当前位置:网站首页>Flink优化的方方面面
Flink优化的方方面面
2022-08-02 21:03:00 【大学生爱编程】
1. MinBatch聚合(微批处理:每隔一段时间更新状态)
flink默认每一条数据都会更新状态,此处我们缓存一批数据进行更新
优缺点:增加吞吐量但增加延迟,综合考虑
设置MinBatch:
-- sql中开启
-- 开启
set table.exec.mini-batch.enabled=true;
-- 最大缓存时间
set table.exec.mini-batch.allow-latency='5 s';
-- 批次大小
set table.exec.mini-batch.size=1000;
2. Local-Global 本地加全局聚合
开启预聚合需要先开启MiniBatch
-- 开启MinBatch
set table.exec.mini-batch.enabled=true;
-- 最大缓存时间
set table.exec.mini-batch.allow-latency='5 s';
-- 批次大小
set table.exec.mini-batch.size=1000;
-- 开启预聚合
set table.optimizer.agg-phase-strategy=TWO_PHASE;
2.1 datagen-blackhole示例
写入黑洞是用于高性能测试的,写入命令行会造成限制
上游产生数据太多,下游处理数据太少,造成反压,但是任务也不会失败会报警告
灰色运行状态:上游反压
-- source 表
CREATE TABLE words (
word STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '10000', -- 每秒生成多少行数据
'fields.word.length' = '2' --字段长度限制
);
-- 黑洞
CREATE TABLE blackhole_table (
word STRING,
c BIGINT
)
WITH ('connector' = 'blackhole')
-- 执行查询
insert into blackhole_table
select word,count(1) as c from
words
group by word
2.2 图解
出现反压造成数据延迟的问题,处理不过来的数据保存在内存中,内存增加的时候会向上游反馈,上游数据放在自己的内存中,再向flink源数据进行反馈,直到sourcetask降低读取数据速率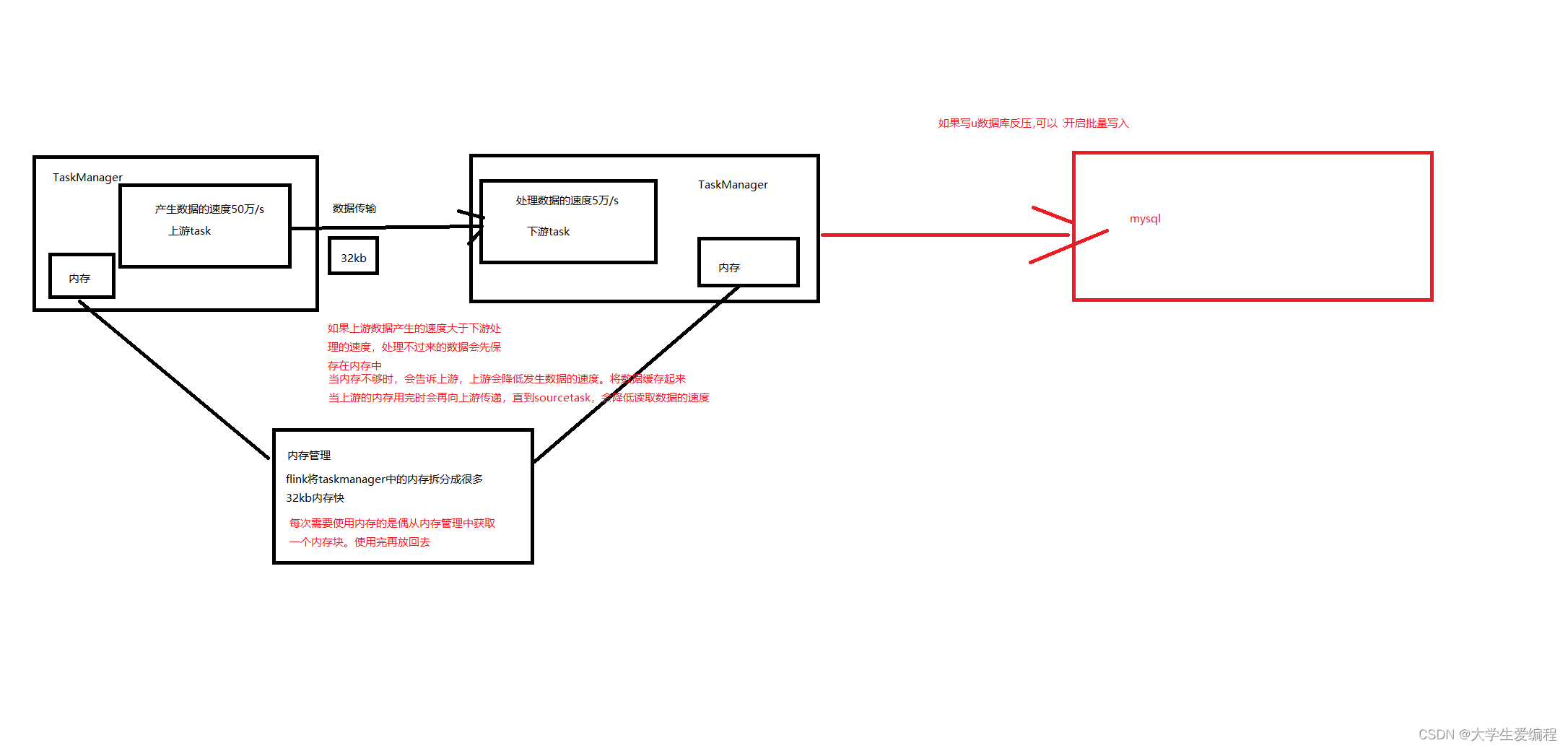
2.3 datagen数据写入数据库调节反压示例
2.3.1 开启预聚合优化Flink内部反压(参数互相配合,调节测试)
上游生产数据的速度时50万每秒,下游消费数据的速度10万每秒 —反压
--source
CREATE TABLE words (
word STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '500000', -- 每秒生成多少行数据
'fields.word.length' = '2' --字段长度限制
);
-- 黑洞
CREATE TABLE blackhole_table (
word STRING,
c BIGINT
)
WITH ('connector' = 'blackhole');
--sql语句
insert into blackhole_table
select word,count(1) as c from
words
group by word;
开启minibatch和预聚合,预聚合之后上游发送到数据下游数据量会减少,flink内部没有发生反压了
set table.exec.mini-batch.enabled=true;
set table.exec.mini-batch.allow-latency='5 s';
set table.exec.mini-batch.size=1000;
set table.optimizer.agg-phase-strategy=TWO_PHASE;
2.3.2 写入MySQL出现外部反压(对写入方式进行调节)
将数据保存到mysql,写入数据的速度只能达到1600/s - 反压
数据源还是上面的datagen
--mysql sink
CREATE TABLE word_count (
word STRING,
c BIGINT,
PRIMARY KEY (word) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata',
'table-name' = 'word_count',
'username' = 'root',
'password' = '123456'
)
--sql语句
insert into word_count
select word,count(1) as c from
words
group by word
1.此时出现反压,我们采用批量写入等操作,增加批次大小(数据不是一条条写,会增加延迟),和提高并行度(资源申请耗时,增加成本),可以解决反压
2.删除表word_count 后添加sink表的设置:
--sink表
CREATE TABLE word_count (
word STRING,
c BIGINT,
PRIMARY KEY (word) NOT ENFORCED
) WITH (
'connector' = 'jdbc',
'url' = 'jdbc:mysql://master:3306/bigdata',
'table-name' = 'word_count',
'username' = 'root',
'password' = '123456',
'sink.buffer-flush.max-rows'='1000' ,-- 每批次最大值,会增加延迟
'sink.parallelism' ='3' --提高写入数据并行度,增加成本
);
--sql语句
insert into word_count
select word,count(1) as c from
words
group by word;
2.3.3 数据写入hbase出现反压
-- source 表
CREATE TABLE words (
word STRING
) WITH (
'connector' = 'datagen',
'rows-per-second' = '500000', -- 每秒生成的数据行数据
'fields.word.length' = '2' --字段长度限制
);
-- hbase sink
drop table hbase_word_count;
CREATE TABLE hbase_word_count (
word STRING,
info ROW<c BIGINT>,
PRIMARY KEY (word) NOT ENFORCED
) WITH (
'connector' = 'hbase-1.4',
'table-name' = 'word_count',
'zookeeper.quorum' = 'master:2181,node1:2181,node2:2181',
'sink.parallelism' = '3', -- 写入数据并行度
'sink.buffer-flush.max-rows' = '3000' -- 写入数据批次大小
);
--先再habse中创建表
create 'word_count','info'
--- 将数据写入hbase
insert into hbase_word_count
select word,ROW(c) as info from (
select word,count(1) as c from
words
group by word
) as a;
手动切分region,效果也一般看不出来,如果是分布式的效果预期会好一些
3. 反压总结
上游生产数据速度比下游消费数据速度大,flink会发生反压,反压会从下游向上游传播,直到sourcetask降低拉去数据速度,避免flink任务执行报错
3.1flink内部发生反压
增加flink任务并行度,就是加资源,申请资源时间长,成本提高
-- flink sql
SET 'parallelism.default' = '2';
会增加延迟:
set table.exec.mini-batch.enabled=true;
-- 最大缓存时间
set table.exec.mini-batch.allow-latency='5 s';
-- 批次大小
set table.exec.mini-batch.size=1000;
-- 开启预聚合
set table.optimizer.agg-phase-strategy=TWO_PHASE;
3.2 数据保存到外部发生反压
写入MySQL:
-- 每批次最大值,会增加延迟
'sink.buffer-flush.max-rows'='1000'
--提高写入数据并行度,增加成本
'sink.parallelism' ='3'
写入hbase:
-- 每批次最大值,会增加延迟
'sink.buffer-flush.max-rows'='1000'
--提高写入数据并行度,增加成本
'sink.parallelism' ='3'
异步IO(只支持hbase2.2以上版本):
flink查询hbase可以开启异步IO:
lookup.async=true
边栏推荐
猜你喜欢

增删改查这么多年,最后栽在MySQL的架构设计上!
HCIP--路由策略实验
A brief discussion on the transformation of .NET legacy applications
Redis是如何轻松实现系统秒杀的?
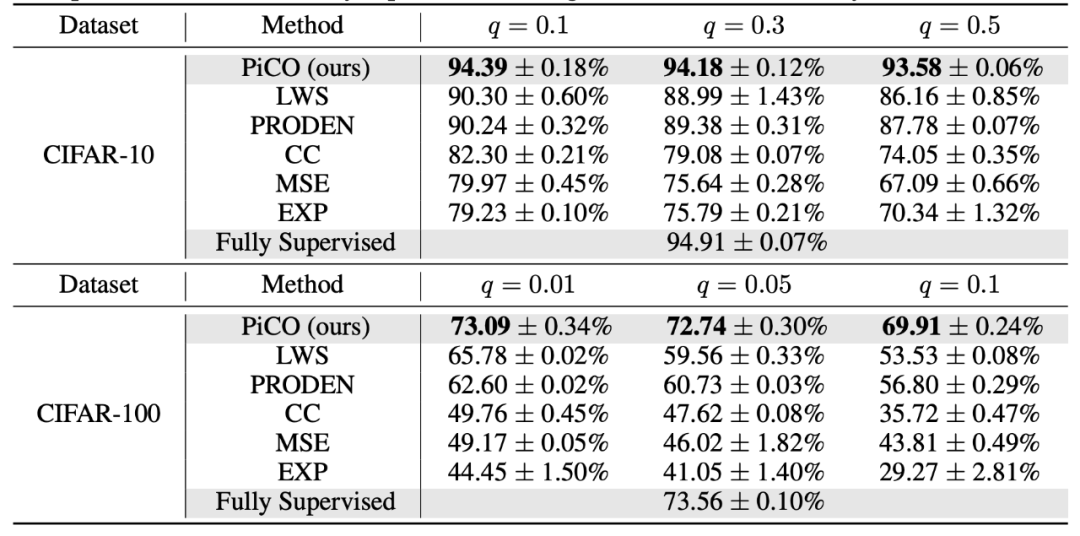
ICLR 2022最佳论文:基于对比消歧的偏标签学习
Adobe官方清理工具Adobe Creative Cloud Cleaner Tool使用教程

汉源高科千兆4光4电工业级网管型智能环网冗余以太网交换机防浪涌防雷导轨式安装
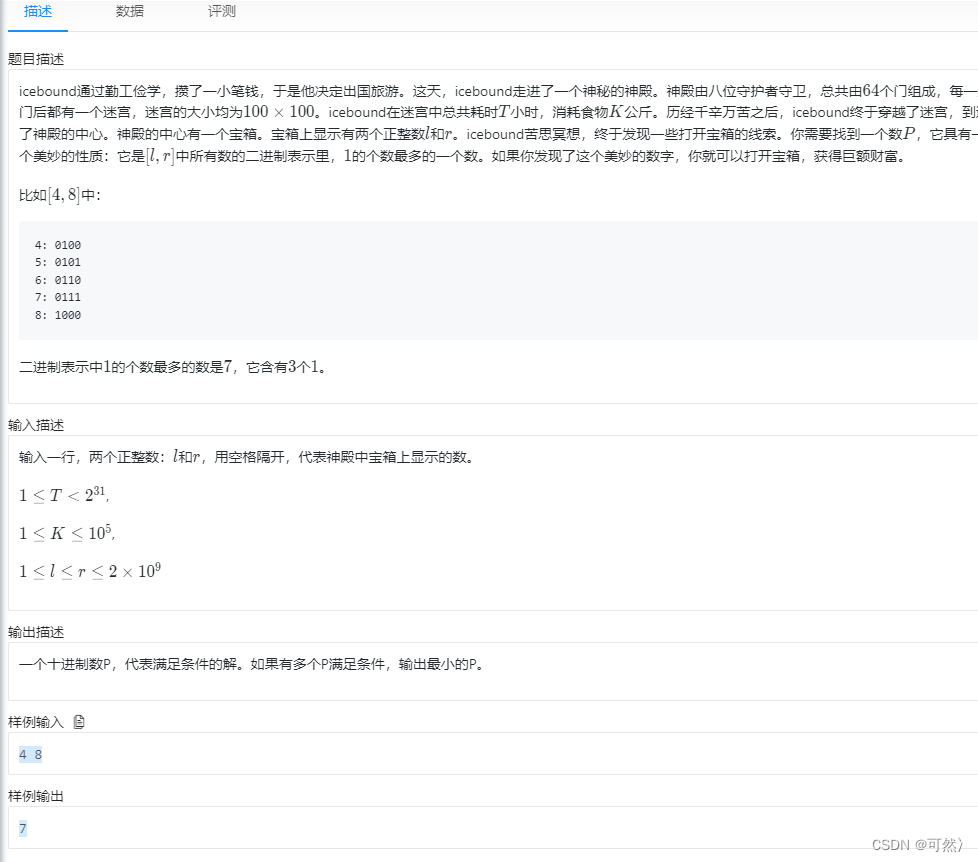
2018HBCPC个人题解

The software testing process specification is what?Specific what to do?
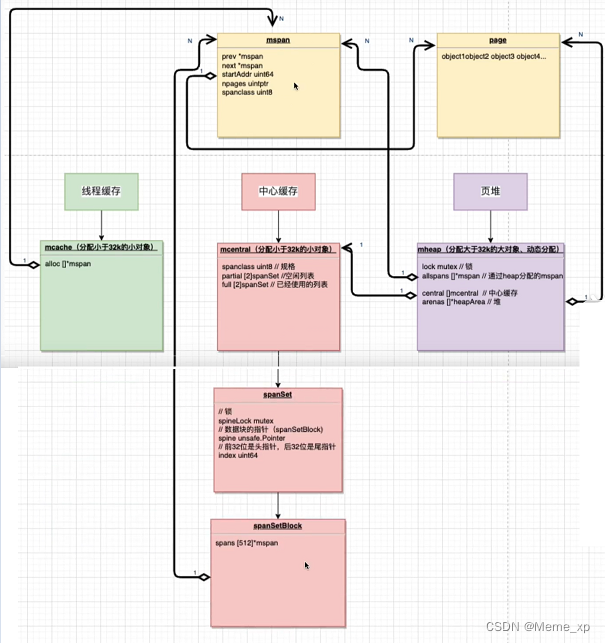
go——内存分配机制

随机推荐
【3D视觉】深度摄像头与3D重建
开关、电机、断路器、电热偶、电表接线图大全
js函数防抖和函数节流及其他使用场景
如何成为一名正义黑客?你应该学习什么?
微软SQL服务器被黑客入侵以窃取代理服务的带宽
Informatics Olympiad All-in-One (1260: [Example 9.4] Intercepting Missiles (Noip1999))
HCIP--路由策略实验
Details in C# you don't know
C语言中变量在内存中的保存与访问
Day35 LeetCode
[C题目]力扣1. 两数之和
How to quickly compare two byte arrays for equality in .NET
解道6-编程技术3
y85.第四章 Prometheus大厂监控体系及实战 -- prometheus告警机制进阶、pushgateway和prometheus存储(十六)
字节内部技术图谱 惊艳级实用
性能测试 - 理论
解道7-编程技术4
解道9-编程技术6
iptables、firewalld的使用
Redis是如何轻松实现系统秒杀的?