当前位置:网站首页>Chapter 4 of machine learning [series] naive Bayesian model
Chapter 4 of machine learning [series] naive Bayesian model
2022-06-11 06:03:00 【Forward ing】
machine learning 【 series 】 Chapter 4 naive Bayesian model
Chapter four Naive bayesian model
List of articles
Preface
This chapter mainly explains the naive Bayesian model in machine learning , First, explain the algorithm principle and programming implementation of naive Bayes , Then through a classic case ----- Tumor prediction model to consolidate the knowledge .
One 、 Algorithm principle of naive Bayesian model
1. Bayesian model with one-dimensional characteristic variables
P(Y|X1) = P(X1|Y)P(Y)/P(X1) In Bayesian formula P(X1) It's called a priori probability ,P(Y|X1) It's called posterior probability , and P(X1|Y) It's called likelihood .2. Bayesian model under two-dimensional characteristic variables
P(Y|X1,X2) = P(X1,X2|Y)P(Y)/P(X1,X2)n Bayesian model under dimensional characteristic variables
P(Y|X1,X2,.....,Xn) = P(X1,X2,....,Xn)P(Y)/P(X1,X2,......,Xn) What this formula means is : In character X1, features X2, features X3 And so on , Category Y Probability of occurrence .
Two 、 Simple code implementation of naive Bayesian model
The simple code implementation of Bayesian model is introduced through the following code ( The Gaussian Bayesian classifier is used here )
from sklearn.naive_bayes import GaussianNB
X = [[1,2],[3,4],[5,6],[7,8],[9,10]]
y = [0,0,0,1,1]
model = GaussianNB()
model.fit(X,y)
print(model.predict([[5,5]]))
---> The output is :
[0]
case analysis : Tumor prediction model
1. Reading data
import pandas as pd
df = pd.read_excel(" Tumor data .xlsx")
2. Divide characteristic variables and target variables
X = df.drop(columns=" The nature of the tumor ")
y = df[" The nature of the tumor "]
3. Model construction and use
# Divide the training set and the test set
from sklearn.model_selection import train_test_split
# X_train,y_train Data of characteristic variables and target variables in the training set ,X_test,y_test Is the characteristic variable and target variable data in the test set
# test_size=0.2, Press 8:2 To divide the training set and the test set
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=1) # train_test_split() Functions are randomly partitioned
# Model structures,
from sklearn.naive_bayes import GaussianNB
nb_clf = GaussianNB() # Gaussian naive Bayesian model
# fit() Function training model , The parameters passed in are the previously obtained training set data X_train,y_train
nb_clf.fit(X_train,y_train)
# 3. Model prediction and evaluation
# nb_clf It is the naive Bayesian model built above
y_pred = nb_clf.predict(X_test)
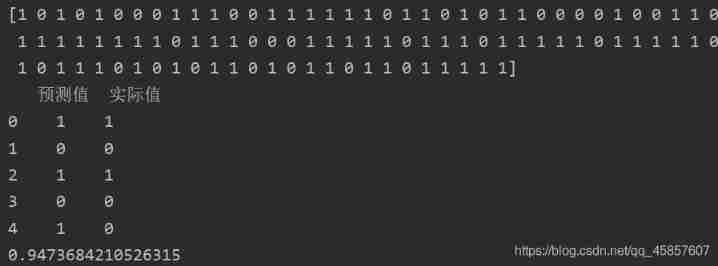
# You can view the front... Of the forecast results through printout 100 term
print(y_pred[:100])
# utilize DataFrame Relevant knowledge points of , Summarize the forecast results y_pred And the actual values in the test set y_test
a = pd.DataFrame()
a[" Predictive value "] = list(y_pred)
a[" actual value "] = list(y_test)
print(a.head())
# View the prediction accuracy of all test set data
from sklearn.metrics import accuracy_score
score = accuracy_score(y_pred,y_test)
print(score)
summary
Reference books :《Python Big data analysis and machine learning business case practice 》边栏推荐
- Compliance management 101: processes, planning and challenges
- NDK R21 compiles ffmpeg 4.2.2+x264 and converts video files using ffmpeg
- [daily exercises] merge two ordered arrays
- Error:Execution failed for task ':app:buildNative'. & gt; A problem occurred'x/x/x/'NDK build' error resolution
- Control your phone with genymotion scratch
- SQLI_ LIBS range construction and 1-10get injection practice
- Continuous update of ansible learning
- 使用Genymotion Scrapy控制手机
- 数组部分方法
- Implementation of data access platform scheme (Youzu network)
猜你喜欢

Login and registration based on servlet, JSP and MySQL

"All in one" is a platform to solve all needs, and the era of operation and maintenance monitoring 3.0 has come

Pycharm usage experience

Servlet

Sqli-labs less-01
数据接入平台方案实现(游族网络)

Review XML and JSON

How to use the markdown editor

Sqli-libs post injection question 11-17 actual combat

Box model
随机推荐
Use of constructors
Fix [no Internet, security] problem
What is a planning BOM?
Build the first power cloud platform
AltiumDesigner2020导入3D Body-SOLIDWORKS三维模型
使用Batch设置IP地址
Set the IP address using batch
做亚马逊测评要了解的知识点有哪些?
[IOS development interview] operating system learning notes
qmake 实现QT工程pro脚本转vs解决方案
Utiliser le fichier Batch Enum
数组部分方法
handler
JIRA software annual summary: release of 12 important functions
How to use the markdown editor
call和apply和bind的区别
Using batch enumeration files
Chapter 2 of machine learning [series] logistic regression model
Vscode plug-in development
使用Genymotion Scrapy控制手机