当前位置:网站首页>Tensor RT's int8 quantization principle
Tensor RT's int8 quantization principle
2022-07-26 18:56:00 【@BangBang】
Quantitative goals
- Neural network operation 32 Weight of floating-point representation , become 8 For the purpose of Int Integers , And hope there is no significant decrease in accuracy
Why use In8, Because it can bringHigherOfThroughput rate, alsolessOfMemory footprint- But there are also challenges ,
Int8YesLower accuracy, And there areSmaller dynamic range - How to ensure
Accuracy after quantificationWell ,Solution: Yes Int8 Quantized model weight and activation function , Minimize information loss . - Tensor RT The method adopted , No additional fine tuning Or retrain .
In8 Reasoning
Challenge
- INT8 be relative to FP32 It has low accuracy and dynamic range

- As can be seen from the table 32 Bit floating point ,16 Bit floating point ,INT8 The dynamic range of is very different , such as
16The locus is-65504 ~ +65504,32 The maximum dynamic range for floating point is-3.4 * 10^(38) ~3.4 x10^(38), andINT8The dynamic range of is much smaller-128 ~ 127 - So we
You cannot use simple type conversions , take 32 Bit floating point , Convert to 8 An integer , Otherwise, it will bring great performance loss.
Linear quantization (Linear quartization)
int8 The relationship with tensor is as follows Tensor Values =FP32 scale factor *int8 array +FP32 bias
among FP32 bias After research, it has little effect on performance , Can be removed
Symmetric linear quartization
Expressed as :Tensor Values =FP32 scale factor *int8 array
For all int 8array As long as a FP32 scale factor
Quantification method
There are two ways to quantify : Quantification of unsaturated 、 Saturated quantification
- Unsaturated quantification
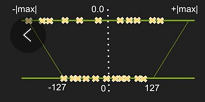
Put the operation range of floating-point numbers above , Mapping to-127 ~127, By mapping the negative maximum to-127, Positive maxima map to127. But this will lead to a significant decrease in accuracy . - Saturation quantification
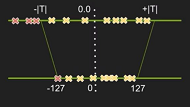
By setting athreshold T, take-TToTMapping in this range to-127~127, Less than-TMapping to-127, Greater thanTMapping to127. So this is the quantification of saturation
If we can be surethreshold TWords , It can improve the accuracy very well , The key point is how to select the appropriate threshold .
How to optimize threshold selection
Yes In8 The representation of requires a trade-off between dynamic range and accuracy 
The picture above shows different networks , The horizontal axis is activation value, The vertical axis is the number of times the normalized number appears , As can be seen from the first picture ,vgg19 conv3_4 Large activation values appear less often , The other two pictures are resnet152 Distribution of activation values , and googlenet:inception_3a Distribution of activation values .
We want to consider minimizing information loss , Think about 32 Bit floating-point number to 8 Bit integers just recode the information
Relative entropy
- What we want
Int8 modelAnd the originalFP32The information expressed by our model is the same , If it can't be done , We want to minimize the loss of information .
- What we want
- Loss of information through
KLDivergence is measured ,KL Divergence is a measure of the difference between two probability distributions , So as to measure the information loss caused by the new coding method .
Solution :Calibration
FP32 The model infers on the calibration data set , The calibration data set extracts some pictures from the training set .
For each layer :
- Collect the distribution of activation values (histograms)
- Using different
Saturation thresholdProduce different quantitative distributions (quantized distributions) - Select one of the thresholds , Make the corresponding quantization distribution and the distribution of activation value , It can be minimized KL The divergence .
K L _ d i v e r g e n c e ( r e f _ d i s t r , q u a n t _ d i s t r ) KL\_divergence(ref\_distr, quant\_distr) KL_divergence(ref_distr,quant_distr), Through iteration, we can get the most suitableSaturation threshold

Calibration algorithm
calibration: Iterative search threshold based on experiment
- Provide a sample data set ( Preferably a subset of the validation set ), be called “” Calibration data set “”, be called " Calibration data set ", Used for calibration
- Run on the calibration dataset FP32 Reasoning . Collect weights 、 Active histogram , And generate a set of 8 Bit notation , And choose to have the least KL The expression of divergence .
- KL Divergence uses the reference distribution (FP32 Distribution ) And quantitative distribution ( namely 8 Bit quantization activation ) Between
TRT Provides Int8EntropyCalibrator, The interface needs to be implemented by the regression end , To provide a set of calibration data and some sample codes for caching results .
How to use it KL Divergence choose the appropriate threshold
Nvidia The choice is KL-divergence, It's actually relative entropy . Relative entropy describes the difference between two distributions , Here is the difference between the two distributions before and after quantification . The smallest difference is the best , So the problem is to find the minimum value of relative entropy 
KL Divergence is to accurately measure the difference between the optimal and suboptimal .
FP32 Is the original optimal coding ,INT8 It's sub optimal coding , use KL Divergence to describe the difference between the two .
Tensor RT Quantitative process (workflow)
Premise
- FP32 Training for Model
- Calibration data set
TensorRT Work done
- use FP32 The model makes reasoning on the calibration data set
- Collect weights under different thresholds 、 Statistics of activation value ( Histogram )
- Execute the calibration algorithm to get the optimal Scale factors
- Then you can put FP32 The weight of is quantized to INT8
- Finally generate a
Calibration table( Calibration table ) and INT8 Executable reasoning engine
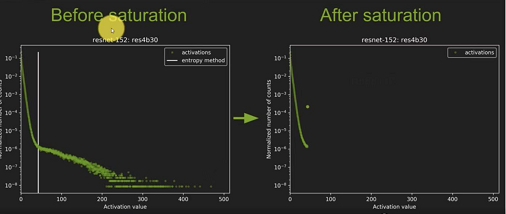
The left figure does not consider saturation , The picture on the right considers saturation , In the figure White line The position is the position of saturation threshold , The part below the threshold remains unchanged , Parts larger than the threshold will be quantified to a value .
边栏推荐
- The principle of database index, why use b+ tree, why not binary tree?
- Redis核心原理
- Development of NFT digital collection system: Shanxi first released digital collections of ancient buildings on "China Tourism Day"
- Linked list - the first common node of two linked lists
- 图解用户登录验证流程,写得太好了!
- 5 best overseas substitutes for WPS Office
- flex布局
- 2022 cloud store joint marketing development fund (MDF) Introduction
- Flask encapsulates seven cattle cloud
- 凝心聚力,心心向印!印度中资手机企业协会(CMA)正式运营!
猜你喜欢

Neural network learning (2) introduction 2

Linked list - merge two sorted lists
Database expansion can also be so smooth, MySQL 100 billion level data production environment expansion practice

MPLS experiment
mpc5744p的pit报错, RTOS无法启动, 时钟源问题

ALV screen input option learning
SSM整合-功能模块和接口测试

MySQL - 函数及约束命令

Still using xshell? Recommend this more modern terminal connection tool

模块八作业 - 消息数据 MySQL 表设计
随机推荐
测试组如何进行QA规范
MPLS实验
Linked list - merge two sorted lists
2022年云商店联合营销市场发展基金(MDF)介绍
VTK (the Visualization Toolkit) loads STL models
SSM integration - functional module and interface testing
Neural network learning (2) introduction 2
自动化测试工具-Playwright(快速上手)
模板进阶(跑路人笔记)
MySQL练习题初级45题(统一表)
JS刷题计划——链表
还在用Xshell?推荐这个更现代的终端连接工具
Microsoft silently donated $10000 to curl, which was not notified until half a year later
Utility website recommendations
Sudden! Arm stops cooperating with Huawei! How big is the impact on Huawei?
Test cases of common functions
PMP candidates must read, and the epidemic prevention requirements for the exam on July 30 are here
详细介绍@GetMapping和@PostMapping的区别
【在 Kotlin 中添加条件行为】
如何成为一名优秀的测试/开发程序员?专注谋定而后动......