当前位置:网站首页>Droid-slam: depth vision slam for monocular and binocular rgbd cameras
Droid-slam: depth vision slam for monocular and binocular rgbd cameras
2022-06-11 10:56:00 【3D vision workshop】
The author 丨 [email protected] You know
Source https://zhuanlan.zhihu.com/p/479534098
Editor 3D Visual workshop
Paper information
@article{teed2021droid,
title={Droid-slam: Deep visual slam for monocular, stereo, and rgb-d cameras},
author={Teed, Zachary and Deng, Jia},
journal={Advances in Neural Information Processing Systems},
volume={34},
year={2021}
}Paper and code
https://arxiv.org/pdf/2108.10869.pdf
https://github.com/princeton-vl/DROID-SLAM
Abstract Abstract
We introduce a new method based on deep learning SLAM System ,DROID-SLAM, It includes Through one Dense BA Layer iteratively updates camera pose and pixel depth . This The system is accurate , This is a big improvement over the previous work , also Is robust , There are far fewer catastrophic failures . Although training on monocular video , But it can use binocular stereo or RGB-D Video achieves better performance in testing .
1. introduction Introduction
SLAM Aimed at (1) Build an environment map ,(2) Locating agents in this environment . This is a SFM A special form of motion recovery structure , Focus on accurately tracking long-term trajectory . For robots , Especially autonomous vehicles , Is a key capability . In the work of this paper , We solve visual problems SLAM problem , The sensor is a monocular sensor 、 Binocular or RGBD Recording in the form of images captured by the camera .
SLAM The problem has been dealt with from many different angles . Early work used methods based on probability and filter , And alternately optimize the map and camera pose . Further , modern SLAM The system has utilized least squares optimization . An important element of accuracy is global BA, It jointly optimizes the camera pose and 3D Map . The advantages of an optimized form are SLAM The system can be easily modified to use different sensors . for example ,ORBSLAM3 Support single item 、 Binocular 、RGBD as well as IMU sensor , And modern SLAM The system can support different camera models . Despite significant progress , however Current SLAM The system lacks the required robustness for many real-world applications . It will fail in many cases , For example, feature point tracking is lost , The divergence of the optimization problem cannot converge and the offset accumulation . Deep learning has been proposed as a solution to many of these failure cases . Previous work has studied the use of nerves 3D Represent learned features instead of artificial features , And combine the learned energy term with the classic back-end optimization . Other jobs try to learn end-to-end SLAM perhaps VO System . Although these systems are sometimes robust , But they are common benchmarks benchmark The accuracy is far lower than the classic SLAM System .
In this paper, DROID-SLAM, A new method based on deep learning SLAM System . It has the best performance , It is superior to the existing classic or learning based benchmarks in challenging benchmarks SLAM System . Specially ,DROID-SLAM Has the following advantages :
High accuracy High Accuracy: We have made great improvements over previous work on multiple datasets or camera modes . stay TartanAir SLAM In the race , We have less monocular tracking than our previous best results 62% Error of , Reduce... On binocular tracking 60%. We are ETH-3D RGBD SLAM Top of the list , stay AUC Better than the second place in terms of indicators 35%, This includes errors and ratios for catastrophic failure . stay EuRoC On a monocular dataset , In the zero failure method , We have reduced 82% The error of the . in consideration of 11 Only... Of the sequences 10 A success , It is better than ORB-SLAM3 Higher than 43%. Input using a binocular camera , We are more than ORB-SLAM3 Less 71% The error of the . stay TUM-RGBD On dataset , We have reduced... In the zero failure approach 83% The error of the .
High robustness High Robustness: Compared to previous systems , We have far fewer catastrophic failures . stay ETH-3D On dataset , We successfully tracked 32 individual RGB-D In dataset 30 individual , The second only succeeded in tracking 19/32. About TartanAir,EuRoC and TUM-RGBD On dataset , We haven't had any failures .
Strong generalization Strong Generalization: Our system only uses monocular input for training , You can use binocular or RGB-D Input to improve accuracy , Without any more training . We are 4 Two data sets and 3 All results on the three camera modes are obtained through a single model , It's all in synthetic TartanAir On dataset , Only monocular input was used to train once .
DROID-SLAM Of “ Design inspired by microcirculation optimization Differentiable Recurrent Optimization-Inspired Design(DROID)” So it has strong performance and generalization , Is an end-to-end differentiable architecture , It combines the advantages of classical methods and deep networks . say concretely , It includes cyclic iterative updates , Based on optical flow RAFT On the basis of , But it introduces two key innovations .
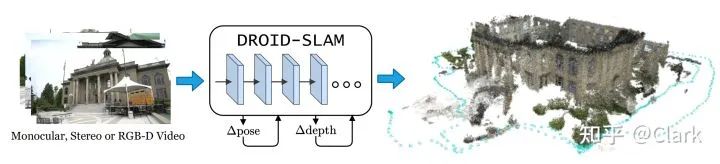
chart 1. DROID-SLAM It can be used in monocular 、 Eyes and RGB-D Run on video . It builds a dense environmental map , At the same time, locate the camera in the map .
First , With iteratively updating the optical flow RAFT Different , We iteratively update the camera pose and depth .RAFT Can run on two frames , Our update can be applied to any number of frames , The joint global optimization of all camera pose and depth maps is realized , This is essential to minimize the drift of long trajectories and closed loops .
secondly ,DROID-SLAM Every update of the pose and depth map of the camera in is made up of the differentiable Dense BA Layers produce , This layer calculates the pose and The density depth of each pixel dense per-pixel depth Gauss of - Newton update , To maximize its compatibility with current optical flow estimation . such DBA Layers take advantage of geometric constraints , Improved accuracy and robustness , The monocular system can handle binocular or RGB-D Input , Without having to train again .
DROID-SLAM The design of is novel . The closest previous depth architecture was DeepV2D and BA-Net, Both methods focus on depth estimation , Limited SLAM result .DeepV2D Update depth and camera pose alternately , instead of BA.BA-Net There is one BA layer , But their layers are essentially different : It is not “dense Dense ”, Because it optimizes a depth basis for linear combination ( A set of pre predicted depth maps ) A small number of coefficients , We directly optimized the depth of each pixel , And not suffer Depth basis depth basis Obstacles . Besides ,BA-Net The photometric re projection error is optimized ( In feature space ), And we optimized the geometric error , Using state-of-the-art flow estimation flow estimation.
We performed extensive evaluations on four different datasets and three different camera modes , The best performance in all cases . We also included ablation experiments , The important design decisions and super parameters are clarified .
2. Related work Related Work
modern SLAM The system regards positioning and mapping as a joint optimization problem .
Vision VSLAM Focus on monocular 、 Three dimensional or RGB-D Observation in the form of images . These methods are usually divided into direct method (direct) or indirect method (indirect). indirect method First, the image is processed into In the middle (intermediate representation) And additional feature descriptors . Then feature matching is performed between images . The indirect method minimizes the re projection error between the projected 3D points and their positions in the image , To optimize camera pose and 3D point cloud .
direct method For the image forming process (image formation process) Modeling , An objective function on photometric error is defined . One advantage of the direct method is , They can model more information about images , Such as line and intensity change , These are not used in the indirect method . However , Photometric errors often lead to more difficult optimization problems , And direct method to Shutter artifact (rolling shutter artifacts) Poor robustness of equal geometric distortion . This approach requires more sophisticated optimization techniques , Such as Image pyramid from thick to thin (coarse-to-fine image pyramid), To avoid falling into local optimization .
Our approach is not suitable for any of the above categories . The same as the direct method , We No preprocessing step is required to detect and match feature points between images . contrary , We use the full image , Allows us to take advantage of a larger than usual indirect method that uses only corner and edge features 、 Wider information . However , Similar to the indirect method , We also minimize the re projection error . This is an easier optimization problem , And avoids the need for more complex representations , Such as image pyramid . In this sense , Our approach draws on the advantages of both approaches : The smoother objective function of the indirect method and the greater modeling ability of the direct method .
Deep learning has been widely used in SLAM problem . A lot of work has focused on training systems for specific sub problems , Such as feature detection 、 Feature matching and outlier removal (outlier rejection) And positioning .SuperGlue For feature matching and verification , It makes the two view pose estimation more robust . Our network is also from Dusmanu Waiting for inspiration , it Build a neural network to the motion recovery structure SFM Tube line , To improve the positioning accuracy of key points .
Other work is focused on end-to-end training SLAM On the system . These methods are not complete SLAM System , But focus on 2 How big is the frame to reach a dozen frames of small-scale reconstruction . They lack modernity SLAM Many core capabilities of the system , Such as closed-loop detection and global BA bundle adjustment , This inhibits their ability to perform large-scale reconstruction , As shown in our experiment .∇SLAM Several existing SLAM Algorithm as Differentiable computing graph (differentiable computation graphs), It allows the error in reconstruction to be propagated back to the sensor observation . And this method is differentiable , It has no trainable parameters , This means that the performance of the system is limited by the accuracy of the classical algorithms they simulate .
DeepFactors Is the most complete depth SLAM System , Based on the early CodeSLAM above . It can Joint optimization of pose and depth variables , And can carry out short-term and long-distance closed-loop . And BA-Net similar ,DeepFactors The learned depth basis is optimized in the reasoning process (deep basis) Parameters of . by comparison , We don't depend on learning basis, Instead, it optimizes pixel level depth . This allows our network to better extend to new datasets , Because of our Depth means (depth representation) It is not bound to the training data set .
3. Method Approach
We use video as input , There are two goals : Estimate the trajectory of the camera and create a three-dimensional map of the environment . We first describe the configuration of the monocular camera ; stay 3.4 This section describes how to generalize the system to binocular stereo and RGB-D video .

3.1 Feature extraction and correlation Feature Extraction and Correlation
Extract features from each new image added to the system . The key components of this phase draw on RAFT.
feature extraction Feature Extraction. Each input image is processed through a feature extraction network . The network is composed of 6 A residual block and 3 Composed of three down sampling layers , produce 1/8 Input dense feature map of image resolution . And RAFT equally , We use two separate networks : Characteristic network (feature network) and Context network (context network). Feature networks are used to build Correlation volume set (set of correlation volumes), During each application of the update operator , Context features are injected into the network .

3.2 Update operator Update Operator


chart 2. Graphic representation of the update operator . The operator acts on frame-graph On the edge of , Forecast passed (DBA) Layer maps to the flow of depth and pose updates
 to update Update. Correlation features and flow features are injected GRU Previously, it was mapped through two convolution layers . Besides , We will also extract the context features from the context network , Inject into by adding element by element GRU in .
to update Update. Correlation features and flow features are injected GRU Previously, it was mapped through two convolution layers . Besides , We will also extract the context features from the context network , Inject into by adding element by element GRU in .
ConvGRU It is a local operation with a small receptive field . We extract the global context by averaging the hidden states in the spatial dimension of the image , And use this eigenvector as an additional input to GRU in . The global context is SLAM It's very important , Incorrect consistency may reduce the accuracy of the system . This is very important for the consistency of network identification and rejection errors .


3.3 Training Training
our SLAM The system is in PyTorch Implemented in , We use LieTorch The extended version of is available in all Group element (group elements) Performs back propagation in the tangent space of .
Eliminate degrees of freedom Removing gauge freedom. Under monocular setting , The network can only restore the camera track to Similarity transformation (similarity transform). One solution is to define a loss that is invariant to similar transformations . However , It still exists during training gauge-freedom, This has little effect on the regulation of linear system and the stability of gradient . We solve this problem by fixing the first two postures to the true value of each training sequence . Fixing the first pose eliminates the six degrees of freedom gauge freedom. Fixing the second pose can solve Scale degrees of freedom (scale freedom).
Build training videos Constructing training video. Each training example consists of a 7 Frame video sequence . To ensure stable training and good downstream performance , We want to sample videos that are not easy or difficult .

3.4 SLAM System
In the process of reasoning , We Combine the network into a complete SLAM System . The SLAM The system takes a video stream as input , And real-time reconstruction and positioning . Our system consists of two threads running asynchronously . front end (front end) Threads Accept new frame , The extracted features , Select keys , And execute local BA. Back end (back end) Threads At the same time, global... Is performed over the entire history of the keyframe BA. Here we provide an overview of the system .
initialization Initialization.DROID-SLAM The initialization of is very simple . We just collect frame data , Until we have a group 12 individual . When we accumulate frames , We only keep the optical flow greater than 16px Time history frame ( Estimate by applying an update iteration ). Once accumulated 12 frame , We passed the 3 Create an edge between the keys in a time step to initialize a frame-graph, And then run 10 Second iteration update operator .
front end Frontend. The front end runs directly on the input video stream . It maintains a set of keyframes and a frame graph, Store the edges between the common view keyframes . The pose and depth of keyframes are actively optimized . First, the feature is extracted from the input frame . Then add the new frame to frame - chart frame-graph in , By means of the average optical flow measurement, the optical flow with 3 The nearest neighbor edge . This pose is initialized using a linear motion model . then , We use several iterations of the update operator to update the pose and depth of the key frame . We fix the first two positions , To eliminate the measurement freedom (gauge freedom), But take all the depths as free variables .
After tracking to a new frame , We select a key frame to delete . We The distance between frame pairs is calculated by calculating the average optical flow size , And remove redundant frames . If no frame is a candidate delete frame , Let's delete the oldest key frame .

then , We apply the update operator to the whole frame-graph in , It usually consists of thousands of frames and edges . Storing a complete set of correlation volumes will soon exceed video memory . contrary , We used in RAFT Memory efficiency implementation proposed in .
In the process of training , We are PyTorch In the use of Automatic differentiation engine (automatic differentiation engine) Realized Dense cluster adjustment DBA. In reasoning , We used a custom CUDA kernel , It takes advantage of it. block-sparse structure , Then the simplified camera block is thinned Cholesky decompose .
We only perform global operations on keyframe images BA. In order to restore the pose of non key frames , We perform pure motion by iteratively estimating the flow between each key frame and its adjacent non key frames BA. During the test , We evaluated the complete camera trajectory , Not just keyframes .
Binocular stereoscopic sum RGBD. Our system can be easily modified to be binocular and RGBD video . stay RGB-D Under the circumstances , We still treat depth as a variable , because The depth of the sensor may be noisy , And lack of observations , And simply add one item to the optimization goal ( The formula 4), It is used to penalize the square distance between the observed depth and the predicted depth . For the Binocular Case , We use the exact same system described above , Only twice the frame image , And fix it DBA The relative pose between the left and right frames in the layer . In the frame graph Cross the camera side (cross camera edges) Allows us to use binocular stereo information .
3D Defect detection video tutorial : The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
4. experiment Experiments
We have carried out experiments on different data sets and sensor modes . We work with established classics based on deep learning SLAM The algorithm is compared , The generalization across data sets is emphasized . According to previous work , We evaluated the accuracy of the camera trajectory , The main use of Absolute trajectory error (Absolute Trajectory Error,ATE). Although some datasets have truth point clouds , But they don't compare SLAM The standard protocol of 3D reconstruction directly given by the system , because SLAM The system can select the 3D points to be reconstructed . Evaluating dense 3D reconstruction is typically considered in the field of multi view solid geometry , Beyond the scope of this work .

chart 3. DROID-SLAM It can be extended to new data sets . So , We've shown people from Tank & Temple、ScanNet、Sintel and ETH-3D The result on ; All use monocular video .
Our network is entirely composed of Tartan Air Data set from monocular video training . We train our network 250k Step , Batch size is 4, A resolution of 384×512,7 Frame clips , an 15 Update iteration . stay 4 individual RTX-3090 GPU It took... To train on 1 weeks .
TartanAir( Monocular and binocular ) This data set is a challenging comprehensive benchmark , And is used as ECCV 2020 SLAM competition Part of . We use official test split, And in surface 1 All... Are provided in “Hard” Sequential ATE.

surface 1. stay TartanAir Results on monocular basis
surface 1 The robustness of our method is proved ( No catastrophic failure ) And accuracy ( Very low drift ). We are TartanAir Retraining on DeepV2D As a baseline baseline. On most sequences , Our performance is superior to the existing methods by an order of magnitude , Its average error ratio TartanVO low 8 times , Than DeepV2D low 20 times . In the table 2 in , We also use TartanAir The data set and ECCV 2020 SLAM Compare the top results in the competition . The top two users in the competition COLMAP Built system , And the speed is slower than real-time operation 40 times . On the other hand , The running speed of our method on monocular benchmark is improved 16 times , The error on monocular datum is reduced 62%, On the binocular benchmark 60%.

surface 2. stay TartanAir Results on test set , And ECCV2020 SLAM Race forward 3 Comparison of names . The fraction is calculated using normalized relative pose error , For sequences of all possible lengths {5、10、15,...,40} rice .
EuRoC( Monocular and binocular ) In the remaining experiments , What we are interested in is the ability of our network to generalize to new cameras and environments .EuRoC Data sets include data from micro air vehicles (MAV) The video captured by the sensor on , Is widely used to evaluate SLAM The benchmark of the system . We use EuRoC Data sets to evaluate monocular and binocular performance , Parallel tables 3 The results are reported in .
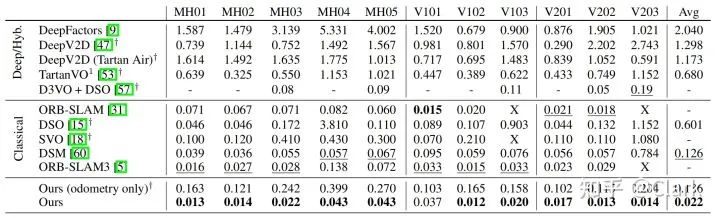
surface 3. EuRoC Monocular on dataset SLAM, ATE[m] Represents the visual odometer method .
In monocular configuration , We achieved an average of 2.2cm Of ATE, In the method of zero failure 82%, In comparison only ORB-SLAM3 Successful sequences , Than ORB-SLAM3 Less 43%.
We compare it with several deep learning methods . We will be in TartanAir Trained on the dataset DeepV2D And in NYUv2 and ScanNet The public version of the training on .DeepFactors Is in ScanNet Trained on . We found that , And classic SLAM System comparison , Recent deep learning methods are EuRoC Poor performance on datasets . This is due to poor generalization ability and data set bias resulting in a large number of drift ; Our method does not have these problems .D3VO By using the neural network as the front end and DSO As a back-end , Good robustness and accuracy can be obtained , Use 11 One of the sequences 6 To evaluate , And unsupervised training for the rest of the sequences , It contains the same scenarios used for the evaluation .
TUM-RGBD Data sets .RGBD The dataset consists of indoor scenes taken with hand-held cameras . Due to shutter artifact , Motion blur and violent rotation , This is a very difficult monocular method dataset . stay surface 4 in , We're interested in the whole Freiburg1 Data sets were benchmarked .

chart 4. stay RGB-D ETH3D-SLAM Generalization results on benchmarks .( Left ) Our method , Only in synthetic TartanAir Training on datasets , Ranked first in the division of training and testing .( Right ) The number of successful tracks is taken as ATE Function diagram of . Our method successfully tracks 30/32 individual RGBD Image data .
classical SLAM Algorithm , Such as ORB-SLAM, Often fails on most sequences . Although the deep learning method is more robust , But their accuracy for most evaluation sequences is low . Our method is robust and accurate . It successfully tracked all 9 A sequence of , meanwhile ATE Absolute trajectory error ratio DeepFactor low 83%, Successful on all videos ,ATE Than DeepV2D low 90%.
ETH3D-SLAM (RGBD) Last , We are ETH3D-SLAM The benchmark evaluates RGB-D Performance of . In this setup , The network also provides RGB-D Camera measurement . We put our network in TartanAir Training on , And add an addition term to the optimization objective , Penalty the distance between the predicted inverse depth and the depth observed by the sensor . Without any fine tuning , Our method ranks first in both training and test sets . Some of these datasets are “ dark ” Of , This means that there is no image data ; On these datasets , We do not submit any forecasts . On the test set , We successfully tracked 30/32 RGB-D.
Time and memory efficiency (Timing and Memory). Our system can use 2 individual 3090 GPU Run in real time . Tracking and local BA At the first GPU Up operation , And the whole picture BA And closed loop detection in the second GPU Up operation . stay EuRoC On dataset , We average 20 Frames per second ( Camera frame rate ) Downsampling to 320×512 The resolution of the , Skip every frame . surface 3 The result in is obtained under this configuration . stay TUM-RGBD On dataset , We downsampling to 240×320 And skip every other frame . stay TartanAir On dataset , Because the camera moves faster , We can't run in real time , Average 8 Frames per second . However , It is still TartanAirSLAM Challenging 16 times , It depends on COLMAP.
SLAM The front end can have 8 GB In memory GPU Up operation . The back-end needs to store the characteristic images of a complete set of image data sets , More stress on memory .TUM-RGBD All results on a dataset can be in a single 1080 Ti On the graphics card .EuRoC、TartanAir and ETH-3D( Video can reach 5000 frame ) The result on the dataset needs a 24GB In memory GPU. At present, the memory and resource requirements are the biggest limitations of our system , We believe that these can be greatly reduced by eliminating redundant computation and more efficient representation .
5. summary Conclusion
We introduced DROID-SLAM, One used for vision SLAM The end-to-end neural structure of .DROID-SLAM To be accurate 、 Robust and universal , It can be used for monocular 、 Eyes and RGB-D video . On a challenging benchmark , Its performance is much better than the previous work .
This article is only for academic sharing , If there is any infringement , Please contact to delete .
3D Visual workshop boutique course official website :3dcver.com
1. Multi sensor data fusion technology for automatic driving field
2. For the field of automatic driving 3D Whole stack learning route of point cloud target detection !( Single mode + Multimodal / data + Code )
3. Thoroughly understand the visual three-dimensional reconstruction : Principle analysis 、 Code explanation 、 Optimization and improvement
4. China's first point cloud processing course for industrial practice
5. laser - Vision -IMU-GPS The fusion SLAM Algorithm sorting and code explanation
6. Thoroughly understand the vision - inertia SLAM: be based on VINS-Fusion The class officially started
7. Thoroughly understand based on LOAM Framework of the 3D laser SLAM: Source code analysis to algorithm optimization
8. Thorough analysis of indoor 、 Outdoor laser SLAM Key algorithm principle 、 Code and actual combat (cartographer+LOAM +LIO-SAM)
10. Monocular depth estimation method : Algorithm sorting and code implementation
11. Deployment of deep learning model in autopilot
12. Camera model and calibration ( Monocular + Binocular + fisheye )
13. blockbuster ! Four rotor aircraft : Algorithm and practice
14.ROS2 From entry to mastery : Theory and practice
15. The first one in China 3D Defect detection tutorial : theory 、 Source code and actual combat
blockbuster !3DCVer- Academic paper writing contribution Communication group Established
Scan the code to add a little assistant wechat , can Apply to join 3D Visual workshop - Academic paper writing and contribution WeChat ac group , The purpose is to communicate with each other 、 Top issue 、SCI、EI And so on .
meanwhile You can also apply to join our subdivided direction communication group , At present, there are mainly 3D Vision 、CV& Deep learning 、SLAM、 Three dimensional reconstruction 、 Point cloud post processing 、 Autopilot 、 Multi-sensor fusion 、CV introduction 、 Three dimensional measurement 、VR/AR、3D Face recognition 、 Medical imaging 、 defect detection 、 Pedestrian recognition 、 Target tracking 、 Visual products landing 、 The visual contest 、 License plate recognition 、 Hardware selection 、 Academic exchange 、 Job exchange 、ORB-SLAM Series source code exchange 、 Depth estimation Wait for wechat group .
Be sure to note : Research direction + School / company + nickname , for example :”3D Vision + Shanghai Jiaotong University + quietly “. Please note... According to the format , Can be quickly passed and invited into the group . Original contribution Please also contact .

▲ Long press and add wechat group or contribute
▲ The official account of long click attention
3D Vision goes from entry to mastery of knowledge : in the light of 3D In the field of vision Video Course cheng ( 3D reconstruction series 、 3D point cloud series 、 Structured light series 、 Hand eye calibration 、 Camera calibration 、 laser / Vision SLAM、 Automatically Driving, etc )、 Summary of knowledge points 、 Introduction advanced learning route 、 newest paper Share 、 Question answer Carry out deep cultivation in five aspects , There are also algorithm engineers from various large factories to provide technical guidance . meanwhile , The planet will be jointly released by well-known enterprises 3D Vision related algorithm development positions and project docking information , Create a set of technology and employment as one of the iron fans gathering area , near 4000 Planet members create better AI The world is making progress together , Knowledge planet portal :
Study 3D Visual core technology , Scan to see the introduction ,3 Unconditional refund within days
There are high quality tutorial materials in the circle 、 Answer questions and solve doubts 、 Help you solve problems efficiently
Feel useful , Please give me a compliment ~
边栏推荐
- 杰理之获取 BLE 出现电压检测、ADC 检测不准【篇】
- Is it safe to open an account online? Can ordinary people drive it?
- Jerry's blepr0 and PR1 are used as ordinary IO ports [chapter]
- NFT 2.0: the next generation of NFT will be lean and trustworthy
- Summary of common constraints in MySQL foundation part I
- NFT将改变元宇宙中的数据所有权
- 使用 Ribbon 实现客户端负载均衡
- pyspark案例系列4-dataframe输出到单个文件夹的解决方案
- Jerry's ble chip power supply range and anti burn chip measures [chapter]
- 基于C语言实现比赛评分系统
猜你喜欢

Package component series - (I) - slots and dynamic components

Using ribbon to realize client load balancing

Electron桌面端开发(开发一个闹钟【完结】)

NFT products are alive

距离度量 —— 欧式距离(Euclidean Distance)

杰理之BLE 芯片供电范围及防烧芯片措施【篇】

新西兰是道路安全做的最好的国家之一
概率论:计算置信区间
Probability theory: calculating confidence intervals

地铁路线图云开发小程序源码和配置教程
随机推荐
Why does a ddrx power supply design require a VTT power supply
Store management skills: how to manage chain stores efficiently?
2022年安全月各类活动方案汇报(28页)
Online files are not transferred to Base64
NFT 2.0: the next generation of NFT will be lean and trustworthy
C#入门系列(十一) -- 多维数组
白屏时间、首屏时间
Jszip get the file of the specified file in the uploaded zip package
Cloud development MBTI personality type test assistant wechat applet source code
SAP Spartacus Reference App Structure
杰理之BLEPR0 和 PR1 当普通 IO 口使用【篇】
杰理之BLE SPP 开启 pin_code 功能【篇】
5.读取指定路径名-dirname
距离度量 —— 欧式距离(Euclidean Distance)
Content-Type: multipart/form-data; boundary=${bound}
C # introductory series (11) -- multidimensional array
DROID-SLAM: 用于单目双目RGBD相机的深度视觉SLAM
Using ribbon to realize client load balancing
网上开户是安全的吗?普通人可以开吗?
Leetcode 1995. 统计特殊四元组(暴力枚举)