当前位置:网站首页>Gan, why '𠮷 𠮷'.Length== 3 ??
Gan, why '𠮷 𠮷'.Length== 3 ??
2022-07-25 22:19:00 【Java technology stack】
source :juejin.cn/post/7025400771982131236
Occasionally encountered in the development process about coding 、Unicode,Emoji The problem of , I found that I didn't fully grasp the basic knowledge of this aspect . So after some searching and learning , Organize a few easy to understand articles and share them .
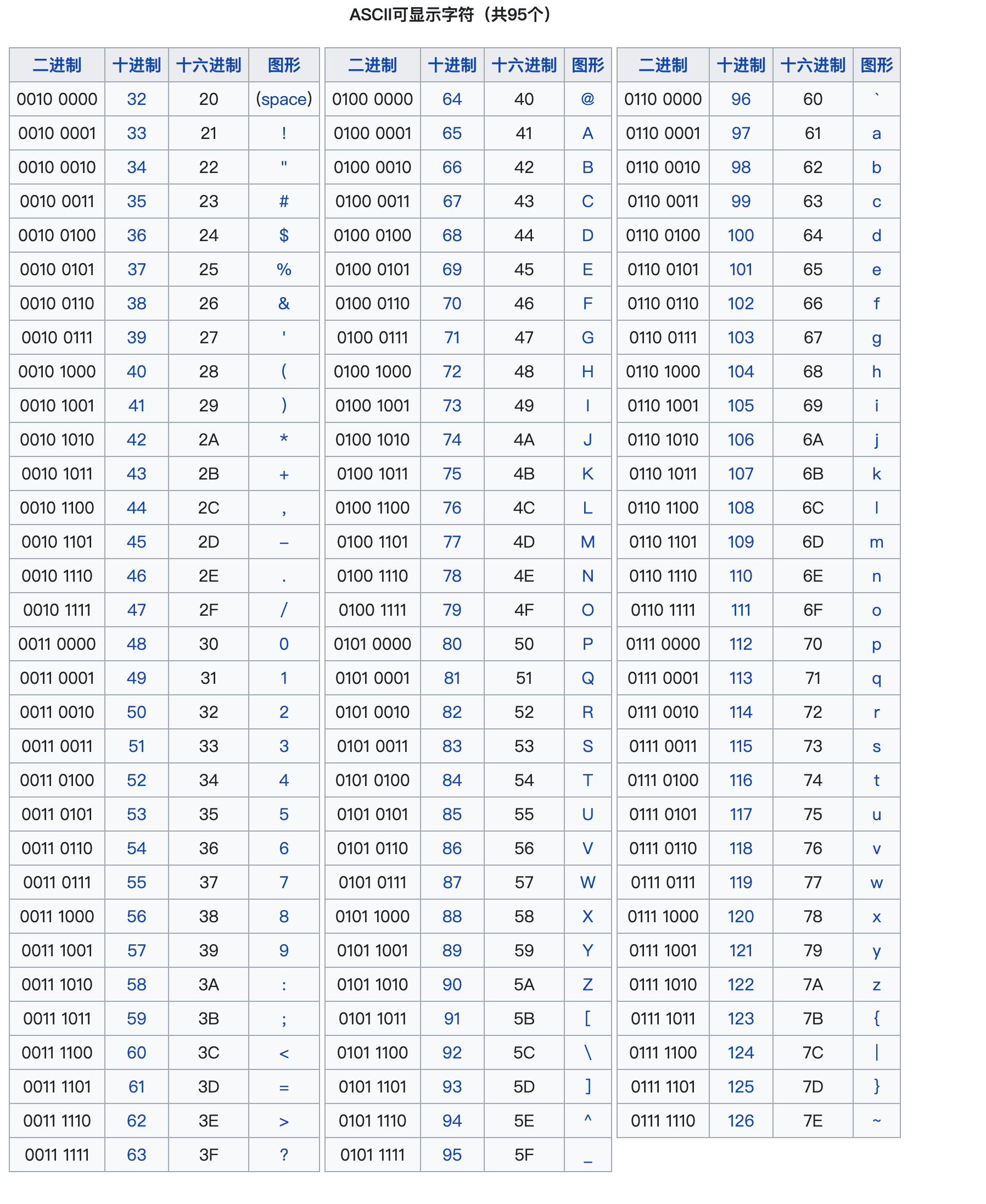
I wonder if you have ever encountered such doubts , In the need to check the length of the form , Different characters found length May vary in size . For example, in the title "𠮷" length yes 2( We need to pay attention to , This is not a Chinese character !).
' ji '.length// 1'𠮷'.length// 2''.length// 1''.length// 2 Copy code To explain this problem, we should start from UTF-16 Let's talk about .
UTF-16
from ECMAScript 2015 You can see in the specification ,ECMAScript Strings use UTF-16 code .
Definite and indefinite : UTF-16 The smallest symbol is two bytes , Even the first byte may be 0 Also take a seat , It's fixed . Not necessarily for the fundamental plane (BMP) Only two bytes are required for the character , Scope of representation
U+0000 ~ U+FFFF, For the supplementary plane, it needs to occupy four bytesU+010000~U+10FFFF.
In the last article , We have introduced utf-8 Coding details , come to know utf-8 Coding needs to occupy 1~4 Different bytes , While using utf-16 You need to take 2 or 4 Bytes . Let's see utf-16 How is it encoded .
UTF-16 Coding logic
UTF-16 The coding is simple , For a given Unicode Code points cp(CodePoint That is, this character is in Unicode Unique number in ):
- If the code point is less than or equal to
U+FFFF( That is, all characters of the basic plane ), No need to deal with , Use it directly . - otherwise , Split into two parts
((cp – 65536) / 1024) + 0xD800,((cp – 65536) % 1024) + 0xDC00To store .
Unicode The standard stipulates U+D800...U+DFFF The value of does not correspond to any character , So it can be used to mark .
Take a specific example : character A The code point is U+0041, It can be directly represented by a symbol .
'\u0041'// -> AA === '\u0041'// -> true Copy code Javascript in \u Express Unicode The escape character of , Followed by a hexadecimal number .
And characters The code point is U+1f4a9, Characters in the supplementary plane , after The formula calculates two symbols 55357, 56489 These two numbers are expressed in hexadecimal as d83d, dca9, Combine the two coding results into a proxy pair .
'\ud83d\udca9'// -> '''' === '\ud83d\udca9'// -> true Copy code because Javascript String usage utf-16 code , So you can correctly pair the agent to \ud83d\udca9 Decode to get the code point U+1f4a9.
You can also use \u + {}, Characters are represented by code points directly followed in braces . Looks different , But they said the results were the same .
'\u0041' === '\u{41}'// -> true'\ud83d\udca9' === '\u{1f4a9}'// -> true Copy code Can open Dev Tool Of console panel , Run code validation results .
So why length There will be problems with judgment ?
To answer this question , You can continue to view the specification , Mentioned inside : stay ECMAScript Where the operation interprets the string value , Every Elements Are interpreted as Single UTF-16 Code unit .
Where ECMAScript operations interpret String values, each element is interpreted as a single UTF-16 code unit.
So it's like Characters actually take up two UTF-16 Symbol of , That is, two elements , So it's length The attribute is 2.( This is the same as the beginning JS Use USC-2 Coding is about , I thought 65536 One character can meet all the needs )
But for the average user , There's no way to understand , Why did you only fill in one '𠮷', The program prompts that it takes up two characters , How can we correctly identify Unicode Character length ?
I am here Antd Form Used by the form async-validator You can see the following code in the package
const spRegexp = /[\uD800-\uDBFF][\uDC00-\uDFFF]/g;if (str) { val = value.replace(spRegexp, '_').length;} Copy code When it is necessary to judge the length of the string , All characters in the range of code points in the supplementary plane will be replaced with underscores , In this way, the length judgment is consistent with the actual display !!!
ES6 Yes Unicode Support for
length Attribute problem , Mainly the original design JS In this language , I didn't think there would be so many characters , It is considered that two bytes can be fully satisfied . So it's not just length, Some common operations of string are Unicode Support will also show abnormal .
The following content will introduce some exceptions API And in ES6 How to deal with these problems correctly .
for vs for of
For example, using for Loop print string , The string will follow JS Understand every “ Elements ” Traverse , The characters of the auxiliary plane will be recognized into two “ Elements ”, So there comes “ The statement ”.
var str = 'yo𠮷'for (var i = 0; i < str.length; i ++) { console.log(str[i])}// -> �// -> �// -> y// -> o// -> �// -> � Copy code While using ES6 Of for of Grammar will not .
var str = 'yo𠮷'for (const char of str) { console.log(char)}// -> // -> y// -> o// -> 𠮷 Copy code Expand grammar (Spread syntax)
The use of regular expressions was mentioned earlier , Count the character length by replacing the characters of the auxiliary plane . The same effect can be achieved by using the expansion syntax .
[...''].length// -> 1 Copy code slice, split, substr And so on .
Regular expressions u
ES6 It also aims at Unicode Characters added u The descriptor .
/^.$/.test('')// -> false/^.$/u.test('')// -> true Copy code charCodeAt/codePointAt
For strings , We also use charCodeAt To get Code Point, about BMP Flat characters are applicable , However, if the character is an auxiliary plane character charCodeAt The returned result will only be the number of the first symbol after encoding .
' plume '.charCodeAt(0)// -> 32701' plume '.codePointAt(0)// -> 32701''.charCodeAt(0)// -> 55357''.codePointAt(0)// -> 128568 Copy code While using codePointAt Then the characters can be recognized correctly , And return the correct code point .
String.prototype.normalize()
because JS Understand a string as a sequence of two byte symbols , The determination of equality is based on the value of the sequence . So there may be as like some strings that look as like as two peas. , But the result of string equality is false.
'café' === 'café'// -> false Copy code The first one in the above code café Yes, there is cafe Add an indented phonetic character \u0301 Composed of , And the second one. café It's made up of caf + é The characters make up . So although they look the same , But the size point is different , therefore JS The result of equality judgment is false.
'cafe\u0301'// -> 'café''cafe\u0301'.length// -> 5'café'.length// -> 4 Copy code In order to correctly identify this code, the points are different , But the same semantic string judgment ,ES6 Added String.prototype.normalize Method .
'cafe\u0301'.normalize() === 'café'.normalize()// -> true'cafe\u0301'.normalize().length// -> 4 Copy code summary
This article is mainly my recent study notes on relearning coding , Because of the rush of time && Level co., LTD. , There must be a lot of inaccurate descriptions in the article 、 Even the wrong content , If you find anything, please kindly point out .️
Recent hot article recommends :
1.1,000+ Avenue Java Arrangement of interview questions and answers (2022 The latest version )
2. Explode !Java Xie Cheng is coming ...
3.Spring Boot 2.x course , It's too complete !
4. Don't write about the explosion on the screen , Try decorator mode , This is the elegant way !!
5.《Java Development Manual ( Song Mountain version )》 The latest release , Download it quickly !
I think it's good , Don't forget to like it + Forward !
边栏推荐
- The reisson distributed lock renewal failed due to network reasons, resulting in the automatic release of the lock when the business is still executing but the lock is not renewed.
- 2day
- ML-Numpy
- TFrecord写入与读取
- Method of converting MAPGIS format to ArcGIS
- [C syntax] void*
- The second short contact of gamecloud 1608
- [fan Tan] those stories that seem to be thinking of the company but are actually very selfish (I: building wheels)
- Unity performance optimization direction
- 在腾讯干软件测试3年,7月无情被辞,想给划水的兄弟提个醒...
猜你喜欢









随机推荐
El expression improves JSP
在腾讯干软件测试3年,7月无情被辞,想给划水的兄弟提个醒...
JS timer and swiper plug-in
Interpretation of the source code of all logging systems in XXL job (line by line source code interpretation)
Xiaobai programmer's first day
The third day of Xiaobai programmer
Redis基础2(笔记)
VIM usage record
MySQL --- 子查询 - 列子查询(多行子查询)
Formal parameters, arguments and return values in functions
How is it most convenient to open an account for stock speculation? Is it safe for online account managers to open an account
vim用法记录
QML module not found
ArcGIS中的WKID
QML module not found
力矩电机控制基本原理
手机端微信发朋友圈功能测试点总结
Selenium basic use and use selenium to capture the recruitment information of a website (continuously updating)
【数据库学习】Redis 解析器&&单线程&&模型
mysql: error while loading shared libraries: libncurses.so. 5: cannot open shared object file: No suc