当前位置:网站首页>"Real" emotions dictionary based on the text sentiment analysis and LDA theme analysis
"Real" emotions dictionary based on the text sentiment analysis and LDA theme analysis
2022-07-31 00:59:00 【The young man who rides the wind】
——Based on text sentiment analysis in the field of e-commerceLDA主题分析——
一、情感分析
1.1Dictionary import
import os
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from matplotlib.pylab import style #自定义图表风格
style.use('ggplot')
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity = "all"
plt.rcParams['font.sans-serif'] = ['Simhei'] # 解决中文乱码问题
import re
import jieba.posseg as psg
import itertools
#conda install -c anaconda gensim
from gensim import corpora,models #主题挖掘,提取关键信息
# pip install wordcloud
from wordcloud import WordCloud,ImageColorGenerator
from collections import Counter
from sklearn.feature_extraction.text import CountVectorizer
review_long_clean = pd.read_excel('1_review_long_clean.xlsx') #Import the processed dataset
Import the evaluation sentiment dictionary
#A collection of words for sentiment analysis published by HowNet
pos_comment=pd.read_csv('./正面评价词语(中文).txt',header=None,sep='\n',encoding='utf-8')
neg_comment=pd.read_csv('./负面评价词语(中文).txt',header=None,sep='\n',encoding='utf-8')
pos_emotion=pd.read_csv('./正面情感词语(中文).txt',header=None,sep='\n',encoding='utf-8')
neg_emotion=pd.read_csv('./负面情感词语(中文).txt',header=None,sep='\n',encoding='utf-8')
Take a look at the positive and negative sentiment dictionary distribution
print('正面评价词语:',pos_comment.shape)
print('负面评价词语:',neg_comment.shape)
print('正面情感词语:',pos_emotion.shape)
print('负面情感词语:',neg_emotion.shape)
正面评价词语: (3743, 1)
负面评价词语: (3138, 1)
正面情感词语: (833, 1)
负面情感词语: (1251, 1)
#Combine positive and negative
pos=pd.concat([pos_comment,pos_emotion],axis=0)
print('After the front is merged:',pos.shape)
neg=pd.concat([neg_comment,neg_emotion],axis=0)
print('After a negative merger:',neg.shape)
After the front is merged: (4576, 1)
After a negative merger: (4389, 1)
1.2 增加新词
#Judgment is not in the dictionary
c='点赞'
print(c in pos.values)
d='歇菜'
print(d in neg.values)
False
False
Add it to the dictionary if you don't
#Add it to the dictionary if you don't
new_pos=pd.Series(['点赞'])
new_neg=pd.Series(['歇菜'])
positive=pd.concat([pos,new_pos],axis=0)
print(positive.shape)
negative=pd.concat([neg,new_neg],axis=0)
print(negative.shape)
#Store emotional words in,Dataframe中,And positive words are given weight1
positive.columns=['review']
positive['weight']=pd.Series([1]*len(positive))
positive.head()

#Store emotional words in,Dataframe中,And negative words are given weight-1
negative.columns=['review']
negative['weight']=pd.Series([-1]*len(negative))
negative.head()
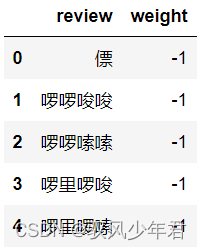
#Combine positive and negative sentiment words
pos_neg=pd.concat([positive,negative],axis=0)
pos_neg.shape
(8967, 2)
1.3合并到review_long_clean中
#表联接
#Clean up the data in a hurry,赋值给data
data=review_long_clean.copy()
print('data原始shape:',data.shape)
#将dataAnd the two tables of emotion words are combined into one,按照data的word列,Sentiment data followreview
review_mltype=pd.merge(data,pos_neg,how='left',left_on='word',right_on='review')
review_mltype.shape
print('After table joins are merged:',review_mltype.shape)
print('----------Complete the sentiment word assignment in the comment------------')
print('review_mltype:')
review_mltype.head()
data原始shape: (25172, 6)
After table joins are merged: (25172, 8)
----------Complete the sentiment word assignment in the comment------------
review_mltype:
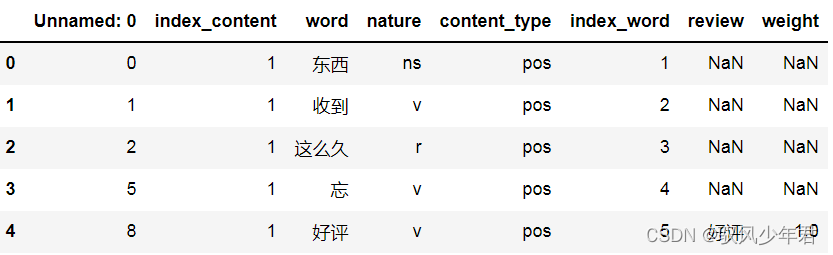
#Delete the sentiment value column,Also give words that are not emotional words,权重为0
review_mltype=review_mltype.drop(['review'],axis=1)
review_mltype=review_mltype.replace(np.nan,0)
review_mltype.head()

1.4 Correct emotional tendencies
If there are multiple negatives,Then the odd number negates the negative,Even negative is positive
Look before the emotional word2个词,to punish the negative tone.If at the beginning of the sentence,then there is no no,If in the second word of the sentence,look before1个词,to judge the negative tone.
#Read the negative word dictionary,Create a new columnfreq
notdict=pd.read_csv('./not.csv')
notdict.shape
notdict['freq']=[1]*len(notdict)
notdict.head()
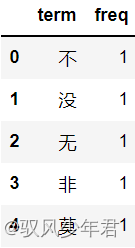
#准备一,构建amend_weight列,Its value is the same as the sentiment weight value
review_mltype['amend_weight']=review_mltype['weight']
#创建,id列,初始化值为0-to the last one,顺序值
review_mltype['id']=np.arange(0,review_mltype.shape[0])
review_mltype.head(10)
review_mltypeEmotionally weighted after sorting,全部评论数据
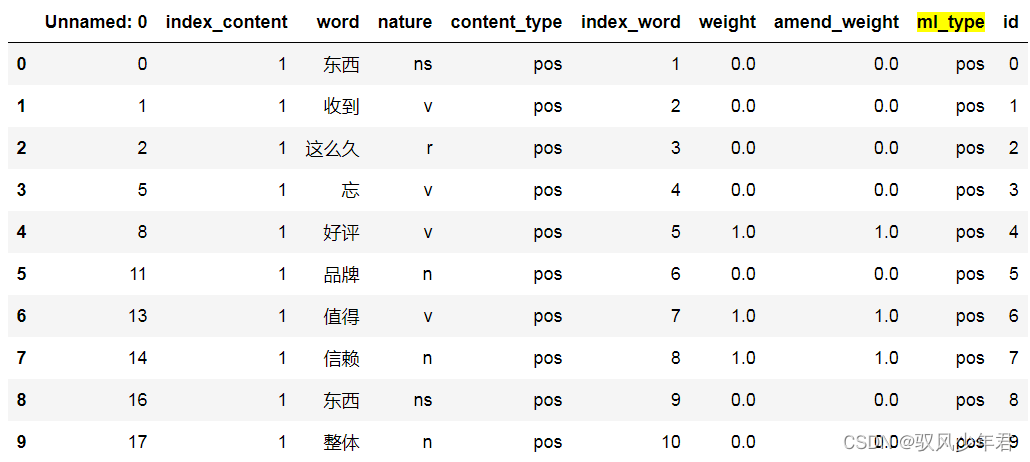
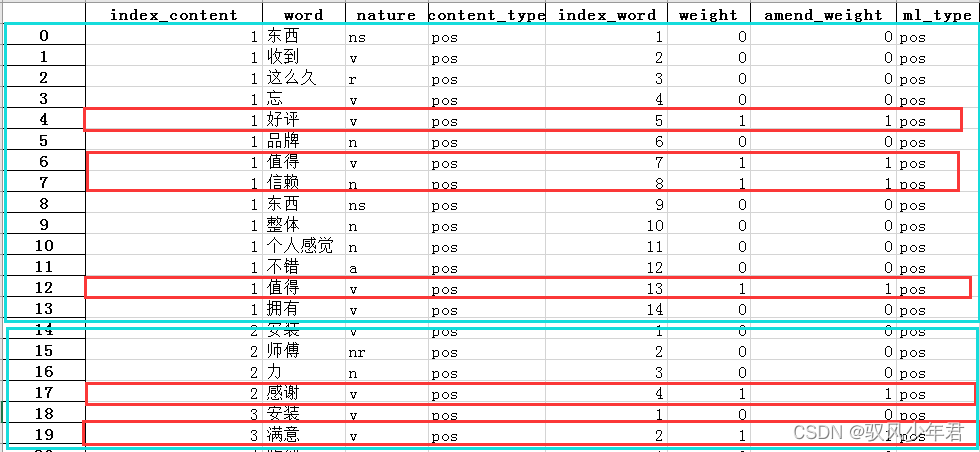
Only extract text with sentiment value
# 准备二,Only take out rows with sentiment value
only_review_mltype=review_mltype[review_mltype['weight']!=0]
#Only indices with sentiment values are kept
only_review_mltype.index=np.arange(0,only_review_mltype.shape[0]) #索引重置
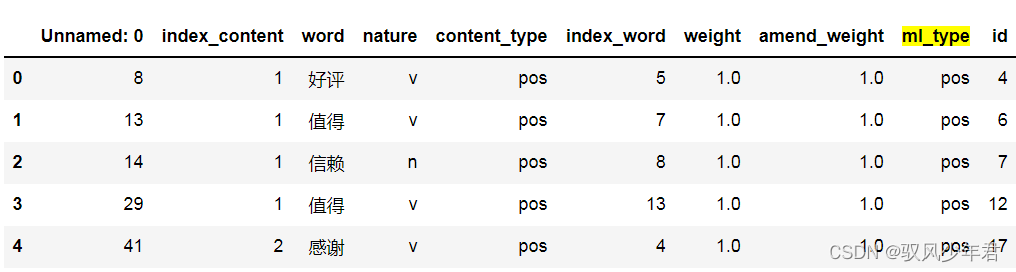
print(only_review_mltype.shape)
only_review_mltype.head()
(1526, 10)
Look before the emotional word2个词,to punish the negative tone.If at the beginning of the sentence,then there is no no,If in the second word of the sentence,look before1个词,to judge the negative tone.
#Look before the emotional word2个词,to punish the negative tone.If at the beginning of the sentence,then there is no no,If in the second word of the sentence,look before1个词,to judge the negative tone.
index=only_review_mltype['id']
for i in range(0,only_review_mltype.shape[0]):
review_i=review_mltype[review_mltype['index_content']==only_review_mltype['index_content'][i]] #第iComments on emotional words
review_i.index=np.arange(0,review_i.shape[0])#重置索引后,The index value is equivalent to index_word
word_ind = only_review_mltype['index_word'][i] #第isentiment value in the position of the comment
#第一种,在句首.则不用判断
#第二种,in the comments section2is the location
if word_ind==2:
ne=sum( [ review_i['word'][word_ind-1] in notdict['term'] ] )
if ne==1:
review_mltype['amend_weight'][index[i]] = -( review_mltype['weight'][index[i]] )
#第三种,in the comments section2个位置以后
elif word_ind > 2:
ne=sum( [ word in notdict['term'] for word in review_i['word'][[word_ind-1,word_ind-2]] ] ) # Note the use of square brackets[word_ind-1,word_ind-2]
if ne==1:
review_mltype['amend_weight'][index[i]]=- ( review_mltype['weight'][index[i]] )
review_mltype.shape
review_mltype[(review_mltype['weight']-review_mltype['amend_weight'])!=0] #Indicates that the two columns have the same value
1.5Calculate the sentiment value of each comment
Calculate all sentiment values in a text,adding up to one piece.
emotion_value=review_mltype.groupby('index_content',as_index=False)['amend_weight'].sum()
emotion_value.head()
emotion_value.to_csv('./1_emotion_value.csv',index=True,header=True)

1.6 View sentiment analysis performance
#per commentamend_weightThe sum is not equal to zero
content_emotion_value=emotion_value.copy()
content_emotion_value.shape
#取出不等于0的的文本
content_emotion_value=content_emotion_value[content_emotion_value['amend_weight']!=0]
#Set emotional tendencies
content_emotion_value['ml_type']=''
content_emotion_value['ml_type'][content_emotion_value['amend_weight']>0]='pos'
content_emotion_value['ml_type'][content_emotion_value['amend_weight']<0]='neg'
content_emotion_value.shape
content_emotion_value.head()

二、Sentiment analysis effect
读取原始数据
#读取原始数据
raw_data=pd.read_csv('./reviews.csv')
raw_data.head()
方法缺陷:
#per commentamend_weight总和等于零
#This method doesn't really work,More than half of the comments are indistinguishable、负情感.
content_emotion_value0=emotion_value.copy()
content_emotion_value0=content_emotion_value0[content_emotion_value0['amend_weight']==0]
content_emotion_value0.head()
raw_data.content[6]
raw_data.content[7]
raw_data.content[8]
2.1 将数据合并
Sentiment analysis results,merge with the original dataset:
#Merge into large tables
content_emotion_value=content_emotion_value.drop(['amend_weight'],axis=1)
review_mltype.shape
review_mltype=pd.merge(review_mltype,content_emotion_value,how='left',left_on='index_content',right_on='index_content')
review_mltype=review_mltype.drop(['id'],axis=1)
review_mltype.shape
review_mltype.head()
review_mltype.to_csv('./1_review_mltype',index=True,header=True)
2.2 结果对比
Compare with the real value,The accuracy of sentiment analysis results:
cate=['index_content','content_type','ml_type']
data_type=review_mltype[cate].drop_duplicates()
confusion_matrix=pd.crosstab(data_type['content_type'],data_type['ml_type'],margins=True)
confusion_matrix

data=data_type[['content_type','ml_type']]
data=data.dropna(axis=0)
print( classification_report(data['content_type'],data['ml_type']) )
precision recall f1-score support
neg 0.90 0.87 0.88 437
pos 0.89 0.92 0.90 501
accuracy 0.89 938
macro avg 0.90 0.89 0.89 938
weighted avg 0.89 0.89 0.89 938
2.3 Emotion word cloud
Categorize text by sentiment,Then count the word cloud
data=review_mltype.copy()
word_data_pos=data[data['ml_type']=='pos']
word_data_neg=data[data['ml_type']=='neg']
font=r"C:\Windows\Fonts\msyh.ttc"
background_image=plt.imread('./pl.jpg')
wordcloud = WordCloud(font_path=font, max_words = 100, mode='RGBA' ,background_color='white',mask=background_image) #width=1600,height=1200
wordcloud.generate_from_frequencies(Counter(word_data_pos.word.values))
plt.figure(figsize=(15,7))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()
background_image=plt.imread('./pl.jpg')
wordcloud = WordCloud(font_path=font, max_words = 100, mode='RGBA' ,background_color='white',mask=background_image) #width=1600,height=1200
wordcloud.generate_from_frequencies(Counter(word_data_neg.word.values))
plt.figure(figsize=(15,7))
plt.imshow(wordcloud)
plt.axis('off')
plt.show()


三、基于LDA模型的主题分析
优点:No manual debugging is required,Find the optimal topic structure with relatively few iterations.
3.1建立词典、语料库
data=review_mltype.copy()
word_data_pos=data[data['ml_type']=='pos']
word_data_neg=data[data['ml_type']=='neg']
#建立词典,去重
pos_dict=corpora.Dictionary([ [i] for i in word_data_pos.word]) #shape=(n,1)
neg_dict=corpora.Dictionary([ [i] for i in word_data_neg.word])
#建立语料库
pos_corpus=[ pos_dict.doc2bow(j) for j in [ [i] for i in word_data_pos.word] ] #shape=(n,(2,1))
neg_corpus=[ neg_dict.doc2bow(j) for j in [ [i] for i in word_data_neg.word] ]
3.2Optimizing the number of topics
#Construct the number of topics optimization function
def cos(vector1,vector2):
''' 函数功能:Cosine similarity function '''
dot_product=0.0
normA=0.0
normB=0.0
for a,b in zip(vector1,vector2):
dot_product +=a*b
normA +=a**2
normB +=b**2
if normA==0.0 or normB==0.0:
return None
else:
return ( dot_product/((normA*normB)**0.5) )
#Optimizing the number of topics
#这个函数可以重复调用,Solve problems with other projects
def LDA_k(x_corpus,x_dict):
''' 函数功能: '''
#Initialize the average cosine similarity
mean_similarity=[]
mean_similarity.append(1)
#Loop to generate topics and calculate the similarity between topics
for i in np.arange(2,11):
lda=models.LdaModel(x_corpus,num_topics=i,id2word=x_dict) #LDA模型训练
for j in np.arange(i):
term=lda.show_topics(num_words=50)
#Extract each subject term
top_word=[] #shape=(i,50)
for k in np.arange(i):
top_word.append( [''.join(re.findall('"(.*)"',i)) for i in term[k][1].split('+')]) #列出所有词
#Construct word frequency vectors
word=sum(top_word,[]) #Train all words
unique_word=set(word) #去重
#Construct a list of subject headings,Lines represent topic numbers,Columns represent each subject heading
mat=[] #shape=(i,len(unique_word))
for j in np.arange(i):
top_w=top_word[j]
mat.append( tuple([ top_w.count(k) for k in unique_word ])) #统计listThe frequency of elements in ,返回元组
#两两组合.方法一
p=list(itertools.permutations(list(np.arange(i)),2)) #返回可迭代对象的所有数学全排列方式.
y=len(p) # y=i*(i-1)
top_similarity=[0]
for w in np.arange(y):
vector1=mat[p[w][0]]
vector2=mat[p[w][1]]
top_similarity.append(cos(vector1,vector2))
# #两两组合,方法二
# for x in range(i-1):
# for y in range(x,i):
#Calculate the average cosine similarity
mean_similarity.append(sum(top_similarity)/ y)
return mean_similarity
#Calculate the average cosmic similarity of topics
pos_k=LDA_k(pos_corpus,pos_dict)
neg_k=LDA_k(neg_corpus,neg_dict)
pos_k
neg_k
[1,
0.04,
0.006666666666666667,
0.0033333333333333335,
0.0,
0.004,
0.006666666666666666,
0.025000000000000015,
0.03500000000000002,
0.046222222222222234]
[1,
0.02,
0.0,
0.0,
0.0,
0.0026666666666666666,
0.002857142857142857,
0.0035714285714285718,
0.01333333333333334,
0.022222222222222233]
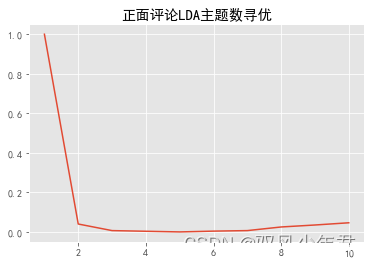
pd.Series(pos_k,index=range(1,11)).plot()
plt.title('正面评论LDAOptimizing the number of topics')
plt.show()
<matplotlib.axes._subplots.AxesSubplot at 0x1de4b888>
Text(0.5, 1.0, ‘正面评论LDAOptimizing the number of topics’)
pd.Series(neg_k,index=range(1,11)).plot()
plt.title('负面评论LDAOptimizing the number of topics')
plt.show()
matplotlib.axes._subplots.AxesSubplot at 0x1d077ac8>
Text(0.5, 1.0, ‘负面评论LDAOptimizing the number of topics’)

Determine the number of positive and negative topics3
pos_lda=models.LdaModel(pos_corpus,num_topics=2,id2word=pos_dict)
neg_lda=models.LdaModel(neg_corpus,num_topics=2,id2word=neg_dict)
pos_lda.print_topics(num_topics=10)
neg_lda.print_topics(num_topics=10)
[(0,
‘0.085*“安装” + 0.036*“满意” + 0.019*“服务” + 0.018*“不错” + 0.015*“好评” + 0.012*“客服” + 0.011*“人员” + 0.010*“物流” + 0.009*“送” + 0.008*“家里”’),
(1,
‘0.024*“师傅” + 0.021*“送货” + 0.019*“很快” + 0.016*“值得” + 0.013*“售后” + 0.012*“信赖” + 0.012*“东西” + 0.009*“太” + 0.009*“购物” + 0.009*“电话”’)]
[(0,
‘0.089*“安装” + 0.018*“师傅” + 0.015*“慢” + 0.013*“装” + 0.011*“打电话” + 0.011*“太慢” + 0.008*“坑人” + 0.008*“服务” + 0.007*“配件” + 0.007*“问”’),
(1,
‘0.021*“垃圾” + 0.019*“太” + 0.019*“差” + 0.016*“安装费” + 0.015*“售后” + 0.014*“东西” + 0.013*“不好” + 0.013*“客服” + 0.012*“加热” + 0.012*“小时”’)]
边栏推荐
- ECCV 2022丨轻量级模型架构火了,力压苹果MobileViT(附代码和论文下载)
- DOM系列之 client 系列
- The sword refers to offer17---print the n digits from 1 to the largest
- 小程序-全局数据共享
- 【Yugong Series】July 2022 Go Teaching Course 017-IF of Branch Structure
- Typescript14 - (type) of the specified parameters and return values alone
- 这个项目太有极客范儿了
- 剑指offer17---打印从1到最大的n位数
- MySQL database advanced articles
- MySQL database (basic)
猜你喜欢

Mysql: Invalid default value for TIMESTAMP

TypeScript在使用中出现的问题记录

孩子的编程启蒙好伙伴,自己动手打造小世界,长毛象教育AI百变编程积木套件上手

typescript9-常用基础类型
Problem record in the use of TypeScript
Mysql:Invalid default value for TIMESTAMP

Unity2D horizontal version game tutorial 4 - item collection and physical materials

Mysql systemized JOIN operation example analysis

ECCV 2022丨轻量级模型架构火了,力压苹果MobileViT(附代码和论文下载)

网站频繁出现mysql等数据库连接失败等信息解决办法
随机推荐
这个项目太有极客范儿了
【愚公系列】2022年07月 Go教学课程 017-分支结构之IF
Yolov7实战,实现网页端的实时目标检测
解析云原生消息流系统 Apache Pulsar 能力及场景
蓝牙mesh系统开发三 Ble Mesh 配网器 Provisioner
MySQL database (basic)
MySQL高级-六索引优化
typescript10-commonly used basic types
typescript15- (specify both parameter and return value types)
Rocky/GNU之Zabbix部署(2)
Problem record in the use of TypeScript
Artificial Intelligence and Cloud Security
ECCV 2022丨轻量级模型架构火了,力压苹果MobileViT(附代码和论文下载)
【952. 按公因数计算最大组件大小】
网站频繁出现mysql等数据库连接失败等信息解决办法
Why use high-defense CDN when financial, government and enterprises are attacked?
redis学习
DOM系列之动画函数封装
分布式系统的一致性与共识(1)-综述
SWM32 Series Tutorial 6 - Systick and PWM