30 Repositories
Latest Python Libraries
Simple and Distributed Machine Learning
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
 3.9k Dec 30, 2022
3.9k Dec 30, 2022

DeepAmandine is an artificial intelligence that allows you to talk to it for hours, you won't know the difference.
DeepAmandine This is an artificial intelligence based on GPT-3 that you can chat with, it is very nice and makes a lot of jokes. We wish you a good ex
 3 Apr 19, 2022
3 Apr 19, 2022
Serverless proxy for Spark cluster
Hydrosphere Mist Hydrosphere Mist is a serverless proxy for Spark cluster. Mist provides a new functional programming framework and deployment model f
 317 Dec 01, 2022
317 Dec 01, 2022
Fast Fourier Transform-accelerated Interpolation-based t-SNE (FIt-SNE)
FFT-accelerated Interpolation-based t-SNE (FIt-SNE) Introduction t-Stochastic Neighborhood Embedding (t-SNE) is a highly successful method for dimensi
 547 Dec 21, 2022
547 Dec 21, 2022
Apache Flink
Apache Flink Apache Flink is an open source stream processing framework with powerful stream- and batch-processing capabilities. Learn more about Flin
 20.4k Dec 30, 2022
20.4k Dec 30, 2022
Apache Liminal is an end-to-end platform for data engineers & scientists, allowing them to build, train and deploy machine learning models in a robust and agile way
Apache Liminals goal is to operationalise the machine learning process, allowing data scientists to quickly transition from a successful experiment to an automated pipeline of model training, validat
121 Dec 28, 2022
Apache Spark - A unified analytics engine for large-scale data processing
Apache Spark Spark is a unified analytics engine for large-scale data processing. It provides high-level APIs in Scala, Java, Python, and R, and an op
34.7k Jan 04, 2023

PySpark Cheat Sheet - learn PySpark and develop apps faster
This cheat sheet will help you learn PySpark and write PySpark apps faster. Everything in here is fully functional PySpark code you can run or adapt to your programs.
 168 Jan 01, 2023
168 Jan 01, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
 6.9k Jan 04, 2023
6.9k Jan 04, 2023
A fast, scalable, high performance Gradient Boosting on Decision Trees library, used for ranking, classification, regression and other machine learning tasks for Python, R, Java, C++. Supports computation on CPU and GPU.
Website | Documentation | Tutorials | Installation | Release Notes CatBoost is a machine learning method based on gradient boosting over decision tree
6.9k Jan 05, 2023
Proyecto - Análisis de texto de eventos históricos
Acceder al código desde Google Colab para poder ver de manera adecuada todas las visualizaciones y poder interactuar con ellas. Link de acceso: https:
 1 Jan 31, 2022
1 Jan 31, 2022
Functions for easily making publication-quality figures with matplotlib.
Data-viz utils 📈 Functions for data visualization in matplotlib 📚 API Can be installed using pip install dvu and then imported with import dvu. You
 16 Sep 15, 2022
16 Sep 15, 2022
The most widely used Python to C compiler
Welcome to Cython! Cython is a language that makes writing C extensions for Python as easy as Python itself. Cython is based on Pyrex, but supports mo
 7.6k Jan 03, 2023
7.6k Jan 03, 2023
Koalas: pandas API on Apache Spark
pandas API on Apache Spark Explore Koalas docs » Live notebook · Issues · Mailing list Help Thirsty Koalas Devastated by Recent Fires The Koalas proje
 3.2k Jan 04, 2023
3.2k Jan 04, 2023

Delta Sharing: An Open Protocol for Secure Data Sharing
Delta Sharing: An Open Protocol for Secure Data Sharing Delta Sharing is an open protocol for secure real-time exchange of large datasets, which enabl
 497 Jan 02, 2023
497 Jan 02, 2023
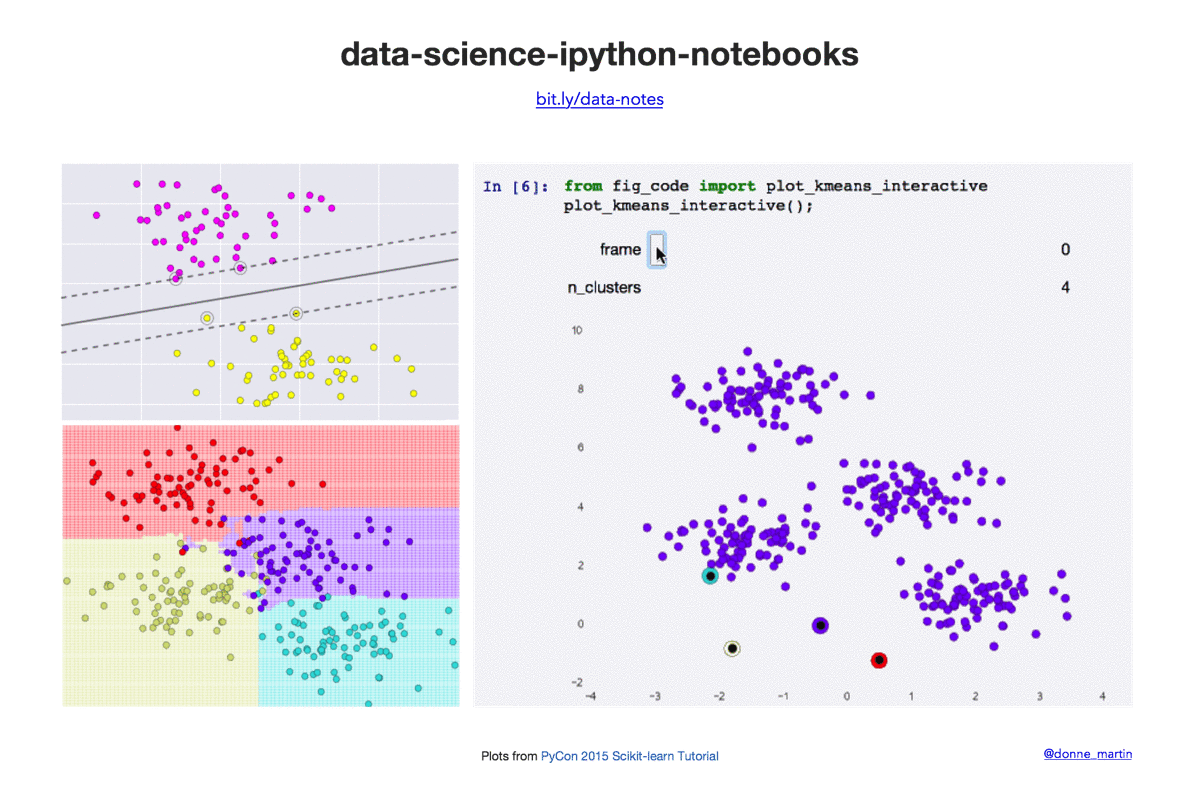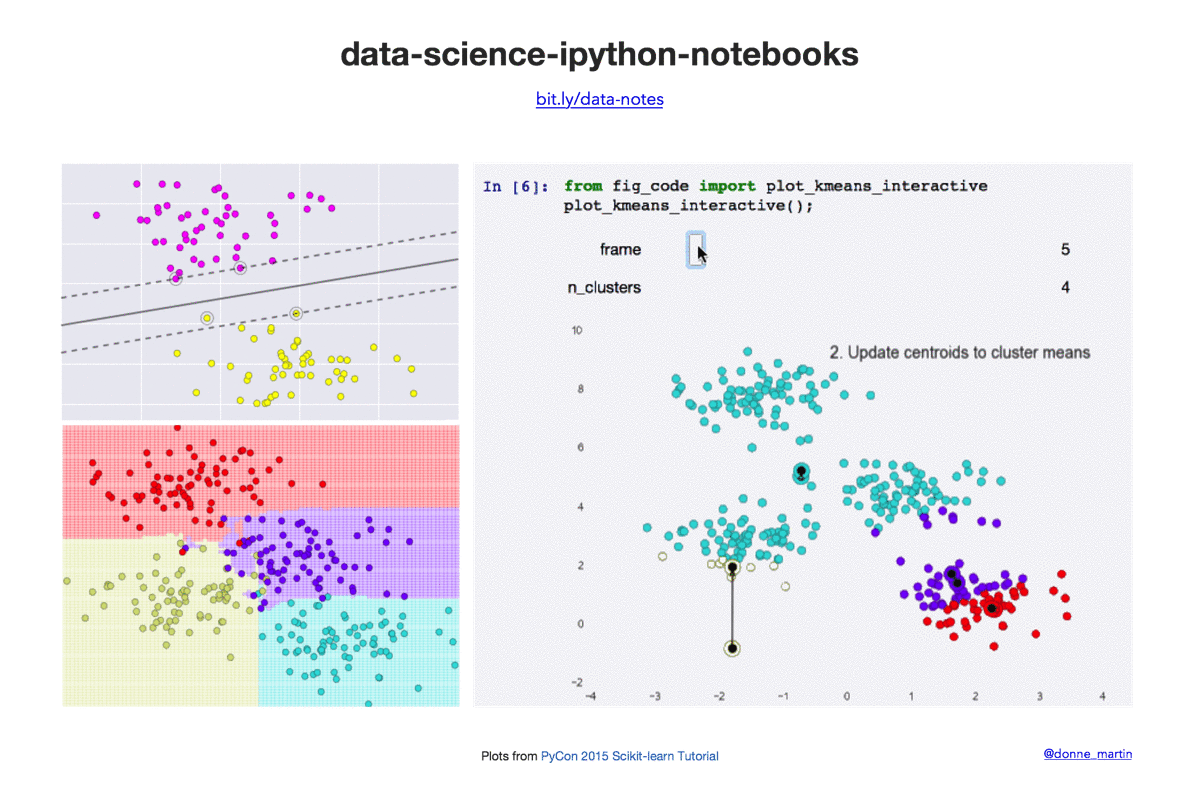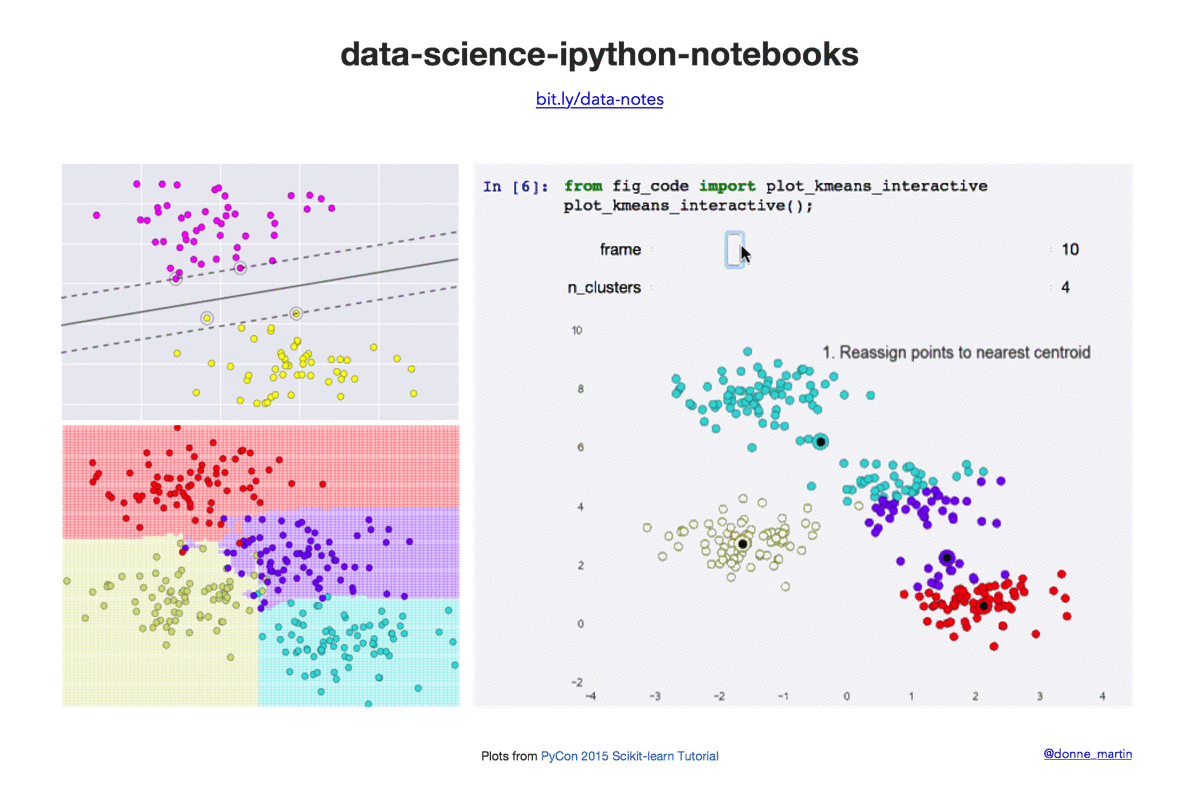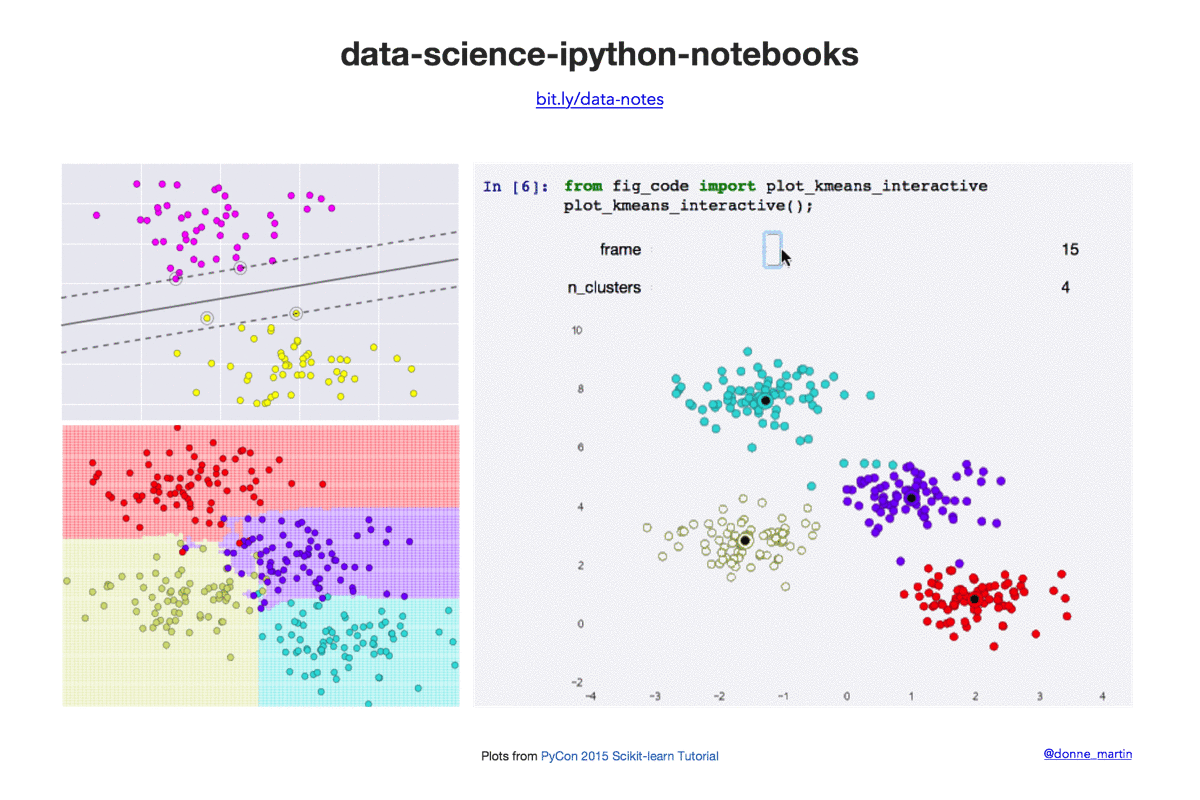
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, AWS, and various command lines.
Data science Python notebooks: Deep learning (TensorFlow, Theano, Caffe, Keras), scikit-learn, Kaggle, big data (Spark, Hadoop MapReduce, HDFS), matplotlib, pandas, NumPy, SciPy, Python essentials, A
 24.5k Jan 09, 2023
24.5k Jan 09, 2023
Eland is a Python Elasticsearch client for exploring and analyzing data in Elasticsearch with a familiar Pandas-compatible API.
Python Client and Toolkit for DataFrames, Big Data, Machine Learning and ETL in Elasticsearch
 463 Dec 30, 2022
463 Dec 30, 2022
Feature Store for Machine Learning
Overview Feast is an open source feature store for machine learning. Feast is the fastest path to productionizing analytic data for model training and
 3.8k Dec 30, 2022
3.8k Dec 30, 2022
H2O is an Open Source, Distributed, Fast & Scalable Machine Learning Platform: Deep Learning, Gradient Boosting (GBM) & XGBoost, Random Forest, Generalized Linear Modeling (GLM with Elastic Net), K-Means, PCA, Generalized Additive Models (GAM), RuleFit, Support Vector Machine (SVM), Stacked Ensembles, Automatic Machine Learning (AutoML), etc.
H2O H2O is an in-memory platform for distributed, scalable machine learning. H2O uses familiar interfaces like R, Python, Scala, Java, JSON and the Fl
 6.1k Jan 05, 2023
6.1k Jan 05, 2023
BigDL: Distributed Deep Learning Framework for Apache Spark
BigDL: Distributed Deep Learning on Apache Spark What is BigDL? BigDL is a distributed deep learning library for Apache Spark; with BigDL, users can w
 4.1k Jan 09, 2023
4.1k Jan 09, 2023
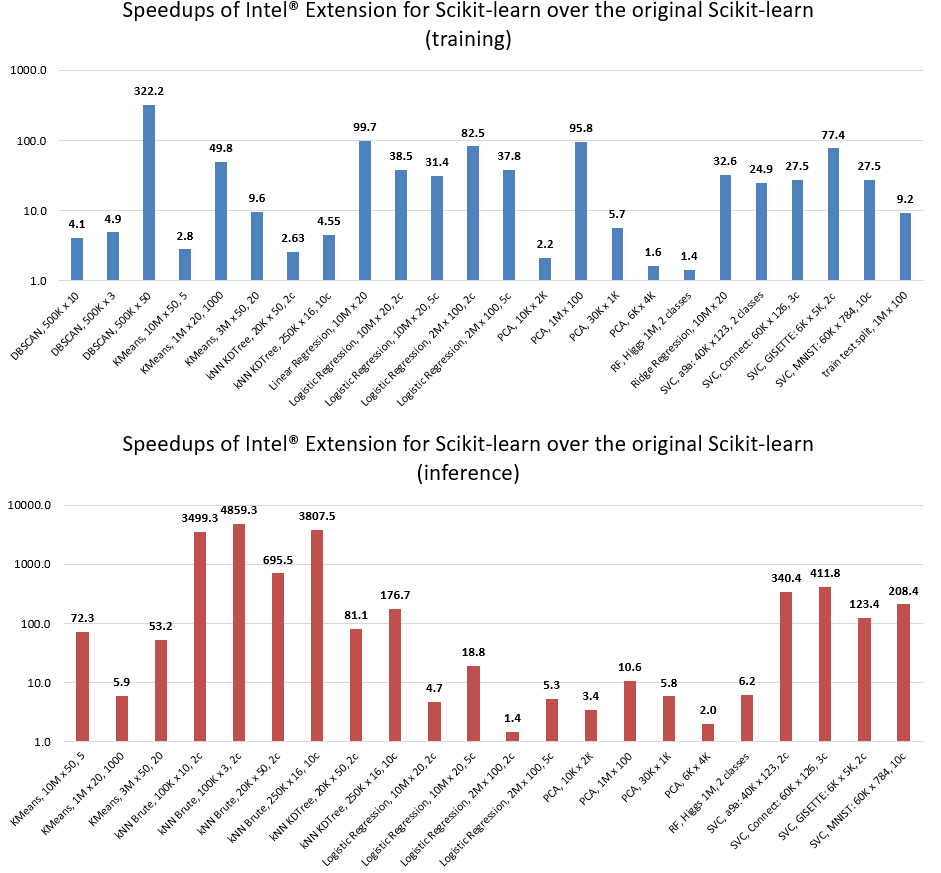
Intel(R) Extension for Scikit-learn is a seamless way to speed up your Scikit-learn application
Intel(R) Extension for Scikit-learn* Installation | Documentation | Examples | Support | FAQ With Intel(R) Extension for Scikit-learn you can accelera
 858 Dec 25, 2022
858 Dec 25, 2022
Spark-movie-lens - An on-line movie recommender using Spark, Python Flask, and the MovieLens dataset
A scalable on-line movie recommender using Spark and Flask This Apache Spark tutorial will guide you step-by-step into how to use the MovieLens datase
 794 Dec 23, 2022
794 Dec 23, 2022
Apache Spark & Python (pySpark) tutorials for Big Data Analysis and Machine Learning as IPython / Jupyter notebooks
Spark Python Notebooks This is a collection of IPython notebook/Jupyter notebooks intended to train the reader on different Apache Spark concepts, fro
1.5k Jan 02, 2023
SynapseML - an open source library to simplify the creation of scalable machine learning pipelines
Synapse Machine Learning SynapseML (previously MMLSpark) is an open source library to simplify the creation of scalable machine learning pipelines. Sy
3.9k Dec 30, 2022
Vaex library for Big Data Analytics of an Airline dataset
Vaex-Big-Data-Analytics-for-Airline-data A Python notebook (ipynb) created in Jupyter Notebook, which utilizes the Vaex library for Big Data Analytics
 1 Feb 13, 2022
1 Feb 13, 2022

Reproducible Data Science at Scale!
Pachyderm: The Data Foundation for Machine Learning Pachyderm provides the data layer that allows machine learning teams to productionize and scale th
 5.7k Dec 29, 2022
5.7k Dec 29, 2022

Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine.
img2dataset Easily turn large sets of image urls to an image dataset. Can download, resize and package 100M urls in 20h on one machine. Also supports
 1.4k Jan 01, 2023
1.4k Jan 01, 2023

Uproot is a library for reading and writing ROOT files in pure Python and NumPy.
Uproot is a library for reading and writing ROOT files in pure Python and NumPy. Unlike the standard C++ ROOT implementation, Uproot is only an I/O li
 164 Dec 31, 2022
164 Dec 31, 2022
Stream Framework is a Python library, which allows you to build news feed, activity streams and notification systems using Cassandra and/or Redis. The authors of Stream-Framework also provide a cloud service for feed technology:
Stream Framework Activity Streams & Newsfeeds Stream Framework is a Python library which allows you to build activity streams & newsfeeds using Cassan
 4.7k Jan 02, 2023
4.7k Jan 02, 2023

A distributed block-based data storage and compute engine
Nebula is an extremely-fast end-to-end interactive big data analytics solution. Nebula is designed as a high-performance columnar data storage and tabular OLAP engine.
 131 Dec 26, 2022
131 Dec 26, 2022