EvoJAX: Hardware-Accelerated Neuroevolution
EvoJAX is a scalable, general purpose, hardware-accelerated neuroevolution toolkit. Built on top of the JAX library, this toolkit enables neuroevolution algorithms to work with neural networks running in parallel across multiple TPU/GPUs. EvoJAX achieves very high performance by implementing the evolution algorithm, neural network and task all in NumPy, which is compiled just-in-time to run on accelerators.
This repo also includes several extensible examples of EvoJAX for a wide range of tasks, including supervised learning, reinforcement learning and generative art, demonstrating how EvoJAX can run your evolution experiments within minutes on a single accelerator, compared to hours or days when using CPUs.
EvoJAX paper: https://arxiv.org/abs/2202.05008
Installation
EvoJAX is implemented in JAX which needs to be installed first.
Install JAX: Please first follow JAX's installation instruction with optional GPU/TPU backend support. In case JAX is not set up, EvoJAX installation will still try pulling a CPU-only version of JAX. Note that Colab runtimes come with JAX pre-installed.
Install EvoJAX:
# Install from PyPI.
pip install evojax
# Or, install from our GitHub repo.
pip install git+https://github.com/google/[email protected]
Code Overview
EvoJAX is a framework with three major components, which we expect the users to extend.
- Neuroevolution Algorithms All neuroevolution algorithms should implement the
evojax.algo.base.NEAlgorithminterface and reside inevojax/algo/. We currently provide PGPE, with more coming soon. - Policy Networks All neural networks should implement the
evojax.policy.base.PolicyNetworkinterface and be saved inevojax/policy/. In this repo, we give example implementations of the MLP, ConvNet, Seq2Seq and PermutationInvariant models. - Tasks All tasks should implement
evojax.task.base.VectorizedTaskand be inevojax/task/.
These components can be used either independently, or orchestrated by evojax.trainer and evojax.sim_mgr that manage the training pipeline. While they should be sufficient for the currently provided policies and tasks, we plan to extend their functionality in the future as the need arises.
Examples
As a quickstart, we provide non-trivial examples (scripts in examples/ and notebooks in examples/notebooks) to illustrate the usage of EvoJAX. We provide example commands to start the training process at the top of each script. These scripts and notebooks are run with TPUs and/or NVIDIA V100 GPU(s):
Supervised Learning Tasks
While one would obviously use gradient-descent for such tasks in practice, the point is to show that neuroevolution can also solve them to some degree of accuracy within a short amount of time, which will be useful when these models are adapted within a more complicated task where gradient-based approaches may not work.

- MNIST Classification - We show that EvoJAX trains a ConvNet policy to achieve >98% test accuracy within 5 min on a single GPU.
- Seq2Seq Learning - We demonstrate that EvoJAX is capable of learning a large network with hundreds of thousands parameters to accomplish a seq2seq task.
Classic Control Tasks
The purpose of including control tasks are two-fold: 1) Unlike supervised learning tasks, control tasks in EvoJAX have undetermined number of steps, we thus use these examples to demonstrate the efficiency of our task roll-out loops. 2) We wish to show the speed-up benefit of implementing tasks in JAX and illustrate how to implement one from scratch.

- Locomotion - Brax is a differentiable physics engine implemented in JAX. We wrap it as a task and train with EvoJAX on GPUs/TPUs. It takes EvoJAX tens of minutes to solve a locomotion task in Brax.
- Cart-Pole Swing Up - We illustrate how the classic control task can be implemented in JAX and be integrated into EvoJAX's pipeline for significant speed up training.
Novel Tasks
In this last category, we go beyond simple illustrations and show examples of novel tasks that are more practical and attractive to researchers in the genetic and evolutionary computation area, with the goal of helping them try out ideas in EvoJAX.
 |
 |
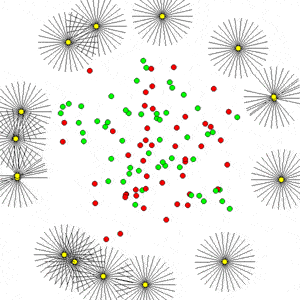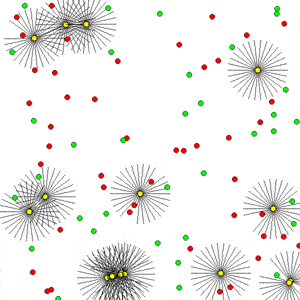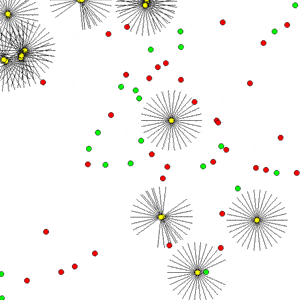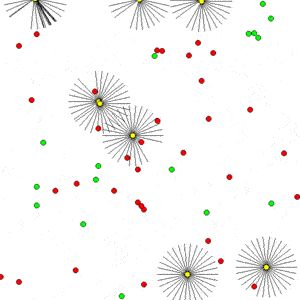
| Multi-agent WaterWorld | ES-CLIP: “A drawing of a cat” |
- WaterWorld - In this task, an agent tries to get as much food as possible while avoiding poisons. EvoJAX is able to learn the agent in tens of minutes on a single GPU. Moreover, we demonstrate that multi-agents training in EvoJAX is possible, which is beneficial for learning policies that can deal with environmental complexity and uncertainties.
- Abstract Paintings (notebook 1 and notebook 2) - We reproduce the results from this computational creativity work and show how the original work, whose implementation requires multiple CPUs and GPUs, could be accelerated on a single GPU efficiently using EvoJAX, which was not possible before. Moreover, with multiple GPUs/TPUs, EvoJAX can further speed up the mentioned work almost linearly. We also show that the modular design of EvoJAX allows its components to be used independently -- in this case it is possible to use only the ES algorithms from EvoJAX while leveraging one's own training loops and environment implantation.
Disclaimer
This is not an official Google product.





 I traced back the problem to line 110 in
I traced back the problem to line 110 in  But line 26 of FitnessShaper class from
But line 26 of FitnessShaper class from  How to get around this issue?
How to get around this issue?





 506 Dec 28, 2022
506 Dec 28, 2022
 59 Oct 13, 2022
59 Oct 13, 2022
 27 Jan 07, 2023
27 Jan 07, 2023
 9.3k Jan 02, 2023
9.3k Jan 02, 2023
 4.2k Jan 03, 2023
4.2k Jan 03, 2023
 2 Oct 26, 2022
2 Oct 26, 2022
 7 Nov 15, 2021
7 Nov 15, 2021
 109 Dec 28, 2022
109 Dec 28, 2022
 18 Aug 22, 2022
18 Aug 22, 2022
 40 Dec 14, 2022
40 Dec 14, 2022
 11 Sep 28, 2022
11 Sep 28, 2022
 83 Dec 30, 2022
83 Dec 30, 2022
 24 May 31, 2022
24 May 31, 2022
 1 Nov 02, 2021
1 Nov 02, 2021
 22.9k Jan 09, 2023
22.9k Jan 09, 2023
 25 Feb 17, 2021
25 Feb 17, 2021
 684 Dec 26, 2022
684 Dec 26, 2022
 187 Dec 26, 2022
187 Dec 26, 2022
 3.8k Jan 01, 2023
3.8k Jan 01, 2023
 121 Dec 25, 2022
121 Dec 25, 2022