当前位置:网站首页>MySQL advanced - index optimization (super detailed)
MySQL advanced - index optimization (super detailed)
2022-06-30 18:10:00 【Noblegasesgoo】
Performance analysis
MySQL Query Optimizer
Mysql In particular Responsible for optimizing SELECT Statement optimizer , The main function is By calculating the statistics collected in the analysis system , Requested for client Query Provide the best execution plan he thinks ( He thinks the best , but ** Is not necessarily DBA Feel the best , This part takes the most time **).
When the client MySQL Ask for one Query When , The command parser module completes the request classification , The difference is SELECT And forward it to MySQL Query Optimizer when ,MQO For the whole Query To optimize , Deal with the budget of some constant expressions , Convert it to a constant value and correct the ,Query Simplification and transformation of query conditions in , Such as Remove some useless or obvious conditions 、 Structural adjustment etc. , Then analysis Query Medium Hint Information ( If any ), Look at the display Hint Information Is it possible to be completely certain that Query Implementation plan of . If No, Hint or Hint The information is not enough to fully determine the implementation plan , will Read the statistics of the object involved , according to Query Carry out corresponding calculation and analysis , Let's get the final implementation plan .
MySQL Common bottlenecks
CPU
- CPU In the bag and It usually occurs when data is loaded into memory or read from disk When
IO
- disk I/O Where is the bottleneck When the loaded data is much larger than the memory capacity .
Server hardware
- The performance bottleneck of hardware :top,free,iostat and vmstat To see the performance status of the system .
Explain( a key )
What is it?
Use EXPLAIN keyword Sure simulation Optimizer perform SQL Query statement , Never know MySQL How to deal with you SQL Of the statement , Analyze the performance bottleneck of your query statement or table structure .
stay MySQL 5.7 in , Merge and optimize the derived tables , If you want to view it intuitively select_type Value , The function needs to be turned off temporarily ( The default is on )
-- Turn off the merge optimization of derived tables
set global optimizer_switch='derived_merge=off';
-- Turn off the merge optimization of derived tables ( Valid only for this session )
set session optimizer_switch='derived_merge=off';
-- Open the merge optimization of the derived table ( Valid only for this session )
set session optimizer_switch='derived_merge=on';
What can I do?
- Read order of tables
- Which indexes can be used
- Operation type of data read operation
- Which indexes are actually used
- References between tables
- How many rows per table are queried by the optimizer
How do you play?
Explain + SQL Sentence can be used .

Analysis of each field
Of the test case sql
CREATE TABLE t1(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t2(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t3(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
CREATE TABLE t4(id INT(10) AUTO_INCREMENT,content VARCHAR(100) NULL , PRIMARY KEY (id));
INSERT INTO t1(content) VALUES(CONCAT('t1_',FLOOR(1+RAND()*1000)));
INSERT INTO t2(content) VALUES(CONCAT('t2_',FLOOR(1+RAND()*1000)));
INSERT INTO t3(content) VALUES(CONCAT('t3_',FLOOR(1+RAND()*1000)));
INSERT INTO t4(content) VALUES(CONCAT('t4_',FLOOR(1+RAND()*1000)));
id Field
select The serial number of the query , Contains a set of numbers , Express Execute in query select The order of clauses or operation tables .
Situation 1 :id identical
id identical , The order of execution is from top to bottom
EXPLAIN SELECT *
FROM t1, t2, t3
WHERE
t1.id = t2.id
AND t2.id = t3.id;

In this case , Yes where First statement after t1.id = t2.id adopt t1.id relation t2.id, and t2.id The result is Based on the t2.id = t3.id On the basis of .
It may also occur that the execution order is t1 -> t3 -> t2 The situation of .
Situation two :id Different
EXPLAIN SELECT t2.*
FROM t2
WHERE id = (SELECT t1.id
FROM t1
WHERE id = (
SELECT t3.id
FROM t3));

From the results we can see that , If it is Subquery ,id The serial number of will increase ,id The bigger the value is. , The higher the priority , The first to be executed .
It can be understood as , Priority of parentheses .
id Increasing -> id The bigger the value is. -> The higher the priority -> The first to be executed
Situation three :id Same and different , At the same time
EXPLAIN SELECT t2.*
FROM (SELECT t3.id
FROM t3) AS s1, t2
WHERE s1.id = t2.id;

id If the same , It can be thought of as a group , Execute from top to bottom in the group , So in all groups ,id The higher the value, the higher the priority , The group with higher priority , Execute first .
The result once shocked me , Because there is no derived table . I went to check , The occurrence of derived tables is not a good query scheme , A derived table is essentially a temporary table , If it is too large, you may have to create it on disk instead of in memory , Such creation and access will consume IO Resources , May be in MySQL5.7 Optimizer in , Will automatically help optimize derived tables , Merge derived tables into outer queries .
such as :
-- Before optimization
SELECT * FROM (SELECT * FROM t1) AS s1;
-- After optimization
SELECT * FROM t1;
select_type
Type of query , It is mainly used for Distinguish ordinary query , The joint query , Complex queries such as subqueries .
What are they?
That's all :
Let's take a look one by one .
- SIMPLE
ordinary SELECT Inquire about , The query does not contain subqueries or UNION

PRIMARY
If the query contains any Complex sub parts , The outermost query is marked PRIMARY, The last one .

5.7 Version of the optimizer directly optimizes , Here we use other people's pictures .
- DERIVER
stay FROM The subqueries contained in the list are marked with DERIVERD( The derived )MySQL These subqueries will be executed recursively , Put the results in the provisional table .

- SUBQUERY
stay SELECT or WHERE Package in the list Contains subqueries .

- DEPENDENT SUBQUERY(5.7 There is no )
stay SELECT or WHERE The list contains subqueries , Subqueries are based on the outermost layer

DEPENDENT SUBQUERY And SUBQUERY The difference between
Dependent subqueries : The subquery result is multivalued | Subquery : The query result is single value .
- UNCACHEABLE SUBQUREY(5.7 There is no )
Subqueries that cannot be cached , It is estimated that the temporary table is too large .
- UNION
If the second SELECT Appear in the UNION after , Is marked as UNION;
if UNION Included in FROM Clause , The outer SELECT Will be marked as DERIVED

- UNION RESULT
Use union A temporary table will be generated after keywords , For this temporary table select .

table
Table corresponding to row query .
- When
fromIf there is a subquery in the clause ,table List as deriverN The format of , Indicates that this line executes id = N Query of row . - When there is
unionwhen ,tableThe data is<union M,N>The format of , M and N To participate inunionOfselectThat's ok id.
type( It's very important )
type Indicates the association type of this row query ( Access type , Or query type ), Through this value, you can know the approximate range of query data records in this row .
Its value is related to whether we have optimized SQL Is closely linked .
The common values from the best to the worst are :system > const > eq_fef > ref > range > index > all;
In general , We want to To ensure efficiency , We should optimize our statements to at least range Level , If possible, it is better to optimize to ref; range Level is generally used for range lookup , So in other words , In addition to range lookup , We Other query statements should be optimized to ref Level .
What are they?
These are the only common :

Now let's take a look at how many situations will occur one by one :
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-MKnFTanX-1644829484203)(2021-11-27- Index optimization .assets/image-20211127145716128.png)]](/img/bf/7ced38012be0355a9f23d52cf968d2.jpg)
NULL
- Express MySQL Be able to decompose query statements in optimization phase , There is no need to access tables and indexes during execution .
system / const
- MySQL It can optimize a query part and convert it into a constant ( Can pass
show warningsView the optimization results ), It is mainly used to query the primary key (primary key) Or a unique index (Unique Key) Corresponding records , Because there is no repetition , So you can only query one record at most , So it's faster .system yes const The special case of , When When there is only one record in the temporary table, it is system.
- MySQL It can optimize a query part and convert it into a constant ( Can pass

eq_ref
- Unique index scan , For each index key , Only one record in the table matches it , Common in primary key or unique index scan .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-Px5Hb2cx-1644829484204)(2021-11-27- Index optimization .assets/B35FF991-62B8-4EC7-896C-7B7192751A0E.png)]](/img/22/a141635a027c3a1656aca74cb00582.jpg)
ref
- Non unique index scan , Returns a match All rows of individual values , In essence, it is also an index access , It returns all rows that match a single value , However , It may find more than one eligible row , So it should be a mixture of search and scan .

range
- Retrieve only rows in the given range , Use an index to select rows ,
keyColumn shows which index is used It's usually in yourwhereIn the sentencebetween、<>、inAnd so on . - such Range scanning is better than full table scanning , Because it only Need to start at some point in the index , And it ends at another point in the index , Don't scan all indexes .
- Retrieve only rows in the given range , Use an index to select rows ,

index
Full Index Scan,indexAndALLThe difference forindexType only traverses the index tree . This is usually better thanALLfast , Because index files are usually smaller than data files .- That is to say, although
allandindexRead the whole watch , howeverindexRead from index ,allIt's read from the hard disk .
all
Full Table Scan, Will traverse the entire table to find the matching rows .
index_merge
- In the query process, we need to use multiple indexes in combination , It usually occurs when there is
orKeywordssqlin .
- In the query process, we need to use multiple indexes in combination , It usually occurs when there is

ref_or_null
- For a field, both association conditions are required , Also needed
nullWhen it's worth it , The query optimizer will choose to useref_or_nullLink query . - Compare with the above , Primary key id In general, it can't be null So it's not ref_or_null.
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-yyUQV1Z9-1644829484205)(2021-11-27- Index optimization .assets/F999ECF8-4C11-4FC6-AFFD-7697C63DB330.png)]](/img/54/313e8e0482c3e44f2c07a0af9dd251.jpg)
- For a field, both association conditions are required , Also needed
index_subquery
- Using indexes to associate subqueries , No longer scan the full table .

unique_subquery
- The connection type is similar to
index_subquery. Unique index in subquery .
- The connection type is similar to
possible_keys
- Show the indexes that may be applied to this table , One or more .
- If there is an index on the field involved in the query , Then the index will be listed , But it doesn't have to be actually used by the query .
key
- Actual index used . If null, No index is used
- If an overlay index is used in the query , Then the index and query select Fields overlap .
- in other words , When querying a field , And that field has a corresponding index ,key The value of is displayed as an index , instead of null.
key_len
- Represents the number of bytes used in the index , adopt This column calculates the length of the index used in the query , stay Without loss of accuracy , Usually the less the better .
- It shows the maximum possible length , and Not necessarily the actual length used .
- That is, it is calculated according to the table definition rather than through intra table retrieval .
- key_len Field can help you check whether you make full use of the index .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-raWpuC5Y-1644829484207)(2021-11-27- Index optimization .assets/image-20211127160713103.png)]](/img/eb/be772d1406d52bb54a0d036cd9a355.jpg)
ref
- Shows which column of the index is used , If possible , It's a constant .
- Which columns or constants are used to find values on the index .

rows
- rows Columns show MySQL The number of rows that it must check to execute the query .
Extra( important )
contain Not suitable for displaying in other columns however Very important additional information .
Using filesort
- explain MySQL Will use a for the data External index sort , Instead of reading according to the index order in the table .
- MySQL in A sort operation that cannot be done with an index is called “ Sort in file ”.
- This situation is tantamount to a narrow escape .
- For example, composite index , Only one field of the composite index is used , So it can't be sorted , Will appear .
Using temporary
- Temporary tables are used to save intermediate results ,
MySQLUse temporary tables when sorting query results . - It is common in sorting
order byAnd group queriesgroup by. - To be in Use index in grouping , You also have to follow the order in which indexes are defined , No castles in the air , Otherwise, it is easy to cause this Extra, By the way, bring another one on top Extra
- Temporary tables are used to save intermediate results ,

Using index
It means corresponding select Used in the operation Overlay index (Covering Index), Avoid the data row of the table , Good efficiency !
If it appears at the same time using where, indicate The index is only used to read data and Non index lookup .
Overlay index
- Simply put, it's me ** The fields of the built Composite Index , Exactly all the fields I'm looking for , And in the same order , It's actually an index scan INDEX**.
- The index is efficient to find that That's ok One way , however General databases can also use indexes to find one Column The data of , So it doesn't have to read the entire line , After all, index leaf nodes store the data they index , When you can get the desired data by reading the index , Then there is no need to read .
- ① An index ② Containing or covering select Clause and query condition where clause ③ All the required fields are called overlay indexes .
SELECT id , name FROM t_xxx WHERE age = 18;- There is a composite index
idx_id_name_age_xxxContainsid,name,ageThree fields . When querying, the indexed columns are directly retrieved , Instead of looking for other data in the row , More efficient . - It feels that it can be used for a large amount of data , And this kind of index can be used for many fixed field queries .
- Be careful : If you want to Use overlay index , Be sure to pay attention to
select listOnly the required columns are extracted from the , And the columns are included in the coverage index . Can not beselect *, If all fields are indexed together, the index file will be too large , Query performance degradation .

Using where
- indicate Used where Filter .
using join buffer
indicate Connection caching is used .

Occurs when two tables are joined ,
- The driver table (join Which side is the former simplicity , Which side is the drive table ,inner join The table with less data ) Without index , Indexing the driver table solves this problem , also type Will become ref.
join More , In the configuration file join buffer You can turn it up a little bit .
impossible where
- indicate where The value of the clause is always false, Can't be used to get any tuples .
select tables optimized away
- In the absence of
GROUP BYIn the case of clause , Index based optimization MIN/MAX Operation or for MyISAM Storage engine optimization COUNT(*) operation , You don't have to wait for the execution phase to calculate , The query execution plan generation phase completes the optimization .
- In the absence of
Example

Running order ?
t2 -> t1 -> t3 -> <derived3> -> <union1, 4>

Index optimization
Optimization analysis
Performance degradation SQL slow , Long execution time , The reasons for the long waiting time are as follows :
- The query statement is poorly written
- No index , Too many subqueries .
- Index failure
- It was indexed but not used , Or not indexed .
- Too many associated queries join
- It may be caused by the design defect of the database , Or a last resort .
- Often cause Long execution time .
- Server tuning and parameter settings
- buffer 、 Number of threads, etc .
- It often leads to the maximum number of concurrency The waiting time is long .
Single table optimization
Build table SQL
CREATE TABLE IF NOT EXISTS `article` (
`id` INT(10) UNSIGNED NOT NULL PRIMARY KEY AUTO_INCREMENT,
`author_id` INT(10) UNSIGNED NOT NULL,
`category_id` INT(10) UNSIGNED NOT NULL,
`views` INT(10) UNSIGNED NOT NULL,
`comments` INT(10) UNSIGNED NOT NULL,
`title` VARBINARY(255) NOT NULL,
`content` TEXT NOT NULL
);
INSERT INTO `article`(`author_id`, `category_id`, `views`, `comments`, `title`, `content`) VALUES
(1, 1, 1, 1, '1', '1'),
(2, 2, 2, 2, '2', '2'),
(1, 1, 3, 3, '3', '3');
SELECT * FROM article;
Case realization SQL
-- Inquire about category_id by 1 And comments Greater than 1 Under the circumstances ,views The most article_id
SELECT id,author_id FROM article WHERE category_id = 1 AND comments > 1 ORDER BY views DESC LIMIT 1;
Optimization starts
EXPLAIN SELECT `id`,`author_id` FROM `article` WHERE `category_id` = 1 AND `comments` > 1 ORDER BY `views` DESC LIMIT 1;

We can see , At this point we type yes ALL( Full table scan ), And it is a simple single table query , however Using filesort 了 , Put it all together , This is the worst case .
We can index query types to range Direction depends ;
-- Build composite index ALTER TABLE `article` ADD `index` idx_article_ccv(`category_id`,`comments`,`views`);We can see that it has not been eliminated Using filesort however range It is already within the acceptable range .

Why do we all have indexes , But it's still file sorting , There is no index sort ?
- Because the BTree How index works , Prioritize category_id Reordering comments, If the same comments Then reorder view,
- Now our SQL In the sentence comments Field in Composite index of In the middle ,
- here comments > 1 The condition is a Range ( So it is range),
- therefore MySQL We can't use the index to look at the following views Partial search , namely range Invalid index after type query field .
After the analysis, let's try to build a composite index across the fields that need a range query .
-- Delete the first index DROP INDEX idx_article_ccv ON article; -- Create a new index CREATE INDEX idx_article_cv ON article(`category_id`,`views`);The last analysis :

It can be seen that this is the result we want most ,type = ref,ref = const,Extra Medium Using filesort It's gone .
Association query optimization
Build table SQL
CREATE TABLE IF NOT EXISTS `class` (
`id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`id`)
);
CREATE TABLE IF NOT EXISTS `book` (
`bookid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`bookid`)
);
CREATE TABLE IF NOT EXISTS `phone` (
`phoneid` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`card` INT(10) UNSIGNED NOT NULL,
PRIMARY KEY (`phoneid`)
);
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO class(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO book(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
INSERT INTO phone(card) VALUES(FLOOR(1 + (RAND() * 20)));
Case a : Double table
Case realization SQL
-- Double table
SELECT * FROM class LEFT JOIN book ON class.card = book.card;
Optimization starts
-- Analyze the following statements
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card;

It's coming straight ALL and Using join buffer, This is what we do not want , We are heading for ref | range as well as const To optimize .
Try adding an index to eliminate ALL.
ALTER TABLE `book` ADD INDEX idx_c(`card`);

We can see that the second line is ref and Eliminated Using join buffer 了 , But the first line is still ALL. This is from The left connection feature determines .LEFT JOIN Conditions apply to Determine how to search rows from the right table , There must be... On the left , So on the right is our key point , There must be an index .
Let's see if there is any way to divide the first line ALL, Try... In the left table card Field creation index .
ALTER TABLE `class` ADD INDEX idx_c(`card`);Effect grouping , Successfully optimized the first line of ALL by index , Can accept .

But generally we Just optimize to the third step , Multiple indexes may also take up space , Try to avoid excessive consumption of space resources , because rows The indicators are the same , We might as well save more space .
Case 2 : Three watches
Case realization SQL
-- Delete the redundant index first
DROP INDEX idx_c ON class;
DROP INDEX idx_c ON book;
-- This case is to be analyzed SQL
SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card;
Optimization starts
First analyze this statement
EXPLAIN SELECT * FROM class LEFT JOIN book ON class.card = book.card LEFT JOIN phone ON book.card = phone.card;

It can be seen that , This is a normal statement that has not been optimized , It can be like a double watch , Optimize according to that set of rules .
We start adding indexes to two right tables that participate in the corresponding left join
-- Add a new index ALTER TABLE `book` ADD INDEX B (`card`); ALTER TABLE `phone` ADD INDEX P (`card`);Optimized to an acceptable level .

MySQL Of FILESORT Sort ( a key )
One way sorting
What is it? ?
from ** disk Read all the columns required by the query **, according to ORDER BY Column stay buffer Sort them out , Then scan the sorted list for output , its Be more efficient , Avoid reading data for the second time . also Put random IO It becomes a sequence IO, But he Will use more space , Because it Save each line in memory 了 .
Two way sorting
What is it? ?
MySQL 4.1 Before that, we used two-way sorting , Literally Scan the disk twice , And finally get the data . Read Row pointer and ORDER BY Column , Sort them out , Then scan the ordered list , Re read the corresponding data output from the list according to the value in the list .
Take sort field from disk , stay buffer Sort , Take other fields from disk .
Compare
- Multiple sorting , You need to sort by disk , So take the data 、 When you're ready to get the data , Twice IO operation , It will be slow .
- One way sorting , Store the arranged data in memory , One time is omitted IO operation , So it will be faster , however You need enough memory on your computer .
Conclusion and question
One way sorting is the last out , So the overall performance is better than two-way sorting .
But in sort_buffer in , Method B Than Method A Take up a lot of space , because Method B yes Take out all the fields ,, therefore ** It is possible that the total size of the retrieved data exceeds sort_buffer The capacity of , Cause only access sort_buffer Data of capacity size **, Sort ( establish tmp file , Multiplex merge ), Take it after you've finished sort_buffer Capacity size , Arrange again …… So many times I/O.
I wanted to save it once I/O operation , Instead, it leads to a lot of I/O operation , It's not worth it .
So we need to transport peacekeepers at this time DBA appear Adjust according to the business MySQL In the database configuration file sort_buffer Size .
ORDER BY Optimize
MySQL Support two ways of sorting ,FileSort and Index,Index Efficient , It means MySQL Scan index itself to complete sorting .FileSort The way is less efficient .
We are starting to optimize order by Before clause , We need to know what stage we are going to optimize , about ORDER BY Sort , Try to optimize to INDEX The best way is to sort , avoid FILESORT.
case analysis
Build table SQL
CREATE TABLE tblA(
id int primary key not null auto_increment,
age INT,
birth TIMESTAMP NOT NULL,
name varchar(200)
);
INSERT INTO tblA(age,birth,name) VALUES(22,NOW(),'abc');
INSERT INTO tblA(age,birth,name) VALUES(23,NOW(),'bcd');
INSERT INTO tblA(age,birth,name) VALUES(24,NOW(),'def');
CREATE INDEX idx_A_ageBirth ON tblA(age,birth,name);
SELECT * FROM tblA;
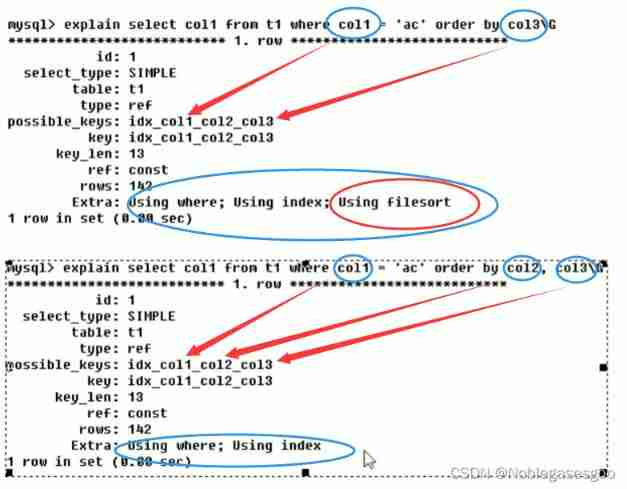
Situation 1

The first sentence : The leader is in , however Sort according to the younger brother , Big brother is in the back , The order is out of order , appear filesort.
The second sentence : The leader is in , And the eldest brother and the second younger brother .
The third sentence : The leader is in , And use the big brother that has been indexed to sort .
The fourth sentence : The leader is in , But use younger brother sorting , be not in where The index fields that appear in the clause are order by An occurrence in a clause will invalidate the index , appear filesort.
Situation two
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-BkC2lUlk-1644829484211)(2021-11-27- Index optimization .assets/D2AB50A2-757C-44A6-9E60-8FC4AF33DF97.png)]](/img/18/6b59038402537d1b5d19efa38b0170.jpg)
The first sentence : Index sort invalid , Because it doesn't start with big brother .
The second sentence : Index sort invalid , Because it doesn't start with big brother .
The third sentence : Index sorting succeeded , because WHERE Clauses come in indexed field order and are not invalidated until they are scoped , So there is no full table scan , also ,ORDER BY The clause begins with big brother .
The fourth sentence : Index sort invalid , Because the index is sorted by default , Then you force the reverse order , Can cause indexes to fail .
Case summary
- about ORDER BY Sort , Try to optimize to INDEX The best way is to sort , avoid FILESORT.
- Sort as much as possible on the index columns , Follow the best left prefix rule for indexes .
- If ** Not in index column On ,filesort There are two algorithms :mysql It's about to start Two way sorting and One way sorting **.
- ORDER BY There are two cases , Will use INDEX Sort by :
- ORDER BY sentence Use the leftmost column of the index .
- Use WHERE Clause and ORDER BY Clause The condition column combination satisfies Index leftmost prefix rule .
- WHERE Clause if index range query appears ( namely explain It appears that range It can lead to )order by Index failure .
GROUP BY Optimize
Let's start with an example ,GROUP BY grouping , It must be sorted before grouping , There will be temporary tables 
Prevent index failure
Case study SQL
CREATE TABLE staffs (
id INT PRIMARY KEY AUTO_INCREMENT,
NAME VARCHAR (24) NULL DEFAULT '' COMMENT ' full name ',
age INT NOT NULL DEFAULT 0 COMMENT ' Age ',
pos VARCHAR (20) NOT NULL DEFAULT '' COMMENT ' Position ',
add_time TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT ' Entry time '
) CHARSET utf8 COMMENT ' Employee record form ' ;
INSERT INTO staffs(NAME,age,pos,add_time) VALUES('z3',22,'manager',NOW());
INSERT INTO staffs(NAME,age,pos,add_time) VALUES('July',23,'dev',NOW());
INSERT INTO staffs(NAME,age,pos,add_time) VALUES('2000',23,'dev',NOW());
INSERT INTO staffs(NAME,age,pos,add_time) VALUES(null,23,'dev',NOW());
ALTER TABLE staffs ADD INDEX idx_staffs_nameAgePos(name, age, pos);
The leftmost prefix rule ( a key )
If more than one column is indexed , Follow the leftmost prefix rule . The leftmost prefix rule refer to ** The query starts at the top left of the index and does not skip the columns in the index .**
Start with the first condition on the far left , If an index is used , Then you have to start with the leftmost field of the index , You can't lose , Don't omit , It's like a building , The third floor cannot be built without the first floor and the second floor .
The middle brother can't break , It is impossible to build the third floor directly after the first floor .
Indexes idx_staffs_nameAgePos When indexing , With name,age ,pos The order of the establishment of . A full value match indicates Queries that match in order .
therefore According to the leftmost prefix rule , It will reduce the probability of index failure .
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July';
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July' AND age = 25;
-- Full value matching my favorite
EXPLAIN SELECT * FROM staffs WHERE NAME = 'July'AND age = 25 AND pos = 'dev';

Do not operate on index columns
Do nothing on the index column , such as Calculation 、 function 、 Automatically | Manual type conversion , because Doing so invalidates the index and leads to a full table scan .
-- Wrong operation application left Functions operate on index fields
EXPLAIN SELECT * FROM staffs WHERE left(NAME,4) = 'July';
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-osdsSw1r-1644829484213)(2021-11-27- Index optimization .assets/image-20211128163623456.png)]](/img/a8/63a9456a96f57103be8d4471cc874f.jpg)
Storage engine problem
The storage engine cannot use the column to the right of the range condition in the index

Compare the two pictures , We found that , The second uses only two index fields , The index of the third field is invalid , All invalid after range condition field , So we have to optimize this range query as much as possible .
Try to use index overlay
Reduce use SELECT *, As the title .
MySQL Use is not equal to ( important )
MySQL Use It's not equal to (!= | <>) You will not be able to use the index , Causes a full table scan , Attention is being taken **!= operation ** The index field of cannot be used , All indexes are invalid .

is not null and is null
The former cannot be indexed , The latter can be indexed .

To use less like keyword ( a key )
**like Start with a wildcard (‘%xxxx’)** Such conditions ,MySQL The index will fail and become a full table scan .
like ‘abc%’type The type is range , It's the scope , You can use index .

But the inevitable use %xxx% What to do with the scene ?
- We can use Index overlay To solve .
CREATE TABLE `tbl_user` (
`id` INT(11) NOT NULL AUTO_INCREMENT,
`NAME` VARCHAR(20) DEFAULT NULL,
`age` INT(11) DEFAULT NULL,
email VARCHAR(20) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
INSERT INTO tbl_user(NAME,age,email) VALUES('1aa1',21,'[email protected]');
INSERT INTO tbl_user(NAME,age,email) VALUES('2aa2',222,'[email protected]');
INSERT INTO tbl_user(NAME,age,email) VALUES('3aa3',265,'[email protected]');
INSERT INTO tbl_user(NAME,age,email) VALUES('4aa4',21,'[email protected]');
INSERT INTO tbl_user(NAME,age,email) VALUES('aa',121,'[email protected]');
-- before index
-- There is no index , So it doesn't matter how the following statements come from
EXPLAIN SELECT NAME,age FROM tbl_user WHERE NAME LIKE '%aa%';
EXPLAIN SELECT id FROM tbl_user WHERE NAME LIKE '%aa%';
EXPLAIN SELECT NAME FROM tbl_user WHERE NAME LIKE '%aa%';
EXPLAIN SELECT age FROM tbl_user WHERE NAME LIKE '%aa%';
EXPLAIN SELECT id,NAME FROM tbl_user WHERE NAME LIKE '%aa%';
EXPLAIN SELECT id,NAME,age FROM tbl_user WHERE NAME LIKE '%aa%';
EXPLAIN SELECT NAME,age FROM tbl_user WHERE NAME LIKE '%aa%';
EXPLAIN SELECT * FROM tbl_user WHERE NAME LIKE '%aa%';
EXPLAIN SELECT id,NAME,age,email FROM tbl_user WHERE NAME LIKE '%aa%';
-- create index Create a composite index
CREATE INDEX idx_user_nameAge ON tbl_user(NAME,age);
-- DROP INDEX idx_user_nameAge ON tbl_user
-- after index
EXPLAIN SELECT * FROM tbl_user WHERE NAME =800 AND age = 33;
To sum up, to solve this problem , We have to build a composite index , Then make a query within the index field , For example, composite index a,b,c Three fields , You can only use d Field , perhaps a,b,c,d Four fields ( One more field comes out ) No index other than is invalidated .
Type conversion
Type conversion will cause index invalidation , such as String type == No addition Single quotation marks == Meeting Automatic type Convert to another type .
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-mnF26G3q-1644829484214)(2021-11-27- Index optimization .assets/image-20211128165209506.png)]](/img/96/e3e3cab03a9d4b52fb650942b3df96.jpg)
To use less or keyword
or Also need to use less , use or Keyword will also invalidate the index .

summary
Optimization summary chart ( important )
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-vtElbent-1644829484215)(2021-11-27- Index optimization .assets/image-20211129161203575.png)]](/img/1e/20c66365293dbf64f904076ed51084.jpg)
Example summary diagram
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-g8UhtqxD-1644829484215)(2021-11-27- Index optimization .assets/image-20211129160957139.png)]](/img/40/7cef2baa78131f75bdc767b071a4d5.jpg)
General advice
- For single key indexes , Try to choose the current query Better filtering index .
- In the choice Composite index When , At present query The most filterable field in the index field order , The higher the position, the better .
- When choosing a composite index , Try to include the current query Medium where An index of more fields .
- As much as possible by analyzing statistics and adjusting query To achieve the purpose of selecting the appropriate index .
Summary of association query optimization
Make sure that the driven meter join The field has been indexed ( Was the driver table :join Table after is driven table ( Need to be queried )).
MySQL Automatically select the small table as the driving table . Because the driver table will be scanned by the whole table anyway , So the fewer scans, the better
left join when , Choose a small watch as the driving watch , Big watch as driven watch ,right join conversely ( however left join It must be the driving table on the left , On the right is the driven table ,right join conversely ).
inner join when ,mysql Will help you choose the table of small result set as the driving table .
Subqueries should not be placed in the driven table , It's possible that indexes are not used .
Reduce... As much as possible join The number of times .
Always remember to use Small tables drive large tables .
Optimize statements in nested loops first .
There is no guarantee that the driven table join The condition field is called Cited and On the premise of sufficient memory resources , Don't be too stingy JoinBuffer Set up .
EXISTS And IN Subquery optimization summary
With an index :
- use inner join It's the best The second is in ,exists The worst .
- inner join > in > exists.
![[ Failed to transfer the external chain picture , The origin station may have anti-theft chain mechanism , It is suggested to save the pictures and upload them directly (img-nSaOc5WE-1644829484215)(2021-11-27- Index optimization .assets/image-20211129182820101.png)]](/img/63/cd54b488f8e8c2550c1644d9cbf125.jpg)
No index
- Small tables drive large tables
- because join The way needs to be distinct , No index distinct High consumption performance therefore exists > in > join.
- Big tables drive small ones
- in and exists The performance of the should be close to that of the are relatively poor exists A little better More than 5% , however inner join Better than using join buffer So much faster .
- inner join > exists > in
- If it is left join Is the slowest .
- Small tables drive large tables
The content of this article is based on Shang Silicon Valley MySQL Advanced tutorials .
Code cloud warehouse synchronization notes , You can take it yourself. Welcome star correct :https://gitee.com/noblegasesgoo/notes
If something goes wrong, I hope the leaders in the comment area can discuss and correct each other , Maintain the health of the community. Let's work together , There is no tolerance for wrong knowledge .
—————————————————————— Love you noblegasesgoo
边栏推荐
- The gates of Europe
- Building a basic buildreoot file system
- MIT science and Technology Review released the list of innovators under the age of 35 in 2022, including alphafold authors, etc
- Grep output with multiple colors- Grep output with multiple Colors?
- Word中添加代码块(转载)
- 清华只能排第3?2022软科中国大学AI专业排名发布
- Spin lock exploration
- 【剑指Offer】53 - I. 在排序数组中查找数字 I
- Deep understanding of JVM (III) - memory structure (III)
- ASP. Net password encryption and password login
猜你喜欢

Customer relationship CRM management system based on SSH
MySQL之零碎知识点

自旋锁探秘

同济、阿里的CVPR 2022最佳学生论文奖研究了什么?这是一作的解读

Word中添加代码块(转载)

MIT科技评论2022年35岁以下创新者名单发布,含AlphaFold作者等

Redis (VI) - master-slave replication

. Net ORM framework hisql practice - Chapter 1 - integrating hisql

Daily interview 1 question - how to prevent CDN protection from being bypassed
![[Netease Yunxin] playback demo build: unable to convert parameter 1 from](/img/6e/41e1eafd4c863c9e5f3a545b69a257.png)
[Netease Yunxin] playback demo build: unable to convert parameter 1 from "asyncmodalrunner *" to "std:: nullptr\u T"**
随机推荐
每日面试1题-如何防止CDN防护被绕过
[software testing] basic knowledge of software testing you need to know
Add code block in word (Reprint)
Inventory in the first half of 2022: summary of major updates and technical points of 20+ mainstream databases
现在玩期货需要注意什么,在哪里开户比较安全,我第一次接触
What does software testing need to learn? Test learning outline sorting
5g business is officially commercial. What are the opportunities for radio and television?
Development: how to install offline MySQL in Linux system?
Conception d'un centre commercial en ligne basé sur SSH
Solution: STM32 failed to parse data using cjson
Deep understanding of JVM (VI) -- garbage collection (III)
Nft: unlimited possibilities to open the era of encryption Art
LRN local response normalization
Word中添加代码块(转载)
Small Tools(3) 集成Knife4j3.0.3接口文档
K-line diagram must be read for quick start
Flutter custom component
【机器学习】K-means聚类分析
NFT铸造交易平台开发详情
Is there an optimal solution to the energy consumption anxiety in the data center?