当前位置:网站首页>TiDB 6.0 Placement Rules In SQL 使用实践
TiDB 6.0 Placement Rules In SQL 使用实践
2022-08-05 10:53:00 【TiDB_PingCAP】
本文作者:吴永健 https://tidb.net/u/banana_jian
简介
TiDB 6.0 版本正式提供了基于 SQL 接口的数据放置框架(Placement Rules in SQL), 特性用于通过 SQL 接口配置数据在 TiKV 集群中的放置位置。通过该功能,用户可以将表和分区指定部署至不同的地域、机房、机柜、主机。适用场景包括低成本优化数据高可用策略、保证本地的数据副本可用于本地 Stale Read 读取、遵守数据本地要求等。它支持针对任意数据提供副本数、角色类型、放置位置等维度的灵活调度管理能力,这使得在多业务共享集群、跨 AZ 部署等场景下,TiDB 得以提供更灵活的数据管理能力,满足多样的业务诉求。
该功能可以实现以下业务场景:
- 合并多个不同业务的数据库,大幅减少数据库常规运维管理的成本
- 增加重要数据的副本数,提高业务可用性和数据可靠性
- 将最新数据存入 SSD,历史数据存入 HDD,降低归档数据存储成本
- 把热点数据的 leader 放到高性能的 TiKV 实例上
- 将冷数据分离到不同的存储中以提高可用性
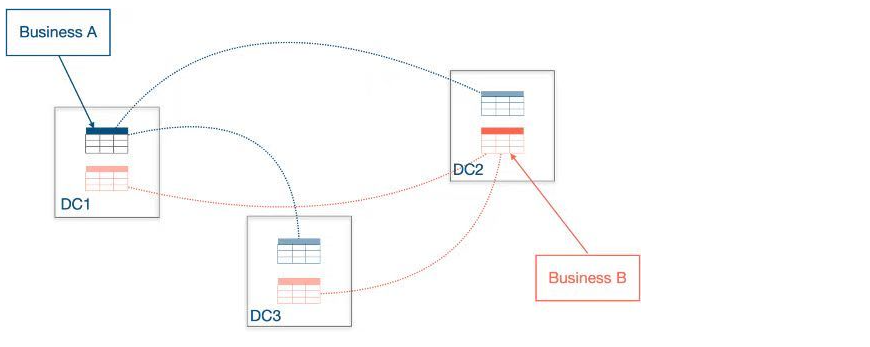
使用放置规则时有 2 种方式
(1) 直接放置
直接放置是指在 create table 时或使用 alter table 方式直接在表的 DDL 语句中使用放置选项
create table jian(id int) primary_region='bj' folllowers=4
(2) 放置策略
使用放置策略时首先通过 create placement policy 建立放置策略,然后在 create table 或 alter table 中直接指定放置策略。
create placement policy location_policy primary_region='bj' folllowers=4;
alter table jian placement policy location_policy;
使用时: 创建放置策略会使 placement policy 更加易于管理,通过修改放置策略可以直接更新所有使用该策略的对象。另一方面对于 create table 时使用和 alter table 时指定,这里也建议大家能注意以下两点:
create 方式建议在项目初期的库表结构设计节点进行设定,那么在初始话项目数据库的时候可以一次成型。否则需要将整个表进行recreate,此处就需要考虑历史数据的问题。
alter 方式由于是使用ALTER进行修改当表数据量大的时候可能会产生大量数据peer的移动,可能会消耗一定的资源,建议在业务低峰进行,但是也较好地弥补了一些即存表没有进行放置规则的设定后期需要添加,或者版本升级后需要使用新特性的问题。
Placement Rules in SQL 的应用场景猜想
由于 Placement Rules in SQL 的灵活性,在使用时可以“因地适宜”。以下是几个可以考虑的场景:
当采取两地三中心或跨地域数据中心部署的时候,由于 tidb 是无状态的应用那么可以利用就近原则将业务接入点进行分块,同时对于数据的分布也可以采用同样的方式。使数据的存放可以达到“本地数据本地访问”,即所有的数据存储,管理在本地区内完成。减少了数据跨地区复制延迟,降低流量成本。
当系统 IO 存在某些瓶颈时可以考虑将某些 tikv 节点的数据盘更换为 SSD,之后经过 Placement Rules 动态调整数据副本的存放策略,提高 db 的 IO 性能。对于一些历史及记录类的数据可以选择存放在一些主要由普通硬盘构成的 tikv 节点上。使硬件资源的配置得到充分的利用,而又不铺张浪费。
同时也考虑当进行硬件更换时可以使用 Placement Rules 对数据分布进行调整以减小 tikv 节点下线时的 peer 移动所需要的时间,因为通过 Placement Rules 可以将数据移动的动作提前进行分散在平时的小维护中。
由于数据的重要程度不同对于以往的副本设置可能更偏向于全局,引入 Placement Rules in SQL 后对于数据的副本数就可以进行灵活的限定,对高要求的数据表进行多副本设置,对于不太紧要的表尽量的减小副本数,在保证数据的安全性的情况下又可以节约存储资源。
如果业务采用了分库的模式为了减少运维成本,那么也可以考虑进行数据库整合,将分散的 mysql 实例迁移到一个 Tidb 集群中以多 schema 的方式存在,同时根据 Placement Rules 原始业务数据库的数据存放节点仍然可以放置在原来的硬件节点上,但是逻辑上由于整合到了一个数据库集群中升级、打补丁、备份计划、扩缩容等日常运维管理频率可以大幅缩减,降低管理负担提升效率。
对于经典的热点问题在 Placement Rules in SQL 也添加了更多的解决方案,通过 Placement Rules in SQL 也可以进行热点表的分布调整,而且也更加的方便与安全。虽然不能精确到 region 的级别,但是在表的粒度上也多提供了一种处理方法。
下面我们来详细看看 placement policy 的使用方法:
当前 tikv 节点以及集群的信息如下:
ID Role Host Ports OS/Arch Status Data Dir Deploy Dir
\-- ---- ---- ----- ------- ------ -------- ----------
192.168.135.148:9093 alertmanager 192.168.135.148 9093/9094 linux/x86_64 Up /tidb-data/alertmanager-9093 /tidb-deploy/alertmanager-9093
192.168.135.148:3000 grafana 192.168.135.148 3000 linux/x86_64 Up - /tidb-deploy/grafana-3000
192.168.135.148:2379 pd 192.168.135.148 2379/2380 linux/x86_64 Up|L|UI /tidb-data/pd-2379 /tidb-deploy/pd-2379
192.168.135.148:9090 prometheus 192.168.135.148 9090/12020 linux/x86_64 Up /tidb-data/prometheus-9090 /tidb-deploy/prometheus-9090
192.168.135.148:4000 tidb 192.168.135.148 4000/10080 linux/x86_64 Up - /tidb-deploy/tidb-4000
192.168.135.148:20160 tikv 192.168.135.148 20160/20180 linux/x86_64 Up /tidb-data/tikv-20160 /tidb-deploy/tikv-20160
192.168.135.148:20161 tikv 192.168.135.148 20161/20181 linux/x86_64 Up /tidb-data/tikv-20161 /tidb-deploy/tikv-20161
192.168.135.148:20162 tikv 192.168.135.148 20162/20182 linux/x86_64 Up /tidb-data/tikv-20162 /tidb-deploy/tikv-20162
这里有一点需要大家注意一下:默认的 PLACEMENT POLICY 是需要以 region 来作为区分标签的,所以在创建 tikv 的时候这里需要明确的指定 tikv 的 region 的标签,不然的话在show placement labels 是无法看到 region lable 的。这里可以参照官方文档的建议
PLACEMENT RULES的使用
1. 创建 PLACEMENT POLICY,并指定 PLACEMENT POLICY,定制其副本放置的位置
这里创建一个 PLACEMENT POLICY 使其 PRIMARY_REGION 放置在 region lable 为 bj 的 tikv 节点上,其余副本放置在 region lable 为 dl,sz 的 tikv 节点上
注意:primary region 必须包含在 region 的定义中
此处的 Raft leader 在 4 号 store 上,看之前开头的环境信息可以验证 PLACEMENT POLICY 已经生效
(root\@127.0.0.1) \[test] 12:00:14> CREATE PLACEMENT POLICY jianplacementpolicy PRIMARY_REGION="bj" REGIONS="bj,dl,sz";
Query OK, 0 rows affected (0.10 sec)
(root\@127.0.0.1) \[test] 12:00:32> CREATE TABLE jian1 (id INT) PLACEMENT POLICY=jianplacementpolicy;
Query OK, 0 rows affected (0.10 sec)
(root\@127.0.0.1) \[test] 12:03:36> show table jian1 regions\G
REGION_ID: 135
START_KEY: t_68\_
END_KEY: t_69\_
LEADER_ID: 137
LEADER_STORE_ID: 4 这里可以看到store_id是4
PEERS: 136, 137, 138
SCATTERING: 0
WRITTEN_BYTES: 39
READ_BYTES: 0
APPROXIMATE_SIZE(MB): 1
APPROXIMATE_KEYS: 0
1 row in set (0.00 sec)
2. 创建表不指定 PLACEMENT POLICY,之后修改 PLACEMENT POLICY 定制其副本放置的位置
leader 的 store 节点由原来的 1 变为了 4,看之前开头的环境信息可以验证 PLACEMENT POLICY 已经生效,可使用这个特性来修改表的leader节点或者当有热点问题时也可以变相的通过这种方式去修改频繁访问的表的leader所在的tikv的节点位置
(root\@127.0.0.1) \[test] 12:03:39> create table jian2(id int);
Query OK, 0 rows affected (0.10 sec)
(root\@127.0.0.1) \[test] 12:05:14> show table jian2 regions\G
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* 1. row \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
REGION_ID: 2
START_KEY: t_70\_
END_KEY:
LEADER_ID: 3
LEADER_STORE_ID: 1
PEERS: 3, 63, 85
SCATTERING: 0
WRITTEN_BYTES: 0
READ_BYTES: 0
APPROXIMATE_SIZE(MB): 1
APPROXIMATE_KEYS: 0
1 row in set (0.00 sec)
(root\@127.0.0.1) \[test] 12:05:16> alter table jian2 PLACEMENT POLICY=jianplacementpolicy;
Query OK, 0 rows affected (0.09 sec)
(root\@127.0.0.1) \[test] 12:05:50> show table jian2 regions\G
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* 1. row \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
REGION_ID: 143
START_KEY: t_70\_
END_KEY: t_71\_
LEADER_ID: 145
LEADER_STORE_ID: 4
PEERS: 144, 145, 146
SCATTERING: 0
WRITTEN_BYTES: 0
READ_BYTES: 0
APPROXIMATE_SIZE(MB): 1
APPROXIMATE_KEYS: 0
1 row in set (0.00 sec)
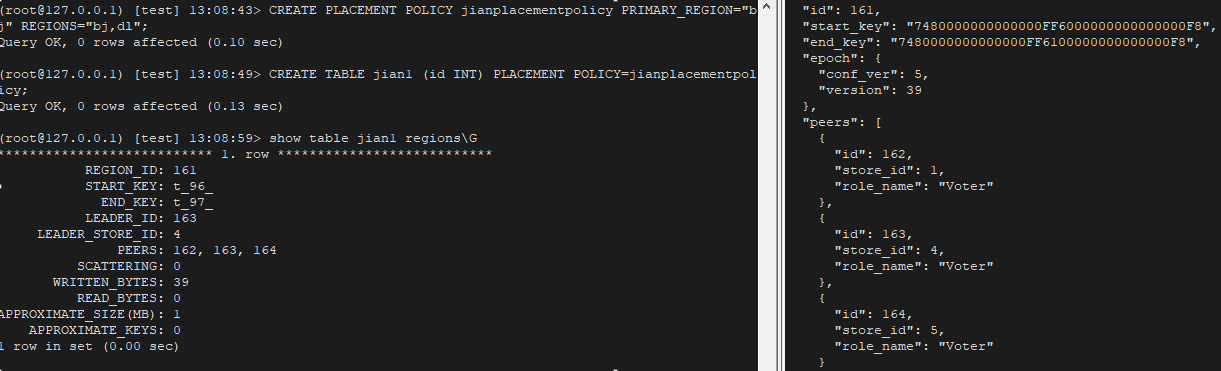
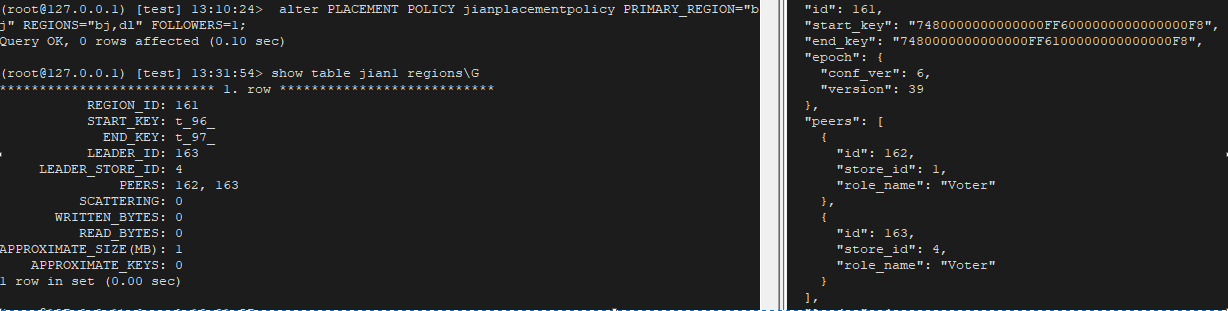
3. 通过 PLACEMENT POLICY 修改表的副本数
Follower 的数量。例如 FOLLOWERS=2 表示数据有 3 个副本(2 个 follower 和 1 个 leader)。
(root\@127.0.0.1) \[test] 12:10:34> alter PLACEMENT POLICY jianplacementpolicy FOLLOWERS=1;
Query OK, 0 rows affected (0.11 sec)
(root\@127.0.0.1) \[test] 12:10:40> show table jian2 regions\G
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* 1. row \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
REGION_ID: 143
START_KEY: t_70\_
END_KEY: t_71\_
LEADER_ID: 145
LEADER_STORE_ID: 4
PEERS: 144, 145 **副本数从 3 个已经调整到了 2 个
**
SCATTERING: 0
WRITTEN_BYTES: 0
READ_BYTES: 0
APPROXIMATE_SIZE(MB): 1
APPROXIMATE_KEYS: 0
1 row in set (0.00 sec)
(root\@127.0.0.1) \[test] 12:10:44> alter PLACEMENT POLICY jianplacementpolicy FOLLOWERS=2;
Query OK, 0 rows affected (0.09 sec)
(root\@127.0.0.1) \[test] 12:10:59> show table jian2 regions\G
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* 1. row \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
REGION_ID: 143
START_KEY: t_70\_
END_KEY: t_71\_
LEADER_ID: 145
LEADER_STORE_ID: 4
PEERS: 144, 145, 148
SCATTERING: 0
WRITTEN_BYTES: 0
READ_BYTES: 0
APPROXIMATE_SIZE(MB): 1
APPROXIMATE_KEYS: 0
1 row in set (0.02 sec)
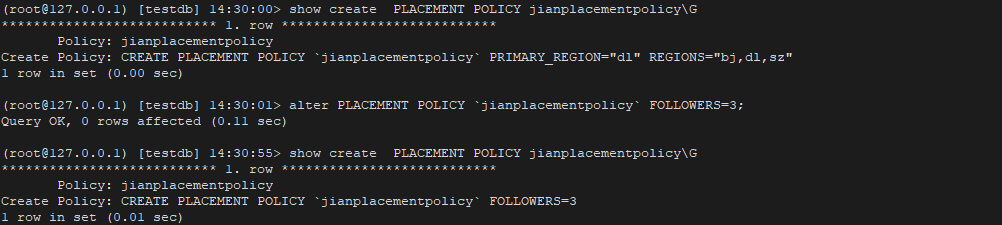
4. 修改 PLACEMENT POLICY 定义
注意:修改定义时需要将原来的定义都带上否则会将其覆盖 这一点在官方文档中并没有特殊说明,也是自己在测试这个功能的时候偶然的发现,目前官方也没有直接修改的语法,所以大家在修改放置规则的时候一定要注意之前的定义以免将之前的定义覆盖。
##########################################################
之前的 PRIMARY_REGION="bj" REGIONS="bj,dl,sz" 定义已经被覆盖了
##########################################################
5. PRIMARY_REGION 节点宕机
如果 PRIMARY_REGION 的 tikv 节点宕机,那么 leader 节点也会转移到非 PRIMARY_REGION 节点,当 tikv 节点恢复正常后 leader 节点也会随之转移回来
以下的过程
leader 节点:store4-- 停止 store 的 tikv —》store1 – 恢复 tikv 节点-- 》store4
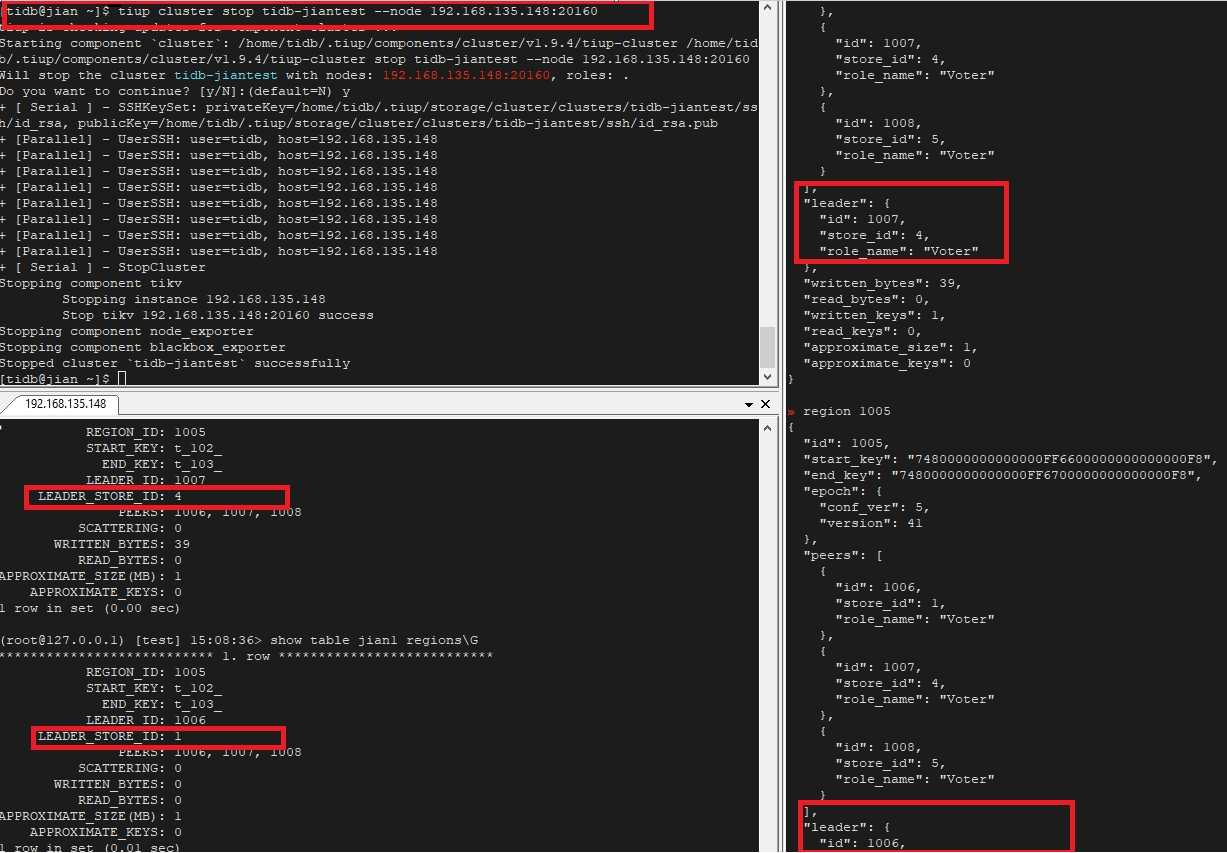
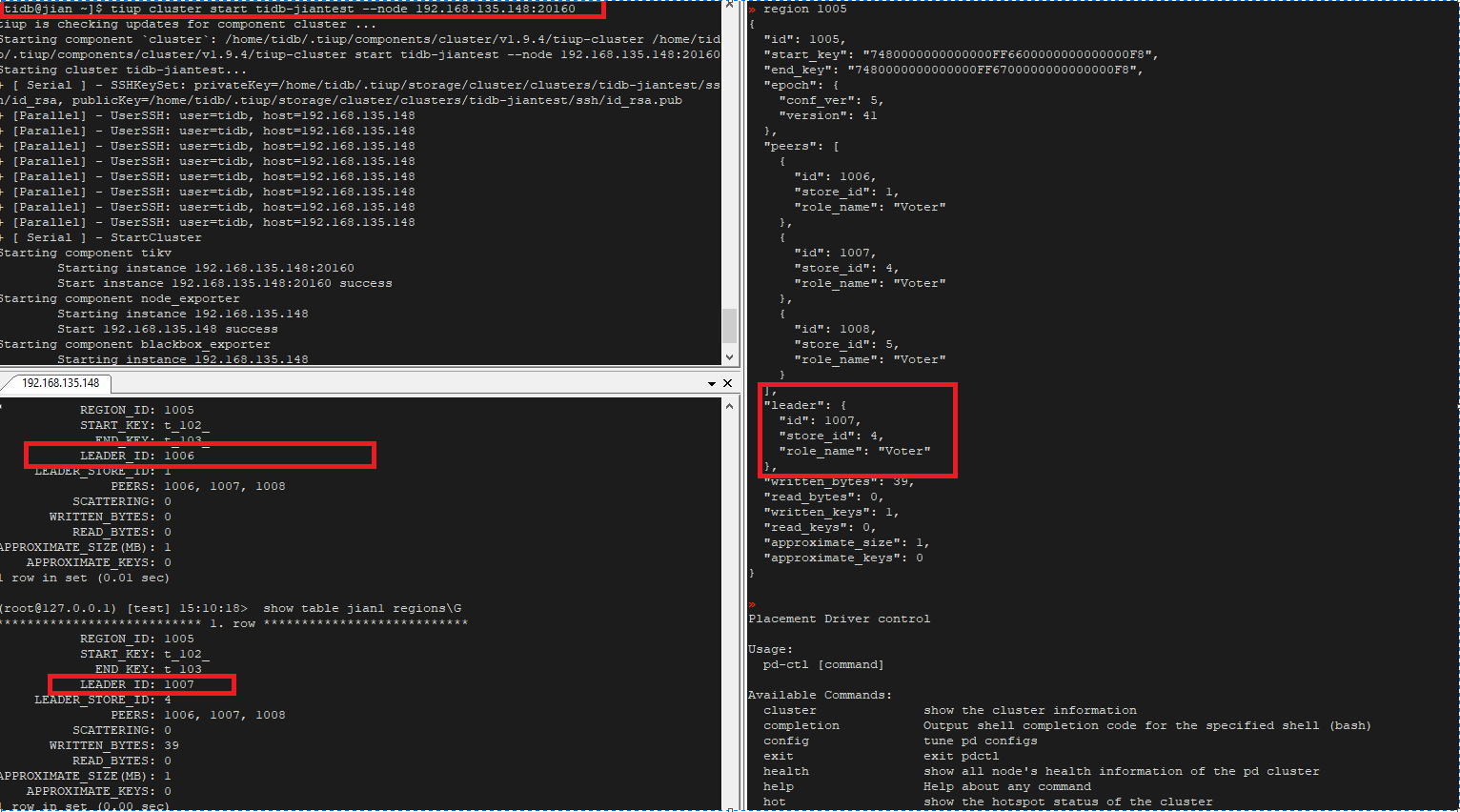
6. 更改 PRIMARY_REGION
如果更改表当前 palcement policy 定义的 primary region 那么表的 leader 也会随 PRIMARY_REGION 的改变而改变
下图 jian1 表一开始的 region 1005 的 leader 是在 store4(bj)上边,之后修改其 PRIMARY_REGION 为 dl(store 1),可以看到 region 1005 的 leader 也确实随之发生了改变
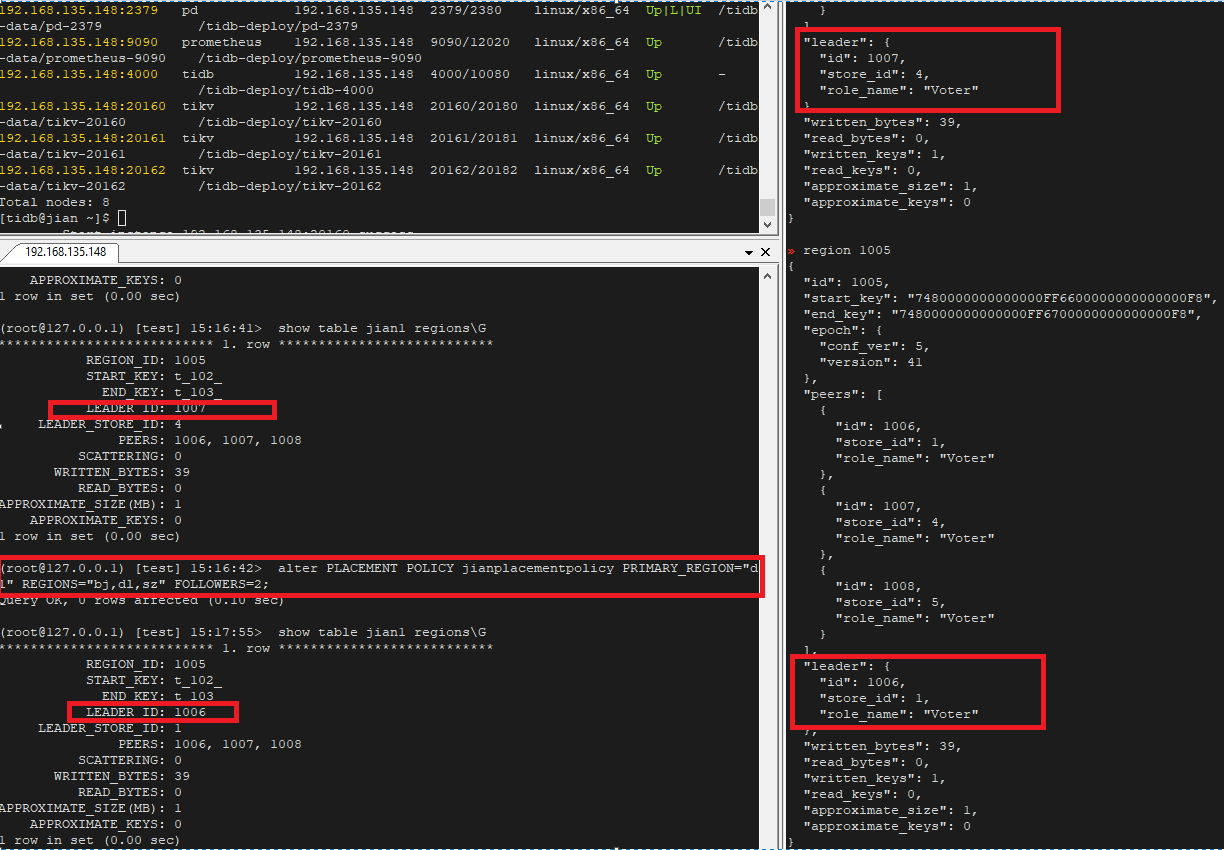
7. PLACEMENT POLICY 同样适用与分区表
以下样例中我们手动指定了每一个分区的 PLACEMENT POLICY,使其每个分区的 leader 都存放于不同的 store 上。
CREATE PLACEMENT POLICY policy_table FOLLOWERS=3;
CREATE PLACEMENT POLICY policy_dl PRIMARY_REGION="dl" REGIONS="dl,bj,sz";
CREATE PLACEMENT POLICY policy_bj PRIMARY_REGION="bj" REGIONS="dl,bj,sz";
CREATE PLACEMENT POLICY policy_sz PRIMARY_REGION="sz" REGIONS="dl,bj,sz" FOLLOWERS=1;
SET tidb_enable_list_partition = 1;
CREATE TABLE t1 (
location VARCHAR(10) NOT NULL,
userdata VARCHAR(100) NOT NULL
) PLACEMENT POLICY=policy_table PARTITION BY LIST COLUMNS (location) (
PARTITION p_dl VALUES IN ('dl') PLACEMENT POLICY=policy_dl,
PARTITION p_bj VALUES IN ('bj') PLACEMENT POLICY=policy_bj,
PARTITION p_sz VALUES IN ('sz') PLACEMENT POLICY=policy_sz
);
下图可一看到t1的region分别存放在store 1(dl),4(bj),5(sz)上边
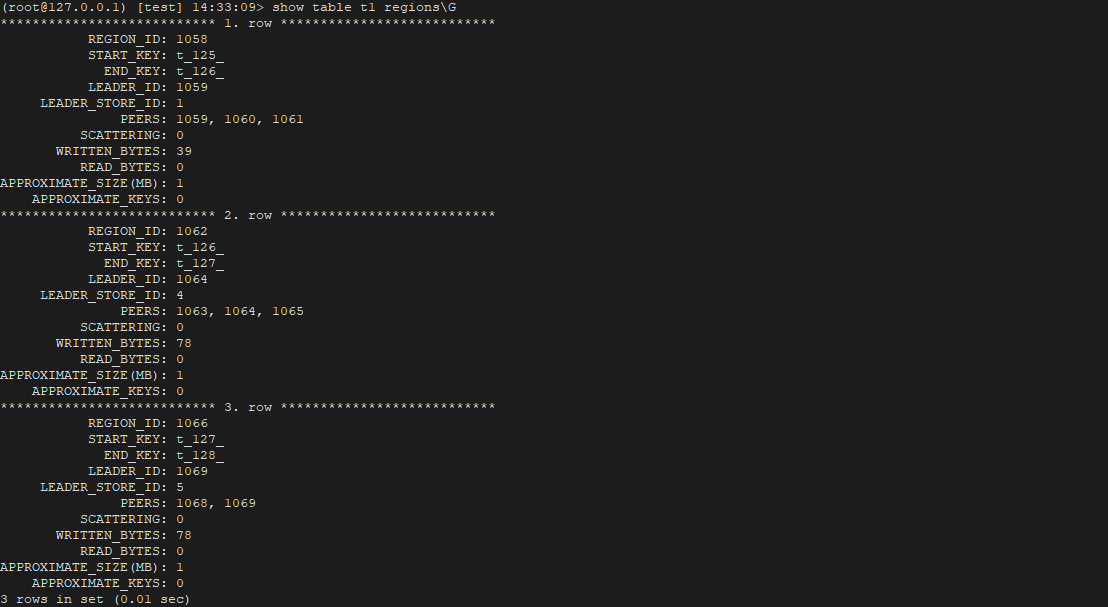
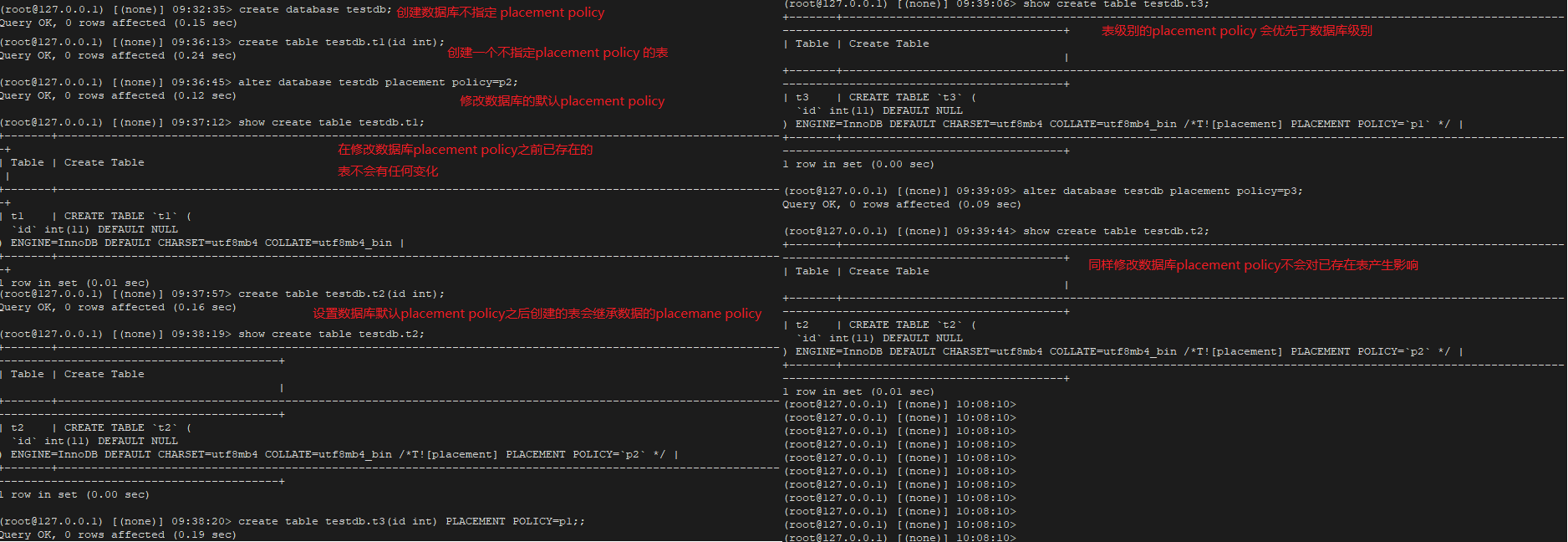
8. 查看数据库中现有的 PLACEMENT POLICY

9. 设置数据库级别的 PLACEMENT POLICY
更改默认的放置选项,但更改不影响已有的表
创建新表会自动继承当前数据的放置规则
表级别的放置规则要优先于数据库级别的放置规则
10. 高级放置规则
注意:PRIMARY_REGION、REGIONS 和 SCHEDULE 选项不可与 CONSTRAINTS 选项同时指定,否则会报错
以下 placement policy 的解读为:
- 使用该规则的表的 region 只可以放置在含有 rack 标签且等于 rack1 的 tikv 节点上
- 使用该规则的表的 leader region 只可以放置在含有 dc 标签且等于 bja 的 tikv 节点上
- 使用该规则的表的 follower region 只可以放置在含有 dc 标签且等于 dla 的 tikv 节点上
(root\@127.0.0.1) \[(none)] 16:34:28> create placement policy localtion_policy CONSTRAINTS="\[+rack=rack1]" LEADER_CONSTRAINTS="\[+dc=bja]" FOLLOWER_CONSTRAINTS="{+dc=dla: 1}";
Query OK, 0 rows affected (0.10 sec)
(root\@127.0.0.1) \[(none)] 16:35:41> create table testdb.jian2(id int) placement policy=localtion_policy;
Query OK, 0 rows affected (0.19 sec)
(root\@127.0.0.1) \[(none)] 16:35:49> show table testdb.jian2 regions\G
\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\* 1. row \*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*\*
REGION_ID: 1127
START_KEY: t_167\_
END_KEY: t_168\_
LEADER_ID: 1129
LEADER_STORE_ID: 4
PEERS: 1128, 1129
SCATTERING: 0
WRITTEN_BYTES: 0
READ_BYTES: 0
APPROXIMATE_SIZE(MB): 1
APPROXIMATE_KEYS: 0
1 row in set (0.01 sec)
注意:虽然 placement policy 高级匹配规则的默认 followers 是 2(三副本)但是实际的副本数还是要看符合 lable 的 tikv 的数量,如果实际的tikv节点数量无法满足2followers 那么最终也只会有两个副本(也就是只有一个followers和一个leader)上边的查询结果可以看到实际 region 的副本只有两个,但是当查询 localtion_policy 这个规则定义的时候 followers 为 2
POLICY_ID: 17
CATALOG_NAME: def
POLICY_NAME: localtion_policy
PRIMARY_REGION:
REGIONS:
CONSTRAINTS: \[+rack=rack1]
LEADER_CONSTRAINTS: \[+dc=bja]
FOLLOWER_CONSTRAINTS: {
+dc=dla: 1}
LEARNER_CONSTRAINTS:
SCHEDULE:
FOLLOWERS: 2
LEARNERS: 0
11. placement policy 的创建选项
| 选项名 | 描述 |
|---|---|
| PRIMARY_REGION | Raft leader 被放置在有 region 标签的节点上,且这些 region 标签匹配本选项的值。 |
| REGIONS | Raft followers 被放置在有 region 标签的节点上,且这些 region 标签匹配本选项的值。 |
| SCHEDULE | 用于调度 follower 放置位置的策略。可选值为 EVEN(默认值)或 MAJORITY_IN_PRIMARY。 |
| FOLLOWERS | Follower 的数量。例如 FOLLOWERS=2 表示数据有 3 个副本(2 个 follower 和 1 个 leader)。 |
| CONSTRAINTS | 适用于所有角色 (role) 的约束列表。例如,CONSTRAINTS=“[+disk=ssd]”。 |
| LEADER_CONSTRAINTS | 仅适用于 leader 的约束列表。 |
| FOLLOWER_CONSTRAINTS | 仅适用于 follower 的约束列表。 |
| LEARNER_CONSTRAINTS | 仅适用于 learner 的约束列表。 |
| LEARNERS | 指定 learner 的数量。 |
12. 删除 placement policy
删除 placement policy 时一定要确保没有任何表在使用当前的 placement policy 否则会报错
(root\@127.0.0.1) \[test] 12:11:43> drop PLACEMENT POLICY jianplacementpolicy;
ERROR 8241 (HY000): Placement policy 'jianplacementpolicy' is still in use
(root\@127.0.0.1) \[test] 12:16:20> alter table jian1 PLACEMENT POLICY=default;
Query OK, 0 rows affected (0.08 sec)
查看某个 placement policy 是否正在被表使用
SELECT table\_schema, table\_name FROM information\_schema.tables WHERE tidb\_placement\_policy\_name='jianplacementpolicy';
SELECT table\_schema, table\_name FROM information\_schema.partitions WHERE tidb\_placement\_policy\_name='jianplacementpolicy';
总结
当前版本在使用 Placement Rules in SQL 时如果使用基本的放置规则那么只可以使用 PRIMARY_REGION 和 REGIONS 来进行放置规则的设置,但是如果使用高级放置规则那么 tikv 的 label 标签不需要必须设置 region 层级的标签,可以灵活使用和定义已存在或者需要的标签。
高级放置规则的默认 followers 的数量为 2,但是如果在设置规则 FOLLOWER_CONSTRAINTS 时如果满足的节点不满足 2 时只会在 FOLLOWER_CONSTRAINTS 匹配的节点上创建副本,这一点在创建时一定要规划好自己的集群中的 tikv 节点的标签设计,以免导致 region 的副本数过少。
Placement Rules in SQL 可以通过它对分区 / 表 / 库不同级别的数据进行基于标签的自由放置。
总之 TiDB 6.0 的 Placement Rules In SQL 暴露了以往用户无法控制的内部调度能力,并提供了方便的 SQL 接口,这开启了诸多以往不可能实现的场景,更多的运用方式与使用场景还期待各位的发掘。
边栏推荐
- 第五章:activiti流程分流判断,判断走不同的任务节点
- What are the standards for electrical engineering
- 60行从零开始自己动手写FutureTask是什么体验?
- UDP通信
- 教你本地编译运行一个IDEA插件,在IDEA里聊天、下棋、斗地主!
- 2022 Hangzhou Electric Power Multi-School Session 6 1008.Shinobu Loves Segment Tree Regular Questions
- Use KUSTO query statement (KQL) to query LOG on Azure Data Explorer Database
- SkiaSharp 之 WPF 自绘 投篮小游戏(案例版)
- [Strong Net Cup 2022] WP-UM
- Dynamics 365Online PDF导出及打印
猜你喜欢

脱光衣服待着就能减肥,当真有这好事?

GPU-CUDA-图形渲染分析

今天告诉你界面控件DevExpress WinForms为何弃用经典视觉样式
60行从零开始自己动手写FutureTask是什么体验?

一张图看懂 SQL 的各种 join 用法!
How to choose coins and determine the corresponding strategy research
Login function and logout function (St. Regis Takeaway)

Getting started with Polkadot parachain development, this article is enough

【MySQL基础】-【数据处理之增删改】
PCB布局必知必会:教你正确地布设运算放大器的电路板
随机推荐
Dynamics 365Online PDF导出及打印
FPGA: Use of the development environment Vivado
nyoj754 黑心医生 结构体优先队列
DocuWare平台——文档管理的内容服务和工作流自动化的平台详细介绍(下)
How to choose coins and determine the corresponding strategy research
上位机开发C#语言:模拟STC串口助手接收单片机发送数据
The host computer develops C# language: simulates the STC serial port assistant to receive the data sent by the microcontroller
【综合类型第 35 篇】程序员的七夕浪漫时刻
R语言使用yardstick包的pr_curve函数评估多分类(Multiclass)模型的性能、查看模型在多分类每个分类上的ROC曲线(precision(精准率),R代表的是recall(召回率)
第五章:redis持久化,包括rdb和aof两种方式[通俗易懂]
#yyds干货盘点#【愚公系列】2022年08月 Go教学课程 001-Go语言前提简介
拓朴排序例题
19.3 restart the Oracle environment
产品太多了,如何实现一次登录多产品互通?
linux下oracle常见操作以及日常积累知识点(函数、定时任务)
SMB + SMB2: Accessing shares return an error after prolonged idle period
【AGC】增长服务1-远程配置示例
[Translation] Chaos Net + SkyWalking: Better observability for chaos engineering
教你本地编译运行一个IDEA插件,在IDEA里聊天、下棋、斗地主!
Use KUSTO query statement (KQL) to query LOG on Azure Data Explorer Database