当前位置:网站首页>(CVPR 2020) RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
(CVPR 2020) RandLA-Net: Efficient Semantic Segmentation of Large-Scale Point Clouds
2022-06-10 18:15:00 【Fish Xiaoyu】
Abstract
We studied large-scale 3D Effective semantic segmentation of point cloud . By relying on expensive sampling techniques or computationally intensive preprocessing / Post processing steps , Most of the existing methods can only be trained and operated on small-scale point clouds . In this paper , We introduced RandLA-Net, This is an efficient and lightweight neural architecture , The semantics of each point of a large-scale point cloud can be directly inferred . The key to our method is to use random point sampling instead of more complex point selection methods . Although computing and memory efficiency is very high , But random sampling may accidentally discard key features . To overcome this problem , We introduce a new local feature aggregation module to gradually add each 3D Receptive field of point , So as to effectively preserve the geometric details . A lot of experiments show that , our RandLA-Net It can be processed at one time 100 10000 points , Faster than existing methods 200 times . Besides , our RandLA-Net In two large benchmarks Semantic3D and SemanticKITTI It obviously surpasses the most advanced semantic segmentation methods .
1. Introduction
On a large scale 3D The effective semantic segmentation of point cloud is a real-time intelligent system ( Such as autonomous driving and augmented reality ) The basic and essential abilities of . A key challenge is that the original point cloud obtained by the depth sensor is usually irregularly sampled 、 Unstructured and unordered . Although deep convolution networks are structured 2D Excellent performance in computer vision tasks , But they cannot be directly applied to such unstructured data .
lately , Pioneering work PointNet[43] It has become a promising direct treatment 3D The method of point cloud . It uses a shared multi-layer perceptron (MLP) Learn every feature . This is computationally valid , But you can't capture broader context information for each point . In order to learn more abundant local structures , Subsequently, many special neural modules were quickly introduced . These modules can usually be classified as :1) Adjacent feature pool [44, 32, 21, 70, 69], 2) Figure message passing [57, 48, 55, 56, 5, 22, 34], 3)kernel-based convolution[49, 20, 60, 29, 23, 24, 54, 38] and 4) Attention based aggregation [61, 68, 66, 42]. Although these methods have achieved impressive results in object recognition and semantic segmentation , But almost all of these methods are limited to minimal 3D Point cloud ( for example ,4k Point or 1×1 Rice block ), It cannot be directly extended to larger point clouds ( for example , Millions of points and the largest 200×200 rice ), No preprocessing steps such as block partitioning are required . There are three reasons for this limitation . 1) The commonly used point sampling methods in these networks are either computationally expensive , Or memory efficiency is low . for example , Widely used farthest point sampling [44] need 200 How many seconds to 100 Of ten thousand points 10% sampling .2) Most existing local feature learners usually rely on computationally expensive kernel or graph construction , Therefore, a large number of points cannot be processed .3) For point clouds that typically consist of hundreds of target scales , The existing local feature learners can not capture complex structures , Or inefficiency , Because their receptive field size is limited .
Some recent work has begun to solve the task of directly processing large-scale point clouds .SPG[26] Preprocess the big point cloud into hypergraph before applying neural network to learn the semantics of each super point .FCPN[45] and PCT[7] Both combine voxelization and point level network to deal with massive point clouds . Although they achieve good segmentation accuracy , But the calculation of pretreatment and voxelization steps is too large , Cannot be deployed in a real-time application .
In this paper , Our goal is to design a neural architecture with high memory and computational efficiency , It can directly handle large-scale in a single pass 3D Point cloud , Without any pretreatment / Post processing steps , For example, voxelization 、 Block segmentation or graphic construction . However , This task is very challenging , Because it needs :1) A sampling method with high memory and computing efficiency , To gradually down sample large-scale point clouds to adapt to the current GPU The limitation of , as well as 2) An effective local feature learner , To gradually increase the acceptance field size to preserve complex geometry . So , Firstly, we systematically prove that random sampling is the key driving force for deep neural networks to effectively deal with large-scale point clouds . however , Random sampling discards critical information , Especially for targets with sparse points . In order to deal with the potential adverse effects of random sampling , We propose a new efficient local feature aggregation module , To capture complex local structures on a gradually smaller set of points .
In the existing sampling methods , Farthest point sampling and inverse density sampling are most commonly used in small-scale point clouds [44,60,33,70,15]. Since point sampling is a basic step in these networks , We are the first 3.2 The relative advantages of different methods are studied in section , Among them, we see that the common sampling methods limit the scaling of large point clouds , And become an important bottleneck of real-time processing . However , We believe that random sampling is by far the most suitable component for large-scale point cloud processing , Because it is fast and can be effectively expanded . Random sampling is not without cost , Because prominent point features may be accidentally discarded , And it can not be directly used in the existing network without causing performance loss . To overcome this problem , We are 3.3 Section designs a new local feature aggregation module , It can effectively learn complex local structures by gradually increasing the size of receptive fields in each nerve layer . especially , For each 3D spot , We first introduce a local space coding (LocSE) Element to explicitly preserve local geometry . secondly , We use attention pools to automatically preserve useful local features . Third , We will have more than one LocSE Cells and attention pools are stacked into an expanded residual block , The effective receptive field of each point is greatly increased . Please note that , All these neural components are shared as MLP Realized , Therefore, it has significant memory and computational efficiency .
Overall speaking , Based on the principle of simple random sampling and effective local feature aggregator , Our efficient neural architecture RandLA-Net Not only faster than existing large-scale point cloud methods 200 times , And more than Semantic3D[17] and SemanticKITTI[3] The most advanced semantic segmentation method on the benchmark . chart 1 Shows the qualitative results of our method . Our main contribution is :
We analyze and compare the existing sampling methods , Random sampling is determined as the most suitable component for effective learning on large-scale point clouds .
We propose an efficient local feature aggregation module , Keep the complex local structure by gradually increasing the receptive field of each point .
We demonstrated significant memory and computational gains on the baseline , And it surpasses the most advanced semantic segmentation methods on multiple large-scale benchmarks .
chart 1.PointNet++[44]、SPG[26] Stay with us SemanticKITTI[3] The semantic segmentation result of the method on . our RandLA-Net stay 3D Direct processing in space 150 × 130 × 10 150 \times 130 \times 10 150×130×10 m 1 0 5 10^{5} 105 A large point cloud of points only needs 0.04 second , Than SPG fast 200 times . The red circle highlights the excellent segmentation accuracy of our method .

2. Related Work
In order to learn from 3D Feature extraction from point cloud , Traditional methods often rely on handmade features [11、47、25、18]. Recent learning based approaches [16, 43, 37] It mainly includes projection based as outlined here 、 Voxel based and point based schemes .
(1) Projection and Voxel Based Networks. In order to take advantage of 2D CNN The success of the , A lot of work [30、8、63、27] take 3D Point cloud projection / Flatten to 2D Image to solve the target detection task . however , Geometric details may be lost during projection . perhaps , You can convert a point cloud voxel to 3D grid , And then in [14、28、10、39、9] Application of powerful 3D CNN. Although they have achieved leading results in semantic segmentation and object detection , But their main limitation is the high computational cost , Especially when dealing with large-scale point clouds .
(2) Point Based Networks. suffer PointNet/PointNet++[43, 44] Inspired by the , Many recent works have introduced complex neural modules to learn the local features of each point . These modules can usually be classified as 1) Adjacent feature pool [32, 21, 70, 69], 2) Figure message passing [57, 48, 55, 56, 5, 22, 34, 31], 3) Kernel based convolution [49, 20, 60, 29, 23, 24, 54, 38] and 4) Attention based aggregation [61, 68, 66, 42]. Although these networks show promising results on the small point cloud , But because of its high computing and memory costs , Most of them cannot be directly extended to large scenes . Compared with them , What we proposed RandLA-Net There are three differences :1) It only depends on random sampling in the network , So you need less memory and less computation ; 2) The proposed local feature aggregator can obtain continuous and larger receptive fields by explicitly considering local spatial relations and point features , So it is more effective and robust for learning complex local patterns ;3) The entire network is made up only of shared MLP form , Do not rely on any expensive operations , For example, graph building and kernel , So it is very effective for large-scale point cloud .
(3) Learning for Large-scale Point Clouds. SPG[26] Preprocess the big point cloud into a super point graph , To learn the semantics of each super point . Current FCPN[45] and PCT[7] Apply voxel based and point based networks to deal with massive point clouds . However , Graph Segmentation and voxelization are computationally expensive . by comparison , our RandLA-Net It's end-to-end trainable , No additional pretreatment is required / Post processing steps .
3. RandLA-Net
3.1. Overview
Pictured 2 Shown , Given a large-scale point cloud with millions of points spanning hundreds of meters , To process it with a deep neural network , It is inevitable that these points need to be sampled down gradually and effectively in each neural layer , Without losing useful point features . In our RandLA-Net in , We suggest a simple and fast random sampling method to greatly reduce the point density , At the same time, a well-designed local feature aggregator is applied to retain outstanding features . This makes the whole network achieve an excellent trade-off between efficiency and effectiveness .
chart 2. stay RandLA-Net In every layer of , Large scale point clouds are significantly downsampled , But it can retain the features required for accurate segmentation .

3.2. The quest for efficient sampling
Existing point sampling methods [44, 33, 15, 12, 1, 60] It can be roughly divided into heuristic and learning based methods . however , There is still no standard sampling strategy suitable for large-scale point clouds . therefore , We analyze and compare their relative advantages and complexities as follows .
(1) Heuristic Sampling
Farthest point sampling (FPS): In order to have N N N Large scale point cloud of points P \boldsymbol{P} P In the sample K K K A little bit ,FPS Return to the metric space { p 1 ⋯ ⋅ p k ⋯ p K } \left\{p_{1} \cdots \cdot p_{k} \cdots p_{K}\right\} { p1⋯⋅pk⋯pK} The reordering of , Make each p k p_{k} pk Is the distance before k − 1 k - 1 k−1 The farthest point .FPS stay [44, 33, 60] It is widely used in semantic segmentation of small point sets . Although it covers the whole point set well , But its computational complexity is O ( N 2 ) \mathcal{O}\left(N^{2}\right) O(N2). For large scale point clouds ( N ∼ 1 0 6 ) \left(N \sim 10^{6}\right) (N∼106),FPS In a single GPU Up to... Is required for upper processing 200 second . This explanation FPS Not applicable to large-scale point clouds .
Inverse density importance sampling (IDIS): In order to learn from N N N Sampling in points K K K A little bit ,IDIS According to the density of each point N N N Reorder points , Then choose before K K K A little bit [15]. The computational complexity is about O ( N ) \mathcal{O}(N) O(N). Based on experience , Handle 1 0 6 10^{6} 106 One point needs 10 second . And FPS comparison ,IDIS More efficient , But it is also more sensitive to outliers . however , It is still too slow to use in real-time systems .
Random sampling (RS): Random sampling from the original N N N Select evenly among the points K K K A little bit . Its computational complexity is O ( 1 ) \mathcal{O}(1) O(1), Independent of the total number of input points , That is, it is constant time , So it has inherent scalability . And FPS and IDIS comparison , Random sampling has the highest computational efficiency , Regardless of the size of the input point cloud . Handle 1 0 6 10^{6} 106 Points only need 0.004s.
(2) Learning-based Sampling
Generator based sampling (GS):GS[12] Learn to generate a small set of points to approximate the original large set of points . However ,FPS It is usually used to match the generated subset with the original set in the reasoning stage , This results in additional calculations . In our experiment , Yes 1 0 6 10^{6} 106 Point 10% A maximum of... Is required for sampling 1200 second .
Sampling based on continuous relaxation (CRS):CRS Method [1, 66] Use the reparameterization technique to relax the sampling operation to the continuous domain for end-to-end training . especially , Each sampling point is learned based on the weighted sum of the entire point cloud . When all new points are sampled simultaneously by one matrix multiplication , It leads to a large weight matrix , This leads to unbearable memory costs . for example , It is estimated that more than 300 GB Of memory is used for sampling 1 0 6 10^{6} 106 Point 10%.
chart 3. Proposed local feature aggregation module . The top panel shows the location space coding block of the extracted feature , And an attention pooling mechanism that weights the most important adjacent features based on local context and geometry . The bottom panel shows how to link two of these components together , To increase the receptive field size in the residual block .

- Sampling based on policy gradient (PGS):PGS The sampling operation is formulated as a Markov decision process [62]. It sequentially learns the probability distribution to sample points . However , When the point cloud is large , Due to the great exploration space , The learning probability has a high variance . for example , Right 1 0 6 10^{6} 106 Point 10% sampling , Exploring space is C 1 0 6 1 0 5 \mathrm{C}_{10^{6}}^{10^{5}} C106105, It is unlikely to learn an effective sampling strategy . We found from experience that , If PGS For large point clouds , The network is difficult to converge .
Overall speaking ,FPS、IDIS and GS The calculation cost of is too high , Cannot be applied to large-scale point clouds . CRS Method has too much memory , and PGS It's hard to learn . by comparison , Random sampling has the following two advantages :1) It has remarkable computational efficiency , Because it has nothing to do with the total number of input points ,2) It does not require additional computing memory . therefore , We can safely draw a conclusion , Compared to all existing alternatives , Random sampling is by far the most suitable method for dealing with large-scale point clouds . However , Random sampling may cause many useful point features to be discarded . To overcome it , We propose a powerful local feature aggregation module , As described in the following section .
3.3. Local Feature Aggregation
Pictured 3 Shown , Our local feature aggregation module is applied in parallel to each 3D spot , It consists of three neural units :1) Local space coding (LocSE)、2) Attention pooling and 3) Expansion residual block .
(1) Local Spatial Encoding
Given a point cloud P \boldsymbol{P} P And the characteristics of each point ( for example , original RGB Or intermediate learning characteristics ), This local spatial coding unit explicitly embeds all adjacent points x-y-z coordinate , So that the corresponding point features always know their relative spatial position . This allows LocSE Cells explicitly observe local geometric patterns , Thus, the whole network will benefit from effectively learning the complex local structure . especially , This module includes the following steps :
Look for adjacent points . For the first i A little bit , In order to improve efficiency , First, through the simple nearest neighbor (KNN) The algorithm collects its neighboring points .KNN Based on point by point Euclidean distance .
Relative point position code . For the center point p i p_{i} pi Every recent K K K spot { p i 1 ⋯ p i k ⋯ p i K } \left\{p_{i}^{1} \cdots p_{i}^{k} \cdots p_{i}^{K}\right\} { pi1⋯pik⋯piK}, We explicitly encode the relative point positions as follows :
r i k = M L P ( p i ⊕ p i k ⊕ ( p i − p i k ) ⊕ ∥ p i − p i k ∥ ) ( 1 ) \mathbf{r}_{i}^{k}=M L P\left(p_{i} \oplus p_{i}^{k} \oplus\left(p_{i}-p_{i}^{k}\right) \oplus\left\|p_{i}-p_{i}^{k}\right\|\right) \quad\quad\quad\quad(1) rik=MLP(pi⊕pik⊕(pi−pik)⊕∥∥pi−pik∥∥)(1)
among p i p_{i} pi and p i k p_{i}^{k} pik Yes x-y-z Location , ⊕ \oplus ⊕ It's a join operation , ∥ ⋅ ∥ \|\cdot\| ∥⋅∥ Calculate the Euclidean distance between the adjacent point and the center point . Seems to be r i k \mathbf{r}_{i}^{k} rik It is encoded from the position of redundant points . Interestingly , This often helps the network learn local features and obtain good performance in practice .
Point feature enhancement . For each adjacent point p i k p_{i}^{k} pik, Position the coded relative point r i k \mathbf{r}_{i}^{k} rik Its corresponding point feature f i k \mathbf{f}_{i}^{k} fik Connect , Get an enhanced eigenvector f ^ i k \hat{\mathbf{f}}_{i}^{k} f^ik.
Final ,LocSE The output of the cell is a new set of adjacent features F ^ i = { f ^ i 1 ⋯ f ^ i k ⋯ f ^ i K } \hat{\mathbf{F}}_{i}=\left\{\hat{\mathbf{f}}_{i}^{1} \cdots \hat{\mathbf{f}}_{i}^{k} \cdots \hat{\mathbf{f}}_{i}^{K}\right\} F^i={ f^i1⋯f^ik⋯f^iK}, It explicitly encodes the central point p i p_{i} pi Local geometry of . We have taken note of recent work [36] Point positions are also used to improve semantic segmentation . However , These positions are for learning [36] Point fraction in , And ours LocSE The relative positions are explicitly encoded to enhance the features of adjacent points .
(2) Attentive Pooling
This neural unit is used to aggregate a set of adjacent point features F ^ i \hat{\mathbf{F}}_{i} F^i. Existing work [44, 33] Usually the maximum / Mean pooling to hard integrate adjacent features , Most of the information is lost . by comparison , We turn to powerful attention mechanisms to automatically learn important local features . especially , suffer [65] Inspired by the , Our attention pool unit consists of the following steps .
Calculate the attention score . Given a set of local features F ^ i = { f ^ i 1 ⋯ f ^ i k ⋯ f ^ i K } \hat{\mathbf{F}}_{i}=\left\{\hat{\mathbf{f}}_{i}^{1} \cdots \hat{\mathbf{f}}_{i}^{k} \cdots \hat{\mathbf{f}}_{i}^{K}\right\} F^i={ f^i1⋯f^ik⋯f^iK} We design a shared function g ( ) g() g() To learn the unique attention score for each feature . Basically , function g ( ) g() g() Shared by one MLP And then softmax form . Its formal definition is as follows :
s i k = g ( f ^ i k , W ) ( 2 ) \mathbf{s}_{i}^{k}=g\left(\hat{\mathbf{f}}_{i}^{k}, \boldsymbol{W}\right) \quad\quad\quad\quad(2) sik=g(f^ik,W)(2)
among W W W It's sharing MLP Learnable weight of .
To sum by weight . The attention score of learning can be regarded as the important feature of automatic selection soft mask. In form , The weighted sum of these features is as follows :
f ~ i = ∑ k = 1 K ( f ^ i k ⋅ s i k ) ( 3 ) \tilde{\mathbf{f}}_{i}=\sum_{k=1}^{K}\left(\hat{\mathbf{f}}_{i}^{k} \cdot \mathbf{s}_{i}^{k}\right) \quad\quad\quad\quad(3) f~i=k=1∑K(f^ik⋅sik)(3)
in general , Given input point cloud P \boldsymbol{P} P, For the first i i i A little bit p i p_{i} pi, Our location and attention pool unit learns to aggregate its K K K Geometric patterns and features of the nearest points , And finally generate information feature vector f ~ i \tilde{\mathbf{f}}_{i} f~i.
(3) Dilated Residual Block
Because the big point cloud will be heavily downsampled , Therefore, we hope to significantly increase the receptive field of each point , In this way, even if some points are deleted , The geometric details of the input point cloud are also more likely to be preserved . Pictured 3 Shown , Be successful in ResNet[19] And effective network expansion [13] Inspired by the , We will have more than one LocSE and Attentive Pooling The cells and jump connections are stacked as expanded residual blocks .
To further illustrate our ability to expand the residual block , chart 4 Show red 3D Point at the first time LocSE/Attentive Pooling Observed after operation K K K Adjacent points , Then it can receive up to K 2 K^{2} K2 Information of adjacent points , That is, the neighborhood after the second time of its two hops . This is a cheap method to expand receptive field and effective neighborhood through feature propagation . Theoretically , The more units we stack , The stronger this square is , Because its scope of influence is becoming larger and larger . however , More cells will inevitably sacrifice the overall computational efficiency . Besides , The whole network is likely to be over fitted . In our RandLA-Net in , We simply put two groups LocSE and Attentive Pooling Stack as standard residual blocks , There is a satisfactory balance between efficiency and effectiveness .
Overall speaking , Our local feature aggregation module aims to effectively preserve complex local structures by explicitly considering adjacent geometries and significantly increasing receptive fields . Besides , This module consists only of feedforward (feed-forward)MLP form , Therefore, the calculation efficiency is high .
chart 4. Significantly increase the receptive field at each point ( Dotted circle ) Diagram of the extended residual block of , Colored dots represent aggregated features . L: Local space coding ,A: Attention pooling .

3.4. Implementation
We stack multiple local feature aggregation modules and random sampling layers to achieve RandLA-Net. The detailed architecture is given in the appendix . We use... With default parameters Adam Optimizer . The initial learning rate is set to 0.01, Every epoch And then it goes down 5%. Number of closest points K K K Set to 16. In order to train our RandLA-Net, We sample a fixed number of points from each point cloud ( ∼ 1 0 5 ) \left(\sim 10^{5}\right) (∼105) As input . During the test , The whole original point cloud is input into our network to infer the semantics of each point , There is no need to pre - partition geometry or blocks / post-processing . All experiments were conducted in NVIDIA RTX2080Ti GPU on .
4. Experiments
4.1. Efficiency of Random Sampling
In this section , We evaluate the efficiency of existing sampling methods based on experience , Including the first 3.2 Section FPS、IDIS、RS、GS、CRS and PGS. Specially , We did the following 4 Group experiment .
- The first 1 Group . Given a small-scale point cloud ( ∼ 1 0 3 \sim 10^{3} ∼103 A little bit ), We use each sampling method to down sample it step by step . say concretely , The point cloud is down sampled in five steps , In a single GPU In each step on, only 25% The point of , That is, four times the extraction rate . This means that only ∼ ( 1 / 4 ) 5 × 1 0 3 \sim(1 / 4)^{5} \times 10^{3} ∼(1/4)5×103 A little bit . This down sampling strategy simulates PointNet++[44] The process used in . For each sampling method , We summarized its time and memory consumption for comparison .
chart 5. Time and memory consumption of different sampling methods . Due to limited GPU Memory , The dotted line indicates the estimated value .

- The first 2/3/4 Group . The total number of points increases to a large extent , That is to say, the 1 0 5 10^{5} 105、 1 0 5 10^{5} 105 and 1 0 6 10^{6} 106 P.m. . We use and 1 Group the same five sampling steps .
analysis . chart 5 The total time and memory consumption of each sampling method for different scale point clouds are compared . It can be seen that :1) For small point clouds ( ∼ 1 0 3 \sim 10^{3} ∼103), All sampling methods tend to have similar time and memory consumption , And is unlikely to incur a heavy or limited computational burden . 2) For large scale point clouds ( ∼ 1 0 6 \sim 10^{6} ∼106),FPS/IDIS/GS/CRS/PGS Or very time-consuming , Or consume memory . by comparison , Random sampling has excellent time and memory efficiency in general . This result clearly shows that , Most existing networks [44、33、60、36、70、66] It can only be optimized on small point clouds , Mainly because they rely on expensive sampling methods . Inspired by this , We are RandLA-Net An effective random sampling strategy is used in .
4.2. Efficiency of RandLA-Net
In this section , We systematically evaluated our RandLA-Net The overall efficiency of semantic segmentation on large-scale point clouds in the real world . especially , We are SemanticKITTI[3] Evaluation on dataset RandLA-Net, Got our network in sequence 08 Total time spent on , All in all 4071 Secondary point cloud scanning . We also evaluated recent representative works on the same dataset [43、44、33、26、54] Time consumption of . For a fair comparison , We will scan the same number of points each time ( namely 81920) Input each neural network .
Besides , We also evaluated RandLA-Net And baseline memory consumption . especially , We not only report the total number of parameters for each network , The maximum value of each network as input in a single pass is also measured 3D points , To infer the semantics of each point . Please note that , All experiments were performed with AMD 3700X @3.6GHz CPU and NVIDIA RTX2080Ti GPU On the same machine .
analysis . surface 1 It quantitatively shows the total time and memory consumption of different methods . It can be seen that ,1)SPG[26] The minimum number of network parameters , However, due to the expensive geometric division and hypergraph construction steps , The longest time to process point clouds ; 2)PointNet++[44] and PointCNN[33] The cost of computing is also high , Mainly because FPS Sampling operation ;3)PointNet[43] and KPConv[54] Due to memory inefficient operation , It is impossible to obtain a super large-scale point cloud in one pass ( for example 1 0 6 10^{6} 106 A little bit ).4) Because of the simple random sampling and the high efficiency based on MLP Local feature aggregator for , our RandLA-Net In the shortest time (4071 Frame average 185 second → about 22FPS) To infer the semantic tag cloud of each large-scale point ( most 1 0 6 10^{6} 106 spot ).
surface 1.SemanticKITTI[3] Data set sequence 08 The computation time of different semantic segmentation methods 、 Network parameters and maximum input points .

4.3. Semantic Segmentation on Benchmarks
In this section , We evaluated on three large public datasets RandLA-Net Semantic segmentation : Outside Semantic3D[17] and SemanticKITTI[3] And indoor S3DIS[2].
(1) Yes Semantic3D The evaluation of . Semantic3D Data sets [17] from 15 Point clouds and for training 15 A point cloud for online testing . Each point cloud has at most 1 0 8 10^{8} 108 A little bit , In the real world 3D The space has the largest coverage 160×240×30 rice . original 3D Point belongs to 8 Categories , contain 3D coordinate 、RGB Information and intensity . We only use 3D Coordinate and color information to train and test our RandLANet. Average intersection and union ratio of all classes (mIoU) And overall accuracy (OA) Used as a standard indicator . For a fair comparison , We only include recently released strong baselines (strong baselines)[4, 52, 53, 46, 69, 56, 26] And the most advanced methods at present KPConv[54] Result .
surface 2 The quantitative results of different methods are presented . RandLA-Net stay mIoU and OA Aspect is obviously superior to all existing methods . It is worth noting that , In addition to low vegetation and scanning art ,RandLANet Excellent performance in six of the eight categories .
surface 2. Semantic3D(reduced-8)[17] Quantitative results of different methods . Compare only recently published methods . On 2020 year 3 month 31 A visit to .

surface 3. SemanticKITTI[3] Quantitative results of different methods . Compare only recently published methods , All scores are from the online single scan evaluation track . On 2020 year 3 month 31 A visit to .

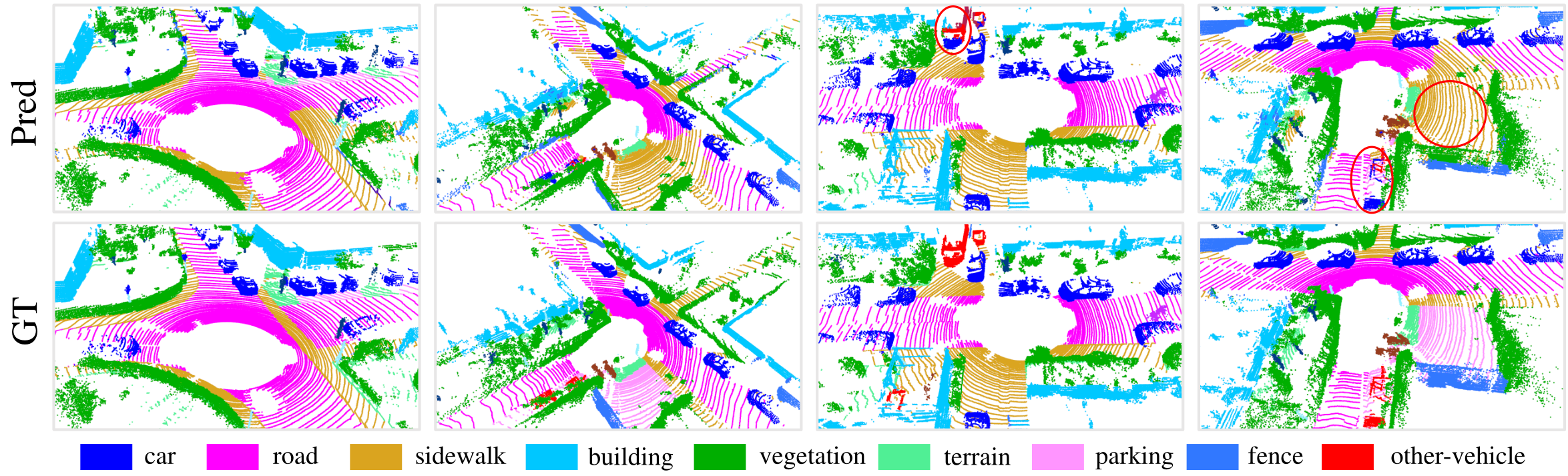
chart 6. RandLA-Net stay SemanticKITTI[3] Qualitative results on validation sets . Red circles indicate failure cases .
(2) Yes SemanticKITTI The evaluation of . SemanticKITTI[3] from 43552 A densely annotated LIDAR Scan composition , Belong to 21 A sequence of . Each scan is a large-scale point cloud , There are about 1 0 5 10^{5} 105 A little bit , stay 3D Across space 160×160×20 rice . The official will sequence 00∼07 and 09∼10(19130 Scans ) Used for training , Sequence 08(4071 Scans ) Used to verify , Sequence 11∼21(20351 Scans ) For online testing . original 3D It's just 3D coordinate , No color information . exceed 19 Category mIoU The score is used as a standard indicator .
surface 3 It shows our RandLANet Quantitative comparison with two recent method series , namely 1) Point based approach [43、26、49、44、51] and 2) Projection based method [58、59、3、40], And the picture 6 Shows RandLA-Net Some qualitative results on the validation split . It can be seen that , our RandLA-Net Much more than all point based methods [43、26、49、44、51]. We also outperform all projection based methods [58, 59, 3, 40], But not significantly , Mainly because RangeNet++[40] Better results have been achieved in small target categories such as traffic signs . However , our RandLA-Net Network parameter ratio RangeNet++[40] Less 40 times , And it's more efficient , Because it doesn't need expensive pre - / Back projection step .
(3) Yes S3DIS The evaluation of . S3DIS Data sets [2] from 271 A room makes up , Belong to 6 It's a big area . Each point cloud is a single room of medium size ( ∼ 20 × 15 × 5 \sim 20 \times 15 \times 5 ∼20×15×5 rice ), With dense 3D spot . To evaluate our RandLA-Net Semantic segmentation , We used the standard in the experiment 6 Re cross validation . A total of 13 Average of classes IoU (mIoU)、 Average class accuracy (mAcc) And overall accuracy (OA).
As shown in the table 4 Shown , our RandLA-Net It achieves performance equivalent to or better than the most advanced methods . Please note that , These baselines [44, 33, 70, 69, 57, 6] Most tend to use complex but expensive operations or sampling to optimize point cloud chunks ( for example , 1 × 1 1 \times 1 1×1 rice ) On the Internet , And a relatively small room is good for them to be divided into small pieces . by comparison ,RandLA-Net Take the entire room as input , And it can effectively infer the semantics of each point in a single pass .
surface 4.S3DIS Data sets [2] Quantitative results of different methods (6 Re cross validation ). Include only recently released methods .

4.4. Ablation Study
Because in the 4.1 The influence of random sampling is fully studied in section , We performed the following ablation studies on our local feature aggregation module . All ablation networks are in sequence 00∼07 and 09∼10 Training on , And in SemanticKITTI Data sets [3] Sequence 08 Test on .
(1) Remove local space coding (LocSE). This unit makes each 3D The point can clearly observe its local geometry . Remove locSE after , We directly input the local point feature into the subsequent attention pool .
(2∼4) use max/mean/sum pooling Instead of attentive pooling. The attention pool unit learns to automatically combine all local point features . by comparison , Widely used max/mean/sum pooling Tends to hard select or combine features , So their performance may not be optimal .
(5) Simplified extended residual block . The expanded residual block is stacked with multiple LocSE Units and attention pools , Greatly expanded each 3D Receptive field of point . By simplifying this block , We only use one per layer LocSE Unit and attention pooling , in other words , We're not the same RandLA-Net That links multiple blocks .
surface 5 All ablation networks were compared mIoU fraction . thus , We can see that :1) The biggest impact is caused by chained spatial embedding and the removal of attention pooling blocks . This is in the picture 4 Highlighted in , It shows how to use two chained blocks to allow information to spread from a wider neighborhood , About K 2 K^{2} K2 A point, not just K K K. This is especially important for random sampling , Random sampling does not guarantee that a specific set of points will be preserved .2) The removal of local spatial coding units shows the second largest impact on performance , It shows that this module is necessary for learning local and relative geometric context effectively .3) Removing the attention module will degrade performance because it cannot effectively retain useful features . From this ablation study , We can see how the proposed neural units complement each other to achieve our most advanced performance .
surface 5. Based on our complete RandLA-Net The average of all ablation networks IoU fraction .

5. Conclusion
In this paper , We have proved that the use of lightweight network architecture can effectively segment large-scale point clouds . Compared to most current methods that rely on expensive sampling strategies , We use random sampling in our framework to significantly reduce memory footprint and computational costs . A local feature aggregation module is also introduced , To effectively preserve useful features from a wide range of neighborhoods . A large number of experiments on multiple benchmarks have proved the high efficiency and the most advanced performance of our method . By drawing on recent work [64] And real-time dynamic point cloud processing [35], Extend our end-to-end on large-scale point clouds 3D The framework for instance splitting will be interesting .
References
[1] Abubakar Abid, Muhammad Fatih Balin, and James Zou. Concrete autoencoders for differentiable feature selection and reconstruction. In ICML, 2019.
[2] Iro Armeni, Sasha Sax, Amir R Zamir, and Silvio Savarese. Joint 2D-3D-semantic data for indoor scene understanding. In CVPR, 2017.
[3] Jens Behley, Martin Garbade, Andres Milioto, Jan Quenzel, Sven Behnke, Cyrill Stachniss, and Juergen Gall. SemanticKITTI: A dataset for semantic scene understanding of lidar sequences. In ICCV, 2019.
[4] Alexandre Boulch, Bertrand Le Saux, and Nicolas Audebert. Unstructured point cloud semantic labeling using deep segmentation networks. In 3DOR, 2017.
[5] Chao Chen, Guanbin Li, Ruijia Xu, Tianshui Chen, Meng Wang, and Liang Lin. ClusterNet: Deep hierarchical cluster network with rigorously rotation-invariant representation for point cloud analysis. In CVPR, 2019.
[6] Lin-Zhuo Chen, Xuan-Yi Li, Deng-Ping Fan, Ming-Ming Cheng, Kai Wang, and Shao-Ping Lu. LSANet: Feature learning on point sets by local spatial attention. arXiv preprint arXiv:1905.05442, 2019.
[7] Siheng Chen, Sufeng Niu, Tian Lan, and Baoan Liu. PCT: Large-scale 3D point cloud representations via graph inception networks with applications to autonomous driving. In ICIP, 2019.
[8] Xiaozhi Chen, Huimin Ma, Ji Wan, Bo Li, and Tian Xia. Multi-view 3D object detection network for autonomous driving. In CVPR, 2017.
[9] Yilun Chen, Shu Liu, Xiaoyong Shen, and Jiaya Jia. Fast point R-CNN. In ICCV, 2019.
[10] Christopher Choy, JunY oung Gwak, and Silvio Savarese. 4D spatio-temporal convnets: Minkowski convolutional neural networks. In CVPR, 2019.
[11] Chin Seng Chua and Ray Jarvis. Point signatures: A new representation for 3D object recognition. IJCV, 1997.
[12] Oren Dovrat, Itai Lang, and Shai Avidan. Learning to sample. In CVPR, 2019.
[13] Francis Engelmann, Theodora Kontogianni, and Bastian Leibe. Dilated point convolutions: On the receptive field of point convolutions. In BMVC, 2019.
[14] Benjamin Graham, Martin Engelcke, and Laurens van der Maaten. 3D semantic segmentation with submanifold sparse convolutional networks. In CVPR, 2018.
[15] Fabian Groh, Patrick Wieschollek, and Hendrik P . A. Lensch. Flex-convolution (million-scale point-cloud learning beyond grid-worlds). In ACCV, 2018.
[16] Y ulan Guo, Hanyun Wang, Qingyong Hu, Hao Liu, Li Liu, and Mohammed Bennamoun. Deep learning for 3d point clouds: A survey. arXiv preprint arXiv:1912.12033, 2019.
[17] Timo Hackel, Nikolay Savinov, Lubor Ladicky, Jan D Wegner, Konrad Schindler, and Marc Pollefeys. Semantic3d. net: A new large-scale point cloud classification benchmark. ISPRS, 2017.
[18] Timo Hackel, Jan D Wegner, and Konrad Schindler. Fast semantic segmentation of 3d point clouds with strongly varying density. ISPRS, 2016.
[19] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for image recognition. In CVPR, 2016.
[20] Binh-Son Hua, Minh-Khoi Tran, and Sai-Kit Yeung. Pointwise convolutional neural networks. In CVPR, 2018.
[21] Qiangui Huang, Weiyue Wang, and Ulrich Neumann. Recurrent slice networks for 3D segmentation of point clouds. In CVPR, 2018.
[22] Li Jiang, Hengshuang Zhao, Shu Liu, Xiaoyong Shen, ChiWing Fu, and Jiaya Jia. Hierarchical point-edge interaction network for point cloud semantic segmentation. In ICCV, 2019.
[23] Artem Komarichev, Zichun Zhong, and Jing Hua. A-CNN: Annularly convolutional neural networks on point clouds. In CVPR, 2019.
[24] Shiyi Lan, Ruichi Y u, Gang Y u, and Larry S Davis. Modeling local geometric structure of 3D point clouds using GeoCNN. In CVPR, 2019.
[25] Loic Landrieu, Hugo Raguet, Bruno V allet, Clément Mallet, and Martin Weinmann. A structured regularization framework for spatially smoothing semantic labelings of 3d point clouds. ISPRS, 2017.
[26] Loic Landrieu and Martin Simonovsky. Large-scale point cloud semantic segmentation with superpoint graphs. In CVPR, 2018.
[27] Alex H Lang, Sourabh V ora, Holger Caesar, Lubing Zhou, Jiong Yang, and Oscar Beijbom. PointPillars: Fast encoders for object detection from point clouds. In CVPR, 2019.
[28] Truc Le and Ye Duan. PointGrid: A deep network for 3D shape understanding. In CVPR, 2018.
[29] Huan Lei, Naveed Akhtar, and Ajmal Mian. Octree guided cnn with spherical kernels for 3D point clouds. In CVPR, 2019.
[30] Bo Li, Tianlei Zhang, and Tian Xia. V ehicle detection from 3D lidar using fully convolutional network. In RSS, 2016.
[31] Guohao Li, Matthias Muller, Ali Thabet, and Bernard Ghanem. Deepgcns: Can gcns go as deep as cnns? In ICCV, October 2019.
[32] Jiaxin Li, Ben M Chen, and Gim Hee Lee. SO-Net: Selforganizing network for point cloud analysis. In CVPR, 2018.
[33] Yangyan Li, Rui Bu, Mingchao Sun, Wei Wu, Xinhan Di, and Baoquan Chen. PointCNN: Convolution on Xtransformed points. In NeurIPS, 2018.
[34] Jinxian Liu, Bingbing Ni, Caiyuan Li, Jiancheng Yang, and Qi Tian. Dynamic points agglomeration for hierarchical point sets learning. In ICCV, 2019.
[35] Xingyu Liu, Mengyuan Yan, and Jeannette Bohg. MeteorNet: Deep learning on dynamic 3D point cloud sequences. In ICCV, 2019.
[36] Y ongcheng Liu, Bin Fan, Shiming Xiang, and Chunhong Pan. Relation-shape convolutional neural network for point cloud analysis. In CVPR, 2019.
[37] Zhijian Liu, Haotian Tang, Y ujun Lin, and Song Han. Pointvoxel cnn for efficient 3d deep learning. In NeurIPS, 2019.
[38] Jiageng Mao, Xiaogang Wang, and Hongsheng Li. Interpolated convolutional networks for 3D point cloud understanding. In ICCV, 2019.
[39] Hsien-Y u Meng, Lin Gao, Y u-Kun Lai, and Dinesh Manocha. VV-net: V oxel vae net with group convolutions for point cloud segmentation. In ICCV, 2019.
[40] Andres Milioto, Ignacio Vizzo, Jens Behley, and Cyrill Stachniss. RangeNet++: Fast and accurate lidar semantic segmentation. In IROS, 2019.
[41] Andriy Mnih and Karol Gregor. Neural variational inference and learning in belief networks. arXiv preprint arXiv:1402.0030, 2014.
[42] Anshul Paigwar, Ozgur Erkent, Christian Wolf, and Christian Laugier. Attentional pointnet for 3d-object detection in point clouds. In CVPRW, 2019.
[43] Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. PointNet: Deep learning on point sets for 3D classification and segmentation. In CVPR, 2017.
[44] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. PointNet++: Deep hierarchical feature learning on point sets in a metric space. In NeurIPS, 2017.
[45] Dario Rethage, Johanna Wald, Jurgen Sturm, Nassir Navab, and Federico Tombari. Fully-convolutional point networks for large-scale point clouds. In ECCV, 2018.
[46] Xavier Roynard, Jean-Emmanuel Deschaud, and Franc ¸ois Goulette. Classification of point cloud scenes with multiscale voxel deep network. arXiv preprint arXiv:1804.03583, 2018.
[47] Radu Bogdan Rusu, Nico Blodow, and Michael Beetz. Fast point feature histograms (fpfh) for 3D registration. In ICRA, 2009.
[48] Yiru Shen, Chen Feng, Yaoqing Yang, and Dong Tian. Mining point cloud local structures by kernel correlation and graph pooling. In CVPR, 2018.
[49] Hang Su, V arun Jampani, Deqing Sun, Subhransu Maji, Evangelos Kalogerakis, Ming-Hsuan Yang, and Jan Kautz. SPLA TNet: sparse lattice networks for point cloud processing. In CVPR, 2018.
[50] Richard S Sutton, David A McAllester, Satinder P Singh, and Yishay Mansour. Policy gradient methods for reinforcement learning with function approximation. In NeurIPS, 2000.
[51] Maxim Tatarchenko, Jaesik Park, Vladlen Koltun, and QianYi Zhou. Tangent convolutions for dense prediction in 3D. In CVPR, 2018.
[52] Lyne Tchapmi, Christopher Choy, Iro Armeni, JunY oung Gwak, and Silvio Savarese. Segcloud: Semantic segmentation of 3D point clouds. In 3DV, 2017.
[53] Hugues Thomas, Franc ¸ois Goulette, Jean-Emmanuel Deschaud, and Beatriz Marcotegui. Semantic classification of 3D point clouds with multiscale spherical neighborhoods. In 3DV, 2018.
[54] Hugues Thomas, Charles R Qi, Jean-Emmanuel Deschaud, Beatriz Marcotegui, Franc ¸ois Goulette, and Leonidas J Guibas. KPConv: Flexible and deformable convolution for point clouds. In ICCV, 2019.
[55] Chu Wang, Babak Samari, and Kaleem Siddiqi. Local spectral graph convolution for point set feature learning. In ECCV, 2018.
[56] Lei Wang, Y uchun Huang, Yaolin Hou, Shenman Zhang, and Jie Shan. Graph attention convolution for point cloud semantic segmentation. In CVPR, 2019.
[57] Y ue Wang, Y ongbin Sun, Ziwei Liu, Sanjay E. Sarma, Michael M. Bronstein, and Justin M. Solomon. Dynamic graph cnn for learning on point clouds. ACM Transactions on Graphics (TOG), 2019.
[58] Bichen Wu, Alvin Wan, Xiangyu Y ue, and Kurt Keutzer. Squeezeseg: Convolutional neural nets with recurrent crf for real-time road-object segmentation from 3D lidar point cloud. In ICRA, 2018.
[59] Bichen Wu, Xuanyu Zhou, Sicheng Zhao, Xiangyu Y ue, and Kurt Keutzer. Squeezesegv2: Improved model structure and unsupervised domain adaptation for road-object segmentation from a lidar point cloud. In ICRA, 2019.
[60] Wenxuan Wu, Zhongang Qi, and Li Fuxin. PointConv: Deep convolutional networks on 3D point clouds. In CVPR, 2018.
[61] Saining Xie, Sainan Liu, Zeyu Chen, and Zhuowen Tu. Attentional shapecontextnet for point cloud recognition. In CVPR, 2018.
[62] Kelvin Xu, Jimmy Ba, Ryan Kiros, Kyunghyun Cho, Aaron Courville, Ruslan Salakhudinov, Rich Zemel, and Y oshua Bengio. Show, attend and tell: Neural image caption generation with visual attention. In ICML, 2015.
[63] Bin Yang, Wenjie Luo, and Raquel Urtasun. Pixor: Realtime 3D object detection from point clouds. In CVPR, 2018.
[64] Bo Yang, Jianan Wang, Ronald Clark, Qingyong Hu, Sen Wang, Andrew Markham, and Niki Trigoni. Learning object bounding boxes for 3D instance segmentation on point clouds. In NeurIPS, 2019.
[65] Bo Yang, Sen Wang, Andrew Markham, and Niki Trigoni. Robust attentional aggregation of deep feature sets for multiview 3D reconstruction. IJCV, 2019.
[66] Jiancheng Yang, Qiang Zhang, Bingbing Ni, Linguo Li, Jinxian Liu, Mengdie Zhou, and Qi Tian. Modeling point clouds with self-attention and gumbel subset sampling. In CVPR, 2019.
[67] Xiaoqing Ye, Jiamao Li, Hexiao Huang, Liang Du, and Xiaolin Zhang. 3D recurrent neural networks with context fusion for point cloud semantic segmentation. In ECCV, 2018.
[68] Wenxiao Zhang and Chunxia Xiao. PCAN: 3D attention map learning using contextual information for point cloud based retrieval. In CVPR, 2019.
[69] Zhiyuan Zhang, Binh-Son Hua, and Sai-Kit Yeung. Shellnet: Efficient point cloud convolutional neural networks using concentric shells statistics. In ICCV, 2019.
[70] Hengshuang Zhao, Li Jiang, Chi-Wing Fu, and Jiaya Jia. Pointweb: Enhancing local neighborhood features for point cloud processing. In CVPR, 2019.
边栏推荐
- pwnable start
- c语言学习回顾---1 基础知识回顾
- Some views on the current CIM (bim+gis) industry
- MMdetection之build_optimizer模块解读
- 内存池原理一(基于整块)
- Summary of all contents of cloud computing setup to ensure that a complete cloud computing server can be built, including node installation, instance allocation, network configuration, etc
- mmcv之Registry类解读
- AOV network topology sorting
- .NET 开源的免费午餐结束了?
- How to locate the hot problem of the game
猜你喜欢

Classic topics of leetcode tree (I)

The latest good article | interpretable confrontation defense based on causal inference

AOV网拓扑排序

The short ticket hypothesis: finding sparse, trainable neural networks

Leetcode 875. Coco, who likes bananas

Abbexa丙烯酰胺-PEG-NHS说明书

IIS安装 部署网站

Numpy - record

c语言---7 初识操作符

JS blur shadow follow animation JS special effect plug-in
随机推荐
4. ssh
XML & XPath parsing
高数_第6章无穷级数__绝对收敛_条件收敛
c语言---12 分支语句switch
c语言---7 初识操作符
改变世界的开发者丨玩转“俄罗斯方块”的瑶光少年
AOV网拓扑排序
Some views on the current CIM (bim+gis) industry
Leetcode 875. 爱吃香蕉的珂珂
仅需三步学会使用低代码ThingJS与森数据DIX数据对接
c语言---9 初识宏、指针
软考不通过能不能补考?解答来了
CodeCraft-22 and Codeforces Round #795 (Div. 2)
Mmdetection build_ Optimizer module interpretation
Unity踩坑记录:如果继承MonoBehaviour,类的构造函数可能会被Unity调用多次,不要在构造函数做初始化工作
传统企业在进行信息化升级的过程中,如何做好信息化顶层设计
Set up an online help center to easily help customers solve problems
苹果放大招!这件事干的太漂亮了……
分享我做Dotnet9博客网站时积累的一些资料
LeetCode 321. 拼接最大数***