当前位置:网站首页>Mining microbial dark matter -- a new idea
Mining microbial dark matter -- a new idea
2022-06-25 07:54:00 【Guhe Niubo】
Gu He health

An in-depth study of the microbiome , It is expected to provide a new solution to our health problems .
However, most microbial genomes have not been cultured yet , Even in the genome sequences that have been found , There are a lot of Unable to comment function . Therefore, the functional diversity of microbial phylogenetic tree cannot be fully captured , this This limits our ability to model advanced features of biological sequences . The construction of the model is an important part of the microbiome research .
Here we introduce a The newly released deep learning model , It provides some new ideas for the microbial research .

What can this model do ?
The researchers built LookingGlass Program , application RNN Cyclic neural networks and LSTM Learning method of short - and long-term memory neural network , Learn each nucleotide character in the sequence , In order to achieve Be able to predict different functions of classification 、 Homology and environmental origin reads Purpose .
LookingGlass Model also Have the ability of transfer learning , After fine tuning, you can perform a series of different tasks : For example, identifying new Oxidoreductases , Predict the optimum temperature of the enzyme , And identifying amino acid sequences .
LookingGlass The model can represent other unknown and uncommented sequences in terms of function , thus Mining microbial dark matter .
Fang Law
1► LookingGlass The training set of the model 、 Verification set And test set selection
The genome sequences of representative bacteria and archaea are classified by GTDB51(89.0 edition ) determine .
The complete genome sequence passed NCBI Genbank ftp download . That's what happened 24,706 Genome , Include 23,458 Bacterial genomes and 1248 Archaea genome .
To determine their actual sequence length , Use MetaSeek API Downloaded their sequencing metadata . Remove the length <60bp or >300bp The sample of , Finally, the average sequence length is 136bp Total of 7909 Samples .
LookingGlass The training set of the model 、 Both the verification set and the test set are in Class level Divided on , Between the three at this classification level No overlapping parts .
- The verification set is Actinobacteria, Alphaproteobacteria, Thermoplasmata, Bathyarchaeia Under each species 8 Genome , total 32 Genome ;
- The test set is Bacteroidia, Clostridia, Methanosarcinia, Nitrososphaeria Total under species 32 Genome ;
- The training set is for each of the remaining categories 1 Genome , total 32 Archaea genomes and 298 Bacterial genomes .
2►LookingGlass Model architecture and training
Main application RNN loop Neural networks and LSTM Long and short term memory neural network .
LookingGlass Use Three layers LSTM Encoder model , Each hidden layer has 1152 A unit , According to the result of super parameter adjustment ,embedding The size is 104.
LookingGlass Train in a self supervised way , According to the context of the preceding nucleotides in the sequence , Predict a masked nucleotide .
For each... In the training set sequence reads, Consider multiple training inputs , Move the masked nucleotide from the second position to the last position along the length of the sequence . Because it is a character level model , Linear decoder from possible vocabulary “A”、“C”、“G” and “T” The next nucleotide in the predicted sequence , with “ Start reading ” Special mark of 、“ Unknown nucleotides ”( In the case of ambiguous sequences )、“ End of read ”( stay LookingGlass Only during training “ Read start ” marked ) and “ fill ” Mark ( For classification purposes only ).
LSTM Regularization and optimization of utilize dropout And gradient descent method for optimal performance , Use fastai Library training .
Hardware aspect ,LookingGlass stay Microsoft Azure On , Memory is 16GB Of Pascal P100 GPU Training . In total, I trained 12 God , common 75 individual epoch, The learning rate is gradually reduced according to the result of hyperparametric optimization :15 individual epoch, The learning rate is 1e-2,15 individual epoch, The learning rate is 2e-3, And 1e-3 The learning rate of 45 individual epoch.
3► Superparameter optimization
Adjust the super parameters by random search , Major adjustments :
- kmer size
- stride
- number of LSTM layers
- number of hidden nodes per layer
- dropout rate
- weight decay
- momentum
- embedding size
- bptt size
- learning rate
- batch size
The main result
LookingGlass Be able to capture the functional characteristics of the sequence

Multi classification confusion matrix for functional annotation prediction . The horizontal axis represents the true value , The vertical axis represents the predicted value . The value in the box is the normalized prediction percentage , On the left is the correct prediction , On the right is the wrong prediction .
chart a Represents the validation set EC Prediction of the first position of the function number , chart b Indicates the prediction of the second position , The accuracy of the display is 80% above .
LookingGlass Able to capture phylogenetic features of sequences

LookingGlass Identify homologous sequence pairs at the gate level . Blue is homologous (Homologous), Red is non homologous (Nonhomologous).
chart a by embedding Degree of similarity Comparison between groups , Homologous group was significantly higher than non homologous group ,embedding The similarity is calculated as embedding Cosine similarity between vectors .
chart b by Accuracy 、 accuracy 、 Recall rate and F1 Changes in scores , Visible in embedding The similarity threshold is 0.62 Its accuracy (accuracy) The highest , Reached 66.4%, This means Door level Of . In the article, it shows that it has reached the level of 68.3%, At the target level 73.2%, It has reached the level of 76.6%, stay Genus level Up to 78.9%.LookingGlass Use embedding Methods to distinguish homologous and non homologous sequences , Without depending on their sequence similarity (Smith-Waterman comparison ).
chart c The results of searching homologues by these two methods are compared , The black box in the figure indicates that LookingGlass Correctly identified homologous sequences , But when using the comparison, we missed . It can be seen that many homologues have very low sequence similarity (bit score<50), Cannot be captured by comparison based methods , but LookingGlass Sure .LookingGlass High accuracy in identifying homologous genes , It has nothing to do with their sequence similarity , It shows that it captures a high level of features , It may reflect the phylogenetic relationship between sequences .
LookingGlass Distinguish the sequence of different environmental samples

come from 100 Metagenomic functional annotation sets of different environmental samples are used as validation sets . From there, for each environment group Random sampling 20000 Sequence calculation embedding Similarity degree . Find out Intergroup Of embedding similarity It is usually lower than that in the group Of , That is, sequences from the same environmental background are usually clustered together .
LookingGlass Support the transfer of learning tasks
With LookingGlass As a starting point , Fine tune the pre training model , To perform different tasks .
1. Predict taxonomic oxidoreductase
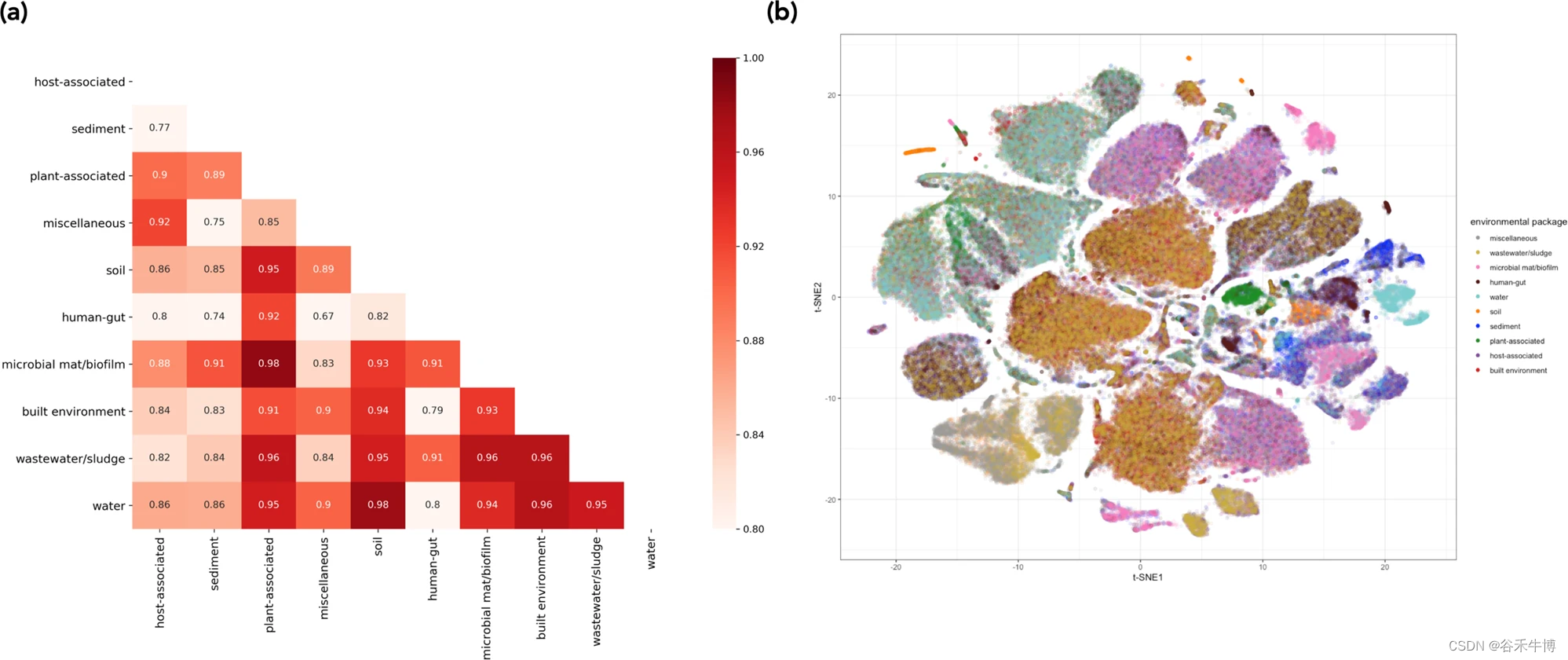
Yes LookingGlass After fine tuning the function annotation classification model , Perform the prediction and classification task of oxidoreductase .
The above figure shows the sequence similarity (bit score<50) Sequence , Predict whether the classification is the coding gene of oxidoreductase Accuracy 、 accuracy 、 Recall rate and F1 Changes in scores , The result indicates that the default threshold is 0.5 when , Its accuracy (accuracy) The highest , by 82.3%.
be based on LookingGlass The model can Distinguish between different environmental backgrounds Sequence under This advantage , The researchers used data from 16 Marine metagenomes as test sets , The sample coverage ranges from latitude ( from -62 C to 76 degree ), Ocean depth ( From the surface ~5 Meters to the middle ~ 200-1000 rice ) And oxygen concentration ( Including... From the lowest oxygen zone 4 Middle and upper layer samples ), From which each macrogenome is randomly selected 2000 ten thousand reads.
Mining the sequence of oxidoreductase , And prove that LookingGlass The classification of oxidoreductases is superior to the traditional homology based methods .
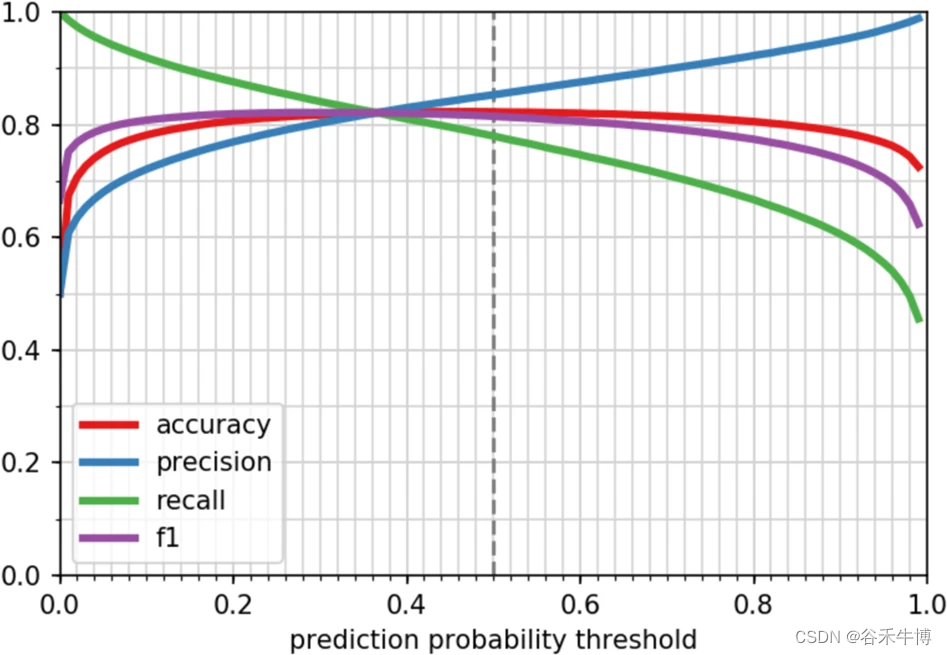

chart a by LookingGlass In the surface ocean (surface)、 Middle zone (mesopelagic) And the area with the lowest oxygen concentration (OMZ) Predict the proportion classified as oxidoreductase sequence .
chart b In the ocean surface zone group , Correlation between latitude and oxidoreductase , The results showed that there was a significant correlation (R2 = 0.79,P = 0.04).
chart c For separate use LookingGlass、MG-RAST and mi-faser Tool search oxidoreductase sequence , It was predicted to be oxidoreductase (oxidoreductases)、 Non oxidoreductase (not oxidoreductases) And uncommented (unannotated) Sequence proportion of . The result is MG-RAST The comments 26.7-50.3% Of reads, among 0.01-4.0% Identified as oxidoreductase .Mi-faser The comments 0.17-2.9% Of reads, among 0.04-0.59% Identified as oxidoreductase . so ,LookingGlass More advantage .
2. Use LookingGlass Identify amino acid sequences
LookingGlass Directly from CDS Predict the starting position of the translation frame (1、2、3、-1、-2 or -3), The accuracy is up to 97.8%, But it is only used for non coding at present DNA A lower proportion of prokaryotic sequences .
3. from DNA The sequence fragment predicts the optimal temperature of the enzyme
The optimum temperature of the enzyme depends in part on DNA Sequence characteristics , But it's hard to predict , Especially short reading and long reading . Divide the temperature into psychrophilic (<15°C)、 Thermophilic (20-40°C) Or thermophilic (>50°C), fine-tuning LookingGlass After procedure , The input sequence predicts the best temperature category , Accuracy up to 70.1%.
junction On
LookingGlass The program can Not by comparison Refer to the database to pre Measure and characterize DNA Sequence , thus Obtain functional notes and phylogenetic information . meanwhile ,LookingGlass The transfer learning framework can quickly learn 、 Training and convergence for different classification tasks , This provides some contributions to the modeling of complex biological systems in the future .
It is predicted that taxonomic oxidoreductase can Mining the potential functions of location sequences , Predictable enzymes will be expanded in the future . Predicting the optimal temperature of enzyme can be used to guide the function and optimal temperature of protein design .
To make a long story short , This is a good exploration . The author has encapsulated the model functions used in this article as python library —fastBio, The data set used in this paper can be directly used for model training , Available at :github.com/ahoarfrost/fastBio/
Main references :Hoarfrost A, Aptekmann A, Farfañuk G, Bromberg Y. Deep learning of a bacterial and archaeal universal language of life enables transfer learning and illuminates microbial dark matter. Nat Commun. 2022 May 11;13(1):2606. doi: 10.1038/s41467-022-30070-8. PMID: 35545619; PMCID: PMC9095714.
边栏推荐
猜你喜欢

使用Adobe Acrobat Pro调整PDF页面为统一大小

TCP与UDP

Modular programming of LCD1602 LCD controlled by single chip microcomputer
Anaconda navigator启动慢的一个解决方法

Summary of small problems in smartbugs installation

用函数的递归来解决几道有趣的题

NPM install reports an error: gyp err! configure error

传统的IO存在什么问题?为什么引入零拷贝的?

OpenCV每日函数 结构分析和形状描述符(8) fitLine函数 拟合直线

417-二叉树的层序遍历1(102. 二叉树的层序遍历、107.二叉树的层次遍历 II、199.二叉树的右视图、637.二叉树的层平均值)
随机推荐
What are the benefits of reserving process edges for PCB production? 2021-10-25
One "stone" and two "birds", PCA can effectively improve the dilemma of missing some ground points under the airborne lidar forest
Terms and concepts related to authority and authentication system
This article uses pytorch to build Gan model!
C WinForm panel custom picture and text
使用Adobe Acrobat Pro调整PDF页面为统一大小
Pit encountered by pytorch: why can't l1loss decrease during model training?
1742. 盒子中小球的最大数量
一文了解 | 革兰氏阳性和阴性菌区别,致病差异,针对用药
海思3559 sample解析:vio
Insert and sort the linked list [dummy unified operation + broken chain core - passive node]
C# 读取web上的xml
【日常训练】207. 课程表
The fourth floor is originally the fourth floor. Let's have a look
微信小程序开通客服消息功能开发
如何用svn新建属于自己的分支
STL tutorial 4- input / output stream and object serialization
Atlassian Confluence 远程代码执行漏洞(CVE-2022-26134漏洞分析与防护
微信小程序入门记录
How to select lead-free and lead-free tin spraying for PCB? 2021-11-16