当前位置:网站首页>2016Analyzing the Behavior of Visual Question Answering Models
2016Analyzing the Behavior of Visual Question Answering Models
2022-06-27 03:15:00 【weixin_ forty-two million six hundred and fifty-three thousand 】
Abstract
The performance of most models is about 60-70%, this paper , We propose a systematic approach to analyze the behavior of these models , As a first step in identifying strengths and weaknesses and identifying the most productive directions . We analyze two models , One is with and without attention , It also shows the similarity and difference of the behavior of these models , We also analyzed 2016 year VQA The winning project of the challenge .
Our analysis shows that , Despite recent progress , But today's VQA yes “ Short sighted ”( Often fail in sufficiently new examples ), often “ Jump to conclusion ”( After listening to half of the questions, converge on the predicted answer ), and “ Stubborn ”( You can't change their answers based on the images ).
One 、 Introduce
Most models behave as 60-70%, And 2016VQA Before the challenge 9 There is only a gap between names 5%, Human performance on open tasks is 83% about , There are... In multiple tasks 91%. So as a first step in understanding the model , It is meaningful to compare the advantages and disadvantages of different models , Models for developing failure models , And determine the most fruitful direction of progress , Develop technology to understand VQA The behavior of the model is crucial .
In this paper , We have developed new technologies to describe VQA act , As a concrete example , We analyzed two kinds of VQA Model .
Two 、 Related work
This thesis is devoted to behavior analysis as a diagnosis VQA The wrong first step ,Yang They divide errors into four categories -- Model focus error area ; The model focuses on the appropriate area but predicts the wrong answer ; The predicted answer is different from the label but acceptable ; The label is wrong . Although these are rough but useful ways , But what we are interested in is understanding VQA Whether the model can be extended to new instances , Listen to the whole question , Whether to look at the image .
3、 ... and 、 behavior analysis
We analyze along three dimensions VQA Model :
(1) Extend to new instances : We investigate whether test cases with incorrect answers are new , There are two possible ways to test a new instance :1) Test questions - The image pair is new ;2) test QI Yes, it is similar , But the answer needed in the test set is new .
(2) Complete problem understanding : We analyze whether the model listens to the first few words of the problem or the whole problem .
(3) Complete image understanding : We study whether the prediction of the model changes according to the image .
Based on an inattentive model CNN+LSTM: stay VQA Implement... On the validation set 54.13% The accuracy of , A two channel model -- One channel is used for CNN Process images , For the other channel LSTM Dealing with problems , Combine the images obtained from the two channels with the problem features , And through a FC The layer gets the... In the answer space softmax Distribution .
Based on having attention (ATT) Model of CNN+LSTM: We use 2016VQA The model of the challenge , stay VQA Implement... On the validation set 57.02% The accuracy of . The model interprets images and problem concerns together in a hierarchical manner , Combination of participating images and problem features obtained from different levels , And through a FC Layer to get the answer space softmax Distribution .
VQA2016 The winning works of the challenge (MCB): Multimode compact bilinear pooling model (mcb) stay VQA You get... On the validation set 60.36% The accuracy of . In the model , Multimodal compact bilinear pooling is used to predict the attention to image features , And combine the involved image features with the problem features , The characteristics of the combination pass through a FC Layer to get the answer space softmax Distribution .
3.1 Generalize to new instances
To analyze the first new , We measured the test accuracy and test QI To its k The nearest neighbor (k-NN) The correlation between the distances of training pairs . For each test QI Yes , We found it in the training set k-NNs, And calculate the test QI To its k-NNs The average distance between .k-NNs Is in the combination of images + Problems embedded in space computing (FC Before layer ), stay CNN+LSTM Euclidean distance measurement is used on the model , stay ATT and MCB Cosine distance measurement is used on the model .
The correlation between accuracy and average distance is important ,(CNN+LSTM Model in k=50 Place for -0.41,ATT Model in k=15 Place for -0.42), A high negative correlation indicates , The model is useful for generalizing to new tests QI On the performance is not good . The correlation between accuracy and average distance is MCB The model is not significant in (k=1 Place for -0.14), indicate MCB It can be better extended to new tests QI Right up .
We also found that , Pass the inspection test QI To and k-NN Training QI Right distance , Can successfully predict CNN+LSTM Model (67.5%) The mistakes made (ATT The model is 66.7%,MCB The model is 55.08%). therefore , This analysis not only reveals VQA Why the model made mistakes , It also allows us to build human like models , This can predict your upcoming failure , And may refuse to answer questions that “ It's so different ” The problem of .
To analyze the second new ( The answers in the test set are not similar ), We calculated the test accuracy and k-NN Training QI Right GT Answer and test ground truth value (GT) The correlation between the average distances of the answers . The distance between the answers is on average Word2Vec In the space of vectors , about CNN+LSTM and ATT Model , This correlation is quite high (-0.62), And for MCB Model , These correlations are significant (-0.47). High negative correlation indicates that the model tends to repeat the answers seen in the training .
This distance feature is also easy to predict failure , By using CNN+LSTM Model k-NN Training GT Right GT Answer check test GT The distance of the answer , Predictable 74.19% Failure of (ATT The model is 75.41%,MCB The model is 70.17%). Please note that , Different from the previous analysis , This analysis only explains the faults , But it can not be used to predict failure ( Because it uses GT label ). As shown in the figure below 1.

chart 1 First line in , See the test QI To its k-NN Training QI Yes (( The first 1, The first 2, The first 3)-NN The distance is {15.05,15.13,15.17}) Is quite different , This is higher than the average distance in all successful cases {8.74,9.23,9.50}, Explained the mistake . The second line shows that the model sees the same problem in the training set ( test QI On semantics and testing QI To be highly similar ), The answers you see during the training are different from the answers you need to generate during the test , So I can't answer the test correctly QI Yes . indicate , The existing models lack combination : Be able to combine cone and green( Both have been seen in the training set ), To answer the test QI Right green cone, This combination is desirable , It's also the core .
3.2 Complete problem understanding
We provide some questions about length increase ( From left to right 0 To 100%). then , We calculate that as more and more words are entered , Show answers to some questions and answers to complete questions VQA Percentage of questions with the same accuracy .

chart 2 It shows that , about 40% The problem of ,CNN+LSTM The model listens to half the questions , Seems to focus on a predicted answer , The model predicts based on half of the problem , With ultimate accuracy (54%) Of 68%. When based on images , The model is just 24% The accuracy of the .ATT The model seems to be listening to half the questions more often (49% Time for ) Then it converges to a predicted answer , The final accuracy is achieved (57%) Of 74%.MCB Model in 45% After listening to only half of the questions in my time , It converges on the predicted answer , The final accuracy is achieved 67%(60%). As shown in the figure 3 Qualitative examples .

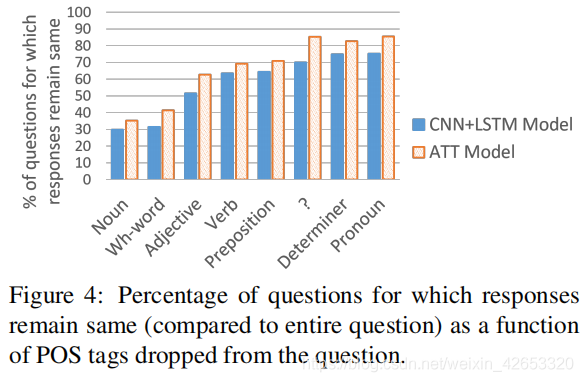
We also analyzed when a particular voice part (POS) When the word of the tag is deleted from the question , Changes in response predicted by the model . Experimental results show that ,wh-words It has the greatest impact on model decision-making , Pronouns have the least influence on model decision .
3.3 Complete image understanding

We calculate the percentage of time for a given problem (X) The response does not change according to the image , And draw X Histogram . We are right. VQA At least... In the validation set 25 Analyze the problems in the image , A total of 263 A question . The cumulative graph shows , about 56% The problem of ,CNN+LSTM The model outputs the same answer to at least half of the images .ATT and MCB Model ( Focus only on specific spatial areas in the image ), Fewer questions produce the same answer for at least half of the images (ATT The model is 42%,MCB The model is 40%).
stay CNN+LSTM In the model , For greater than 50% Less than 55% The average precision of the same answer question generated by the image of 56%(ATT by 60%,MCB by 73%), This is better than in the whole VQA The average precision of the validation set is high (CNN+LSTM by 54.13%,ATT by 57.02%,MCB by 60.36%), therefore , It seems statistically advantageous to produce the same answer on the image .

chart 6 It shows CNN+LSTM The model predicts that the image of a given problem has the same response . The first line shows an example where the model makes mistakes on multiple images by predicting the same answer for all images . The second line shows an example where the model is always correct , Even if it predicts the same answer in the image . This is because of things like “What covers the ground?” Only when the ground is covered with snow ,VQA Data sets will ask for images ( Because the subjects were viewing the images when they asked for them ). therefore , This analysis exposes the label bias in the data set ( especially “ yes / no ” problem ).
Four 、 summary
We have developed new technologies to describe VQA Model behavior , As a first step in understanding these models , Compare the advantages and disadvantages of different models in a meaningful way , Develop insights into their failure modes , And determine the most productive direction of progress . Our behavioral analysis shows that , Despite recent progress , But today's VQA The model is “ Short sighted ”( Often fail on sufficiently novel instances ), Often “ Jump to conclusion ”( The predicted answer after listening to half of the questions ), also “ stubborn ”( Will not change the answer according to the image ), There are fewer attention-based models " Stubborn " Than models that don't use attention .
As a last thought , We noticed that , Considering the model architecture and the data set being trained , Some of the pathological behaviors exposed in the paper are in a sense “ Correct ”. Ignore optimization errors , The maximum likelihood training goal is obviously to capture the statistical data of the data set . Our motivation is simply to better understand existing generalization models through their behavior , And use these observations to guide future choices —— Do we need new model classes ? Or data sets with different deviations ? wait .
边栏推荐
- 发现一款 JSON 可视化工具神器,太爱了!
- TP5 Spreadsheet Excle 表格导出
- Oracle/PLSQL: Ltrim Function
- ESP8266
- 2022 Chinese pastry (Advanced) recurrent training question bank and online simulation test
- PAT甲级 1021 Deepest Root
- Implementation of window encryption shell
- Test the respective roles of nohup and &
- Flink learning 1: Introduction
- Learn Tai Chi maker mqtt (IX) esp8266 subscribe to and publish mqtt messages at the same time
猜你喜欢

Pat grade a 1026 table tennis

Learn Tai Chi maker mqtt (IX) esp8266 subscribe to and publish mqtt messages at the same time

栈溢出漏洞

2021:Graphhopper: Multi-Hop Scene Graph Reasoning for Visual Question Answering

Learn from Taiji Maker - mqtt Chapter 2 (I) QoS service quality level
学习太极创客 — MQTT(六)ESP8266 发布 MQTT 消息
pytorch 22 8种Dropout方法的简介 及 基于Dropout用4行代码快速实现DropBlock

2019LXMERT:Learning Cross-Modality Encoder Representations from Transformers
PAT甲级 1026 Table Tennis

Flink学习4:flink技术栈
随机推荐
人间清醒:底层逻辑和顶层认知
Introduction to stm32
Paddlepaddle 20 implementation and use of exponentialmovingaverage (EMA) (support static graph and dynamic graph)
Easy to use plug-ins in idea
Overview of Tsinghua & Huawei | semantic communication: Principles and challenges
学习太极创客 — MQTT 第二章(二)ESP8266 QoS 应用
Flink learning 2: application scenarios
学习太极创客 — MQTT(六)ESP8266 发布 MQTT 消息
剑指Offer || :栈与队列(简单)
TopoLVM: 基于LVM的Kubernetes本地持久化方案,容量感知,动态创建PV,轻松使用本地磁盘
455. distribute biscuits [distribution questions]
2016Analyzing the Behavior of Visual Question Answering Models
mmdetection 用yolox训练自己的coco数据集
Pat grade a 1019 general palindromic number
Learn Tai Chi Maker - mqtt (VI) esp8266 releases mqtt message
Pat grade a 1026 table tennis
Stack overflow vulnerability
Getting started with bluecms code auditing
paddlepaddle 21 基于dropout实现用4行代码dropblock
Window 加密壳实现