当前位置:网站首页>string类的模拟实现
string类的模拟实现
2022-06-21 15:51:00 【华为云】
string类的模拟实现
string.h
#pragma oncenamespace bit{ public: typedef char* iterator; typedef const char* const_iterator; iterator begin() { return _str; } iterator end() { return _str + _size; } const_iterator begin() const { return _str; } const_iterator end() const { return _str + _size; } /*string() :_str(new char[1]) ,_size(0) ,_capacity(0) { *_str = '\0'; }*/ //string(char* str = "\0") string(char* str = "") :_size(strlen(str)) ,capacity(_size); { _str(new char[_capacity + 1]);//预留\0 strcpy(_str, str); } //s1.swap(s2) void swap(string& s) { //注意这里的swap不算重载,重载要求的是在同一作用域,就像string和vector里都有push_back,它们函数名、返回值、参数可能都是相同的,那它们俩能同时存在的原因就是它俩在不同的作用域 ::swap(_str, s._str); ::swap(_size, s._size); ::swap(_capacity, s._capacity); } //s2(s1) string(const string& s) :_str(nullptr); { string tmp(s._str); swap(tmp)//this->swap(tmp); } //s1=s3 string& operator=(string s) { swap(s);//this->swap(s); return *this; } ~string() { delete[] _str; _str = nullptr; } //读写 char& operator[](size_t pos) { assert(pos < _size); return _str[pos]; } //读 const char& operator[](size_t pos) const { assert(pos < _size); return _str[pos]; } //增容 void reserve(size_t n) { if(n > _capacity) { char* tmp = new char[n + 1]; strcpy(tmp, _str); delete[] _str; _str = tmp; _capacity = n; } } void resize(size_t n, char ch = '\0') { if(n <= _size) { _size = n; _str[_size] = '\0'; } else { if(n > _capacity)//一次性增容,避免频繁增容所带来的消耗 { reserve(n); } for(size_t i = _size; i < n; i++) { _str[i] = ch; } _size = n; _str[_size] = '\0'; } } void push_back(char ch) { /*if(_size >= _capacity)//扩容 { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } _str[_size] = ch; ++_size; _str[_size] = '\0';*/ //实现insert后直接复用 insert(_size, ch); } void append(const char* str) { /*size_t len = strlen(str); if(_size + len > _capacity)//扩容 { reserve(_size + len); } strcpy(_str + _size, str); _size += len;*/ //复用insert insert(_size, str); } string& operator+=(char ch) { push_back(ch);//this->push_back(ch); return *this; } string& operator+=(const char* str) { append(str); return *this; } string& operator+=(const string& s) { *this += s._str; return *this; } size_t size() const { return _size; } size_t capacity() const { return _capacity; } size_t find(char ch, size_t pos = 0) { for(size_t i = pos; i < _size; ++i) { if(_str[i] == ch) { return i; } } return npos; } size_t find(const char* sub, size_t pos = 0) { const char* p = strstr(_str + pos, sub); if(p == nullptr) { return npos; } else { return p - _str; } return npos; } string& insert(size_t pos, char ch) { assert(pos <= _size); if(_size == _capacity) { size_t newcapacity = _capacity == 0 ? 4 : _capacity * 2; reserve(newcapacity); } /*int end = _size; while(end >= (int)pos) { _str[end + 1] = _str[end]; --end; }*/ size_t end = _size + 1; while(end > pos) { _str[end] = _str[end - 1]; --end; } _str[pos] = ch; ++_size; return *this; } string& insert(size_t pos, const char* str) { assert(pos <= _size); size_t len = strlen(str); if(len == 0)//空串直接返回 { return *this; } if(len + _size > _capacity) { reserve(len + _size); } size_t end = _size + len; while(end >= pos + len) { _str[end] = str[end - len]; --end; } for(size_t i = 0; i < len; ++i) { _str[pos + i] = str[i]; } _size += len; return *this; } const char* c_str() { return _str; } string& erase(size_t pos, size_t len = npos) { assert(pos < _size); //1、pos后删完 //2、pos后删一部分 if(len == npos || pos + len >= _size) { _str[pos] = '\0'; _size = pos; } else { strcpy(_str + pos, _str + pos + len);//这里直接调用strcpy即可 _size -= len; } return *this; } void print(const string& s) { for(size_t i = 0; i < s.size(); ++i) { //s[i] = 'x'//err cout << s[i] << " "; } cout << endl; string::const_iterator it = s.begin(); while(it != s.end()) { cout << *it << " "; } cout << endl; } void clear() { _str[0] = '\0'; _size = 0; } private: char* _str; size_t _size; size_t _capacity;//不包含最后做标识的\0 static const size_t npos; }; static size_t string::npos = -1; string operator+(const string& s1, char ch) { string ret = s1; ret += ch; return ret; } string operator+(const string& s1, const char* str) { string ret = s1; ret += str; return ret; } ostream& operator<<(ostream& out, const string& s) { for(size_t i = 0; i < s.size(); ++i) { out << s[i]; } return out; } istream& operator>>(istream& in, string& s) { s.clear(); char ch; //in >> ch; ch = in.get(); while(ch != ' ' || ch != '\n') { s += ch; //in >> ch; ch = in.get(); } return in; } istream& getline>>(string& s) { s.clear(); char ch; ch = in.get(); while(ch != '\n') { s += ch; ch = in.get(); } return in; } bool operator>(const string& s1, const string& s2) { size_t i1 = 0, i2 = 0; //“abc" "aa" //"aa" "abc" while(i1 < s1.size() && i2 < s2.size()) { if(s1[i1] > s2[i2]) { return true; } else if(s1[i1] < s2[i2]) { return false; } else { ++i1; ++i2; } } //"abc" "abc" -> false //"abcd" "abc" -> true //"abc" "abcd" -> false if(i1 == s1.size()) { return false; } else { return true; } } bool operator==(const string& s1, const strint& s2) { size_t i1 = 0, i2 = 0; while(i1 < s1.size() && i2 < s2.size()) { if(s1[i1] != s2[i2]) { return false; } else { ++i1; ++i2; } } if(i1 == s1.size() && i2 == s2.size()) { return true; } else { return false; } } inline bool operator!=(const string& s1, const string& s2) { return !(s1 == s2); } inline bool operator>=(const string& s1, const string& s2) { return s1 > s2 || s1 == s2; } inline bool operator<(const string& s1, const string& s2) { return !(s1 >= s2) } inline bool operator<=(const string& s1, const string& s2) { return !(s1 > s2) } void test_string1() { string s1("hello"); s1.push_back(' '); s1.append("world"); s1 += ' '; s1 += "world"; string s2(s1); s2.resize(3); s2.resize(8, 'x'); s2.resize(20, 'x'); } void test_string2() { //遍历打印 //1、 string s1("hello world"); for(size_t i = 0; i < s1.size(); ++i) { s1[i] += 1;//普通迭代器可读写 cout << s1[i] << " "; } cout << endl; //2、 string::iterator it = s.begin(); while(if != s1.end()) { *it -= 1; cout << *it << endl; ++it; } cout << endl; //3、 for(auto e : s1) { cout << e << " "; } cout << endl; print(s1); } void test_string3() { string s1("hello world"): s1.insert(5, 'x'); cout << s1.c_str() << endl; string s2("helloworld"); s2.insert(5, "bit"); cout << s2.c_str() << endl; s2.insert(0, "hello"); cout << s2.c_str() << endl; string s3("helloworld"); s3.erase(5, 3); cout << s3.c_str() << endl; s3.erase(5); cout << s3.c_str() << endl; } void test_string4() { string s1("hello"); cin >> s1; cout << s1 << endl; cout << s1.c_str() << endl; //以上两种cout的差别点 string s2("hello"); s2.resize(20); s2[19] = 'x'; cout << s1 << endl; cout << s1.c_str() << endl; string s3; cin >> s3; cout << s3 << endl; } void test_string5() { //string s1; //cin >> s1; //cout << s1 << endl; getline(cin, s1); cout << s1 << endl; }}string.cpp
#include"string.h"int main(){ try { bit::test_string1(); bit::test_string2(); bit::test_string3(); bit::test_string4(); bit::test_string5(); } catch(exception& e) { cout << e.what() << endl; } return 0;}说明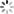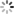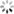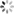
对于默认构造函数,我们之前说过写无参的不如写全缺省的,这里的缺省值可以给 “” 或 “\0”。_str 需要支持增删查改,所以得把原来的空间拷贝到新开的一块空间上进行操作,需要注意的是 _capacity 不包含 \0,也就是说 10 个字符需要有 11 个空间。
对于普通数组而言,越界读一般是检查不出来的,越界写是抽查,可能会检查出来,可能的意思是数组后面有一个标志位,如果修改了它就会报错,但不可能数组之后都是标志位,所以就可能就会出现往后越界一个位置会报错,往后越界二个位置不会报错的情况。这个在之前有说过,感兴趣的可以去测试下。 但是在 string 里无论是越界读还是越界写都会报错。
为什么到了 string,[ ] 就查的这么严 ???因为 [ ] 是一个函数调用,它对这里的参数进行了严格的检查。
当 _capacity 满了,push_back 直接扩二倍是可以的,但是 append 扩二倍不一定能满足,因为 append 尾插的是一个字符串。
对于 resize,string 里有两个版本,第一个版本如果没给值,它默认是用 \0 初始化,第二个版本是用指定字符初始化。其实第一个版本有点累赘了,这里我们直接把第二个版本的第二个参数设为缺省值为 \0 即可,其中我们在实现 resize 时又分为几种情况:
hello\0:_size = 5
- n <= _size:_size = 3
- n > _size && n < _capacity:_size = 8
- n > _capacity:_size = 15
对于第 3 种,我们也有很多种方法实现,比如去循环复用 +=,当 n 远大于当前空间时效率就很低,可能只需要一步到位的代码,却需要频繁增容,如果你不知道 string 的底层你根本不知道要这样写。这也就是我们为什么要去模拟实现 string 的原因。
对于第 2、3 种,我们的循环里的结束条件不能为 i <= n,因为这里要分情况,如果没传 ch,这里写 i <= n 是没问题的,但是如果传的是 x,就不行了,需要在循环后面补 \0,所以干脆 i < n,再在循环后被 \0。
可以看到迭代器的实现并不难,其实相比 string 和 vector 的迭代器,list 的迭代器就要复杂许多了。string::iterator 就是告诉编译器 iterator 去全局去找是找不到的,要到 string 这个域里去找,迭代器它是一个内嵌类型,所以说它要指定类域。注意这里是一个左闭右开的区间,它是一个普通迭代器,支持读写。
可以看到我们也没实现范围 for,为什么它依然可以完成呢,其实范围 for 的原理就是被替换成迭代器,范围 for 的语法是说取 s1 里的每个数据,赋值给 e,然后它会自动走,自动判断结束。所谓的这些自动其实没这么神奇,就像模板好像很牛逼,写一个 swap,其它地方都可以用,其实是把一些工作交给编译器去做了。这里也是一样,你可以认为这里的 e 是定义的一个变量,然后把 *it 赋值给 e,所以对 e 的改变不会影响 s1,需要加上引用才行。所以范围 for 的原理就是被替换成迭代器。
当然空口无凭,这里我们把 begin 改成了 Begin,报错了,以上就能说明范围 for 会被原模原样的替换成迭代器,但是迭代器得跟着规范去走,得用 begin。
print 就会用到 const 迭代器,对于 const 对象还要去实现一个 const 版本的 operator[],迭代器也要去实现 const 迭代器。注意对于普通对象和 const 对象,operator[] 和迭代器就必须实现两份,而像 size() 实现一份 const 版本就可以满足了。
注意这里实现的 insert 有问题,当 s1.insert(0, ‘x’) 时,当 end 减到 -1 时,本来应该结束了,但是它还会走,因为这里当无符号和有符号比较时,进行整型提升了,这里的 -1 会被提升为一个很大的正数。解决方法:
- 将参数的 size_t pos 改成 int pos,但不符合设计的意义
- 在 while 循环里比较时,将 pos 强转为 int
- 将 end 的值改成 _size + 1,具体见详细代码
这里就非常考验 C语言的基本功了,如果你不知道这个提升机制,甚至你在调试的时候都会怀疑是编译器的 bug。
对于erase 的实现,它的第二个参数我们给的是一个缺省值 npos,它是无符号的 -1。
一般我们重载流提取、流插入都是全局的。在实现日期类时,我们也写过,那里需要使用到友元,但是流提取和流插入必须是友元这句话是不对的,日期类里的友元,是要突破封装访问日期类的年月日,这里不一定要去访问。比如流插入的 operator[] 是公有的,流提取提供的 += 是公有的。
对于上面的 operator<<,我们发现它并不能提取我们输入的字符。其实这里的 in 是拿不到换行符或空格的,C语言中的 scanf 也是这样的,对于 C语言它可以使用 getchar 来解决,这里我们可以看到 C++ 中 cin 对象里也有类似的接口 get。
其次 operator>> 里还有个问题,当对 s1 字符串继续 cin >> s1 时,新输入的字符串会补在原字符串的后面,所以这里我们还要提供一个 clear 接口,在 operator>> 的第一行 clear。
以上两种 cout 有无区别 ???
一般情况下没有啥区别,但在某种场景下有区别,这种场景很不容易被发现。这里对 s2 resize 后,它会变成 hello\0\0\0\0…x,此时第一个 cout 会全部输出,因为它是按 _size 走的;第二个 cout 不会输出,因为它遇到 \0 就终止。所以大部分情况我们都用第一种 cout,因为它有保障。
这里我们输入 hello world,但只获取到了 hello,这个原因是 cin 是以空格或换行结束的,它认为 hello 和 world 是给两个对象的,所以这里就实现了 getline>>。注意这里的实现和 operator>> 是一样的,不同的地方是 getline 遇到换行才结束。
对于 operator> 写成成员或全局都可以,我们这里根据库里来实现写成全局。注意这里比较的是 ASCII 码。这里比较有如下情况:
- “abc” “aa”
- “aa” “abc”
- “abc” “abc”
- “abcd” “abc”
- “abc” “abcd"
当我们实现了 operator>、operator==,那么其它的就可以直接复用了,且实现为 inline,避免建立函数栈帧所带来的开销。
注意 operator+ 尽量少用,因为它内部需要两次深拷贝。
对于 find 我们这里只实现查找字符和查找字符串
补充
如下 s1 和 s2 对象的大小为什么是 28 字节
根据我们实现的 string 类,应该只有 12 字节,凭空多出的 16 字节是怎么来的 ?
这其实是 VS 下面的一个技术优化(也可以说是 PJ 版本自己考虑的),调试发现除了 size、capacity、指针,还多了很多东西。
也就是说你的字符个数小于 16,它不会去堆上开空间,而是存储在 _Buf 数组里;如果字符个数大于等于 16,它就会存储在 _str 指向的堆上。这种方式的好处就是对于小空间不用去系统去申请了,减少内存碎片。
Linux 下 s1 和 s2 的大小
扩展阅读
边栏推荐
- Web page automation practice "3. in elong, hotels are accurately matched according to city + date + keyword" part 2
- SQLSTATE[42000]: Syntax error or access violation: 1055 Expression #1 of SELECT list is not in GROUP
- Native JS routing, iframe framework
- Distributed monomer brought by microservice architecture
- 关于cookie和session的一些理解
- 单一职责原则(SRP)
- SQLSTATE[42000]: Syntax error or access violation: 1055 Expression #1 of SELECT list is not in GROUP
- Wireshark抓包分析SSL握手的过程
- 2022年Q1手机银行用户规模达6.5亿,加强ESG个人金融产品创新
- Research Report on the overall scale, major manufacturers, major regions, products and application segments of roots superchargers in the global market in 2022
猜你喜欢

使用APICloud实现文档下载和预览功能

CVPR2022|用魔法打败魔法,网易互娱AILab图像鉴伪新方法破解伪造人脸

2 万字 + 30 张图 | 细聊 MySQL undo log、redo log、binlog 有什么用?

Richardsutton: experience is the ultimate data of AI. The four stages lead to the development of real AI

WDS必知必会
![[pytorch basic tutorial 29] DIN model](/img/13/a180134e149c7ec08ff878f3e3514c.png)
[pytorch basic tutorial 29] DIN model
Cvpr2022 | defeat magic with magic, Netease Entertainment AILab new method for image forgery detection to crack forged faces
![[greedy] leetcode1005k times the maximum value of the array after negation](/img/9a/c4997d6ee3ec211ccc384fd5d13ff0.png)
[greedy] leetcode1005k times the maximum value of the array after negation

Daily appointment queue assistant | user manual

华为云发布桌面IDE-CodeArts
随机推荐
Score-Based Generative Modeling through Stochastic Differential Equations
NFT卡牌链游系统开发详情分析
What has paileyun done to embrace localization and promote industrial Internet?
20000 words + 30 pictures | what's the use of chatting about MySQL undo log, redo log and binlog?
Selection (036) - what is the output of the following code?
旭日图有效展示数据的层级和归属关系
The third child is here at last! General intelligent planning platform - APS module
Kubernetes deployment language
Comprehensive learning notes for intermediate network engineer in soft test (nearly 40000 words)
高级性能测试系列《3.性能指标、可靠性测试、容量测试、性能测试》
SQLSTATE[42000]: Syntax error or access violation: 1055 Expression #1 of SELECT list is not in GROUP
Baota, a well-known server operation and maintenance software manufacturer, joined dragon lizard community and completed compatibility and adaptation with Anolis OS
Distributed monomer brought by microservice architecture
依靠可信AI的鲁棒性有效识别深度伪造,帮助银行对抗身份欺诈
Single responsibility principle (SRP)
WDS must know and know
Blazor概述和路由
深入理解零拷贝技术
Score-Based Generative Modeling through Stochastic Differential Equations
高级性能测试系列《6.问题解答、应用的发展》