A ConvNet for the 2020s
Official PyTorch implementation of ConvNeXt, from the following paper:
A ConvNet for the 2020s. arXiv 2022.
Zhuang Liu, Hanzi Mao, Chao-Yuan Wu, Christoph Feichtenhofer, Trevor Darrell and Saining Xie
Facebook AI Research, UC Berkeley
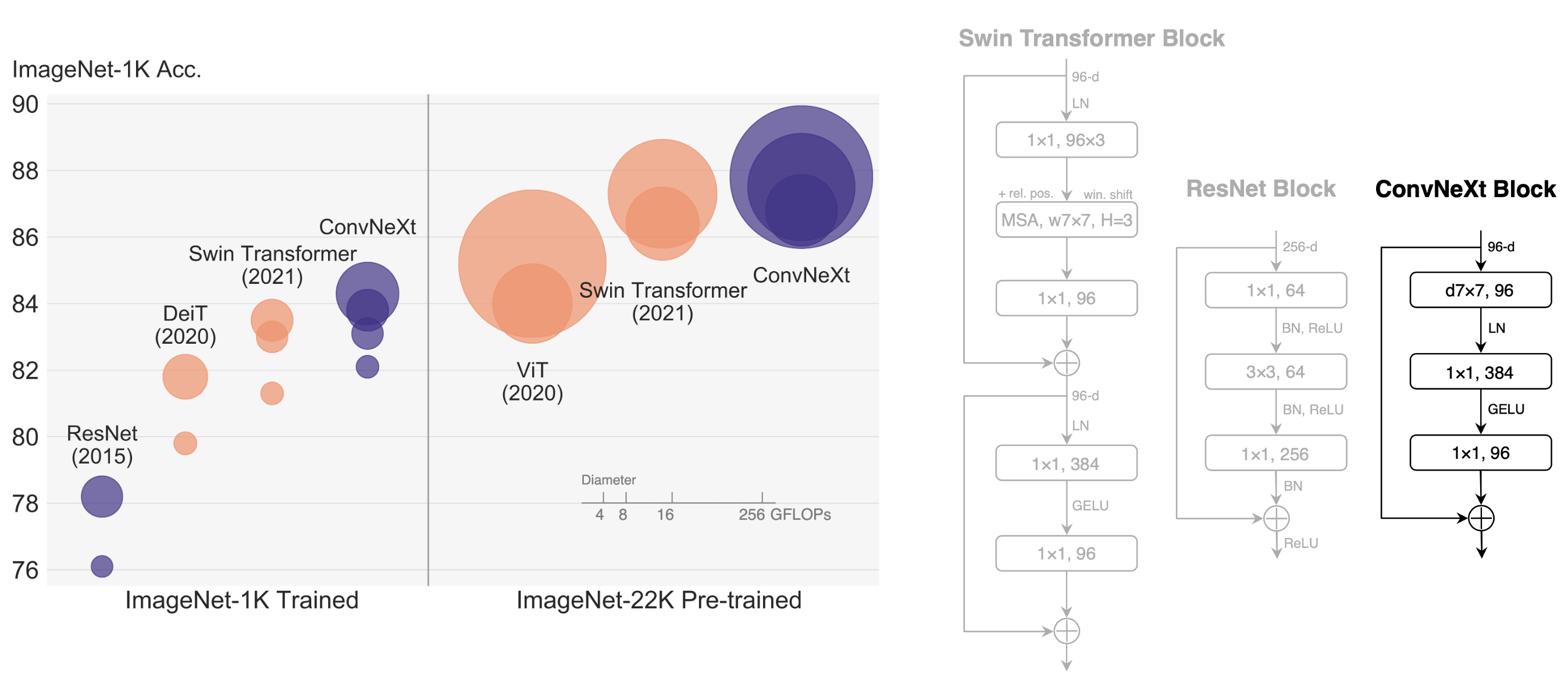
We propose ConvNeXt, a pure ConvNet model constructed entirely from standard ConvNet modules. ConvNeXt is accurate, efficient, scalable and very simple in design.
Catalog
- ImageNet-1K Training Code
- ImageNet-22K Pre-training Code
- ImageNet-1K Fine-tuning Code
- Downstream Transfer (Detection, Segmentation) Code
Results and Pre-trained Models
ImageNet-1K trained models
| name | resolution | [email protected] | #params | FLOPs | model |
|---|---|---|---|---|---|
| ConvNeXt-T | 224x224 | 82.1 | 28M | 4.5G | model |
| ConvNeXt-S | 224x224 | 83.1 | 50M | 8.7G | model |
| ConvNeXt-B | 224x224 | 83.8 | 89M | 15.4G | model |
| ConvNeXt-B | 384x384 | 85.1 | 89M | 45.0G | model |
| ConvNeXt-L | 224x224 | 84.3 | 198M | 34.4G | model |
| ConvNeXt-L | 384x384 | 85.5 | 198M | 101.0G | model |
ImageNet-22K trained models
| name | resolution | [email protected] | #params | FLOPs | 22k model | 1k model |
|---|---|---|---|---|---|---|
| ConvNeXt-B | 224x224 | 85.8 | 89M | 15.4G | model | model |
| ConvNeXt-B | 384x384 | 86.8 | 89M | 47.0G | - | model |
| ConvNeXt-L | 224x224 | 86.6 | 198M | 34.4G | model | model |
| ConvNeXt-L | 384x384 | 87.5 | 198M | 101.0G | - | model |
| ConvNeXt-XL | 224x224 | 87.0 | 350M | 60.9G | model | model |
| ConvNeXt-XL | 384x384 | 87.8 | 350M | 179.0G | - | model |
ImageNet-1K trained models (isotropic)
| name | resolution | [email protected] | #params | FLOPs | model |
|---|---|---|---|---|---|
| ConvNeXt-S | 224x224 | 78.7 | 22M | 4.3G | model |
| ConvNeXt-B | 224x224 | 82.0 | 87M | 16.9G | model |
| ConvNeXt-L | 224x224 | 82.6 | 306M | 59.7G | model |
Installation
Please check INSTALL.md for installation instructions.
Evaluation
We give an example evaluation command for a ImageNet-22K pre-trained, then ImageNet-1K fine-tuned ConvNeXt-B:
Single-GPU
python main.py --model convnext_base --eval true \
--resume https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_224.pth \
--input_size 224 --drop_path 0.2 \
--data_path /path/to/imagenet-1k
Multi-GPU
python -m torch.distributed.launch --nproc_per_node=8 main.py \
--model convnext_base --eval true \
--resume https://dl.fbaipublicfiles.com/convnext/convnext_base_22k_1k_224.pth \
--input_size 224 --drop_path 0.2 \
--data_path /path/to/imagenet-1k
This should give
* [email protected] 85.820 [email protected] 97.868 loss 0.563
- For evaluating other model variants, change
--model,--resume,--input_sizeaccordingly. You can get the url to pre-trained models from the tables above. - Setting model-specific
--drop_pathis not strictly required in evaluation, as theDropPathmodule in timm behaves the same during evaluation; but it is required in training. See TRAINING.md or our paper for the values used for different models.
Training
See TRAINING.md for training and fine-tuning instructions.
Acknowledgement
This repository is built using the timm library, DeiT and BEiT repositories.
License
This project is released under the MIT license. Please see the LICENSE file for more information.
Citation
If you find this repository helpful, please consider citing:
@Article{liu2021convnet,
author = {Zhuang Liu and Hanzi Mao and Chao-Yuan Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie},
title = {A ConvNet for the 2020s},
journal = {arXiv preprint arXiv:2201.03545},
year = {2022},
}

 1.8k Jan 07, 2023
1.8k Jan 07, 2023
 121 Dec 24, 2022
121 Dec 24, 2022
 0 Oct 13, 2021
0 Oct 13, 2021
 176 Dec 19, 2022
176 Dec 19, 2022
 1 Mar 08, 2022
1 Mar 08, 2022
 24 Dec 12, 2022
24 Dec 12, 2022
 401 Dec 30, 2022
401 Dec 30, 2022
 24 Dec 13, 2022
24 Dec 13, 2022
 2.1k Jan 02, 2023
2.1k Jan 02, 2023
 189 Dec 26, 2022
189 Dec 26, 2022
 37 Oct 09, 2022
37 Oct 09, 2022
 56 Nov 01, 2022
56 Nov 01, 2022
 178 Dec 20, 2022
178 Dec 20, 2022
 124 Dec 20, 2022
124 Dec 20, 2022
 726 Dec 29, 2022
726 Dec 29, 2022
 9 Jun 30, 2022
9 Jun 30, 2022
 5.6k Jan 08, 2023
5.6k Jan 08, 2023
 442 Jan 04, 2023
442 Jan 04, 2023
 44 Nov 29, 2022
44 Nov 29, 2022
 144 Dec 24, 2022
144 Dec 24, 2022