当前位置:网站首页>Data mining knowledge points sorting (final review version)
Data mining knowledge points sorting (final review version)
2022-06-30 16:52:00 【A cute little monkey】
Catalog
- == Chapter one The introduction ==
- The background of data mining ? What is the driving force ?
- What are the characteristics of big data ?
- What is data mining ?
- What is the general process of data mining ?
- Industry data consolidation & What is the process of analysis ?
- The four main tasks of data mining ? What's the difference between them ?
- Combined with classification , This paper introduces some common concepts in data mining
- == Chapter two data ==
- Data attribute type
- What is an asymmetric property ?
- General characteristics of data sets
- What is a dimensional disaster ?
- How to understand dimensional disasters ?
- How to avoid dimension disaster ?
- What are the types of datasets ?
- What are the common data quality problems ?
- Measure the similarity and dissimilarity of data
- == The third chapter Data preprocessing ==
- Why do I need data preprocessing ?
- The main task of data preprocessing ?
- Data cleaning
- Missing data
- How to deal with missing data
- Abnormal data
- How to smooth outliers ( Mainly for outliers )?
- Type conversion
- sampling
- Data standardization
- Statistical description and visualization of data
- Selection and extraction of data
Chapter one The introduction
The background of data mining ? What is the driving force ?
DRIP(Data Rich,Information Poor)
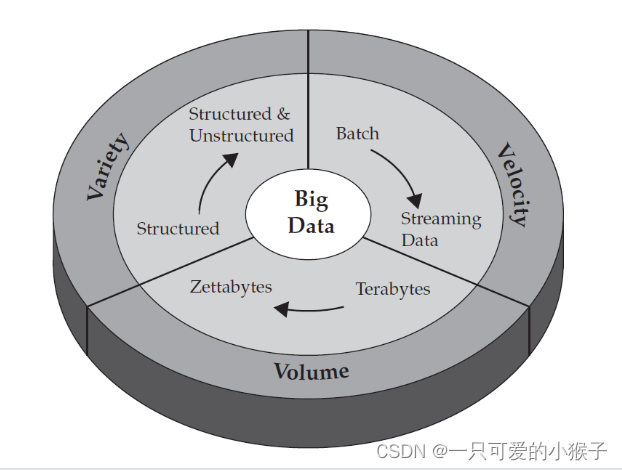
What are the characteristics of big data ?
3v : volume、velocity、Varity
The amount of data is TB Level to ZB level
Data diversity has changed from structured to unstructured and structured data
The speed of data transmission is very fast
Big data leads to difficult storage and computing
What is data mining ?
Data mining is Discover knowledge from data .
Mining from large amounts of data is Interested in 、 Helpful 、 The implicit 、 Previously unknown 、 and Patterns or knowledge that may be useful .
data mining Not fully automatic The process of , Human participation may be required in all links .
What is the general process of data mining ?

Industry data consolidation & What is the process of analysis ?

Extract data from various data sources , Then do some cleaning and fusion ( Extract transform load ), These data are processed , To put it together , And then install it in the data warehouse , Then take the data from the data warehouse to do all kinds of analysis and mining .
### Examples of data mining applications in various fields ** Public safety **: Excavate the law of crime , Prevent crime or reduce the occurrence of crime ** Personalized medicine **: Yes DNA Analyze , Depending on the genes , More tailored to the case ** city planning **: Use big data to analyze traffic heat maps in different periods , To help the staff lay out the route ** Precision sales **: Leverage customer information , Implement accurate recommendations ** motion **: Use data analysis to select potential players with low value
The four main tasks of data mining ? What's the difference between them ?
Main task : Clustering analysis 、 Classified forecast 、 Correlation analysis 、 Anomaly detection .
difference :
Classification is the use of labels for model building , Then use the model to predict , It is a supervised learning method
Clustering is achieved by minimizing the distance between clusters , Maximize the distance between clusters , It is an unsupervised learning method
Combined with classification , This paper introduces some common concepts in data mining
What is the classification boundary ?
Learn such classification boundaries by building models , A category boundary can be a category line , The classification surface can also be a hyperplane .
What is over fitting ?
The trained classification boundary fits the training data too much , It may cause the model to have a good effect in training , The effect is not good in the test set

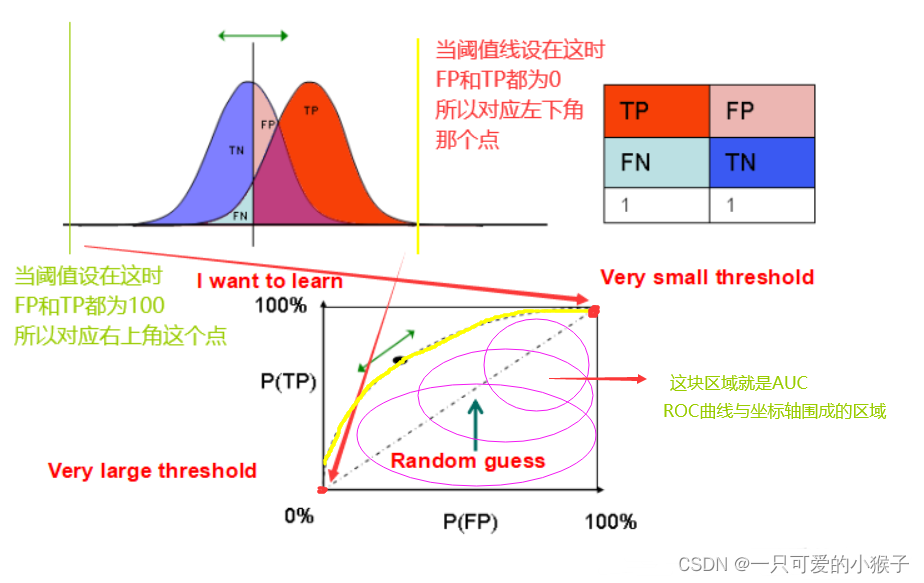
What is confusion matrix ?

The evaluation index :
TPR = TP / (TP + FN)( The predicted value of the true correct value is the correct proportion )
TNR = TN / (TN + FP) ( The proportion of the truly wrong values in which the predicted value is wrong )
Accuracy = (TP + TN) / (P + N) ( Predict the correct proportion of all actual results )
What is? ROC curve /AUC Evaluation criteria ?
What is cost sensitive learning ?
There are two kinds of errors in the confusion matrix , One is positive and the other is negative ; One is that the negative prediction becomes positive
Among the practical problems , These two mistakes are put together , The cost of error varies , Therefore, we should focus on reducing the high cost of errors in learning
for example : During medical treatment , Those who are really ill are diagnosed as having no disease , Those who are not ill are diagnosed as ill , It must be the former that is more costly , So reduce the occurrence of the former
Chapter two data
Data attribute type
It is divided into : Continuous and discrete
What is an asymmetric property ?
Only pay attention to A few non-zero attribute values It makes sense , Call this attribute asymmetric ( for example : Supermarket shopping , It only matters what you buy , And don't care what you didn't buy )
General characteristics of data sets
(1) dimension
Is the number of attributes in the dataset . When analyzing high-dimensional data, it is easy to fall into Dimension disaster . An important motivation for data preprocessing is to reduce dimensions , And dimensional reduction .
(2) sparsity
Some datasets, such as datasets with asymmetric attributes , The non-zero term is less than 1%, This allows you to store only non-zero values , It will greatly reduce the computing time and storage space . There are algorithms for sparse data ( sparse matrix ) To deal with .
(3) The resolution of the
Data with different resolutions can be obtained at different acquisition frequencies . for example : Data with a resolution of several meters , The earth is very uneven , But if the data with resolution of tens of kilometers , But relatively flat . The data mode depends on the resolution . The resolution is too small , The pattern may not appear . Too much resolution , The pattern may not see .
What is a dimensional disaster ?
In order to get better classification effect , We can add more features , But when we have a certain number of characteristics , Instead, the effect of classifiers began to decline .

How to understand dimensional disasters ?

The high-dimensional classifier learns the noise and anomalies of the training data , However, the fitting effect of data outside the sample is not ideal . Resulting in over fitting .
let me put it another way , As the dimensions increase , But the data is fixed , therefore The data becomes more and more sparse in the feature space , Make the model easy to over fit , Learned noise and outliers , Thus, dimensional disasters occur .
How to avoid dimension disaster ?
(1) Amount of training data
In theory, , The number of training samples is required As the index increases ( Infinite ), Dimensional disasters will not happen .
(2) The type of model
A classifier with nonlinear decision boundary , Such as neural network 、KNN, Decision tree , Good classification effect , But the generalization ability is poor .
therefore , The dimension cannot be too high when using these classifiers , Instead, you need to increase the amount of data .
If it is a classifier with good generalization ability , Like Bayes 、 Linear classifier , More features can be used .
What are the types of datasets ?
(1) Record data ( Data matrix 、 Trading data 、 Text data )
The standard form of data set is data matrix .( Data objects have the same set of numeric attributes )( It's a table )

What is the word bag model ?( Each document is expressed as a word vector ; Each word is a component of a vector ; The value of each component is the number of times the word appears in the document .)

(2) Figure data ( web 、 Molecular structure )
(3) Sequence data ( The time series 、 Spatial data 、 Image data 、 Video data )
What are the common data quality problems ?
Poor data quality will have a negative impact on many data processing work ( for example : Some people in good standing are refused loans )
Common data quality problems : noise 、 outliers 、 Missing value 、 duplicate value 、 Inconsistent values 、 Unbalanced data
noise (Noise): Is an unrelated data object
outliers (Outliers): It's data objects , But its characteristics are significantly different from most objects in the dataset
Measure the similarity and dissimilarity of data
Similarity measure : Measure the similarity of data objects . The more similar , The higher the value ; The value usually falls in [0,1].
Dissimilarity measure : Measure the dissimilarity of data objects . The more dissimilar , The higher the value ; The value usually falls in [0,+), The upper bound is uncertain .
Similarity measurement method : Binary vector similarity (SMC、Jaccard coefficient )、 Cosine similarity 、 Pearson correlation
Dissimilarity measures :Euclidean distance 、Minkowski distance 、 Markov distance
Similarity measure between binary vectors

Similarity measure between multivariate vectors ( Cosine similarity )

Pearson correlation coefficient
The correlation coefficient (x, y) = covariance (x, y) / ( Standard deviation (x) * Standard deviation (y))
The correlation is 【-1, 1】 There is a linear correlation between , Therefore, the variables of the nonlinear function are uncorrelated ( The correlation coefficient is 0 0)
Pearson test can only prove the linear correlation of variables , Whether the two variables are related , Chi square test can be used
Euclidean distance

Minkowski distance
Minkowski distance (Minkowski distance) yes Euclidean A generalization of distance

among r Is the parameter , n Is dimension ( attribute ),xk and yk Namely x and y Of the k Attributes ( component ) .
r = 1. Manhattan distance (Manhattan,L1 norm )
r = 2. Euclid distance (Euclidean,L2 norm )
r-> ∞. Supremum distance (Lmax or L∞ norm )
Markov distance

Advantages of Mahalanobis distance :
(1) Not affected by dimensions
The Mahalanobis distance is divided by a covariance matrix , This removes the variance between the components , Eliminate dimensionality , The Mahalanobis distance between two points is independent of the unit of measurement of the original data , More scientific and reasonable .
(2) Mahalanobis distance can also eliminate the interference of correlation between variables
The third chapter Data preprocessing
Why do I need data preprocessing ?
Because the real data is very “dirty”, There's a lot of data , The following problems may arise 
The main task of data preprocessing ?

Data cleaning

Missing data

How to deal with missing data

Abnormal data
Random errors in measurement variables (Noise) Or deviation (Outlier)
That is, noise and outliers
How to smooth outliers ( Mainly for outliers )?



Type conversion
There are several categories of attributes , Any conversion can be realized by encoding

discretization ( Continuous variable discrete type )




Supervised discretization : Find breakpoints using class labels , New samples can be discretized according to this , Reclassification
sampling
Sampling to reduce the time complexity of data reading processing
Sampling can be used to adjust the distribution of classes ( Apply to unbalanced datasets )
What is an unbalanced dataset ?
Unbalanced dataset refers to the dataset with unbalanced sample size of each category when solving classification problems .
What's wrong with unbalanced data sets ?
Here's an example :100 One of them 99 It's all healthy , A man has cancer . Train a classifier through this unbalanced data set , Whether the predicted people are healthy or not , The accuracy is 99%, The model trained by this unbalanced data set is meaningless .
This is the drawback of unbalanced data sets .
How to avoid the disadvantages of unbalanced data sets ?
(1) Adjust the distribution of classes by sampling
To increase the number of small class samples by sampling small class samples — Oversampling ( Add copies of some samples )
Sample large classes of samples to increase the number of small classes of samples — Undersampling ( Delete some samples )


(2) Define a new accuracy evaluation annotation
Data standardization
There are definite upper and lower bounds :Min-max Standardization

There are no upper and lower bounds :Z-score Standardization

Statistical description and visualization of data
Statistics of data description


Data visualization



Selection and extraction of data
Why feature extraction ?
Too many attributes will cause the dimension of the whole space to be too large ( It may lead to dimensional disaster ), For example, in 100 Maintenance classification , It needs to be in 100 Search for decision boundary on dimensional special space , This will make the problem too difficult .
Therefore, feature extraction is needed , Pick out the most relevant attributes , Make the problem less difficult .
How to judge the quality of attributes ?
qualitative : Category histogram ( Discrete attributes )、 Category distribution map ( Continuous attribute )
ration : entropy 、 Information gain
Entropy is used to measure the uncertainty of a system . That is, the confidence level to measure how much a value is taken or to judge what a class is . Mathematical expectation of information quantity , Measuring the uncertainty of a system in information theory .( The smaller the better. )
Information gain : When additional attributes are known , How much uncertainty has been reduced for the whole system .( The bigger the better )
边栏推荐
- Bidding announcement: Taizhou Unicom Oracle all in one machine and database maintenance service project in 2022
- 2022 Blue Bridge Cup group B - expense reimbursement - (linear dp| status DP)
- Multi terminal collaboration of Huawei accounts to create a better internet life
- Raft介绍
- Hologres shared cluster helps Taobao subscribe to the extreme refined operation
- Lambda表达式_Stream流_File类
- List announced - outstanding intellectual property service team in China in 2021
- Cesium-1.72 learning (earth model creation online offline tile)
- Etcd tutorial - Chapter 8 compact, watch, and lease APIs for etcd
- Interpretation of gaussdb's innovative features: partial result cache accelerates operators by caching intermediate results
猜你喜欢

List announced - outstanding intellectual property service team in China in 2021

Home office discussion on the experience of remote assistance to quickly improve efficiency | community essay solicitation
![Delete duplicates in an ordered array ii[double pointers -- unified in multiple cases]](/img/e2/cadfdbe476a86cb2d72c1ae0160a4a.png)
Delete duplicates in an ordered array ii[double pointers -- unified in multiple cases]

更多龙蜥自研特性!生产可用的 Anolis OS 8.6 正式发布

【微信小程序】小程序的宿主环境

深度学习——(2)几种常见的损失函数

Cesium-1.72 learning (earth model creation online offline tile)

BC1.2 PD协议

I 用c I 实现“栈”

利用PIL进行不失真的resize
随机推荐
jspreadsheet/CE JExcel数据字段比给的字段(columns)多会导致空白列的问题解决方案
More dragon lizard self-developed features! Production available Anolis OS 8.6 officially released
Mysql8.0 method and steps for enabling remote connection permission
中国传奇教授李泽湘,正在批量制造独角兽
[wechat applet] basic use of common components (view/scroll-view/wiper, text/rich-text, button/image)
Carry two load balancing notes and find them in the future
RT-Thread 堆区大小设置
牛客网:乘积为正数的最长连续子数组
名单揭晓 | 2021年度中国杰出知识产权服务团队
Distributed machine learning: model average Ma and elastic average easgd (pyspark)
IndexSearch
香港回归25周年 香港故宫博物馆正式开放成文化新地标
MySQL transaction / lock / log summary
招标公告:深圳市财政局数据库异地灾备项目
JS ES5也可以创建常量?
2022 Blue Bridge Cup group B -2022- (01 backpack to calculate the number of schemes)
register_ Chrdev and CDEV_ init cdev_ Add usage differences
[Demo] 循环写文件
2022 Blue Bridge Cup group B - expense reimbursement - (linear dp| status DP)
RT-Thread 堆區大小設置