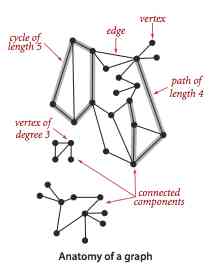
A graph is composed of a set of vertices and a set of edges that can connect two vertices .
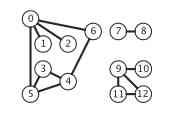
It doesn't matter what the summit is called , But we need a way to refer to these vertices . In general use 0 to V-1 To show that a piece contains V Every vertex in a graph of vertices . This Convention is to facilitate the use of array index to write code that can efficiently access the information of each vertex . Use a symbol table for the names of vertices and 0 To V-1 It is not difficult to establish a one-to-one correspondence between integer values of , Therefore, it is more convenient and general to use the array index as the node name , There's no loss of efficiency .
We use it v-w To express a connection v and w The edge of , w-v It's another representation of this side .
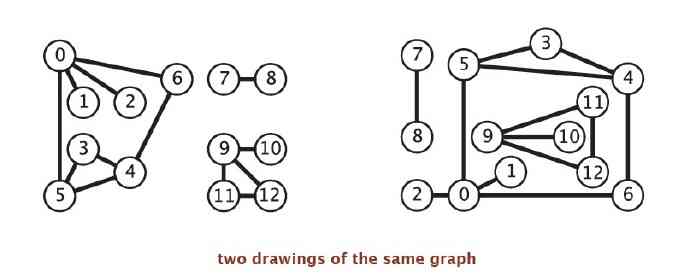
When drawing a picture , Circle the vertex , Use a line segment connecting two vertices to represent an edge , In this way, the structure of the map can be seen intuitively . But this intuition can sometimes mislead us , Because map definition and mapping seem irrelevant , A set of data can draw different shapes of images .
Special graphs
Self ring : That is, an edge connecting a vertex to itself ;
Multiple pictures : Two edges connecting the same pair of vertices become parallel , A graph with parallel edges is called a multigraph .
A graph without parallel edges is called a simple graph .
1. Related terms
When two vertices are connected by an edge , Say these two vertices are adjacent , And say that this edge is attached to these two vertices . The degree of a vertex is the total number of edges attached to it . A subgraph is a subset of all the edges of a graph ( And all the vertices they're attached to ) A picture of the composition . Many computational problems require the identification of various types of subgraphs , In particular, a subgraph consisting of edges that can sequentially connect a series of vertices .
In the picture , A path is a series of vertices connected sequentially by edges . A simple path is a path without repeating vertices . A ring is a path that contains at least one edge and has the same starting and ending points . A simple ring is a ( Except that the starting and ending points must be the same ) A ring without repeating vertices and edges . The length of a path or ring is the number of sides contained in it .
When there is a path between two vertices to connect the two sides , We call one vertex connected to another .
If there is a path from any vertex to another vertex , We call this pair of graphs connected . A disconnected graph consists of several connected parts , They are all connected subgraphs of their poles .
Generally speaking , To deal with a graph, we need to deal with its connected components one by one ( Subgraphs ).
A tree is an acyclic connected graph . A collection of disconnected trees is called a forest . The spanning tree of a connected graph is its subgraph , It contains all the vertices in the graph and is a tree . The spanning forest of a graph is the set of spanning trees of all its connected subgraphs .
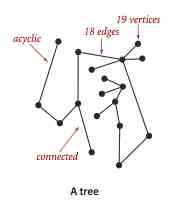
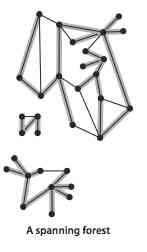
The definition of a tree is very general , With a little change, it can be used to describe the behavior of a program ( Function call level ) Models and data structures . If and only if one contains V A graph of nodes G Meet the following 5 One of the conditions , It's just a tree :
G Yes V - 1 Edges and no rings ;
G Yes V - 1 The edges are connected ;
G It's connected , But deleting any one will make it no longer connected ;
G It's an acyclic graph , But adding any edge produces a loop ;
G There is only one simple path between any pair of vertices in ;
The density of a graph is the proportion of connected vertex pairs to all possible connected vertex pairs . In a sparse graph , There are very few pairs of connected vertices ; And in dense graphs , Only a few pairs of vertices have no edge connection . Generally speaking , If the number of different edges in a graph is in the total number of vertices v Within a small constant multiple of , So we think the picture is sparse , Otherwise it's dense .
Bipartite graph is a graph that can divide all nodes into two parts , The two vertices connected by each edge of a graph belong to different sets .
2. Data structure of undirected graph

Several representations of graphs
The next problem of graph processing is what kind of data structure is used to represent the graph and realize this API, Contains the following two requirements :
1. There must be enough space for the various types of diagrams that may be encountered in the application ;
2.Graph The implementation of instance method must be fast .
There are three options :
1. Adjacency matrix : We can use a V ride V Boolean matrix of . When the apex v and w When there is a connecting edge between , Definition v That's ok w The element value of the column is true, Otherwise false. This representation does not meet the first condition -- The space required for a graph with millions of vertices cannot be satisfied .
2. Array of edges : We can use a Edge class , It contains two int Instance variables . This representation is simple but does not satisfy the second condition -- To achieve Adj You need to check all the edges in the graph .
3. Adjacency table array : Use an array of lists indexed by vertices , Each of these elements is a list of vertices connected to that vertex .

The standard representation of non dense graphs becomes the data structure of adjacency table , It saves all the adjacent vertices of each vertex in a linked list pointed to by the corresponding element of the vertex . We use this array to quickly access the list of adjacent vertices for a given vertex . Use here Bag To implement the linked list , In this way, we can add new edges or traverse all adjacent vertices of any vertex in constant time .
To add a connection v And w The edge of , We will w Add to v In the adjacency list of and put v Add to w In the adjacency table of . So in this data structure, each edge appears twice . such Graph Performance characteristics of the implementation of :
1. Space used and V+E In direct proportion to ;
2. The time required to add an edge is constant ;
3. Traversal vertex v The time required for all adjacent vertices of the and v Is proportional to the degree of .
For these operations , This feature is already optimal , It also supports parallel edges and self rings . Be careful , The order in which the edges are inserted determines Graph The order in which vertices appear in the adjacency list of . Multiple different adjacency lists may represent the same picture . Because the algorithm is using Adj() All adjacent vertices are processed without considering the order in which they appear in the adjacency table , This difference will not affect the correctness of the algorithm , But you need to pay attention to this when debugging or tracking the path of the adjacency list .
public class Graph { private int v; private int e; private List<int>[] adj; // Adjacency list ( use List Instead of bag) /// <summary> /// Create a containing V A graph with vertices but no edges /// </summary> /// <param name="V"></param> public Graph(int V) { v = V; e = 0; adj = new List<int>[V]; for (var i = 0; i < V; i++) adj[i] = new List<int>(); } public Graph(string[] strs) { foreach (var str in strs) { var data = str.Split(' '); int v = Convert.ToInt32(data[0]); int w = Convert.ToInt32(data[1]); AddEdge(v,w); } } /// <summary> /// Number of vertices /// </summary> /// <returns></returns> public int V() { return v; } /// <summary> /// Number of edges /// </summary> /// <returns></returns> public int E() { return e; } /// <summary> /// Add an edge to the graph v-w /// </summary> /// <param name="v"></param> /// <param name="w"></param> public void AddEdge(int v, int w) { adj[v].Add(w); adj[w].Add(v); e++; } /// <summary> /// and v All the adjacent vertices /// </summary> /// <param name="v"></param> /// <returns></returns> public IEnumerable<int> Adj(int v) { return adj[v]; } /// <summary> /// Calculation V Degrees /// </summary> /// <param name="G"></param> /// <param name="V"></param> /// <returns></returns> public static int Degree(Graph G, int V) { int degree = 0; foreach (int w in G.Adj(V)) degree++; return degree; } /// <summary> /// Calculate the maximum degree of all vertices /// </summary> /// <param name="G"></param> /// <returns></returns> public static int MaxDegree(Graph G) { int max = 0; for (int v = 0; v < G.V(); v++) { var d = Degree(G, v); if (d > max) max = d; } return max; } /// <summary> /// Calculate the average degree of all vertices /// </summary> /// <param name="G"></param> /// <returns></returns> public static double AvgDegree(Graph G) { return 2.0 * G.E() / G.V(); } /// <summary> /// Calculate the number of self rings /// </summary> /// <param name="G"></param> /// <returns></returns> public static int NumberOfSelfLoops(Graph G) { int count = 0; for (int v = 0; v < G.V(); v++) { foreach (int w in G.Adj(v)) { if (v == w) count++; } } return count / 2; // Each edge is calculated twice } public override string ToString() { string s = V() + " vertices, " + E() + " edges\n"; for (int v = 0; v < V(); v++) { s += v + ":"; foreach (int w in Adj(v)) { s += w + " "; } s += "\n"; } return s; } }
There are also some operations that may be useful in practical applications , for example :
Add a vertex ;
Delete a vertex .
One way to do this is , Use the symbol table ST Instead of an array of vertex indexes , In this way, there is no need to specify that the vertex name must be an integer after modification . Maybe we need more :
Delete an edge ;
Check if the diagram contains v-w.
To implement these methods , May need to use SET Instead of Bag To implement adjacency list . We call this method adjacency set . There's no need to , because :
No need to add , Delete vertices and edges or check if an edge exists ;
The above operation frequency is very low or the related list is very short , You can use exhaustive traversal directly ;
In some cases, performance is lost logV.
3. Graph processing algorithm design pattern
Because we're going to talk a lot about graph processing algorithms , So the primary goal of the design is to separate the representation from the implementation of the graph . So , We will create a corresponding class for each task , Use cases can create corresponding objects to accomplish tasks . Class constructors generally construct various data structures in preprocessing , To effectively respond to the request of the application instance . A typical use case program constructs a diagram , Pass the graph as an argument to the constructor of an algorithm class , Then various methods are used to get the various properties of the graph .

We use the starting point s Distinguish the vertex passed to the constructor as an argument from other vertices in the graph . In this API in , The task of the constructor is to find other vertices in the graph connected with the starting point . Use cases can call marked Methods and count Methods to understand the properties of graphs . Method name marked It refers to an implementation of this basic method : In the graph, start from the starting point along the path to other vertices and mark each passing vertex .
stay union-find Algorithm I have seen Search API The implementation of the , Its constructor creates a UF object , Once for each edge in the graph union Operate and call connected(s,v) To achieve marked Method . Realization count Method needs a weighted UF Implement and extend it API, For use count Method returns sz[find(v)].
One of the following search algorithms is based on depth first search (DFS) Of , It looks for all the vertices connected to the starting point along the edge of the graph .
4. Depth-first search
To search for a picture , Only one recursive method is needed to traverse all vertices . When you visit one of the vertices :
1. Mark it as visited ;
2. Recursively accesses all its unlabeled neighbor vertices .
This method is called depth first search (DFS).
namespace Graphs { /// <summary> /// Use one bool Array to record all vertices connected to the starting point . The recursive method marks a given vertex and calls itself to access the list of adjacent vertices of that vertex /// All unlabeled vertices . If the graph is connected , The elements in each contiguous list are marked . /// </summary> public class DepthFirstSearch { private bool[] marked; private int count; public DepthFirstSearch(Graph G,int s) { marked = new bool[G.V()]; Dfs(G,s); } private void Dfs(Graph g, int V) { marked[V] = true; count++; foreach (var w in g.Adj(V)) { if (!marked[w]) Dfs(g,w); } } public bool Marked(int w) { return marked[w]; } } }
The depth first search marker is proportional to the sum of the time and the degree of all vertices connected from the starting point .
This simple recursive pattern is just the beginning -- Depth first search can effectively handle many graph related tasks .
1. Connectivity . Given a picture , Whether two given vertices are connected ?( Is there a path between two given vertices ? Path detection ) How many connected subgraphs are there in a graph ?
2. Single point path . Given a picture and a starting point s , from s To a given destination vertex v Is there a path ? If there is , Find this path .
5. Find the way
Single point path API:

The constructor takes a starting point s As a parameter , Calculation s To and s The path between each connected vertex . Starting from s establish Paths After object , Use cases can call PathTo Method to traverse from s To arbitrary and s All vertices on the path of connected vertices .
Realization
The following algorithm is based on depth first search , It adds a edgeTo[ ] integer array , This array can be found from each and s Connected vertices go back to s The path of . It remembers the path from each vertex to the starting point , Instead of recording the path from the current vertex to the starting point . To do this , By the side v-w The first random visit w when , take edgeTo[w] = v To remember this path . let me put it another way , v-w It's from s To w The last known edge on the path of . such , The result of the search is a tree with the starting point as the root node ,edgeTo[ ] It's a tree represented by a parent link . PathTo Methods use variables x Traverse the whole tree , Push all vertices encountered onto the stack .
public class DepthFirstPaths { private bool[] marked; private int[] edgeTo; // The last vertex on a known path from the starting point to a vertex private int s;// The starting point public DepthFirstPaths(Graph G, int s) { marked = new bool[G.V()]; edgeTo = new int[G.V()]; this.s = s; Dfs(G,s); } private void Dfs(Graph G, int v) { marked[v] = true; foreach (int w in G.Adj(v)) { if (!marked[w]) { edgeTo[w] = v; Dfs(G,w); } } } public bool HasPathTo(int v) { return marked[v]; } public IEnumerable<int> PathTo(int v) { if (!HasPathTo(v)) return null; Stack<int> path = new Stack<int>(); for (int x = v; x != s; x = edgeTo[x]) path.Push(x); path.Push(s); return path; } }
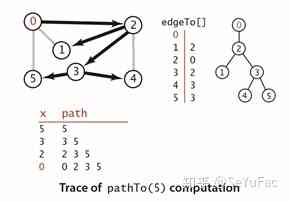
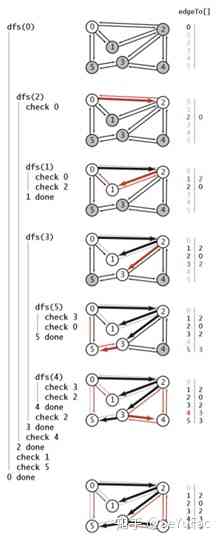
Using depth first search to get the path from a given starting point to any marked vertex, the time required is proportional to the length of the path .
6. Breadth first search
The path obtained by depth first search depends not only on the structure of the graph , It also depends on the representation of the graph and the nature of recursive calls .
Single point shortest path : Given a picture and a starting point s , from s To a given destination vertex v Is there a path ? If there is , Find the shortest one ( It contains the least edges ).
The classic way to solve this problem is called Breadth first search (BFS). Depth first search doesn't work on this problem , Because the sequence of traversing the whole graph has nothing to do with the goal of finding the shortest path . by comparison , Breadth appears again, search appears formally for this goal just appear .
To find out from s To v Shortest path , from s Start , Look for... In all the vertices that can be reached by one edge v , If you can't find it, keep working with s Find all vertices from two edges v , This has been going on .

In the program , When searching a graph, there are many edges to traverse , We will select one of them and leave the other edges for later search . In depth first search , We used a stack that can be pushed down . Use LIFO ( Last in, first out ) To describe the rule of pushing down the stack and walking the maze, first explore the adjacent
Channels are similar to . Choose the last channel you have encountered from the channel to be searched . In breadth first search , We want to traverse all vertices in the order of distance from the starting point , Use (FIFO, fifo ) Queue instead of stack . We're going to pick the first channel we're going to find .
Realization
The following algorithm uses a queue to hold all vertices that have been marked but whose adjacency list has not been checked . First add the vertex to the queue , Then repeat the following steps until the queue is empty :
1. Takes the next vertex of the queue v And mark it ;
2. Will work with v All the adjacent unmarked vertices join the queue .
Below Bfs Methods are not recursive . It explicitly uses a queue . Same as depth first search , The result is also an array edgeTo[ ] , It is also a root node represented by a parent link s The tree of . It means that s To each with s The shortest path of connected vertices .
namespace Graphs { /// <summary> /// Breadth first search /// </summary> public class BreadthFirstPaths { private bool[] marked;// Is the shortest path to the vertex known ? private int[] edgeTo;// The last vertex on a known path to that vertex private int s;// The starting point public BreadthFirstPaths(Graph G,int s) { marked = new bool[G.V()]; edgeTo = new int[G.V()]; this.s = s; Bfs(G,s); } private void Bfs(Graph G, int s) { Queue<int> queue = new Queue<int>(); marked[s] = true;// Mark the starting point queue.Enqueue(s);// Put it in the queue while (queue.Count > 0) { int v = queue.Dequeue();// Delete the next vertex from the queue foreach (var w in G.Adj(v)) { if (!marked[w])// For each unlabeled adjacent vertex { edgeTo[w] = v;// Save the last edge of the shortest path marked[w] = true;// Mark it , Because the shortest path is known queue.Enqueue(w);// And add it to the queue } } } } public bool HasPathTo(int v) { return marked[v]; } } }
The trajectory :
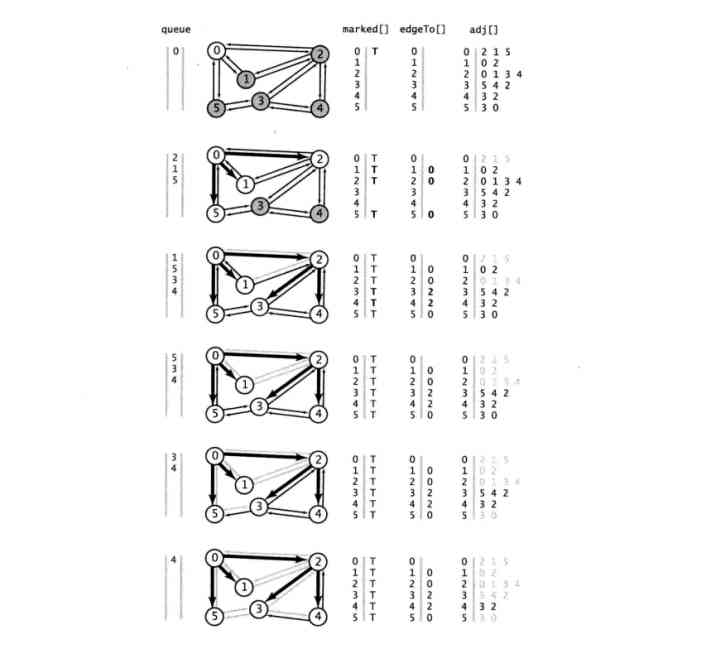
From s Any vertex reachable v , Breadth first search can find one from s To v Shortest path , Nothing else from s To v The path of has fewer edges than this path .
Breadth first search takes time in the worst case and V+E In direct proportion to .
We can also use breadth first search to implement what has been done with depth first search Search API, Because the way it checks all vertices and edges connected to the starting point only depends on the search ability .
Both breadth first search and depth first search will store the starting point in the data structure , Then repeat the following steps until the data structure is empty :
1. Take the next vertex and mark it ;
2. take v All adjacent and unlabeled vertices of are added to the data structure .
The difference between the two algorithms is that the rules of the next vertex are obtained from the data structure ( For breadth first search, it's the first vertex to be added , For depth first search, it is the latest vertex to be added ). This difference leads to two completely different perspectives on Processing Graphs , No matter what rules are used , All vertices and edges connected to the starting point are checked .
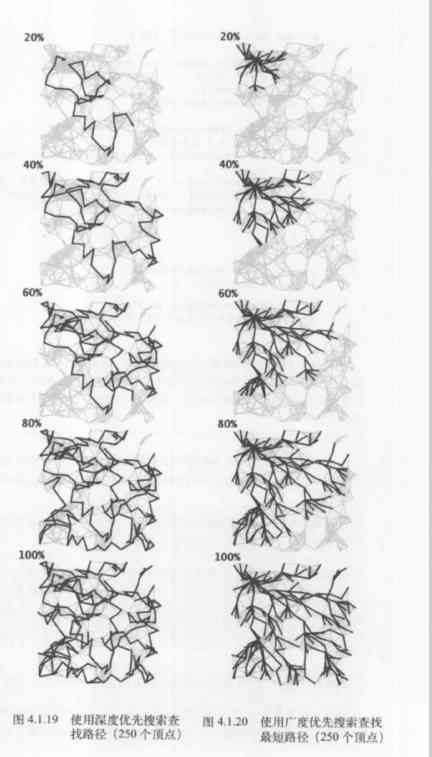
Depth first search goes deep into the graph and saves all the forked vertices in the stack ; Breadth first search is like a fan scan , Use a queue to hold the top most visited vertices . Depth first search the way to explore a graph is to find vertices farther away from the starting point , Only visit the top of the in and out only at the same time as you encounter a dead beard ; Breadth first search first covers the vertices near the starting point , It's only after all the neighboring vertices have been visited that we move forward . Depending on the application , The nature required is also different .
7. Connected component
The next direct application of depth first search is to find all the connected components of a graph . stay union-find in “ And ...... connected ” It's an equivalent relationship , It can cut all vertices into equivalent classes ( Connected component ).

Realization
CC The implementation uses marked Array to find a vertex as the starting point of depth first search in each connected component . Recursive depth first search. The first parameter called is vertex 0 -- It will mark all and 0 Connected vertices . And then... In the constructor for The loop looks for each unlabeled vertex and recursively calls Dfs To mark all vertices adjacent to it . in addition , It also uses an array of vertices as an index id[ ] , The value is the identifier of the connected component , Associate the vertices in the same connected component with the identifier of the connected component . This array makes Connected The implementation of the method becomes very simple .
namespace Graphs { public class CC { private bool[] marked; private int[] id; private int count; public CC(Graph G) { marked = new bool[G.V()]; id = new int[G.V()]; for (var s = 0; s < G.V(); s++) { if (!marked[s]) { Dfs(G,s); count++; } } } private void Dfs(Graph G, int v) { marked[v] = true; id[v] = count; foreach (var w in G.Adj(v)) { if (!marked[w]) Dfs(G,w); } } public bool Connected(int v, int w) { return id[v] == id[w]; } public int Id(int v) { return id[v]; } public int Count() { return count; } } }
Depth first search preprocessing uses time and space with V + E It is proportional and can process connectivity queries about graphs in constant time . From the code, each element of the adjacency list is checked only once , share 2E Elements ( Two on each side ).
union-find Algorithm
CC In this paper, we present a method based on depth first search to solve the problem of graph connectivity union-find Algorithm Compared with the algorithm in , Theoretically , Depth first search is faster , Because it guarantees that the time required is constant and union-find The algorithm doesn't work ; But in practice , This difference is negligible .union-find The algorithm is actually faster , Because it doesn't need to be fully constructed to represent a picture . what's more ,union-find Algorithm is a dynamic algorithm ( We can check whether two vertices are connected at any time with time close to a constant , Even when you add an edge ), But depth first search must preprocess the graph .
therefore , When we only need to judge connectivity, or when we need to complete a large number of connectivity query and insert operation mixing and other similar tasks , More inclined to use union-find Algorithm , Depth first search is suitable for implementing abstract data types of graphs , Because it can make better use of existing data structures .
Using depth first search can also solve Detection ring and Two color problem :
Detection ring , Is a given graph acyclic ?
namespace Graphs { public class Cycle { private bool[] marked; private bool hasCycle; public Cycle(Graph G) { marked = new bool[G.V()]; for (var s = 0; s < G.V(); s++) { if (!marked[s]) Dfs(G,s,s); } } private void Dfs(Graph g, int v, int u) { marked[v] = true; foreach (var w in g.Adj(v)) { if (!marked[w]) Dfs(g, w, v); else if (w != u) hasCycle = true; } } public bool HasCycle() { return hasCycle; } } }
Is it a bipartite picture ?( Two color problem )
namespace Graphs { public class TwoColor { private bool[] marked; private bool[] color; private bool isTwoColorable = true; public TwoColor(Graph G) { marked = new bool[G.V()]; color = new bool[G.V()]; for(var s = 0;s<G.V();s++) { if (!marked[s]) Dfs(G,s); } } private void Dfs(Graph g, int v) { marked[v] = true; foreach (var w in g.Adj(v)) { if (!marked[w]) { color[w] = !color[v]; Dfs(g, w); } else if (color[w] == color[v]) isTwoColorable = false; } } public bool IsBipartite() { return isTwoColorable; } } }
8. Symbol diagram
In typical applications , Graphs are defined by files or web pages , Use strings instead of integers to represent and refer to vertices . In order to adapt to such an application , We use symbolic graphs . Symbol diagram API:

This API Define a constructor to read and construct the graph , use name() and index() Method corresponds the vertex name in the input stream to the vertex index used by the graph algorithm .
Realization
Need to use 3 Data structures :
1. A list of symbols st , The type of bond is string( Vertex name ), The type of value int ( Indexes );
2. An array keys[ ], Used as a reverse index , Save the vertex name for each vertex index ;
3. One Graph object G, It uses an index to refer to vertices in a graph .
SymbolGraph Will traverse the data twice to construct the above data structure , This is mainly because of the structure Graph Object requires the total number of vertices V. In a typical practical application , Indicate in the document defining the diagram V and E It may be inconvenient , And with SymbolGraph, You don't have to worry about maintaining the total number of edges or vertices .
namespace Graphs { public class SymbolGraph { private Dictionary<string, int> st;// Symbol name -> Indexes private string[] keys;// Indexes -> Symbol name private Graph G; public SymbolGraph(string fileName, string sp) { var strs = File.ReadAllLines(fileName); st = new Dictionary<string, int>(); // First pass foreach (var str in strs) { var _strs = str.Split(sp); foreach (var _str in _strs) { st.Add(_str,st.Count); } } keys = new string[st.Count]; foreach (var name in st.Keys) { keys[st[name]] = name; } // Second times Connect the first vertex of each row to the other vertices of the row foreach (var str in strs) { var _strs = str.Split(sp); int v = st[_strs[0]]; for (var i = 1; i < _strs.Length; i++) { G.AddEdge(v,st[_strs[i]]); } } } public bool Contains(string s) { return st.ContainsKey(s); } public int Index(string s) { return st[s]; } public string Name(int v) { return keys[v]; } public Graph Gra() { return G; } } }
The degree of the interval
have access to SymbolGraph and BreadthFirstPaths To find the shortest path in the graph :

summary