当前位置:网站首页>Flink学习2:应用场景
Flink学习2:应用场景
2022-06-27 01:56:00 【hzp666】
目录:

1 三大应用场景

1.1 事件驱动型
事务驱动型:计算和存储是在同一个位置。
事件驱动型:计算和存储是独立分开的。具有状态的应用,从一个或多个事件流中读取事件,并做出反应(触发计算,状态更新等)
事务驱动模型

事件驱动是,会从远程的事务数据库中读写数据。事件驱动型应用是基于传统的应用进化而来的。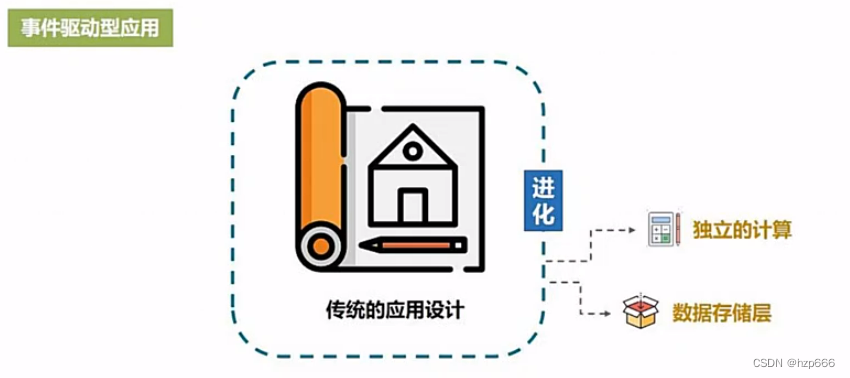


典型的事件驱动应用场景:

事件驱动应用的优势:
访问本地数据更快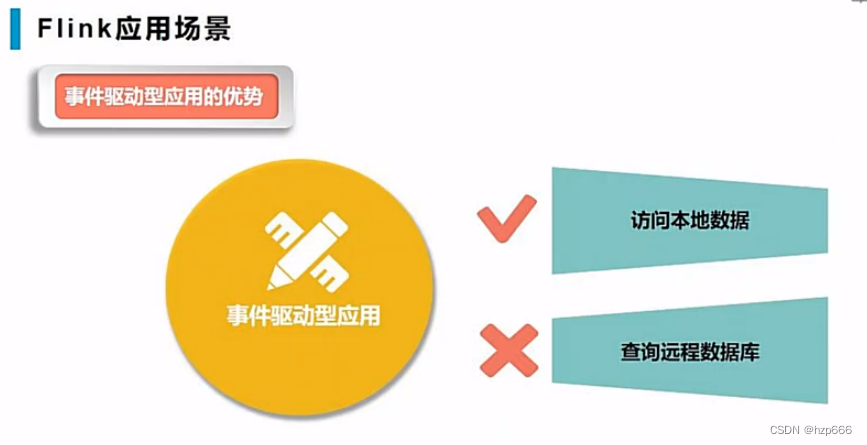


事件驱动型应用,因为是读取本地数据,所以只需考虑自己数据,不会涉及到其他系统的修改。

1.2 flink是如何支持事件驱动应用的:
事件处理很重要的一个能力就是,处理时间和状态。

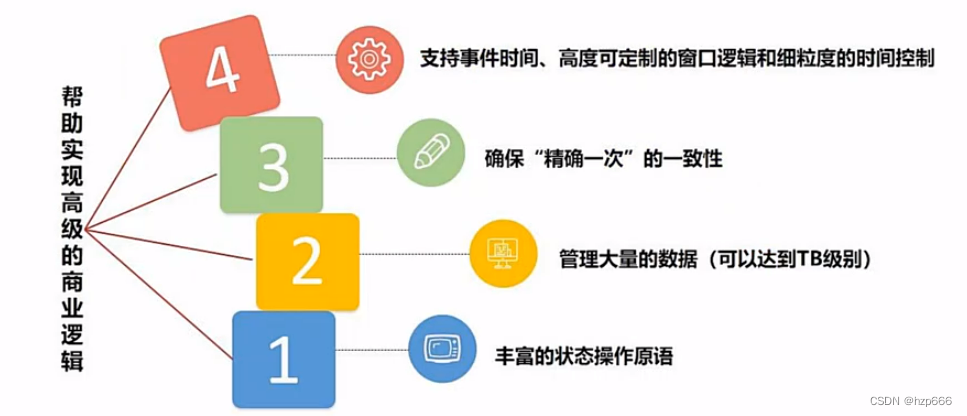

其中flink的savepoint 是一个一致性的状态镜像,可以记录多个应用状态,来使得应用可以安全放心的升级和扩容,并且还可以开启多个应用,来完成A/B测试。
1.2 数据分析型应用
什么是数据分析型应用:

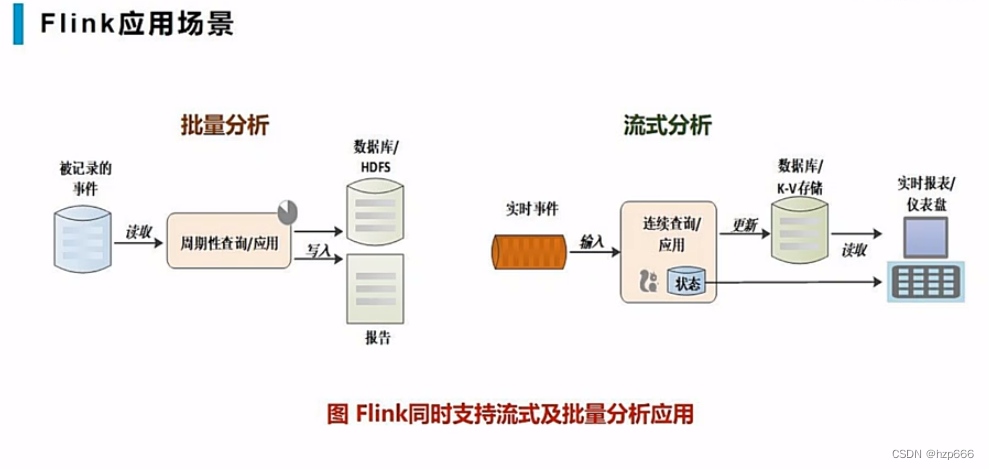
流式数据分析应用:

把结果写到外部数据库,或者内部状态中

然后,报表等数据分析应用,可以从外部数据库,或者内部状态读取:

典型的数据分析场景:

流式查询的优势:
1.实时数据分析,相对批量离线数据分析,延迟低
2.解决了批量离线数据处理中的边界问题
3.利用故障恢复机制,解决了批量离线作业的调度复杂问题(以及上下游依赖导致的上游作业失败,下游作业无法运行)



1.2.1 flink是如何支持数据分析应用的
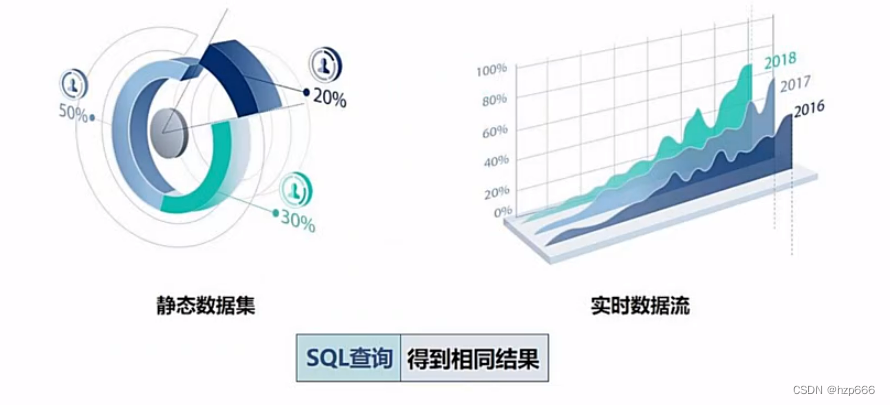
1.提供标准SQL接口,不管是查询静态数据集,还是实时数据集都是可以的。
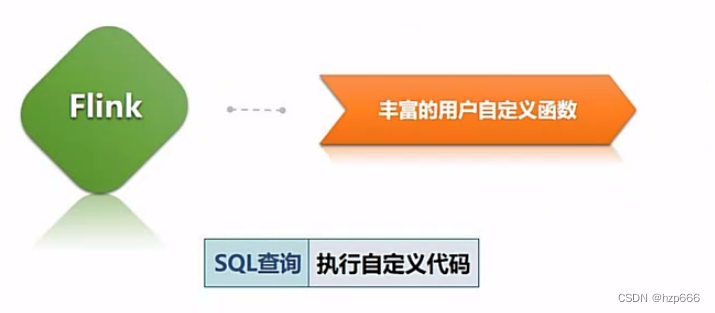
另外还支持自定义UDF函数。
而且,如果需要进一步定制处理逻辑,还可以使用DataSetAPI和DataStreamAPI提供更底层方法
另外,Flink的Gelly库提供了更多的图计算的库。



1.3 数据流水线应用
流水线简介:相对于ETL作业,流水线应用更实时


并且可以实现对目录,文件等实时监控,一旦发生改变可以随时捕获。


流水线应用的典型场景:

流水线的优势:

flink是如何支持流水线应用场景的:

提供大量连接器:

支持以时间分区的方式,来写入文件

边栏推荐
- memcached基础14
- d的appendTo包装
- Clip: learning transferable visual models from natural language monitoring
- Hibernate generates SQL based on Dialect
- STM32入门介绍
- H5 liquid animation JS special effect code
- D's appendto packaging
- Oracle/PLSQL: Upper Function
- Fork (), exec (), waitpid (), $? > > in Perl 8 combination
- Addition, deletion, modification and query of ymal file
猜你喜欢







随机推荐
二叉树oj题目
canvas粒子篇之鼠标跟随js特效
YaLM 100B:来自俄罗斯Yandex的1000亿参数开源大模型,允许商业用途
snakemake 使用的注意事项
二叉樹oj題目
Simply learn the entry-level concepts of googlecolab
P5.js death planet
宁愿去996也不要待业在家啦!24岁,失业7个月,比上班更惨的,是没班可上
Memcached foundation 10
I encountered some problems when connecting to the database. How can I solve them?
memcached基础11
消费者追捧iPhone,在于它的性价比超越国产手机
Arbre binaire OJ sujet
Topolvm: kubernetes local persistence scheme based on LVM, capacity aware, dynamically create PV, and easily use local disk
Oracle/PLSQL: Length Function
Oracle/PLSQL: Soundex Function
Svg drag dress Kitty Cat
UVM in UVM_ report_ Enabled usage
XSS attack (note)
C语言--职工信息管理系统设计