当前位置:网站首页>Machine learning notes - building a recommendation system (6) six automatic encoders for collaborative filtering
Machine learning notes - building a recommendation system (6) six automatic encoders for collaborative filtering
2022-07-26 19:21:00 【Sit and watch the clouds rise】
One 、 Overview of automatic encoder
Automatic encoder is a kind of neural network suitable for unsupervised learning task , Including generation modeling 、 Dimensionality reduction and efficient coding . It is learning computer vision 、 Many fields such as speech recognition and language modeling have shown their advantages in the low-level feature representation . About more detailed automatic encoder and related classification , Please refer to the following link .
Two 、 Automatic encoder is used for collaborative filtering
1、AutoRec
One of the earliest models to consider collaborative filtering from the perspective of automatic encoder is from Suvash Sedhain、Aditya Krishna Menon、Scott Sanner and Lexing Xie Of “Autoencoders Meet Collaborative Filtering ” Of AutoRec.
In the paper , Yes m Users ,n A project , And a partially populated user - Project interaction / Scoring matrix R, Dimension for mx n. Each user u You can use a partially filled vector rᵤ Express , Each project i You can use a partially filled vector rᵢ Express .AutoRec Direct the user rating vector rᵤ Or project rating rᵢ As input data , And get the reconstruction score at the output layer . According to two types of input ,AutoRec There are two variants : Project based AutoRec ( I-AutoRec ) And user based AutoRec ( U-AutoRec ). They all have the same structure .
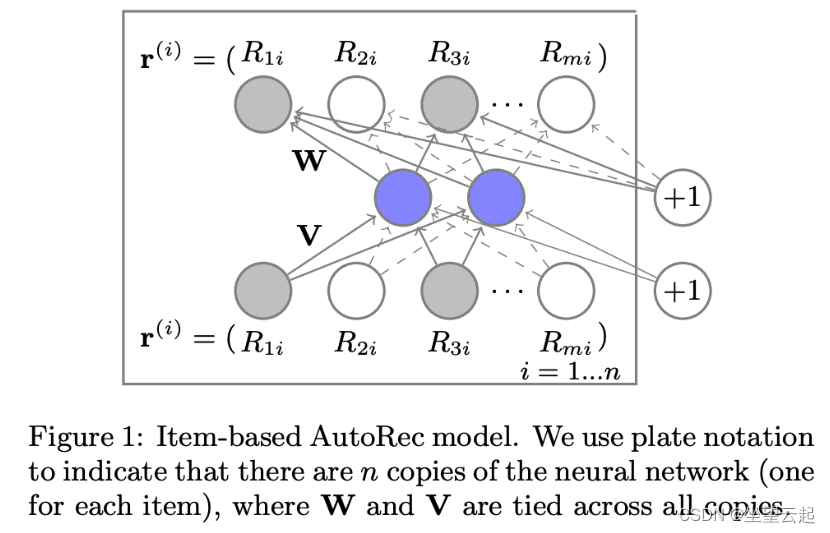
The picture above depicts I-AutoRec Structure . Grey nodes correspond to observed ratings , Solid line connection corresponds to input rᵢ Updated weights .
class AutoRec:
def prepare_model(self):
"""
Function to build AutoRec
"""
self.input_R = tf.compat.v1.placeholder(dtype=tf.float32,
shape=[None, self.num_items],
name="input_R")
self.input_mask_R = tf.compat.v1.placeholder(dtype=tf.float32,
shape=[None, self.num_items],
name="input_mask_R")
V = tf.compat.v1.get_variable(name="V", initializer=tf.compat.v1.truncated_normal(
shape=[self.num_items, self.hidden_neuron],
mean=0, stddev=0.03), dtype=tf.float32)
W = tf.compat.v1.get_variable(name="W", initializer=tf.compat.v1.truncated_normal(
shape=[self.hidden_neuron, self.num_items],
mean=0, stddev=0.03), dtype=tf.float32)
mu = tf.compat.v1.get_variable(name="mu", initializer=tf.zeros(shape=self.hidden_neuron), dtype=tf.float32)
b = tf.compat.v1.get_variable(name="b", initializer=tf.zeros(shape=self.num_items), dtype=tf.float32)
pre_Encoder = tf.matmul(self.input_R, V) + mu
self.Encoder = tf.nn.sigmoid(pre_Encoder)
pre_Decoder = tf.matmul(self.Encoder, W) + b
self.Decoder = tf.identity(pre_Decoder)
pre_rec_cost = tf.multiply((self.input_R - self.Decoder), self.input_mask_R)
rec_cost = tf.square(self.l2_norm(pre_rec_cost))
pre_reg_cost = tf.square(self.l2_norm(W)) + tf.square(self.l2_norm(V))
reg_cost = self.lambda_value * 0.5 * pre_reg_cost
self.cost = rec_cost + reg_cost
if self.optimizer_method == "Adam":
optimizer = tf.compat.v1.train.AdamOptimizer(self.lr)
elif self.optimizer_method == "RMSProp":
optimizer = tf.compat.v1.train.RMSPropOptimizer(self.lr)
else:
raise ValueError("Optimizer Key ERROR")
if self.grad_clip:
gvs = optimizer.compute_gradients(self.cost)
capped_gvs = [(tf.clip_by_value(grad, -5., 5.), var) for grad, var in gvs]
self.optimizer = optimizer.apply_gradients(capped_gvs, global_step=self.global_step)
else:
self.optimizer = optimizer.minimize(self.cost, global_step=self.global_step)2、Deep Autoencoders
DeepRec By NVIDIA Of Oleisii Kuchaiev and Boris Ginsburg Model created , Such as “ Training Deep Autoencoders for Collaborative Filtering ” As shown in . The model is affected by the above AutoRec The inspiration of the model , There are several important differences :
The network is much deeper .
The model uses “ Scale exponentially linear units ”(SELUs).
High dropout rate .
The author uses iterative output to re feed during training .
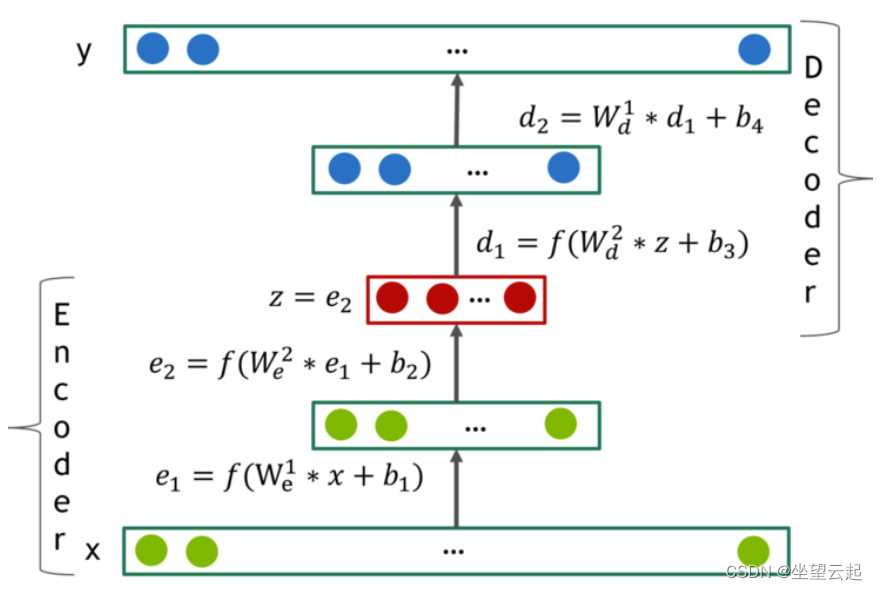
The figure above depicts a typical 4 Layer self encoder network . The encoder has 2 layer e_1 and e_2, The decoder has 2 layer d_1 and d_2. They mean z On the integration . These layers are represented by f(W * x + b), among f Are some nonlinear activation functions . If the range of the active function is smaller than the range of the data , The last layer of the decoder should remain linear . The author found the activation function in the hidden layer f It is very important to include non-zero negative parts , And in most of their experiments SELU unit .
The author optimized Masked Mean Squared Error Loss :

among  Is the actual score ,
Is the actual score , Is the reconstruction score ,
Is the reconstruction score , Is a mask function , If Not for 0, be
Is a mask function , If Not for 0, be  , otherwise
, otherwise  .
.
def Deep_AE_model(X, layers, activation, last_activation, dropout, regularizer_encode,
regularizer_decode, side_infor_size=0):
"""
Function to build the deep autoencoders for collaborative filtering
:param X: the given user-item interaction matrix
:param layers: list of layers (each element is the number of neurons per layer)
:param activation: choice of activation function for all dense layer except the last
:param last_activation: choice of activation function for the last dense layer
:param dropout: dropout rate
:param regularizer_encode: regularizer for the encoder
:param regularizer_decode: regularizer for the decoder
:param side_infor_size: size of the one-hot encoding vector for side information
:return: Keras model
"""
# Input
input_layer = x = Input(shape=(X.shape[1],), name='UserRating')
# Encoder Phase
k = int(len(layers) / 2)
i = 0
for l in layers[:k]:
x = Dense(l, activation=activation,
name='EncLayer{}'.format(i),
kernel_regularizer=regularizers.l2(regularizer_encode))(x)
i = i + 1
# Latent Space
x = Dense(layers[k], activation=activation,
name='LatentSpace',
kernel_regularizer=regularizers.l2(regularizer_encode))(x)
# Dropout
x = Dropout(rate=dropout)(x)
# Decoder Phase
for l in layers[k + 1:]:
i = i - 1
x = Dense(l, activation=activation,
name='DecLayer{}'.format(i),
kernel_regularizer=regularizers.l2(regularizer_decode))(x)
# Output
output_layer = Dense(X.shape[1] - side_infor_size, activation=last_activation, name='UserScorePred',
kernel_regularizer=regularizers.l2(regularizer_decode))(x)
# This model maps an input to its reconstruction
model = Model(input_layer, output_layer)
return model3、 Cooperative denoising automatic encoder
Yao Wu、Christopher DuBois、Alice Zheng and Martin Ester Of “ be used for Top-N Recommend the cooperative denoising automatic encoder of the system ” It is a neural network with a hidden layer . And AutoRec and DeepRec comparison ,CDAE There are the following differences :
CDAE The input of is not user item rating , It's part of the observed implicit feedback r( User's project preferences ). If users like a movie , Then the corresponding entry value is 1, Otherwise 0.
Different from the previous two models used for scoring prediction ,CDAE Mainly used for ranking prediction ( Also known as Top-N Preference recommendation ).

class CDAE(BaseModel):
"""
Collaborative Denoising Autoencoder model class
"""
def __init__(self, model_conf, num_users, num_items, device):
"""
:param model_conf: model configuration
:param num_users: number of users
:param num_items: number of items
:param device: choice of device
"""
super(CDAE, self).__init__()
self.hidden_dim = model_conf.hidden_dim
self.act = model_conf.act
self.corruption_ratio = model_conf.corruption_ratio
self.num_users = num_users
self.num_items = num_items
self.device = device
self.user_embedding = nn.Embedding(self.num_users, self.hidden_dim)
self.encoder = nn.Linear(self.num_items, self.hidden_dim)
self.decoder = nn.Linear(self.hidden_dim, self.num_items)
self.to(self.device)
def forward(self, user_id, rating_matrix):
"""
Forward pass
:param rating_matrix: rating matrix
"""
# normalize the rating matrix
user_degree = torch.norm(rating_matrix, 2, 1).view(-1, 1) # user, 1
item_degree = torch.norm(rating_matrix, 2, 0).view(1, -1) # 1, item
normalize = torch.sqrt(user_degree @ item_degree)
zero_mask = normalize == 0
normalize = torch.masked_fill(normalize, zero_mask.bool(), 1e-10)
normalized_rating_matrix = rating_matrix / normalize
# corrupt the rating matrix
normalized_rating_matrix = F.dropout(normalized_rating_matrix, self.corruption_ratio, training=self.training)
# build the collaborative denoising autoencoder
enc = self.encoder(normalized_rating_matrix) + self.user_embedding(user_id)
enc = apply_activation(self.act, enc)
dec = self.decoder(enc)
return torch.sigmoid(dec)4、 Polynomial variational automatic encoder
One of the most influential papers is from Netflix Of Dawen Liang、Rahul Krishnan、Matthew Hoffman and Tony Jebara Of “ Variational Autoencoders for Collaborative Filtering ”. It proposes a VAE variant , Used for recommendation using implicit data . especially , The author introduces a principled Bayesian inference method to estimate model parameters , And it shows better results than the common likelihood function .
This article USES the U Index all users , Use I Index all items .user-by-item The interaction matrix is called X( Dimension for U x I). Lowercase xᵤ Is a word bag vector , It contains information from users u Number of clicks per item . For implicit feedback , This matrix is binarized into only 0 and 1.
class MultVAE(BaseModel):
"""
Variational Autoencoder with Multninomial Likelihood model class
"""
def __init__(self, model_conf, num_users, num_items, device):
"""
:param model_conf: model configuration
:param num_users: number of users
:param num_items: number of items
:param device: choice of device
"""
super(MultVAE, self).__init__()
self.num_users = num_users
self.num_items = num_items
self.enc_dims = [self.num_items] + model_conf.enc_dims
self.dec_dims = self.enc_dims[::-1]
self.dims = self.enc_dims + self.dec_dims[1:]
self.total_anneal_steps = model_conf.total_anneal_steps
self.anneal_cap = model_conf.anneal_cap
self.dropout = model_conf.dropout
self.eps = 1e-6
self.anneal = 0.
self.update_count = 0
self.device = device
self.encoder = nn.ModuleList()
for i, (d_in, d_out) in enumerate(zip(self.enc_dims[:-1], self.enc_dims[1:])):
if i == len(self.enc_dims[:-1]) - 1:
d_out *= 2
self.encoder.append(nn.Linear(d_in, d_out))
if i != len(self.enc_dims[:-1]) - 1:
self.encoder.append(nn.Tanh())
self.decoder = nn.ModuleList()
for i, (d_in, d_out) in enumerate(zip(self.dec_dims[:-1], self.dec_dims[1:])):
self.decoder.append(nn.Linear(d_in, d_out))
if i != len(self.dec_dims[:-1]) - 1:
self.decoder.append(nn.Tanh())
self.to(self.device)
def forward(self, rating_matrix):
"""
Forward pass
:param rating_matrix: rating matrix
"""
# encoder
h = F.dropout(F.normalize(rating_matrix), p=self.dropout, training=self.training)
for layer in self.encoder:
h = layer(h)
# sample
mu_q = h[:, :self.enc_dims[-1]]
logvar_q = h[:, self.enc_dims[-1]:] # log sigmod^2 batch x 200
std_q = torch.exp(0.5 * logvar_q) # sigmod batch x 200
# reparametrization trick
epsilon = torch.zeros_like(std_q).normal_(mean=0, std=0.01)
sampled_z = mu_q + self.training * epsilon * std_q
# decoder
output = sampled_z
for layer in self.decoder:
output = layer(output)
if self.training:
kl_loss = ((0.5 * (-logvar_q + torch.exp(logvar_q) + torch.pow(mu_q, 2) - 1)).sum(1)).mean()
return output, kl_loss
else:
return output5、 Sequence variational automatic encoder
stay “ Automatic encoder of sequence variation for collaborative filtering ” in ,Noveen Sachdeva、Giuseppe Manco、Ettore Ritacco and Vikram Pudi By exploring the rich information that exists in the history of past preferences , Put forward the right MultVAE An extension of . They introduced a circular version MultVAE, Instead of passing a subset of the whole history without considering time dependence , Instead, a subset of the consumption sequence is transmitted through a cyclic neural network . They show that , Processing time information is important for improving VAE Accuracy is crucial .
class SVAE(nn.Module):
"""
Function to build the SVAE model
"""
def __init__(self, hyper_params):
super(Model, self).__init__()
self.hyper_params = hyper_params
self.encoder = Encoder(hyper_params)
self.decoder = Decoder(hyper_params)
self.item_embed = nn.Embedding(hyper_params['total_items'], hyper_params['item_embed_size'])
self.gru = nn.GRU(
hyper_params['item_embed_size'], hyper_params['rnn_size'],
batch_first=True, num_layers=1
)
self.linear1 = nn.Linear(hyper_params['hidden_size'], 2 * hyper_params['latent_size'])
nn.init.xavier_normal(self.linear1.weight)
self.tanh = nn.Tanh()
def sample_latent(self, h_enc):
"""
Return the latent normal sample z ~ N(mu, sigma^2)
"""
temp_out = self.linear1(h_enc)
mu = temp_out[:, :self.hyper_params['latent_size']]
log_sigma = temp_out[:, self.hyper_params['latent_size']:]
sigma = torch.exp(log_sigma)
std_z = torch.from_numpy(np.random.normal(0, 1, size=sigma.size())).float()
self.z_mean = mu
self.z_log_sigma = log_sigma
return mu + sigma * Variable(std_z, requires_grad=False) # Reparameterization trick
def forward(self, x):
"""
Function to do a forward pass
:param x: the input
"""
in_shape = x.shape # [bsz x seq_len] = [1 x seq_len]
x = x.view(-1) # [seq_len]
x = self.item_embed(x) # [seq_len x embed_size]
x = x.view(in_shape[0], in_shape[1], -1) # [1 x seq_len x embed_size]
rnn_out, _ = self.gru(x) # [1 x seq_len x rnn_size]
rnn_out = rnn_out.view(in_shape[0] * in_shape[1], -1) # [seq_len x rnn_size]
enc_out = self.encoder(rnn_out) # [seq_len x hidden_size]
sampled_z = self.sample_latent(enc_out) # [seq_len x latent_size]
dec_out = self.decoder(sampled_z) # [seq_len x total_items]
dec_out = dec_out.view(in_shape[0], in_shape[1], -1) # [1 x seq_len x total_items]
return dec_out, self.z_mean, self.z_log_sigma6、Shallow Autoencoders
Harald Steck Of “ Embarrassingly Shallow Autoencoders for Sparse Data ” It is a fascinating article , I want to introduce it into this discussion . The motivation here is , According to his literature review , And there's only one 、 Two or three hidden layers “ depth ” The model compares , The ranking accuracy of depth models with a large number of hidden layers in collaborative filtering is usually No, Significantly improve the layer . This is related to NLP Or other fields such as computer vision .

class ESAE(BaseModel):
"""
Embarrassingly Shallow Autoencoders model class
"""
def forward(self, rating_matrix):
"""
Forward pass
:param rating_matrix: rating matrix
"""
G = rating_matrix.transpose(0, 1) @ rating_matrix
diag = list(range(G.shape[0]))
G[diag, diag] += self.reg
P = G.inverse()
# B = P * (X^T * X − diagMat(γ))
self.enc_w = P / -torch.diag(P)
min_dim = min(*self.enc_w.shape)
self.enc_w[range(min_dim), range(min_dim)] = 0
# Calculate the output matrix for prediction
output = rating_matrix @ self.enc_w
return output3、 ... and 、 Model to evaluate
The dataset is MovieLens 1M, Similar to what I used before Matrix Factorization and Multilayer Perceptron Two experiments done . The goal is to predict users' ratings of movies , Score on 1 To 5 Between .
about AutoRec and DeepRec Model , The evaluation index is score prediction ( Return to ) Masking root mean square error in setting (RMSE).
about CDAE、MultVAE、SVAE and ESAE Model , The evaluation index is ranking prediction ( classification ) Set in the Precision、Recall and Normalized Discounted Cumulative Gain (NDCG). As mentioned in the previous section , These models use implicit feedback data , The rating is binarized into 0( Less than or equal to 3) and 1( Greater than 3).

边栏推荐
- Gongfu developer community is settled! On July 30!
- J3:Redis主从复制
- The first letter of leetcode simple question appears twice
- 机器学习笔记 - 构建推荐系统(6) 用于协同过滤的 6 种自动编码器
- 千万不要随便把 Request 传递到异步线程里面 , 有坑 你拿捏不住,得用 startAsync 方法才行
- LeetCode笔记:Weekly Contest 303
- Synchronized theory
- ZbxTable 2.0 重磅发布!6大主要优化功能!
- The difference between advanced anti DDoS server and advanced anti DDoS IP
- Introduce the difference between @getmapping and @postmapping in detail
猜你喜欢
MapReduce (II)

数据湖--概念、特征、架构与案例概述
Mathematical basis of deep learning

分布式事务-seata
MySQL日志介绍

Sentinel isolation and degradation

千万不要随便把 Request 传递到异步线程里面 , 有坑 你拿捏不住,得用 startAsync 方法才行

After the exam on June 25, see how the new exam outline reviews PMP

Microsoft silently donated $10000 to curl, which was not notified until half a year later

Complete MySQL database commands
随机推荐
【MySQL必知必会】 日志Log详解
Synchronized theory
Article 7:exited on desktop-dff5kik with error code -1073741511
模型定义#pytorch学习
MongoDB stats统计集合占用空间大小
(ICLR-2022)TADA!用于视频理解的时间自适应卷积
What do indicators and labels do
Racher deploys kubernetes cluster
Current occupation, write later
JS question brushing plan - array
节省50%成本 京东云发布新一代混合CDN产品
[swoole series 3.1] have you been asked about processes, threads, and collaborations during the interview?
Tensor RT's int8 quantization principle
Cannot find current proxy: Set ‘exposeProxy‘ property on Advised to ‘true‘ to make it available
JS使用readline来实现终端输入数据
深度学习的数学基础
MySQL学习笔记-2.如何提高sql语句的查询性能
[MySQL from introduction to proficiency] [advanced chapter] (VIII) clustered index & non clustered index & joint index
ReentrantLock学习之公平锁过程
Unity farm 2 - planting system