当前位置:网站首页>MySQL高级-六索引优化
MySQL高级-六索引优化
2022-07-31 00:44:00 【嘟哇嘟】
数据库优化方案
- 索引失效,没有充分利用到索引:
索引建立 - 关联查询太多JOIN(设计缺陷或不得已的需求):
SQL优化 - 数据过多:分库分表
- 服务器调/优及各个参数设置(缓冲、线程数等):调整my.cnf
性能分析-explain
1、explain 是什么?
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
2、explain 的用法
explain sql语句
数据准备
use dudu;
create table t1(id int(10) auto_increment, content varchar(100) null, primary key (id));
create table t2(id int(10) auto_increment, content varchar(100) null, primary key (id));
create table t3(id int(10) auto_increment, content varchar(100) null, primary key (id));
create table t4(id int(10) auto_increment, content1 varchar(100) null, content2 varchar(100) null, primary key (id));
create index idx_content1 on t4(content1); -- 普通索引
# 以下新增sql多执行几次,以便演示
insert into t1(content) values(concat('t1_',floor(1+rand()*1000)));
insert into t2(content) values(concat('t2_',floor(1+rand()*1000)));
insert into t3(content) values(concat('t3_',floor(1+rand()*1000)));
insert into t4(content1, content2) values(concat('t4_',floor(1+rand()*1000)), concat('t4_',floor(1+rand()*1000)));
各字段解释
table
单表:显示这一行的数据是关于哪张表的
explain select *from t1;

多表关联:t1为驱动表,t2为被驱动表。
注意:内连接时,MySQL性能优化器会自动判断哪个表是驱动表,哪个表示被驱动表,和书写的顺序无关

id
表示查询中执行select子句或操作表的顺序
id相同:执行顺序由上至下
id不同:如果是子查询,id的序号会递增,id值越大优先级越高,越先被执行
explain select t1.id from t1 where t1.id =(
select t2.id from t2 where t2.id =(
select t3.id from t3 where t3.content = 't3_434'
)
);

注意:查询优化器可能对涉及子查询的语句进行优化,转为连接查询`
explain select * from t1 where content in (select content from t2 where content = 'a');

id为null:最后执行
explain select * from t1 union select * from t2;

小结:
- id如果相同,可以认为是一组,从上往下顺序执行
- 在所有组中,id值越大,优先级越高,越先执行
- 关注点:id号每个号码,表示一趟独立的查询, 一个sql的查询趟数越少越好
select_type
查询的类型,主要是用于区别普通查询、联合查询、子查询等的复杂查询。
SIMPLE
简单查询。查询中不包含子查询或者UNION。
explain select *from t1;

PRIMARY:
主查询。查询中若包含子查询,则最外层查询被标记为PRIMARY。
SUBQUERY:
子查询。在select或where列表中包含了子查询。
explain select * from t3 where id = ( select id from t2 where content= 'a');

DEPENDENT SUBQUREY:
如果包含了子查询,并且查询语句不能被优化器转换为连接查询,并且子查询是 相关子查询(子查询基于外部数据列),则子查询就是DEPENDENT SUBQUREY。
explain select * from t3 where id = ( select id from t2 where content = t3.content);

UNCACHEABLE SUBQUREY:
表示这个subquery的查询要受到外部系统变量的影响
explain select * from t3 where id = ( select id from t2 where content = @@character_set_server);

UNION:
对于包含UNION或者UNION ALL的查询语句,除了最左边的查询是PRIMARY,其余的查询都是UNION。
UNION RESULT:
UNION会对查询结果进行查询去重,MYSQL会使用临时表来完成UNION查询的去重工作,针对这个临时表的查询就是"UNION RESULT"。
explain select * from t3 where id = 1 union select * from t2 where id = 1;

DEPENDENT UNION:
子查询中的UNION或者UNION ALL,除了最左边的查询是DEPENDENT SUBQUREY,其余的查询都是DEPENDENT UNION。
explain select * from t1 where content in (select content from t2 union select content from t3);

DERIVED:
在包含派生表(子查询在from子句中)的查询中,MySQL会递归执行这些子查询,把结果放在临时表里。
explain select * from (select content, count(*) as c from t1 group by content) as derived_t1 where c > 1;
这里的<derived2>就是在id为2的查询中产生的派生表。
补充:MySQL在处理带有派生表的语句时,优先尝试把派生表和外层查询进行合并,如果不行,再把派生表物化掉(执行子查询,并把结果放入临时表),然后执行查询。下面的例子就是就是将派生表和外层查询进行合并的例子:
explain select * from (select * from t1 where content = 't1_832') as derived_t1;

MATERIALIZED:
优化器对于包含子查询的语句,如果选择将子查询物化后再与外层查询连接查询,该子查询的类型就是MATERIALIZED。如下的例子中,查询优化器先将子查询转换成物化表,然后将t1和物化表进行连接查询。将select content from t2结果作为条件
explain select * from t1 where content in (select content from t2);

partitions
代表分区表中的命中情况,非分区表,该项为NULL
type *
说明:
结果值从最好到最坏依次是:
system > const > eq_ref > ref> fulltext > ref_or_null > index_merge
unique_subquery > index_subquery >range > index > ALL
比较重要的包含:system、const 、eq_ref 、ref、range > index > ALLSQL 性能优化的目标:至少要达到
range级别,要求是ref级别,最好是consts级别。(阿里巴巴 开发手册要求)
ALL
全表扫描。Full Table Scan,将遍历全表以找到匹配的行
explain select *from t1;

index
当使用覆盖索引,但需要扫描全部的索引记录时
覆盖索引:`如果能通过读取索引就可以得到想要的数据,那就不需要读取用户记录,或者不用再做回表操作了。一个索引包含了满足查询结果的数据就叫做覆盖索引。
-- 只需要读取聚簇索引部分的非叶子节点,就可以得到id的值,不需要查询叶子节点
explain select id from t1;

-- 只需要读取二级索引,就可以在二级索引中获取到想要的数据,不需要再根据叶子节点中的id做回表操作
explain select id, deptId from t_emp;

range
只检索给定范围的行,使用一个索引来选择行。key 列显示使用了哪个索引,一般就是在你的where语句中出现了between、<、>、in等的查询。这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不用扫描全部索引。
explain select * from t1 where id in (1, 2, 3);

ref
通过普通二级索引列与常量进行等值匹配时
explain select * from t_emp where deptid = 1;

eq_ref
连接查询时通过主键或不允许NULL值的唯一二级索引列进行等值匹配时
explain select * from t1, t2 where t1.id = t2.id;

const
根据主键或者唯一二级索引列与常数进行匹配时
explain select * from t1 where id = 1;

system
MyISAM引擎中,当表中只有一条记录时。(这是所有type的值中性能最高的场景)
create table t(i int) engine=myisam;
insert into t values(1);
explain select * from t;

其他不太常见的类型(了解
index_subquery:利用普通索引来关联子查询,针对包含有IN子查询的查询语句。content1是普通索引字段
explain select * from t1 where content in (select content1 from t4 where t1.content = t4.content2) or content = 'a';

unique_subquery:类似于index_subquery,利用唯一索引来关联子查询。t2的id是主键,也可以理解为唯一的索引字段
explain select * from t1 where id in (select id from t2 where t1.content = t2.content) or content = 'a';

index_merge:在查询过程中需要多个索引组合使用,通常出现在有 or 的关键字的sql中。
explain select * from t_emp where deptid = 1 or id = 1;

ref_or_null:当对普通二级索引进行等值匹配,且该索引列的值也可以是NULL值时。
explain select * from t_emp where deptid = 1 or deptid is null;

**fulltext:**全文索引。一般通过搜索引擎实现,这里我们不展开。
possible_keys 和 keys ***
possible_keys表示执行查询时可能用到的索引,一个或多个。 查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用。keys表示实际使用的索引。如果为NULL,则没有使用索引。
explain select id from t1 where id = 1;

key_len *
表示索引使用的字节数,根据这个值可以判断索引的使用情况,检查是否充分利用了索引,针对联合索引值越大越好。
如何计算:
- 先看索引上字段的类型+长度。比如:int=4 ; varchar(20) =20 ; char(20) =20
- 如果是varchar或者char这种字符串字段,视字符集要乘不同的值,比如utf8要乘 3,如果是utf8mb4要乘4,GBK要乘2
- varchar这种动态字符串要加2个字节
- 允许为空的字段要加1个字节
-- 创建索引
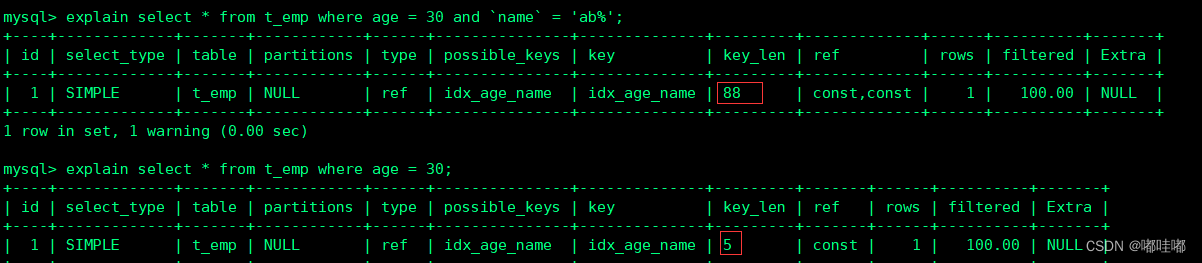
create index idx_age_name on t_emp(age, `name`);
-- 测试1
explain select * from t_emp where age = 30 and `name` = 'ab%';
-- 测试2
explain select * from t_emp where age = 30;
ref
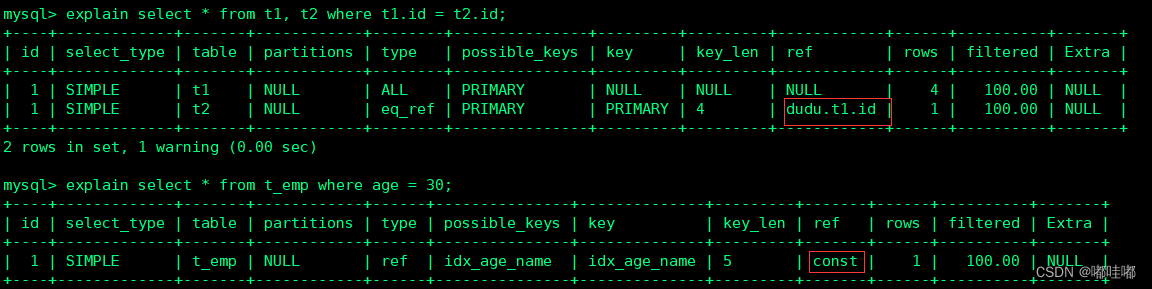
显示与key中的索引进行比较的列或常量。
-- ref=dudu.t1.id 关联查询时出现,t2表和t1表的哪一列进行关联
explain select * from t1, t2 where t1.id = t2.id;
-- ref=const 与索引列进行等值比较的东西是啥,const表示一个常数
explain select * from t_emp where age = 30;
rows *
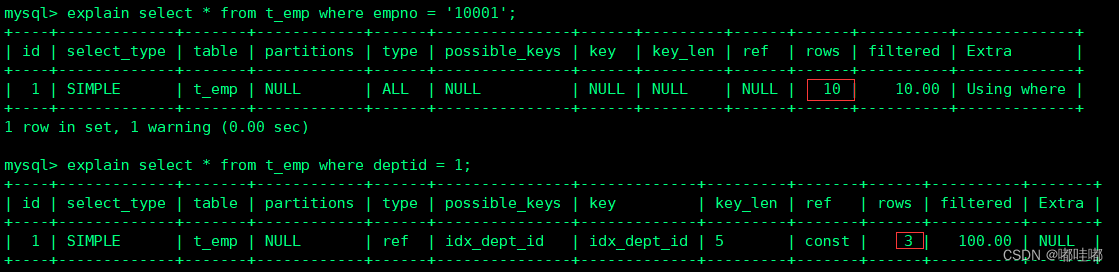
MySQL认为它执行查询时必须检查的行数。值越小越好。
-- 如果是全表扫描,rows的值就是表中数据的估计行数
explain select * from t_emp where empno = '10001';
-- 如果是使用索引查询,rows的值就是预计扫描索引记录行数
explain select * from t_emp where deptid = 1;
filtered
最后查询出来的数据占所有服务器端检查行数(rows)的百分比。值越大越好。
-- 先根据二级索引deptid找到数据的主键,有3条记录满足条件,
-- 再根据主键进行回表,最终找到3条记录,有100%的记录满足条件
explain select * from t_emp where deptid = 1;
-- 这个例子如果name列是索引列则 filtered = 100 否则filtered = 10(全表扫描)
explain select * from t_emp where `name` = '风清扬';

Extra *
包含不适合在其他列中显示但十分重要的额外信息。通过这些额外信息来理解MySQL到底将如何执行当前的查询语句。MySQL提供的额外信息有好几十个,这里只挑介绍比较重要的介绍。
Impossible WHERE:
where子句的值总是false
explain select * from t_emp where 1 != 1;

Using where
使用了where,但在where上有字段没有创建索引
explain select * from t_emp where `name` = '风清扬';

Using temporary
使了用临时表保存中间结果
explain select distinct content from t1;

Using filesort
在对查询结果中的记录进行排序时,是可以使用索引的,如下所示:
explain select * from t1 order by id;

如果排序操作无法使用到索引,只能在内存中(记录较少时)或者磁盘中(记录较多时)进行排序(filesort),如下所示:
explain select * from t1 order by content;

Using index
使用了覆盖索引,表示直接访问索引就足够获取到所需要的数据,不需要通过索引回表
explain select id, content1 from t4;

explain select id from t1;

Using index condition
简单地说就是先把所有条件都查出来再进行回表
叫作 Index Condition Pushdown Optimization (索引下推优化)
如果没有索引下推(ICP),那么MySQL在存储引擎层找到满足content1 > 'z'条件的第一条二级索引记录。主键值进行回表,返回完整的记录给server层,server层再判断其他的搜索条件是否成立。如果成立则保留该记录,否则跳过该记录,然后向存储引擎层要下一条记录。如果使用了索引下推(ICP),那么MySQL在存储引擎层找到满足content1 > 'z'条件的第一条二级索引记录。不着急执行回表,而是在这条记录上先判断一下所有关于idx_content1索引中包含的条件是否成立,也就是content1 > 'z' AND content1 LIKE '%a'是否成立。如果这些条件不成立,则直接跳过该二级索引记录,去找下一条二级索引记录;如果这些条件成立,则执行回表操作,返回完整的记录给server层。
-- content1列上有索引idx_content1
explain select * from t4 where content1 > 'z' and content1 like '%a';

注意如果这里的查询条件只有content1 > 'z',那么找到满足条件的索引后也会进行一次索引下推的操作,判断content1 > 'z’是否成立(这是源码中为了编程方便做的冗余判断)
Using join buffer
在连接查询时,当被驱动表不能有效的利用索引时,MySQL会提前申请一块内存空间(join buffer)来加快查询速度
explain select * from t1, t2 where t1.content = t2.content;

下面这个例子就是被驱动表使用了索引:
explain select * from t_emp, t_dept where t_dept.id = t_emp.deptid;

课外阅读:`在没有索引的情况下,为了优化多表连接,减少磁盘IO读取次数和数据遍历次数,MySQL为我们提供了很多不同的连接缓存的优化算法,可参考
链接: https://blog.csdn.net/qq_35423190/article/details/120504960
Using join buffer (hash join)**8.0新增:**连接缓存(hash连接)速度更快Using join buffer (Block Nested Loop)5.7:连接缓存(块嵌套循环)
准备数据
在做优化之前,要准备大量数据。接下来创建两张表,并往员工表里插入50W数据,部门表中插入1W条数据。
怎么快速插入50w条数据呢? 存储过程
怎么保证插入的数据不重复?函数
部门表:
id:自增长
deptName:随机字符串,允许重复
address:随机字符串,允许重复
CEO:1-50w之间的任意数字
员工表:
- id:自增长
- empno:可以使用随机数字,或者
从1开始的自增数字,不允许重复 - name:随机生成,允许姓名重复
- age:区间随机数
- deptId:1-1w之间随机数
**总结:**需要产生随机字符串和区间随机数的函数。
创建表
CREATE TABLE `dept` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`deptName` VARCHAR(30) DEFAULT NULL,
`address` VARCHAR(40) DEFAULT NULL,
ceo INT NULL ,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1;
CREATE TABLE `emp` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`empno` INT NOT NULL ,
`name` VARCHAR(20) DEFAULT NULL,
`age` INT(3) DEFAULT NULL,
`deptId` INT(11) DEFAULT NULL,
PRIMARY KEY (`id`)
#CONSTRAINT `fk_dept_id` FOREIGN KEY (`deptId`) REFERENCES `t_dept` (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1;
创建函数
-- 查看mysql是否允许创建函数:
SHOW VARIABLES LIKE 'log_bin_trust_function_creators';
-- 命令开启:允许创建函数设置:(global-所有session都生效)
SET GLOBAL log_bin_trust_function_creators=1;
-- 随机产生字符串
DELIMITER $$
CREATE FUNCTION rand_string(n INT) RETURNS VARCHAR(255)
BEGIN
DECLARE chars_str VARCHAR(100) DEFAULT 'abcdefghijklmnopqrstuvwxyzABCDEFJHIJKLMNOPQRSTUVWXYZ';
DECLARE return_str VARCHAR(255) DEFAULT '';
DECLARE i INT DEFAULT 0;
WHILE i < n DO
SET return_str =CONCAT(return_str,SUBSTRING(chars_str,FLOOR(1+RAND()*52),1));
SET i = i + 1;
END WHILE;
RETURN return_str;
END $$
-- 假如要删除
-- drop function rand_string;
-- 用于随机产生区间数字
DELIMITER $$
CREATE FUNCTION rand_num (from_num INT ,to_num INT) RETURNS INT(11)
BEGIN
DECLARE i INT DEFAULT 0;
SET i = FLOOR(from_num +RAND()*(to_num -from_num+1));
RETURN i;
END$$
-- 假如要删除
-- drop function rand_num;
创建存储过程
-- 插入员工数据
DELIMITER $$
CREATE PROCEDURE insert_emp(START INT, max_num INT)
BEGIN
DECLARE i INT DEFAULT 0;
#set autocommit =0 把autocommit设置成0
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO emp (empno, NAME, age, deptid ) VALUES ((START+i) ,rand_string(6), rand_num(30,50), rand_num(1,10000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END$$
-- 删除
-- DELIMITER ;
-- drop PROCEDURE insert_emp;
-- 插入部门数据
DELIMITER $$
CREATE PROCEDURE insert_dept(max_num INT)
BEGIN
DECLARE i INT DEFAULT 0;
SET autocommit = 0;
REPEAT
SET i = i + 1;
INSERT INTO dept ( deptname,address,ceo ) VALUES (rand_string(8),rand_string(10),rand_num(1,500000));
UNTIL i = max_num
END REPEAT;
COMMIT;
END$$
-- 删除
-- DELIMITER ;
-- drop PROCEDURE insert_dept;
调用存储过程
-- 执行存储过程,往dept表添加1万条数据
CALL insert_dept(10000);
-- 执行存储过程,往emp表添加50万条数据,编号从100000开始
CALL insert_emp(100000,500000);
批量删除表索引
DELIMITER $$
CREATE PROCEDURE `proc_drop_index`(dbname VARCHAR(200),tablename VARCHAR(200))
BEGIN
DECLARE done INT DEFAULT 0;
DECLARE ct INT DEFAULT 0;
DECLARE _index VARCHAR(200) DEFAULT '';
DECLARE _cur CURSOR FOR SELECT index_name FROM information_schema.STATISTICS WHERE table_schema=dbname AND table_name=tablename AND seq_in_index=1 AND index_name <>'PRIMARY' ;
#每个游标必须使用不同的declare continue handler for not found set done=1来控制游标的结束
DECLARE CONTINUE HANDLER FOR NOT FOUND set done=2 ;
#若没有数据返回,程序继续,并将变量done设为2
OPEN _cur;
FETCH _cur INTO _index;
WHILE _index<>'' DO
SET @str = CONCAT("drop index " , _index , " on " , tablename );
PREPARE sql_str FROM @str ;
EXECUTE sql_str;
DEALLOCATE PREPARE sql_str;
SET _index='';
FETCH _cur INTO _index;
END WHILE;
CLOSE _cur;
END$$
-- 执行批量删除(索引):dbname 库名称, tablename 表名称
CALL proc_drop_index("dbname","tablename");
开启SQL执行时间的显示
为了方便后面的测试中随时查看SQL运行的时间,测试索引优化后的效果,我们开启profiling
-- 显示sql语句执行时间
SET profiling = 1;
SHOW VARIABLES LIKE '%profiling%';
SHOW PROFILES;
单表索引失效案例
MySQL中提高性能的一个最有效的方式是对数据表设计合理的索引。索引提供了高效访问数据的方法,并且加快查询的速度,因此索引对查询的速度有着至关重要的影响。
我们创建索引后,用不用索引,最终是优化器说了算。优化器会基于开销选择索引,怎么开销小就怎么来。不是基于规则,也不是基于语义。
另外SQL语句是否使用索引,和数据库的版本、数据量、数据选择度(查询中选择的列数)都有关系。
-- 创建索引
create index idx_name on emp(`name`);
计算、函数导致索引失效
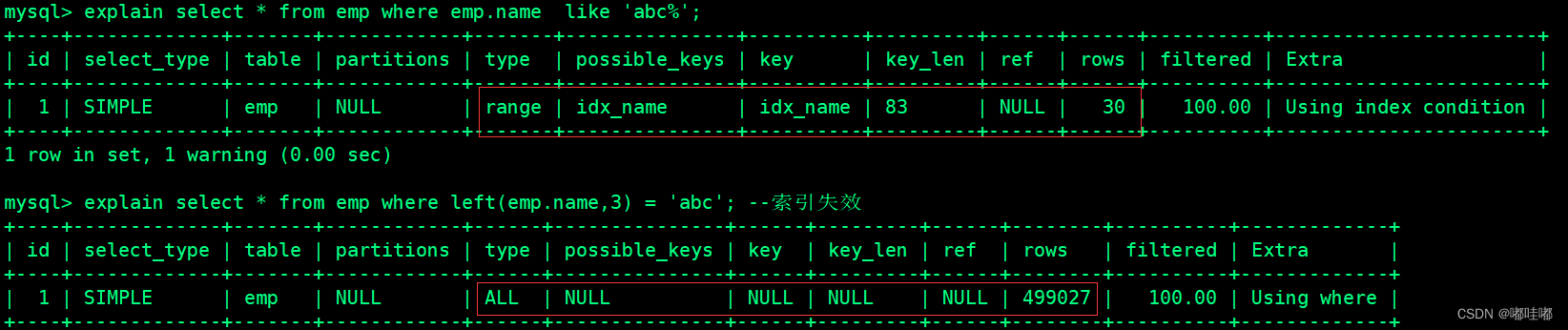
-- 显示查询分析
explain select * from emp where emp.name like 'abc%';
explain select * from emp where left(emp.name,3) = 'abc'; --索引失效
LIKE以%开头索引失效
explain select * from emp where name like '%ab%'; --索引失效

索引是根据左边的查的模糊了就找不到了
拓展:Alibaba《Java开发手册》**
【强制】页面搜索严禁左模糊或者全模糊,如果需要请走搜索引擎来解决。
不等于(!= 或者<>)索引失效
explain select sql_no_cache * from emp where emp.name = 'abc' ;
explain select sql_no_cache * from emp where emp.name <> 'abc' ; --索引失效


IS NOT NULL 和 IS NULL
explain select * from emp where emp.name is null;
explain select * from emp where emp.name is not null; --索引失效
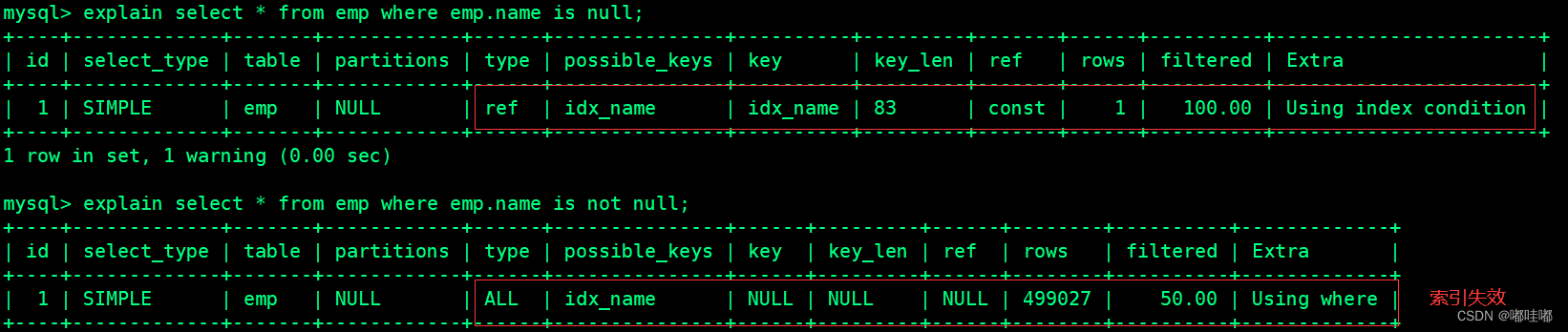
注意:当数据库中的数据的索引列的NULL值达到比较高的比例的时候,即使在IS NOT NULL 的情况下 MySQL的查询优化器会选择使用索引,此时type的值是range(范围查询)
-- 将 id>20000 的数据的 name 值改为 null
update emp set `name` = null where `id` > 20000;
-- 执行查询分析,可以发现 is not null 使用了索引
-- 具体多少条记录的值为null可以使索引在is not null的情况下生效,由查询优化器的算法决定
explain select * from emp where emp.name is not null;

测试完将name的值改回来
update emp set `name` = rand_string(6) where `id` > 20000;
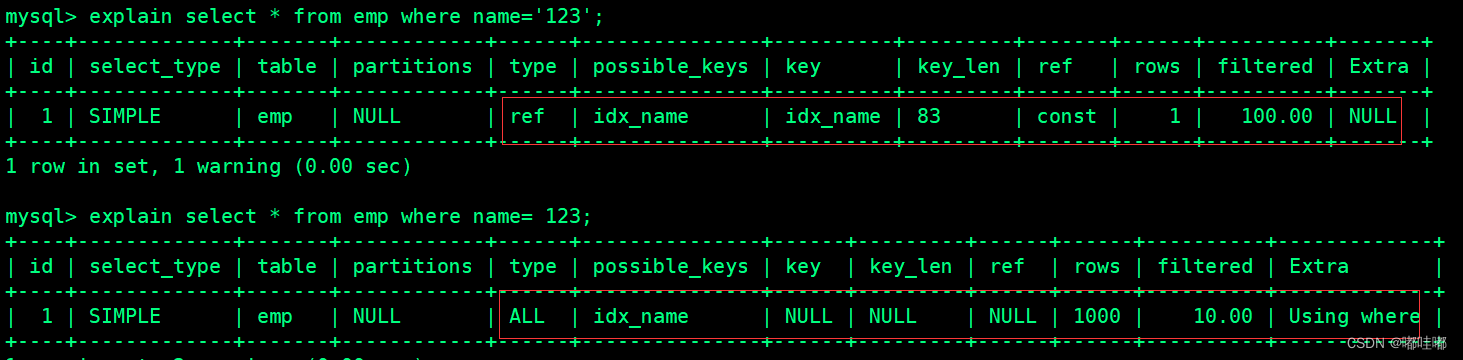
类型转换导致索引失效
explain select * from emp where name='123';
explain select * from emp where name= 123; --索引失效
全值匹配(最常用)
准备:
-- 首先删除之前创建的索引
call proc_drop_index("dudu","emp");
问题为以下查询语句创建哪种索引效率最高
-- 查询分析
explain select * from emp where emp.age = 30 and deptid = 4 and emp.name = 'abcd';
-- 执行sql
select * from emp where emp.age = 30 and deptid = 4 and emp.name = 'abcd';
-- 查看执行时间
show profiles;
创建索引并重新执行以上测试:
-- 创建索引:分别创建以下三种索引的一种,并分别进行以上查询分析
create index idx_age_deptid_name on emp(age,deptid,`name`);

结论可以发现最高效的查询应用了联合索引 idx_age_deptid_name
最佳左前缀法则
准备:
-- 首先删除之前创建的索引
call proc_drop_index("dudu","emp");
-- 创建索引
create index idx_age_deptid_name on emp(age,deptid,`name`);
问题以下这些SQL语句能否命中 idx_age_deptid_name 索引,可以匹配多少个索引字段
测试:
- 如果索引了多列,要遵守最左前缀法则。即查询从
索引的最左前列开始并且不跳过索引中的列。 - 过滤条件要使用索引,必须按照
索引建立时的顺序,依次满足,一旦跳过某个字段,索引后面的字段都无法被使用。
`
explain select * from emp where emp.age=30 and emp.name = 'abcd' ;
-- explain结果:
-- key_len:5 只使用了age索引
-- 索引查找的顺序为 age、deptid、name,查询条件中不包含deptid,无法使用deptid和name索引
explain select * from emp where emp.deptid=1 and emp.name = 'abcd';
-- explain结果:
-- type: all, 执行了全表扫描
-- key_len: null, 索引失效
-- 索引查找的顺序为 age、deptid、name,查询条件中不包含age,无法使用整个索引
explain select * from emp where emp.age = 30 and emp.deptid=1 and emp.name = 'abcd';
-- explain结果:
-- 索引查找的顺序为 age、deptid、name,匹配所有索引字段
explain select * from emp where emp.deptid=1 and emp.name = 'abcd' and emp.age = 30;
-- explain结果:
-- 索引查找的顺序为 age、deptid、name,匹配所有索引字段
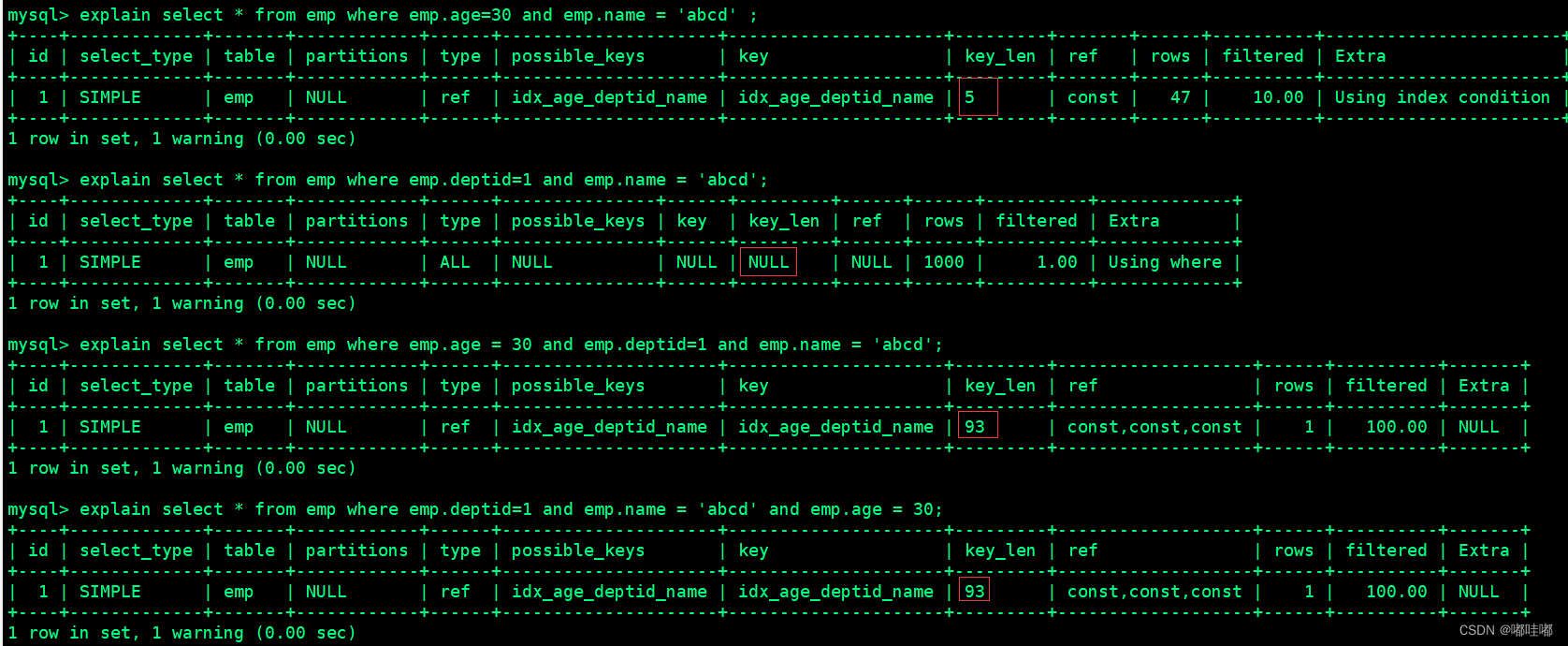
索引中范围条件右边的列失效
把条件放在最右边
准备:
-- 首先删除之前创建的索引
CALL proc_drop_index("dudu","emp");
问题为以下查询语句创建哪种索引效率最高
explain select * from emp where emp.age=30 and emp.deptid>1000 and emp.name = 'abc';
测试1:
-- 创建索引并执行以上sql语句的explain
create index idx_age_deptid_name on emp(age,deptid,`name`);
-- key_len:10, 只是用了 age 和 deptid索引,name失效
注意当我们修改deptId的范围条件的时候,例如deptId>100,那么整个索引失效,MySQL的优化器基于成本计算后认为没必要使用索引了,所以就进行了全表扫描。

测试2:
-- 创建索引并执行以上sql语句的explain(将deptid索引的放在最后)
create index idx_age_name_deptid on emp(age,`name`,deptid);
-- 使用了完整的索引

补充以上两个索引都存在的时候,MySQL优化器会自动选择最好的方案
关联查询优化
数据准备
创建两张表,并分插入16条和20条数据:
-- 分类
CREATE TABLE IF NOT EXISTS `class` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
-- 图书
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
-- 插入16条记录
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
-- 插入20条记录
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
关联查询优化--------左外连接
没有创建索引前的测试进行了全表扫描,查询次数为16*20
explain select * from class left join book on class.card = book.card;
-- 左表class:驱动表、右表book:被驱动表

测试1在驱动表上创建索引:进行了全索引扫描,查询次数是16*20
-- 创建索引
create index idx_class_card on class(card);

测试2在被驱动表上创建索引:可以避免全表扫描,查询次数是16*1
-- 首先删除之前创建的索引
call proc_drop_index("dudu","class");
-- 创建索引
create index idx_book_card on book(card);

测试3同时给两张表添加索引:充分利用了索引,查询次数是16*1
-- 已经有了book索引
create index idx_class_card on class(card);

结论:索引要创建在被驱动表上,驱动表尽量是小表
关联查询优化--------内连接
测试将前面外连接中的LEFT JOIN 变成 INNER JOIN
-- 换成inner join
EXPLAIN SELECT * FROM class INNER JOIN book ON class.card=book.card;
-- 交换class和book的位置
EXPLAIN SELECT * FROM book INNER JOIN class ON class.card=book.card;
都有索引的情况下选择数据量小的表做为驱动表
class表有索引的情况下book表是驱动表
book表有索引的情况下class表是驱动表
都没有索引的情况下选择数据量小的表做为驱动表
结论:发现即使交换表的位置,MySQL优化器也会自动选择驱动表,自动选择驱动表的原则是:索引创建在被驱动表上。
关联查询优化--------扩展掌门人的练习
-- 首先删除之前创建的索引
call proc_drop_index("dudu","emp");
call proc_drop_index("dudu","dept");
三表左连接方式:
-- 员工表(t_emp)、部门表(t_dept)、ceo(t_emp)表 关联查询
explain select emp.name, ceo.name as ceoname
from emp
left join dept on emp.deptid = dept.id
left join emp ceo on dept.ceo = ceo.id;
一趟查询,用到了主键索引,效果最佳
子查询方式:
explain select emp.name,(select emp.name from emp where emp.id = dept.ceo) as ceoname from emp left join dept on emp.deptid = dept.id;
两趟查询,用到了主键索引,跟第一种比,效果稍微差点。
临时表连接方式
explain select emp_with_ceo_id.name, emp.name as ceoname from(select
emp.name, dept.ceo from emp left join dept on emp.deptid = dept.id)
emp_with_ceo_id left join emp on emp_with_ceo_id.ceo = emp.id;
查询一趟,MySQL查询优化器将衍生表查询转换成了连接表查询,速度堪比第一种方式
MySQL5.5查询结果两趟查询,先查询a,b产生衍生表ab,衍生表作为驱动表,c作为被驱动表,使用到c表主键。效果比后面一种要好一点。
临时表连接方式2
explain select emp.name, ceo.ceoname from emp left join(select emp.deptid
as deptid, emp.name as ceoname from emp inner join dept on emp.id =
dept.ceo) ceo on emp.deptid = ceo.deptid;
查询一趟,MySQL查询优化器将衍生表查询转换成了连接表查询,但是只有一个表使用了索引,数据检索的次数稍多,性能最差。
MySQL5.5查询结果两趟查询,先查询b, a产生衍生表ab,衍生表作为被驱动表,衍生表无法建立索引,也就无法优化; 所以,这种语句是性能最差的。
关联查询优化--------总结
- 保证被驱动表的JOIN字段已经创建了索引
- 需要JOIN 的字段,数据类型保持绝对一致。
- LEFT JOIN 时,选择小表作为驱动表,大表作为被驱动表 。减少外层循环的次数。
- INNER JOIN 时,MySQL会自动将小结果集的表选为驱动表 。选择相信MySQL优化策略。
- 能够直接多表关联的尽量直接关联,不用子查询。(减少查询的趟数)
- 不建议使用子查询,建议将子查询SQL拆开结合程序多次查询,或使用 JOIN 来代替子查询。
- 衍生表建不了索引
边栏推荐
- 分布式系统的一致性与共识(1)-综述
- typescript10-常用基础类型
- Unity2D horizontal version game tutorial 4 - item collection and physical materials
- 【愚公系列】2022年07月 Go教学课程 013-常量、指针
- Gabor filter study notes
- typescript12-联合类型
- ShardingSphere之水平分库实战(四)
- Common network status codes
- 【c语言课程设计】C语言校园卡管理系统
- What is Promise?What is the principle of Promise?How to use Promises?
猜你喜欢

MySQL database (basic)
Error in go mode tidy go warning “all” matched no packages
A complete guide to avoiding pitfalls for the time-date type "yyyy-MM-dd HHmmss" in ES

Kotlin协程:协程上下文与上下文元素
Error ER_NOT_SUPPORTED_AUTH_MODE Client does not support authentication protocol requested by serv
会议OA项目待开会议、所有会议功能
Jmeter参数传递方式(token传递,接口关联等)
![[In-depth and easy-to-follow FPGA learning 13---------Test case design 1]](/img/1c/a88ba3b01d2e2302c26ed5f730b956.png)
[In-depth and easy-to-follow FPGA learning 13---------Test case design 1]

unity2D横版游戏教程4-物品收集以及物理材质
Unity2D horizontal version game tutorial 4 - item collection and physical materials
随机推荐
【c语言课程设计】C语言校园卡管理系统
typescript9 - common base types
MySQL Series 1: Account Management and Engine
[In-depth and easy-to-follow FPGA learning 15---------- Timing analysis basics]
ShardingSphere之公共表实战(七)
MySQL数据库约束,表的设计
Error occurred while trying to proxy request项目突然起不来了
Huawei's "genius boy" Zhihui Jun has made a new work, creating a "customized" smart keyboard from scratch
DOM系列之 offset 系列
The difference between h264 and h265 decoding
【愚公系列】2022年07月 Go教学课程 017-分支结构之IF
【ABAP】MFBF过账到质量检验库存类型Demo
Consistency and Consensus of Distributed Systems (1) - Overview
typescript10-常用基础类型
【愚公系列】2022年07月 Go教学课程 015-运算符之赋值运算符和关系运算符
MySQL系列一:账号管理与引擎
MySQL数据库进阶篇
过滤器(Filter)
Mysql systemized JOIN operation example analysis
Bypass of xss