当前位置:网站首页>spark学习笔记(四)——sparkcore核心编程-RDD
spark学习笔记(四)——sparkcore核心编程-RDD
2022-07-27 01:31:00 【一个人的牛牛】
目录
RDD定义&特点
RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是 Spark 中最基本的数据处理模型。它代表一个弹性的、不可变、可分区、里面的元素可并行计算的集合。
RDD特点:
(1)弹性;
1)存储的弹性:内存与磁盘的自动切换;
2)容错的弹性:数据丢失可以自动恢复;
3)计算的弹性:计算出错重试机制;
4)分片的弹性:可根据需要重新分片。
RDD处理流程
执行原理

简单RDD处理流程

wordcount处理流程
 wordcount代码
wordcount代码
def main(args: Array[String]): Unit = {
//建立spark运行配置对象
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//建立连接对象
val sc:SparkContext = new SparkContext(sparkConf)
//读取文件
val fileRDD: RDD[String] = sc.textFile("datas")
//分词
val wordRDD: RDD[String] = fileRDD.flatMap(_.split(" "))
//数据结构转换
val word2RDD: RDD[(String, Int)] = wordRDD.map((_,1))
//分组聚合
val word2count: RDD[(String, Int)] = word2RDD.reduceByKey(_+_)
//采集结果到内存
val wordend: Array[(String, Int)] = word2count.collect()
//打印
word2count.foreach(println)
//关闭spark
sc.stop()
}RDD核心属性
(1)分区列表
RDD 数据结构中存在分区列表,用于执行任务时并行计算,是实现分布式计算的重要属性。
(2)分区计算函数
RDD基础编程
创建RDD
1) 从集合/内存中创建RDD
从集合中创建RDD,Spark主要提供了两个方法:parallelize和makeRDD;
def main(args: Array[String]): Unit = {
//准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
//从内存创建RDD,数据源为内存的数据
//Spark主要提供了两个方法:parallelize和makeRDD
val seq1 = Seq[Int](1,2,3,4)
val seq2 = Seq[Int](2,4,6,8)
//parallelize
val rdd1: RDD[Int] = sc.parallelize(seq1)
//makeRDD
val rdd2: RDD[Int] = sc.makeRDD(seq2)
rdd1.collect().foreach(println)
rdd2.collect().foreach(println)
//关闭环境
sc.stop()
}
2) 从外部文件创建RDD
从外部存储系统的数据集创建RDD;包括本地的文件系统和所有Hadoop支持的数据集, 比如HDFS、HBase;
def main(args: Array[String]): Unit = {
//准备环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
//从文件中创建,数据源为文件
//path路径默认为当前环境的根路径为基准,可以写绝对路径或者相对路径
val rdd: RDD[String] = sc.textFile("datas/word1.txt")
//sc.textFile("D:\\spark\\ec\\word.txt")本地文件路径
//sc.textFile("hdfs://hadoop01:8020/datas/word.txt")分布式存储路径
//sc.textFile("datas")目录路径
//sc.textFile("datas/*.txt")通配符路径
//sc.wholeTextFiles("datas")
//以文件为单位读取数据,结果表示为元组,第一个为文件路径,第二个为内容
rdd.collect().foreach(println)
//关闭环境
sc.stop()
}
3) 从其他RDD创建RDD
通过一个RDD运算完后,产生新的RDD;
例:wordcount程序
4) 直接创建RDD
使用new的方式直接构造RDD,一般由Spark框架自身使用。
RDD并行度与分区
Spark将一个作业切分为多个任务,发送给Executor节点并行计算,而能够并行计算的任务数量我们称之为并行度。
这个数量可以在构建 RDD 时指定。这里的并行执行的任务数量并不是指的切分任务的数量。
例:把任务切分成100个,任务数量为100,并行度为20,并行执行的任务数量就为20。
内存
读取内存数据时,数据可以按照并行度的设定进行数据的分区操作。
def main(args: Array[String]): Unit = {
//环境准备
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
//sparkConf.set("spark.default.parallelism","4")配置4个分区(方式一)
val sc = new SparkContext(sparkConf)
//创建RDD
//并行度&分区
//sc.makeRDD(List(1,2,3,4,5,6,7,8),4)配置4个分区(方式二)
val rdd = sc.makeRDD(List(1,2,3,4,5,6,7,8),2)
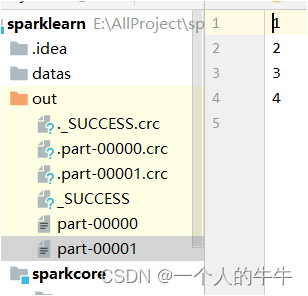
rdd.saveAsTextFile("out")
//关闭环境
sc.stop()
}

文件
读取文件数据时,数据是按照Hadoop文件读取的规则进行切片分区。

def main(args: Array[String]): Unit = {
//创建环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("RDD")
val sc = new SparkContext(sparkConf)
//创建RDD
//textFile将文件作为数据源,默认可以分区
//minPartitions:最小分区数
//math.min(defaultParallelism, 2)默认分区为2
//val rdd = sc.textFile("datas/word1.txt")默认分区
//val rdd = sc.textFile("datas/word1.txt",3)设置最小分区数为3
val rdd = sc.textFile("datas/word1.txt",3)
//分区计算方式:totalSize=7,goalSize = 7/3=2...1 3分区 注:7是字节数
//val rdd = sc.textFile("datas/word1.txt",3)
//totalSize=9,goalSize = 7/4 =1....3 2+1=3分区
rdd.saveAsTextFile("output1")
//关闭环境
sc.stop()
} 
RDD转换算子
spark学习笔记(五)——sparkcore核心编程-RDD转换算子_一个人的牛牛的博客-CSDN博客
RDD行动算子
边栏推荐
- OC-消息机制
- 次轮Okaleido Tiger即将登录Binance NFT,引发社区热议
- Abbkine AbFluor 488 细胞凋亡检测试剂盒特点及实验建议
- 一道数学题,让芯片巨头亏了5亿美金!
- [dynamic programming simple question] leetcode 53. maximum subarray and
- Bulk copy baby upload prompt garbled, how to solve?
- My crawler notes (VII) blog traffic +1 through Crawlers
- How to design the red table of database to optimize the performance
- 177. The nth highest salary (simple)
- 一个测试类了解BeanUtils.copyProperties
猜你喜欢
Common questions and answers of software testing interview (divergent thinking, interface, performance, concept,)

浅浅梳理一下双轴快排(DualPivotQuickSort)

仿知乎论坛社区社交微信小程序

Hcip day 14 notes

impala 执行计划详解
HCIP第十四天笔记

5、 MFC view windows and documents

window对象的常见事件

MySQL:互联网公司常用分库分表方案汇总

After two years of graduation, I switched to software testing and got 12k+, and my dream of not taking the postgraduate entrance examination with a monthly salary of more than 10000 was realized

随机推荐
177. The nth highest salary (simple)
window对象的常见事件
自己梳理的LocalDateTime的工具类
Role of thread.sleep (0)
Common events of window objects
2649: 段位计算
【flask】服务端获取客户端的请求头信息
Boom 3D全新2022版音频增强应用程序App
[二分查找简单题] LeetCode 35. 搜索插入位置,69. x 的平方根,367. 有效的完全平方数,441. 排列硬币
Idea 中添加支持@Data 插件
力扣(LeetCode)207. 课程表(2022.07.26)
175. 组合两个表(非常简单)
Thread.Sleep(0)的作用
CAS deployment and successful login jump address
Coco test dev test code
Call jshaman's Web API interface to realize JS code encryption.
Single case mode (double check lock)
Hcip 13th day notes
[binary search simple question] leetcode 35. search insertion position, 69. Square root of X, 367. Effective complete square, 441. Arrange coins
spark:计算不同分区中相同key的平均值(入门级-简单实现)