen in an exhaust emission control device. However, alternatively, or in addition, it is also possible to use information from a centrally mounted air-fuel ratio sensor. For example, a sensor that is mounted at a location along the length of the emission control device, such as before the last brick in the canister, can be used. In still another approach, downstream sensor(s) can be used to determine when regeneration of the oxygen storage is sufficiently completed. Example operation of is illustrated in the graphs of FIGS. 13D1 and 13D2. Like FIGS. 13B1 and B2, 1 shows the air-fuel ratio of the first cylinder group and 2 shows the air-fuel ratio of the second cylinder group. At time T0, both cylinder groups are operating to carry out combustion about the stoichiometric air-fuel ratio. Then, at time T1, it is requested to disable fuel injection in both cylinder groups. As such, both cylinder groups are shown to operate at a substantially infinite lean air-fuel ratio until time T2. At time T2, it is requested to enable combustion in both cylinder groups. As such, both cylinder groups are shown operating at a rich air-fuel ratio. As illustrated in the figures, the level richness of this air-fuel ratio can vary depending on operating conditions. From times T2 to T3, the oxygen saturated upstream first and second three-way catalysts are having the excess oxygen reduced to establish a desired amount of stored oxygen in both the catalysts. At time T3, the upstream three-way catalyst coupled to the second group has reached the desired amount of stored oxygen and therefore the second cylinder is transitioned to operate about stoichiometry. However, since the downstream three-way catalyst has not yet had its excess oxygen reduced, the first cylinder group continues at a rich air-fuel ratio to reduce all the stored oxygen in the upstream three-way catalyst coupled to the first group, and therefore provide reductants to reduce some of the stored oxygen in the downstream three-way catalyst. Thus, at time T4, the rich operation of the first cylinder group has ended since the downstream three-way catalyst has reached its desired amount of stored oxygen. However, at this point, since the upstream three-way catalyst is saturated at substantially no oxygen storage, the first cylinder groups operate slightly lean for a short duration until T5 to reestablish the stored oxygen in the upstream three-way catalyst. At time T5, then both cylinder groups operate about stoichiometry until time T6, at which time again is desired to operate both cylinders without fuel injection. This operation continues to time T7 at which point it is desired to re-enable only one of the cylinder groups to carry out combustion. Thus, the first cylinder group is operated at a rich air-fuel ratio for a short duration until the oxygen storage has been reestablished in the first upstream three-way catalyst coupled to the first cylinder group. Then, the first cylinder group returns to stoichiometric operation until time T8. At time T8, it is desired to re-enable the second cylinder group. At this time, the second cylinder group operates at a rich air-fuel ratio that varies depending on the engine operating conditions to reestablish the stored oxygen in the downstream three-way catalyst. Then, at time T9, the second cylinder group operates slightly lean for a short duration to reestablish some stored oxygen in the upstream three-way catalyst coupled to the second group. Then, both cylinder groups are operated to oscillate above stoichiometry. In this way, improved operation into and out of cylinder fuel cut conditions can be achieved. Note that regarding the approach taken in \u2014by re-enabling with rich combustion, any NOx generated during the re-enablement can be reacted in the three way catalyst with the rich exhaust gas, further improving emission control. Referring now to , example emission controls device are described which can be used as devices 300 and/or 302 from . As discussed above, fuel economy improvements can be realized on engines (for example, large displacement engines) by disabling cylinders under conditions such as, for example, low load, or low torque request conditions. Cylinder deactivation can take place by either deactivating valves so the cylinders do not intake or exhaust air or by deactivating fuel injectors to the inactive cylinders pumping air. In the latter scheme, the bifurcated catalyst described in has the advantage that they can keep the exhaust from the firing cylinders separate from the non-firing cylinders so that the emission control device (such as, for example, a 3-way catalyst) can effectively convert the emissions from the firing cylinders. This is true even when used on an uneven firing V8 engine (where disabling cylinders to still give a torque pulse every 180 crank angle degrees requires disabling half of the cylinders on one bank and half of the cylinders on the other bank). The bifurcated catalyst approach thus avoids the need to pipe the air cylinders to one catalyst and the firing cylinders to another catalyst with a long pipe to cross the flow from one side of the engine to the other. As such, it is possible, if desired, to maintain current catalyst package space without requiring complicated crossover piping. Specifically, shows a bifurcated catalyst substrate 1410 with a front face 1420 and a rear face (not shown). The substrate is divided into an upper portion 1422 and a lower portion 1424. The substrate is generally oval in cross-sectional shape; however, other shapes can be used, such as circular. Further, the substrate is formed with a plurality of flow paths formed from a grid in the substrate. In one particular example, the substrate is comprised of metal, which helps heat conduction from one portion of the device to the other, thereby improving the ability to operate one group of cylinders in a fuel-cut state. However, a ceramic substrate can also be used. The substrate is constructed with one or more washcoats applied having catalytic components, such as ceria, platinum, palladium, rhodium, and/or other materials, such as precious metals (e.g., metals from Group-8 of the periodic table). However, in one example, a different washcoat composition can be used on the upper portion of the substrate and the lower portion of the substrate, to accommodate the different operating conditions that may be experienced between the two portions. In other words, as discussed above, one or the other of the upper and lower portions can be coupled to cylinders that are pumping air without injected fuel, at least during some conditions. Further, one portion or the other may be heated from gasses in the other portion, such as during the above described cylinder fuel-cut operation. As such, the optimal catalyst washcoat for the two portions may be different. In this example, the two portions are symmetrical. This may allow for the situation where either group of cylinders coupled to the respective portions can be deactivated if desired. However, in an alternative embodiment, the portions can be asymmetrical in terms of volume, size, length, washcoats, or density. Referring now to , an emission control device 1510 is shown housing substrate 1410. The device is shown in this example with an inlet cone 1512 an inlet pipe 1514, an exit cone 1516, and an exit pipe 1618. The inlet pipe and inlet cone are split into two sides (shown here as a top and bottom portion; however, any orientation can be used) each via dividing plates 1520 and 1522. The two sides may be adjacent, as shown in the figure, but neither portion encloses the other portion, in this example. The dividing plates keep a first and second exhaust gas flow stream (1530 and 1532) separated up to the point when the exhaust gas streams reach the substrate portions 1422 and 1424, respectively. The dividing plates are located so that a surface of the plate is located parallel to the direction of flow, and perpendicular to a face of the substrate 1410. Further, as discussed above, because the paths through the substrate are separated from one another, the two exhaust gas streams stay separated through substrate 1410. Also, exit cone 1516 can also have a dividing plate, so that the exhaust streams are mixed after entering exit pipe 1518. Continuing with , four exhaust gas oxygen sensors are illustrated (1540, 1542, 1544, and 1546), however only a subset of these sensors can be used, if desired. As shown by , sensor 1540 measures the oxygen concentration, which can be used to determine an indication of air-fuel ratio, of exhaust stream 1530 before it is treated by substrate 1410. Sensor 1542 measures the oxygen concentration of exhaust stream 1532 before it is treated by substrate 1410. Sensor 1544 measures the oxygen concentration of exhaust stream 1530 after it is treated by substrate 1410, but before it mixes with stream 1532. Likewise, sensor 1546 measures the oxygen concentration of exhaust stream 1532 after it is treated by substrate 1410, but before it mixes with stream 1530. Additional downstream sensors can also be used to measure the mixture oxygen concentration of streams 1530 and 1532, which can be formed in pipe 1518. also shows cut-away views of the device showing an oval cross-section of the catalyst substrate, as well as the inlet and outlet cones and pipes. However, circular cross-sectional pipe, as well as substrate, can also be used. Referring now to , a routine is described for selecting a desired idle speed control set-point for idle speed control which takes into account whether cylinders are deactivated, or whether split ignition timing is utilized. Specifically, as shown in step 1610, the routine determines a desired idle speed set-point, used for feedback control of idle speed via fuel and/or airflow adjustment, based on the exhaust temperature, time since engine start, and/or the cylinder cut state. This allows for improved NVH control, and specifically provides, at least under some conditions, a different idle speed set-point depending on cylinder cut-operation to better consider vehicle resonances. The control strategy of desired idle rpm may also be manipulated to improve the tolerance to an excitation type. For example, in split ignition mode, a higher rpm set-point may reduce NVH by moving the excitation frequency away from that which the vehicle is receptive. Thus, the split ignition idle rpm may be higher than that of a non-split ignition mode. Referring now to , a routine is described for coordinating cylinder deactivation with diagnostics. Specifically, cylinder deactivation is enabled and/or affected by a determination of whether engine misfires have been identified in any of the engine cylinders. For example, in the case of a V-6 engine as shown in , if it is determined that an ignition coil has degraded in one of the cylinders in group 250, then this information can be utilized in enabling, and selecting, cylinder deactivation. Specifically, if the control routine alternatively selects between group 250 and 252 to be deactivated, then the routine could modify this selection based on the determination of degradation of a cylinder in group 250 to select cylinder deactivation of group 250 repeatedly. In other words, rather than having the ability to deactivate ether group 250 or group 252, the routine could deactivate the group which has a cylinder identified as being degraded (and thus potentially permanently deactivated until repair). In this way, the routine could eliminate, at least under some conditions, the option of deactivating group 252. Otherwise, if group 252 were selected to be deactivated, then potentially four out of six cylinders would be deactivated, and reduced engine output may be experienced by the vehicle operator. Likewise, if diagnostics indicate that at least one cylinder from each of groups 250 and 252 should be disabled due to potential misfires, the cylinder cut-out operation is disabled, and all cylinders (except those disabled due to potential misfires) are operated to carry out combustion. Thus, if the control system has the capability to operate on less than all the engine's cylinders and still produce driver demanded torque in a smooth fashion, then such a mode may be used to disable misfiring cylinders with minimal impact to the driver. This decision logic may also include the analysis of whether an injector cutout pattern would result in all the required cylinders being disabled due to misfire. describes an example routine for carryout out this operation. Specifically, in step 1710, the routine determines whether the engine diagnostics have identified a cylinder or cylinders to have potential misfire. In one example, when the diagnostic routines identify cylinder or cylinders to have a potential misfire condition, such as due to degraded ignition coils, those identified cylinders are disabled and fuel to those cylinders is deactivated until serviced by a technician. This reduces potential unburned fuel with excess oxygen in the exhaust that can generate excessive heat in the exhaust system and degrade emission control devices and/or other exhaust gas sensors. When the answer to step 1710 is no, the routine ends. Alternatively, when the answer to step 1710 is yes, the routine continues to step 1712, where a determination is made as to whether there is a cylinder cutout pattern for improved fuel economy that also satisfies the diagnostic requirement that a certain cylinder, or cylinders, be disabled. In other words, in one example, the routine determines whether there is a cylinder cutout mode that can be used for fuel economy in which all of the remaining active cylinders are able to be operated with fuel and air combusting. When the answer to step 1712 is yes, the routine continues to step 1714 in which the patterns that meet the above criteria are available for injector cutout operation. Patterns of cylinder cutout in which cylinders that were selected to remain active have been identified to have potential misfire, are disabled. In this way, it is possible to modify the selection and enablement of cylinder cutout operation to improve fuel economy, while still allowing proper deactivation of cylinders due to potential engine misfires. As described in detail above, various fuel deactivation strategies are described in which some, or all, of the cylinders are operated in a fuel-cut state depending on a variety of conditions. In one example, all or part of the cylinders can be operated in a fuel-cut state to provide improved vehicle deceleration and fuel economy since it is possible to provide engine braking beyond closed throttle operation. In other words, for improved vehicle deceleration and improved fuel economy, it may be desirable to turn the fuel to some or all of the engine cylinders engine off under appropriate conditions. However, one issue that may be encountered is whether the engine speed may drop too much after the fuel is disabled due to the drop in engine torque. Depending on the state of accessories on the engine, the state of the torque converter, the state of the transmission, and other factors discussed below, the fuel-off torque can vary. In one example, an approach can be used in which a threshold engine speed can be used so that in worst case conditions, the resulting engine speed is greater than a minimum allowed engine speed. However, in an alternative embodiment, if desired, a method can be used that calculates, or predicts, the engine speed after turning off the fuel for a vehicle in the present operating conditions, and then uses that predicted speed to determine whether the resulting engine speed will be acceptable (e.g., above a minimum allowed speed for those conditions). For example, the method can include the information of whether the torque converter is locked, or unlocked. When unlocked, a model of the torque converter characteristics may be used in such predictions. Further, the method may use a minimum allowed engine speed to determine a minimum engine torque that will result from fuel shut off operation to enable/disable fuel shut off. Examples of such control logic are described further below with regard to . Such a method could also be used to screen other control system decisions that will affect production of engine torque in deceleration conditions, such as whether to enable/disable lean operation in cylinders that remain combusting when others are operated without fuel injection. Examples of such control logic are described further below with regard to . Furthermore, such an approach can be useful during tip-out conditions in still other situations, other than utilizing full or partial cylinder fuel deactivation, and other than enabling/disabling alternative control modes. Specifically, it can also be used to adjust a requested engine torque during deceleration conditions in which other types of transitions may occur, such as transmission gear shifts. This is described in further detail below with regard to . Referring now to , a model based screening (via a torque converter model, for example) for whether to enable (full or partial) fuel shut off operation to avoid excessive engine speed drop is described. First, in step 1810, the routine determines whether the torque converter is in the locked or partially locked condition. The partially locked condition can be encountered when the lock up clutch is being applied across the torque converter, yet has not fully coupled the torque converter input and output. In one example, the determination of step 1810 is based upon whether the slip ratio between the input torque converter speed and the output torque converter speed is approximately one. When the answer to step 1810 is yes, the routine continues to step 1822, as discussed in further detail below. When the answer to step 1810 is no, the routine continues to step 1812. In step 1812, the routine calculates the minimum allowed engine speed during a deceleration condition. In one example, deceleration condition is indicated by a driver tipout of the accelerator pedal (i.e., an accelerator pedal position less than a threshold value). The minimum allowed engine speed calculated in step 1812 can be based on a variety of operating conditions, or selected to be a single value. When the minimum allowed engine speed is dependent upon operating conditions, it can be calculated based on conditions such as, for example: vehicle speed, engine temperature, and exhaust gas temperature. Continuing with , in step 1814, the routine predicts a turbine speed at a future interval using vehicle deceleration rate. This prediction can be preformed utilizing a simple first order rate of change model where the current turbine speed, and current rate of change, are used to project a turbine speed at a future instant based on a differential in time. Next, in step 1816, the routine calculates a minimum engine torque required to achieve the calculated minimum allowed engine speed with the predicted turbine speed. Specifically, the routine uses a model of the torque converter to calculate the minimum amount of engine torque that would be necessary to maintain the engine speed at the minimum allowed speed taking into account the predicted turbine speed. The details of this calculation are described below with regard to . Next, in step 1818, the routine calculates the maximum engine brake torque available to be produced in a potential new control mode that is being considered to be used. For example, if the potential new control mode utilizes cylinder cut operation, this calculation takes into account that some or all of the cylinders may not be producing positive engine torque. Alternatively, if the new control mode includes lean operation, then again the routine calculates the maximum engine brake torque available taking into account the minimum available lean air fuel ratio. Make a note that regarding step 1818, the first example is described in more detail below with regard to . Next, in step 1820, the routine determines whether the calculated maximum engine brake torque in the potential new control mode is greater than the engine torque required to achieve, or maintain, the minimum allowed engine speed. If the answer to step 1820 is yes, the routine continues to step 1822 to enable the new control mode based on this engine speed criteria. Alternatively, when the answer to step 1820 is no, the routine continues to step 1824 to disable the transition to the new control mode based on this engine speed criteria. In this way, it is possible to enable or disable alternative control modes taking into account their effect on maintaining a minimum acceptable engine speed during the deceleration condition, and thereby reduce engine stalls. Make a note before the description of step 1810 that the routine to may be preformed during tipout deceleration conditions. Referring now to , the routine of has been modified to specifically apply to the cylinder fuel cut operating scenario. Steps 1910-1916 are similar to those described in steps 1810-1816. From step 1916, the routine continues to step 1918 where the routine calculates the engine brake torque that will result from turning off fuel at the minimum engine speed. Specifically, the routine calculates the engine brake torque that will be produced after turning fuel injection off to part or all of the cylinders. Further, this calculation of brake torque is preformed at the minimum engine speed. Then, in stop 1920, the routine determines whether this resulting engine torque at the minimum engine speed during fuel cut operation is greater then the engine torque required to achieve, or maintain, the minimum allowed engine speed. If so, then the engine torque is sufficient in the fuel cut operation, and therefore the fuel cut operation is enabled based on this engine speed criteria in step 1922. Alternatively, when the answer to step 1920 is no, then the engine torque that can be produced in the full or partial fuel cut operation at the minimum engine speed is insufficient to maintain the minimum engine speed, and therefore the fuel shut-off mode is disable based on this engine speed criteria. In this way, it is possible to selectively enable/disable full and/or partial fuel deactivation to the cylinders in a way that maintains engine speed at a minimum allowed engine speed. In this way, engine stalls can be reduced. Note that in this way, at least under some conditions, it is possible to enable (or continue to perform) fuel deactivation to at least one cylinder at a lower engine speed when the torque converter is locked than when the torque converter is unlocked. Thus, fuel economy can be improved under some conditions, without increasing occurrence of engine stalls. Referring now to , a routine is described for clipping a desired engine torque request to maintain engine speed at or above a minimum allowed engine speed during vehicle tip-out conditions utilizing torque converter characteristics. In this way, it is possible to reduce dips in engine speed that may reduce customer feel. For example, in calibrating a requested impeller torque as a function of vehicle speed for one or more of the engine braking modes, it is desirable to select torque values that give good engine braking feel and are robust in the variety of operating conditions. However, this can be difficult since a variety of factors affect engine braking, and such variations can affect the resulting engine speed. Specifically, it can be desirable to produce less than the required torque to idle under deceleration conditions to provide a desired deceleration trajectory. However, at the same time, engine speed should be maintained above a minimum allowed engine speed to reduce stall. In other words, one way to improve the system efficiency (and reduce run-on feel) under deceleration conditions is to produce less engine torque than needed to idle the engine. Yet at the same time, engine speed drops should be reduced that let engine speed fall below a minimum allowed value. In one example, for vehicles with torque converters, a model of the open torque converter can be used to determine the engine torque that would correspond to a given engine speed (target speed or limit speed), and thus used to allow lower engine torques during deceleration, yet maintain engine speed above a minimum value. In this case, if there is a minimum allowed engine speed during deceleration, the controller can calculate the engine torque required to achieve at least that minimum engine speed based on turbine speed. The routine below uses two 2-dimensional functions (fn_conv_cpc and fn_conv_tr) to approximate the K-factor and torque ratio across the torque converter as a function of speed ratio. This approximation includes coasting operation where the turbine is driving the impeller. In an alternative approach, more advanced approximations can be used to provide increased accuracy, if necessary. Note that it is known to use a model of the open torque converter to determine the engine torque that would correspond to a given engine speed in shift scheduling for preventing powertrain hunting. I.e., it is known to forecast the engine speed (and torque converter output speed) after a shift to determine whether the engine can produce enough torque to maintain tractive effort after an upshift (or downshift) in the future conditions. Thus, during normal driving, it is known to screen shift requests to reduce or prevent less than equal horsepower shifts (including a reserve requirement factor), except for accelerations. Further, it is known to include cases where the torque converter is locked, and to include calculations of maximum available engine torque. Referring now to , a routine is described for calculating the engine brake torque required to spin the engine at a specified engine speed and turbine speed. First, in step 2010, temporary parameters are initialized. Specifically, the following 32-bit variables are set to zero: tq_imp_ft_lbf_tmp (temporary value of impeller torque in lbf), tq_imp_Nm_tmp (temporary value of impeller torque in Nm), cpc_tmp (temporary value of K-factor), and tr_tmp (temporary value of torque ratio). Further, the temporary value of the speed ratio (speed_ratio_tmp)=is calculated as a ratio of the temporary turbine speed (nt_tmp) and the temporary engine speed (ne_tmp), clipped to 1 to reduce noise in the signals. Then, in step 2012, the routine calculates the temporary K-factor (cpc_tmp) as a function of the speed ratio and converter characteristics stored in memory using a look-up function, for example. Then, in step 2014, a determination is made as to whether the speed ratio (e.g., speed ratio_tmp>1.0 ?). If so, this signifies that the vehicle is coasting, and positive engine torque is not being transmitted through the torque converter. When the answer to step 2014 is Yes, the routine continues to step 2016. In step 2016, the routine uses a K-factor equation that uses turbine speed and torque as inputs. Specifically, the impeller torque is calculated from the following equations: \n\n/max((), 10000.0) \n\n(); \n\n\n\n Otherwise, when the answer to step 2014 is No, then the K-factor equation uses engine speed and torque as inputs, and the routine continues to step 2018. In step 2018, the impeller torque is calculated from the following equations: \n\n/max((), 10000.0) \n Then, these can be converted to NM units, and losses included, via the following equation in step 2020. \n\n1.3558\n In this way, it is possible to calculate a required torque (tq_imp_Nm_tmp) to maintain engine speed as desired. Example operation is illustrated in . Specifically, demonstrates the performance of this torque request clipping/screening during vehicle testing. At approximately 105.5 seconds the accelerator pedal is released and the torque based deceleration state machine enters hold small positive mode (where a small positive torque is maintained on the drivetrain) followed by an open loop braking mode, where negative engine torque is provided in an open-loop fashion. Soon after the tip-out, the transmission controls command a 3-4 up-shift which will lower the turbine speed below the minimum engine speed target of \u02dc850 rpm in this example, placing a torque load on the engine. This transmission up-shift may result in more engine torque being required to hold 850 rpm engine speed and tqe_decel_req_min (the lower clip applied to the tqe_decel_req value) therefore jumps to 42 Nm to reflect the higher torque request. The value of tqe_decel_req_min is calculated based on the torque converter model described above. By keeping the deceleration torque request from dropping too low, the engine speed behaves as desired. Referring now to , a method for managing the cycle averaged torque during transitions between different cylinder cut-out modes is described. Specifically, such an approach may provide improved torque control during these transitions. Before describing the control routine in detail, the following description and graphs illustrate an example situation in which it is possible to better control cycle averaged torque during the transition (note that this is just one example situation in which the method can be used). These graphs use the example of an eight cylinder engine where the cylinders on the engine are numbered in firing order. When the system transitions from firing 1, 3, 5, 7 to 2, 4, 6, 8, for example, two cylinders may fire in succession. If the torque produced by all the cylinders during the transition is substantially the same, the cycle-average torque produced during the transition may be higher than desired, even though no one cylinder produces substantially more or less torque, and over a cycle, the same number of cylinders is still being fired. In other words, there is a single, effective shift of half of the cylinders firing earlier in the overall engine cycle. This torque disturbance may also result in an engine speed disturbance if occurring during idle speed control conditions. The following figures illustrate an example of this torque disturbance. Note that the following description illustrates a simplified example, and is not meant to define operation of the system. shows the crankshaft torque for an 8 cylinder engine with all cylinders firing, where the crankshaft torque resulting from the sum of the power strokes on the engine are modeled as simple sine waves. For the example where four cylinders are operated to produce the same net torque as all 8 in , then the torque production of each cylinder would double as shown in . If this same level of torque was produced by the firing cylinders in 4 cylinder mode but the system transitioned from firing 1-3-5-7 to 2-4-6-8 with the last cylinder fired before the transition being 3 and the first cylinder fired after the transition being 4, then crankshaft torque would be as illustrated in . As shown in , the summing of the torques from cylinders 3 and 4 may produce a torque increase during this transition point and an increase in the average torque over an engine cycle. The increase could be as much as 12.5% for an 8 cylinder engine, or 16.7% for a 6 cylinder engine due to this overlapping torque addition effect. By recognizing this behavior, the control system can be redesigned to reduce the torque produced by the off-going cylinder (3 in this example) and the on-coming cylinder (4 in this example) such that the average torque over a cycle is not increased during a transition. For an 8 cylinder engine, if the torque produced by cylinders 3 and 4 were reduced by approximately 25% each, then the torque profile would resemble , with the cycle average torque approximately matching the steady 4 or 8 cylinder operation. In this way, it is possible to improve torque control when transitioning between operating in a first mode with the first group combusting inducted air and injected fuel and the second group operating with inducted air and substantially no injected fuel, and operation in a second mode with the second group combusting inducted air and injected fuel and the first group operating with inducted air and substantially no injected fuel. As indicated in the example, above, before the transition, engine torque of a last to be combusted cylinder in the first group is reduced compared with a previously combusted cylinder in that group. Further, after the transition, engine torque of a first to be combusted cylinder in the second group is reduced compared with a next combusted cylinder in that group. The reduction of one or both of the cylinder can be accomplished in a variety of ways, such as, for example: ignition timing retard, or enleanment of the combusted air and fuel mixture. Further, using electric valve actuation, variable valve lift, an electronic throttle valve, etc., the reduction could be performed by reducing air charge in the cylinders. In an alternative embodiment, it may be possible to provide improve torque control during the transition by reducing torque of only one of the last to be fired cylinder in the first group and the first to be fired cylinder in the second group. Further, it may be possible to provide improve torque control during the transition by providing unequal torque reduction in both the last to be fired cylinder in the first group and the first to be fired cylinder in the second group. For example, the torque reduction for the last cylinder of the old firing order (in the example discussed above, cylinder 3) and the first cylinder of the new firing order (cylinder 4) could be implemented in any way such that the total indicated torque produced by these two cylinders was reduced by approximately 25%. For example, if the torque reduction of the last cylinder in the firing order is X * 50% and the reduction of the first cylinder in the new firing order is (1\u2212X)* 50%, average torque could be maintained. For the example reduction of 25% each, X=0.5. If all the torque were reduced on the last old firing order cylinder (X=1), the results would be similar to those shown in . Alternatively, if all the torque reduction was accomplished with the first cylinder of the new firing order (X=0), then the results would be similar to those shown in . These are just two example, and X could be selected anywhere between 0 and 1. Referring now to , an approach to reduce engine NVH during mode transitions between full cylinder operation and partial cylinder operation (between full cylinder operation and split ignition timing operation). shows the frequency content of the engine at 600 RPM with all cylinders firing at stoichiometry and optimal ignition timing. The figure shows a dominant peak at firing frequency of all cylinders firing (FF). This can be compared with , which shows the frequency content of the engine at 600 RPM operating in cylinder cut out mode (e.g., fuel to one bank of a V-6 deactivated, or fuel to two cylinders on each bank of a V-8 deactivated), or operating with split ignition timing between groups of cylinders. This shows a dominant peak at \xbd FF, and a smaller peak at firing frequency due to compression of all cylinders, since deactivated cylinders still pump air. And both can be compared with , which shows the frequency content of the engine at 600 RPM with all cylinders firing at a lean air-fuel ratio and/or with regarded ignition timing. shows a dominant peak at FF, but with a wider spread due to increased combustion variability due to lean, and/or retarded ignition timing. When abruptly transitioning between these modes, there may be a broad band excitation due to the change in fundamental frequency content of the engine torque. This may excite resonance frequencies of the vehicle, such as a vehicle's body resonance, as shown by . Therefore, in one example when such NVH concerns are present, the engine can be operated to gradually make the transition (e.g., by gradually reducing torque in combusting cylinders and gradually increasing torque in deactivated cylinders when enabling combustion in deactivated cylinders). For example, this can be performed via split airflow control between the cylinder groups. Alternative, enleanment and/or ignition timing retard can also be used. In this way, the frequency excitation of any vehicle frequencies may be reduced. In other words, ramping to and from different modes may allow jumping over body resonances so that injector cut-out (or split ignition timing) can operate at lower engine speeds (e.g., during idle) while reducing vibration that may be caused by crossing and excite a body resonance. This is discussed in more detail below with regard to . Specifically, shows the frequency content at a mid-point of a transition in which there are two smaller, broader peaks centered about FF and \xbd FF. In this example, the engine transitions from operating with split ignition timing to operating all cylinders with substantially the same ignition timing. For example, the controller reduces airflow, or retards ignition timing, or enleans, cylinders generating power, and advanced ignition timing of the cylinders with significant ignition timing retard. shows the frequency content near the end of the transition when all of the cylinders are carrying out combustion at substantially the same, retarded, ignition timing. Thus, by using ramping, it may be possible to operate at a lower idle rpm by reducing potential NVH consequence and gradually changing torque frequency content, rather than abruptly stepping to and from different modes with the resultant broad band excitation due to frequency impulses. Further, this may be preferable to an approach that changes engine speed through a resonance before making a transition, which may increase NVH associated with running at a body resonance frequency. Note that these figures show a single body resonance, however, there could also be drive line or mount resonances that vary with vehicle speed and gear ratio. Referring now to , an example control strategy is described for use with a system such as in , for example. This strategy could be used with any even fire V-type engine such as, for example: a V-6 engine, a V-10 engine, a V-12 engine, etc. Specifically, this strategy uses a stoichiometric injector cut-out operation where one group of cylinders is operated to induct air with substantially no fuel injection, and the remaining cylinders are operating to combust a near stoichiometric air-fuel mixture. In this case, such as in the example of , catalysts 222 and 224 can be three-way type catalysts. Also note that a third catalyst can be coupled further downstream in an underbody location, which can also be a three-way catalyst. In this way, it is possible to disable the cylinder group without an upstream three-way catalyst (e.g., group 250), while continuing to operate the other group (group 252) in a stoichiometric condition. In this way, catalyst 222 can effectively reduce exhaust emissions from group 252. Further, when both groups are combusting a stoichiometric mixture, both catalysts 222 and 224 (as well as any further downstream catalysts) can be used to effectively purify exhaust emissions. This exhaust system has a further advantage in that it is able to improve maintenance of catalyst temperatures even in the injector cut-out mode. Specifically, during cylinder fuel injection cut-out, catalyst 222 can convert emissions (e.g. HC, CO and NOx) in the stoichiometric exhaust gas mixture (which can oscillate about stoichiometry). The relatively cool air from bank 250 mixes with the hot stoichiometric exhaust gases before being fed to catalyst 224. However, this mixture is approximately the same temperature in the fuel injection cut-out mode as it would be in stoichiometric operation where both cylinders 250 and 252 carry out combustion. Specifically, when in the injector cut-out mode, the stoichiometric cylinder load is approximately twice the exhaust temperature in the mode of both groups carrying out combustion. This raises the exhaust temperature coming out of the cylinders in group 252 to nearly twice that of the cylinders carrying out combustion at an equivalent engine load. Thus, when excess air is added to the hotter exhaust gas in the cylinder cut-out mode, the overall temperature is high enough to keep catalysts 224 in a light-off mode. Therefore, when the engine exits the injector cut-out mode, both catalysts 222 and 224 are in a light-off mode and can be used to reduce emissions. If, however, the exhaust system design is such that in the injector cut-out mode catalyst 224 still cools below a desired catalyst temperature, then split ignition operation can be used when re-enabling combustion to both cylinder groups as described above with regard to . Specifically, when transitioning from operating with group 250 in the cylinder in the fuel cut mode, and group 252 operating about stoichiometry\u2014to operating both groups about stoichiometry, group 250 can be re-enabled with fuel injection to carry out combustion with a significantly retarded ignition timing. In this way, catalysts 224 can be rapidly heated due to the large amount of heat generated by group 250. Further, the significantly less retarded combustion of group 252 maintains the engine output smoothly about a desired value. As described above, the configuration of can provide significant advantages in the fuel cut mode, however, the inventors herein have recognized that during cold starting conditions, catalyst 224 reaches a light off temperature slower than catalyst 222 due to the further distance from cylinder Group 250 and being in the downstream position relative to catalyst 222. Therefore, in one example, it is possible to provide better catalyst light off operation during a start using the split ignition timing approach described above herein. This is described in further detail below with regard to . Referring now specifically to , a routine as described before regarding engine starting operation with an unequal exhaust path to the first catalyst such as in the system of , for example. First, in step 3410, the routine determines whether the exhaust configuration is one having unequal exhaust paths to a first catalyst. If the answer to step 3410 is \u201cyes\u201d, the routine continues to step 3412. In step 3412, the routine determines whether the current conditions are a \u201ccold engine start.\u201d This can be determined based on a time-sensitive last engine operation, engine coolant temperature and/or various other parameters. If the answer to step 3412 is \u201cyes\u201d, the routine continues to step 3414 to operate the engine in a crank mode. In the crank mode, the engine starter rotates the engine up to a speed at which it is possible to identify cylinder position. At this point, the engine provides for fuel injection to all the cylinders in a sequential mode, or in a \u201cbig bang\u201d mode. In other words, the routine sequentially provides fuel injection to each of the engine cylinders in the desired fire mode to start the engine. Alternatively, the routine fires off fuel injectors simultaneously to all the cylinders and sequentially fires the ignition into each cylinder in the firing order to start the engine. The routine then continues to step 3416 as the engine runs up to the desired idle speed. During the run-up mode, it is possible again to operate all of the cylinders to carry out combustion to run the engine up to a desired engine idle speed. At this point, the routine continues to step 3418, where the power-heat mode (e.g., split ignition timing) is used. In this mode, the cylinder group coupled to an upstream emission control device (e.g., Group 252) is operated with potentially a slightly lean air-fuel mixture, and slightly retarded ignition timing from maximum torque timing to maintain the cylinders at a desired engine speed. However, the other group (Group 250) is then operated with significant ignition timing retard to produce little engine torque output that provide significant amount of heat. While this combustion may be past the combustion stability limit, smooth engine operation can be maintained via the combustion in Group 252. The large amount of heat from Group 250 thereby quickly brings catalysts in the downstream position past a Y-pipe (e.g., catalyst 224) to a desired light-off temperature. In this way, both catalysts can be rapidly brought to a desired temperature, at which the engine can transition to operating both cylinder groups with substantially the same ignition timing. Note that in an alternative embodiment, the split ignition timing between the cylinder groups can be commenced during the run-up mode or even during engine cranking. It will be appreciated that the configurations and routines disclosed herein are exemplary in nature, and that these specific embodiments are not to be considered in a limiting sense, because numerous variations are possible. The subject matter of the present disclosure includes all novel and nonobvious combinations and subcombinations of the various system and exhaust configurations, fuel vapor purging estimate algorithms, and other features, functions, and/or properties disclosed herein. The following claims particularly point out certain combinations and subcombinations regarded as novel and nonobvious. These claims may refer to \u201can\u201d element or \u201ca first\u201d element or the equivalent thereof. Such claims should be understood to include incorporation of one or more such elements, neither requiring nor excluding two or more such elements. Other combinations and subcombinations of the disclosed features, functions, elements, and/or properties may be claimed through amendment of the present claims or through presentation of new claims in this or a related application. Such claims, whether broader, narrower, equal, or different in scope to the original claims, also are regarded as included within the subject matter of the present disclosure. "]






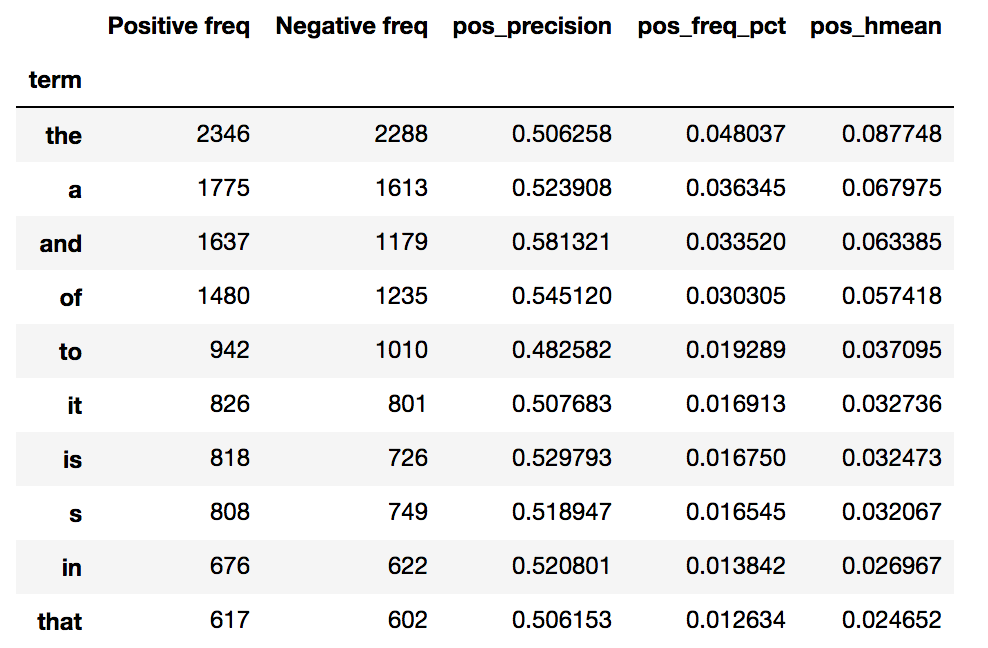


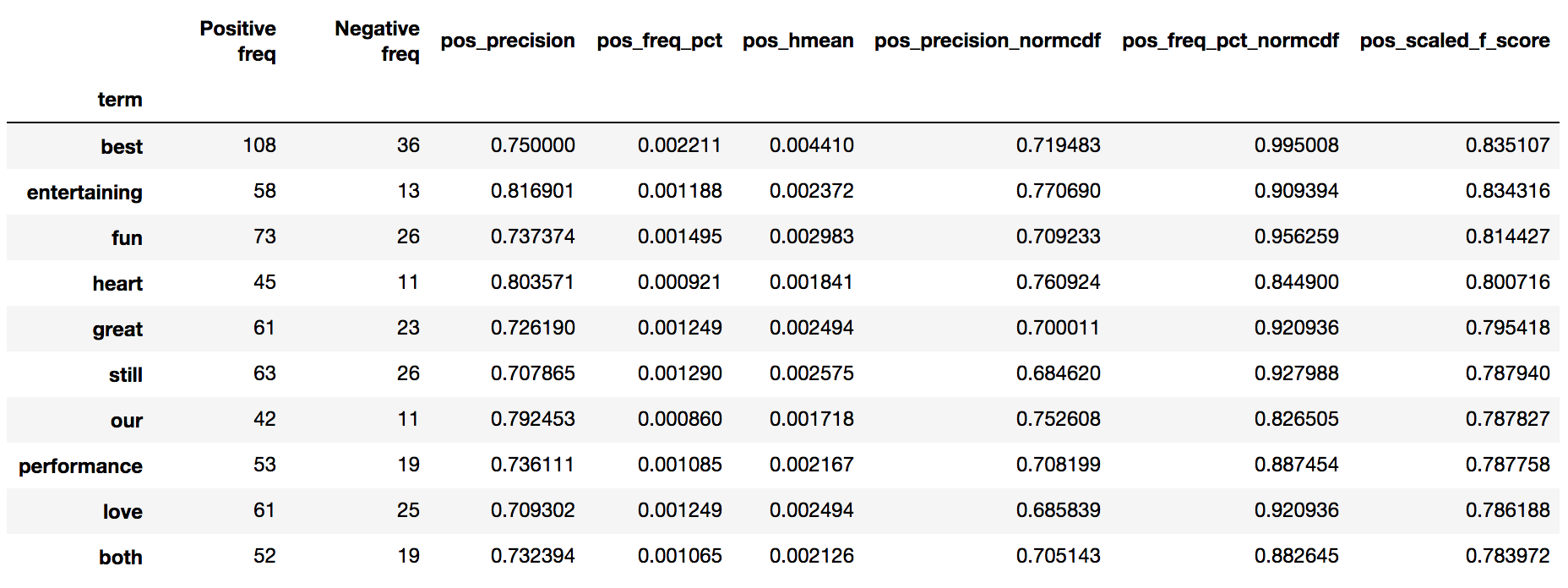
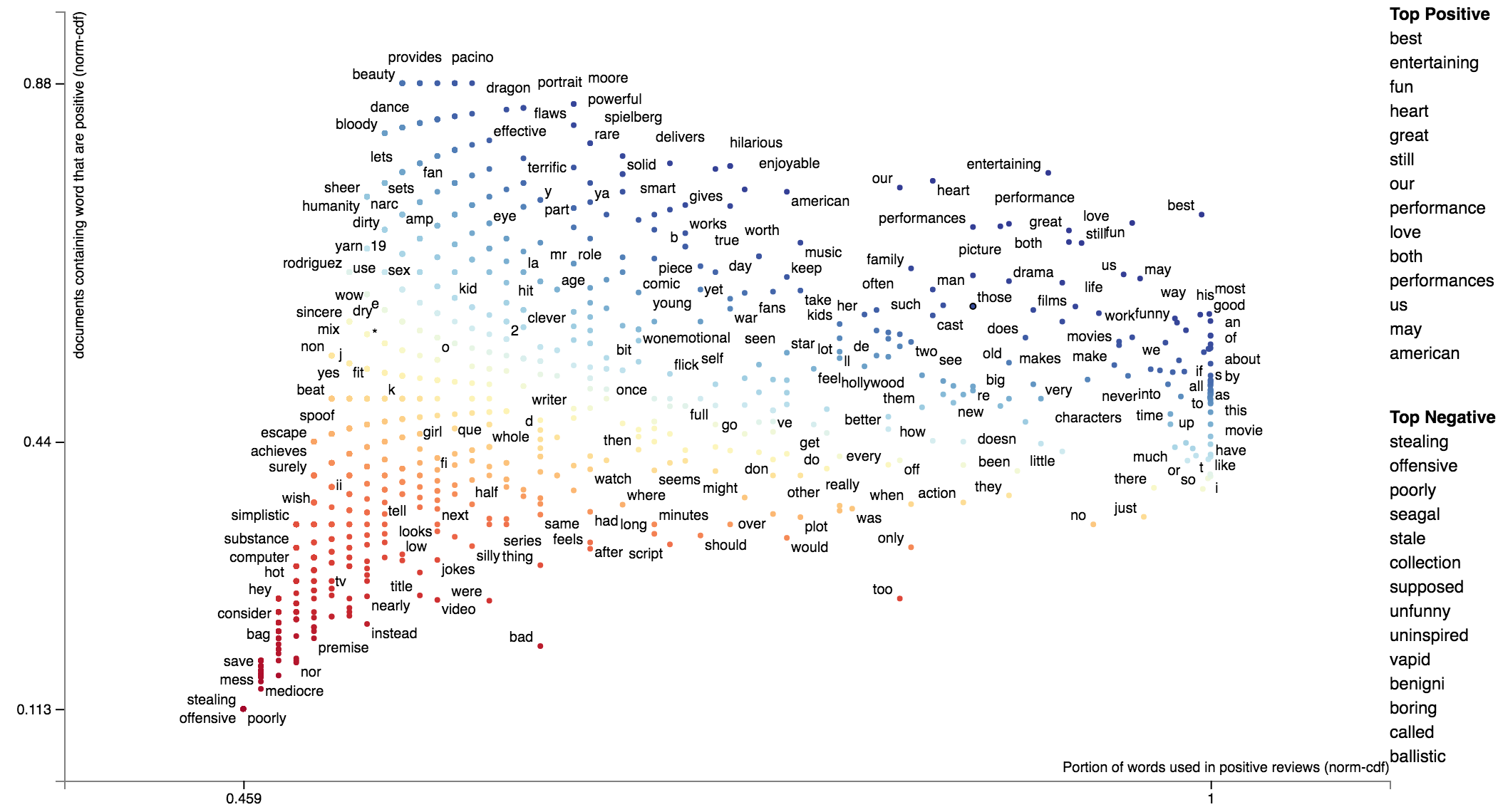

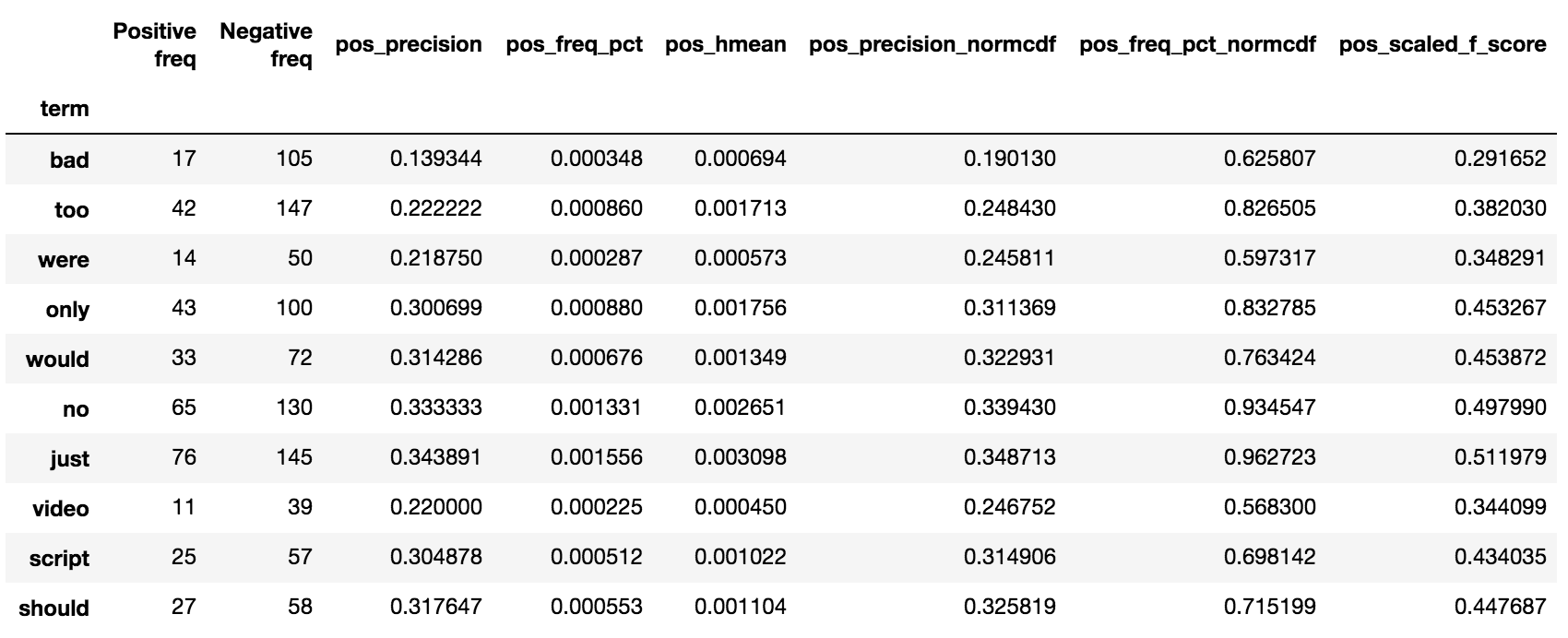
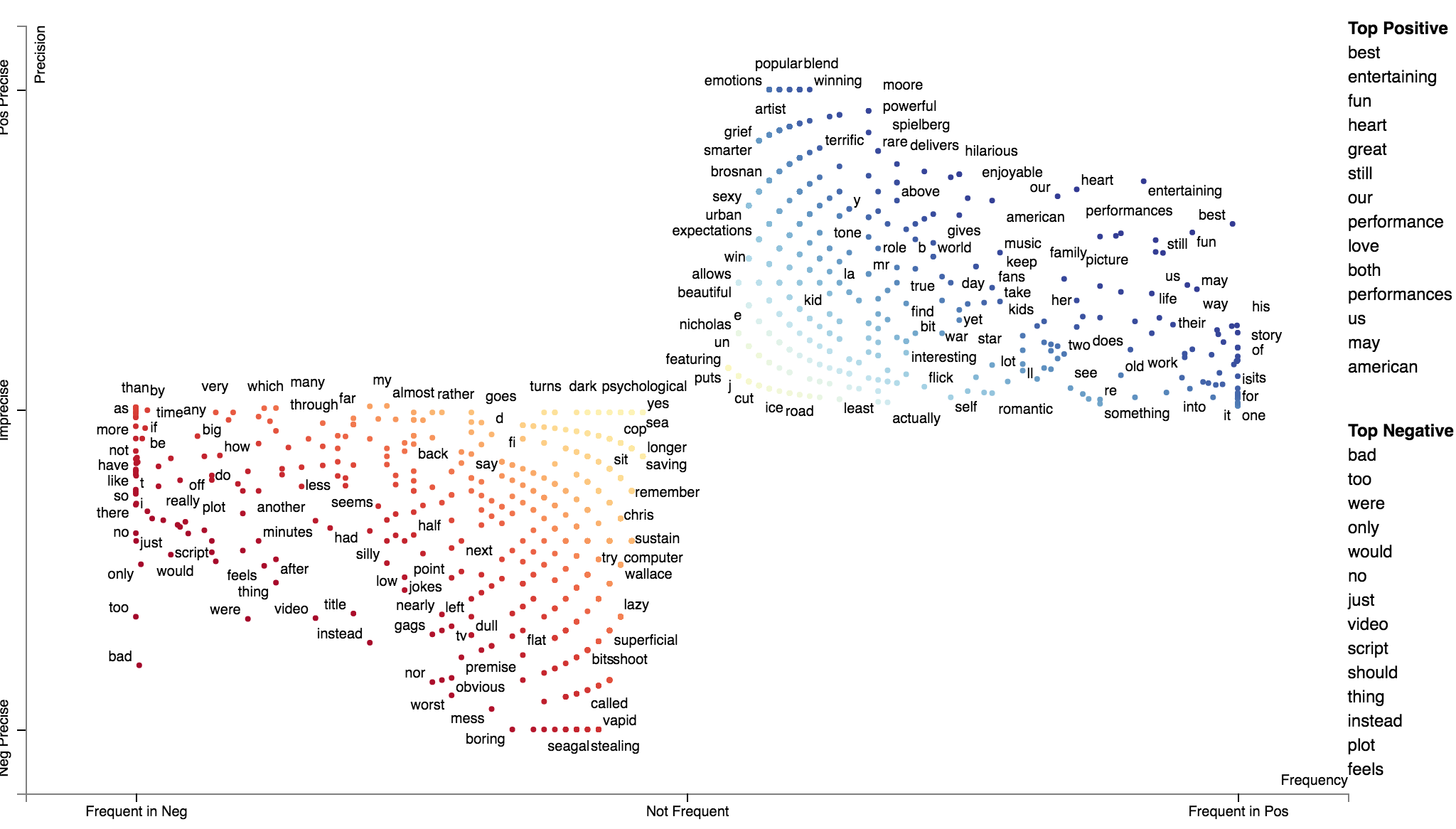
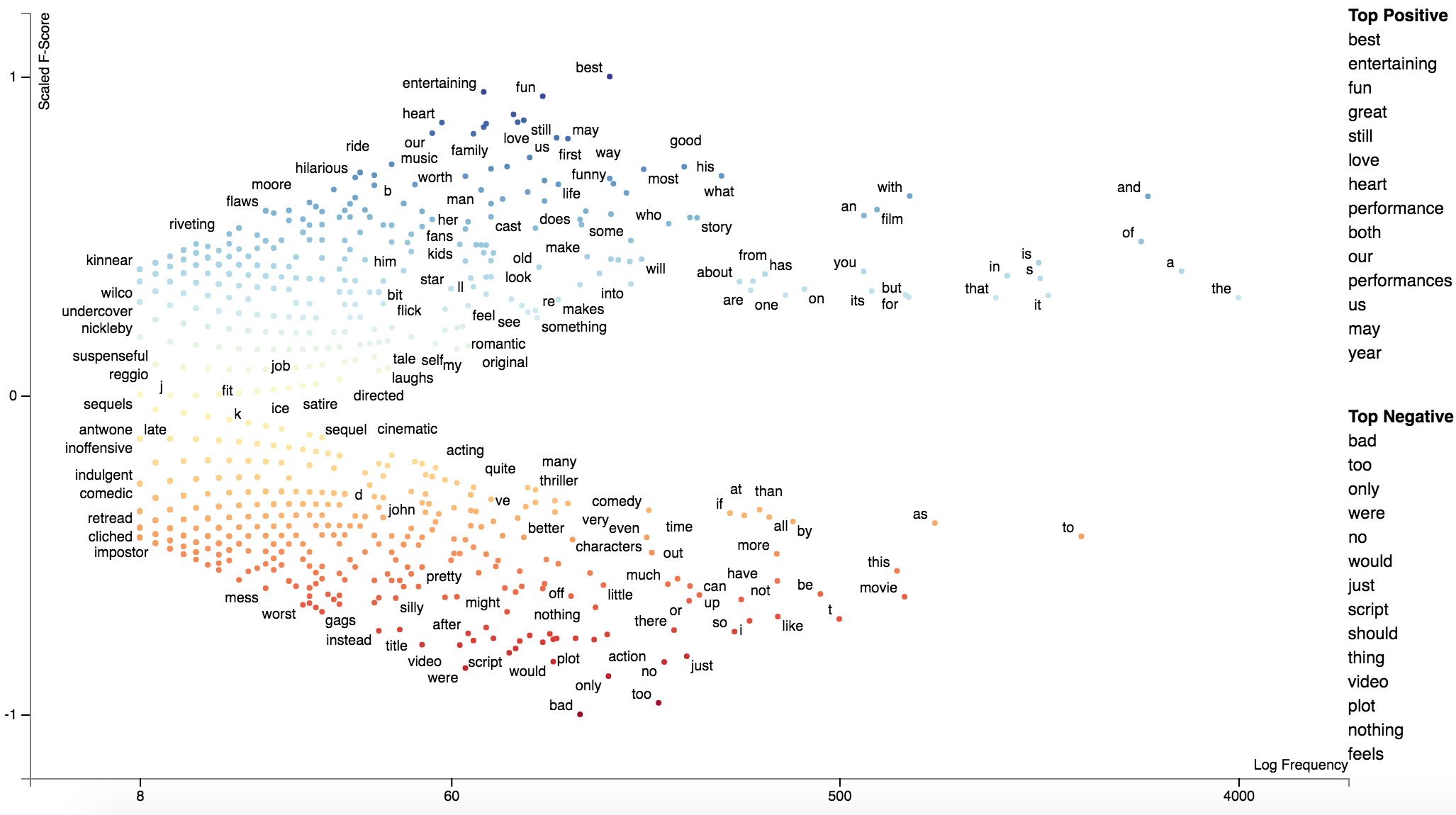


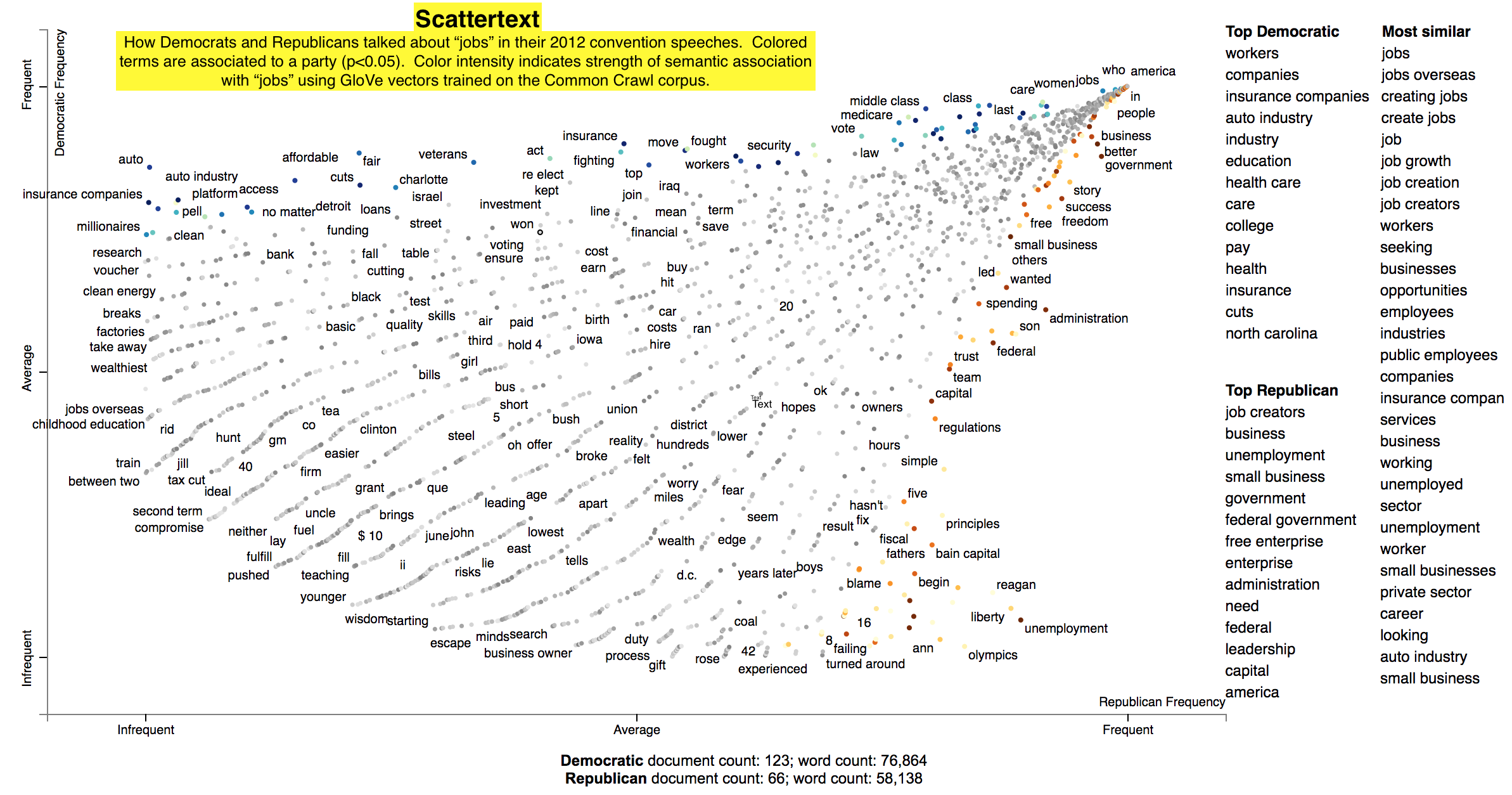















 2.3k Jan 01, 2023
2.3k Jan 01, 2023
 49 Dec 17, 2022
49 Dec 17, 2022
 21 Dec 29, 2022
21 Dec 29, 2022
 1 Jan 13, 2022
1 Jan 13, 2022
 50 Nov 08, 2022
50 Nov 08, 2022
 298 Nov 21, 2022
298 Nov 21, 2022
 7 Dec 05, 2022
7 Dec 05, 2022
 35 Dec 12, 2022
35 Dec 12, 2022
 33 Dec 18, 2022
33 Dec 18, 2022
 103 Dec 23, 2022
103 Dec 23, 2022
 345 Jan 03, 2023
345 Jan 03, 2023
 53 Dec 20, 2022
53 Dec 20, 2022
 7 Mar 12, 2022
7 Mar 12, 2022
 4 Feb 18, 2022
4 Feb 18, 2022
 1.3k Dec 26, 2022
1.3k Dec 26, 2022
 11 Mar 28, 2022
11 Mar 28, 2022
 52 Nov 10, 2022
52 Nov 10, 2022
 2 Oct 19, 2021
2 Oct 19, 2021
 9 Dec 28, 2021
9 Dec 28, 2021
 134 Dec 16, 2022
134 Dec 16, 2022