当前位置:网站首页>SegNet——论文笔记
SegNet——论文笔记
2022-08-04 05:34:00 【热血厨师长】
1、什么是语义分割(semantic segmentation)?
图像语义分割,简而言之就是对一张图片上的所有像素点进行分类,将所有属于同一类的物体标记为同一像素点。

SegNet基于FCN,修改VGG-16网络得到的语义分割网络。
2、SegNet(A Deep Convolutional Encoder-Decoder Architecture for Image Segmentation)
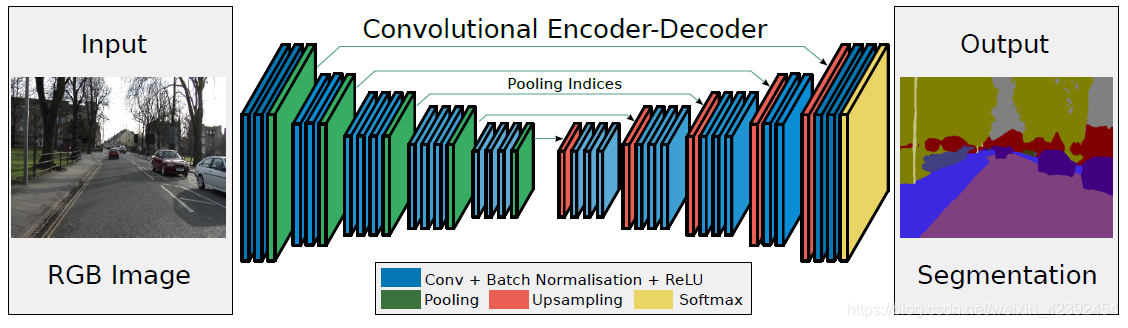
SegNet 有一个编码器网络和一个相应的解码器网络,然后是最终的逐像素分类层。
编码器
- 在编码器处,执行卷积和最大池化。
- VGG16 有 13 个卷积层,将原始的全连接层被替换成解码器。
- 在每个卷积层后添加Batch Normalization层。
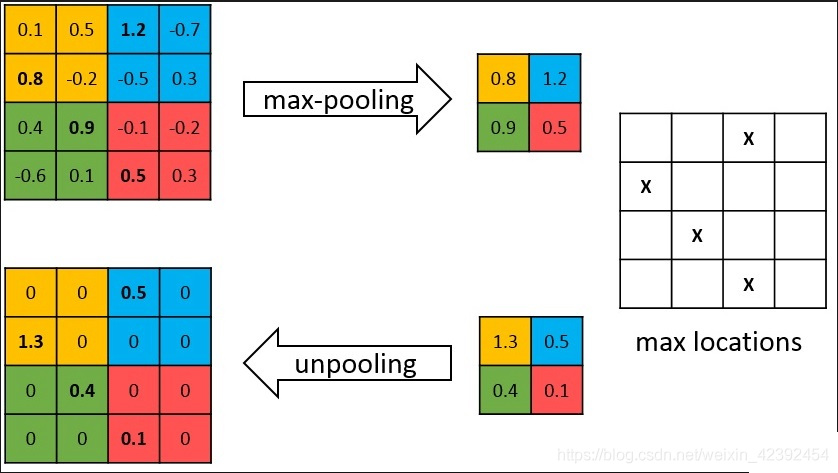
- 在进行 2×2 最大池化时,会存储相应的最大池化索引(位置),用于解码器的反池化操作。
解码器
- 在解码器处,执行上采样和卷积。最后,每个像素都有一个 Softmax 分类器。
- 在上采样期间,调用相应编码器层的最大池化索引以进行上采样,如上所示。
- 最后,使用 K (分类数量)类 Softmax 分类器来预测每个像素点所属的类别。
上采样的方式
目前上采样的方式有两种,一种是反卷积,另一种是双线性插值。但与其他分割网络不一样的是,SegNet采用了带索引的反池化操作,进一步提高的特征传递的准确性。
损失函数
SegNet是逐像素点预测的,因此对于每个像素点来说,Ground Truth不是0就是1,即使分割图像是单通道的(依据分类数给出索引),那也可以变成One-Hot的形式,例如VOC的label就是21通道的。
所以根据像素点的预测方式,使用交叉熵就可以了。当然,后人改进采用了dice loss、focal loss等,在这里就不展开论述了。
预测精度
作者的数据是基于道路场景分割的 CamVid 数据集所训练的结果,SegNet的预测精度如图所示:

内存和推理时间

- SegNet 比FCN和DeepLabv1慢,因为 SegNet 包含解码器架构,这一块主流的深度学习框架优化做的比较少,多数是以用户自己编写自定义层来实现。
- 并且 SegNet 在训练和测试期间都具有较低的内存需求。并且模型尺寸比FCN和DeconvNet 小得多。
3、总结
SegNet原理非常简单,特点就是采用了带索引的池化层和根据索引的反池化层,网络结构上也是采用了VGG16的backbone。但由于目前主流的神经网络框架没有针对池化和反池化操作进行优化,所以SegNet的推理时间会比较长,而从预测指标上来看,也没有非常惊艳的结果。所以SegNet只能说是在池化操作上提出了一些奇淫技巧。
4、实现代码
- 原作者公布的代码alexgkendall/caffe-segnet
- 个人的代码复现Runist/SegNet-keras
- SegNet的论文
边栏推荐
猜你喜欢

随机推荐
复杂格式的json转递
分布式cache项目
Unity Day02
【HIT-SC-MEMO7】哈工大2022软件构造 复习笔记7
bitnami/mongodb-sharded在AWS EKS扩展shard失败解决
C#找系统文件夹路径
关于gopher协议的ssrf攻击
硬件描述语言Verilog HDL学习笔记之模块介绍
Memory Management
Uos统信系统 DNS
0--100的能被3整出的数的集合打乱顺序
EL expression
网络安全求职指南
SSO单点登陆
【HIT-SC-MEMO1】哈工大2022软件构造 复习笔记1
树莓派 4 B 拨动开关控制风扇 Rasberry Pi 4 B Add Toggle Switch for the Fan
一场聚会,转行渗透测试月薪13.5k,感谢那个女同学......
并发概念基础:线程安全与线程间通信
PS像素画学习-1
CMDB 腾讯云部分实现