当前位置:网站首页>redis主从模式
redis主从模式
2022-07-05 11:31:00 【我们一直在路上】
一、Redis中高可用设计的必要性
Redis作为一个高性能Nosq中间件,会有很多热点数据存放在Redis中,一旦Redis-server出现故障,会导致所有相关业务访问都出现问题。另外,即便是设计了数据库兜底的方案,大量请求对数据库的访问也很容易导致数据库出现瓶颈,造成更大的灾难。
除此之外,Redis的集群部署还可以带来额外的收益:
- 负载(性能),Redis本身的QPS已经很高了,但是如果在一些并发量非常高的情况下,性能还是会受到影响。这个时候我们希望有更多的Redis服务来完成工作
- 扩容(水平扩展),第二个是出于存储的考虑。因为Redis所有的数据都放在内存中,如果数据量大,很容易受到硬件的限制。升级硬件收效和成本比太低,所以我们需要有一种横向扩展的方法
二、主从复制的好处
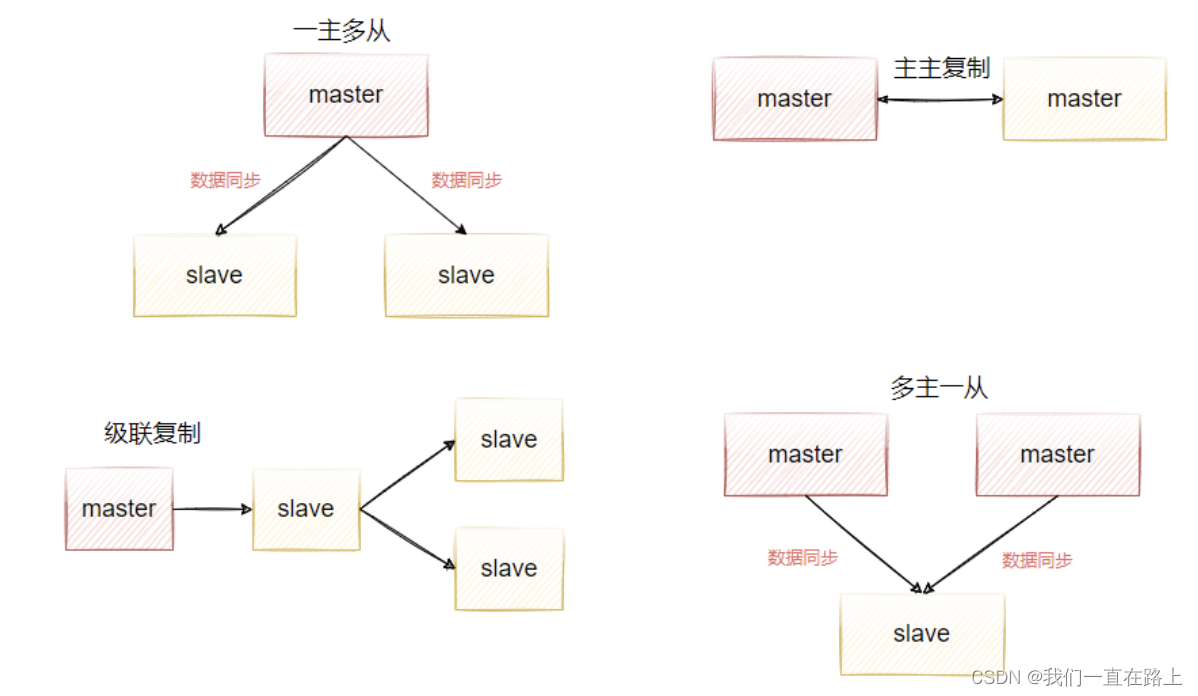
- 数据冗余,主从复制实现了数据的热备,是除了持久化机制之外的另外一种数据冗余方式。
- 读写分离,使数据库能支撑更大的并发。在报表中尤其重要。由于部分报表sql语句非常的慢,导致锁表,影响前台服务。如果前台使用master,报表使用slave,那么报表sql将不会造成前台锁,保证了前台速度。
- 负载均衡,在主从复制的基础上,配合读写分离机制,可以由主节点提供写服务,从节点提供服务。在读多写少的场景中,可以增加从节点来分担redis-server读操作的负载能力,从而大大提高redis-server的并发量
- 保证高可用,作为后备数据库,如果主节点出现故障后,可以切换到从节点继续工作,保证redisserver的高可用。
三、redis如何搭建主从
需要注意,Redis的主从复制,是直接在从节点发起就行,主节点不需要做任何事情
1.在Redis中有三种方式来开启主从复制
- 在从服务器的redis.conf配置文件中加入下面这个配置
replicaof <masterip> <masterport>
- 通过启动命令来配置,也就是启动slave节点时执行如下命令
./redis-server ../redis.conf --replicaof <masterip> <masterport>
- 启动redis-server之后,直接在客户端窗口执行下面命令
redis>replicaof <masterip> <masterport>
启动成功后,使用如下命令查看集群状态
redis> info replication
启动日志中可以看到,在启动过程中已经从master节点复制了信息。
66267:S 12 Jul 2021 22:21:46.013 * Loading RDB produced by version 6.0.9
66267:S 12 Jul 2021 22:21:46.013 * RDB age 50 seconds
66267:S 12 Jul 2021 22:21:46.013 * RDB memory usage when created 0.77 Mb
66267:S 12 Jul 2021 22:21:46.013 * DB loaded from disk: 0.000 seconds
66267:S 12 Jul 2021 22:21:46.013 * Ready to accept connections
66267:S 12 Jul 2021 22:21:46.013 * Connecting to MASTER 192.168.221.128:6379
66267:S 12 Jul 2021 22:21:46.014 * MASTER <-> REPLICA sync started
66267:S 12 Jul 2021 22:21:46.015 * Non blocking connect for SYNC fired the
event.
66267:S 12 Jul 2021 22:21:46.016 * Master replied to PING, replication can
continue...
66267:S 12 Jul 2021 22:21:46.017 * Partial resynchronization not possible
(no cached master)
66267:S 12 Jul 2021 22:21:46.039 * Full resync from master:
acb74093b4c9d6fb527d3c713a44820ff0564508:0
66267:S 12 Jul 2021 22:21:46.058 * MASTER <-> REPLICA sync: receiving 188
bytes from master to disk
66267:S 12 Jul 2021 22:21:46.058 * MASTER <-> REPLICA sync: Flushing old
data
66267:S 12 Jul 2021 22:21:46.058 * MASTER <-> REPLICA sync: Loading DB in
memory
66267:S 12 Jul 2021 22:21:46.060 * Loading RDB produced by version 6.2.4
66267:S 12 Jul 2021 22:21:46.060 * RDB age 0 seconds
66267:S 12 Jul 2021 22:21:46.060 * RDB memory usage when created 1.83 Mb
66267:S 12 Jul 2021 22:21:46.060 * MASTER <-> REPLICA sync: Finished with
success
如果没有开启日志,可以通过下面的方法进行开启
- 找到Redis的配置文件 redis.conf
- 打开该配置文件, vi redis.conf;
- 通过linux的查询命令找到 (loglevel下面)logfile " " ;在冒号里面输入日志的路径,比如logfile “/usr/local/redis/log/redis.log”, 需要提前创建好目录和文件,redis默认不会创建该文件。
在默认情况下,slave服务器是只读的,如果直接在slave服务器上做修改,会报错. 不过可以在slave服务器的redis.conf中找到一个属性,允许slave服务器可以写,但是不建议这么做。因为slave服务器上的更改不能往master上同步,会造成数据不同步的问题
slave-read-only no
三、Redis主从复制的原理分析
Redis的主从复制分两种,一种是全量复制,另一种是增量复制。
1.全量复制
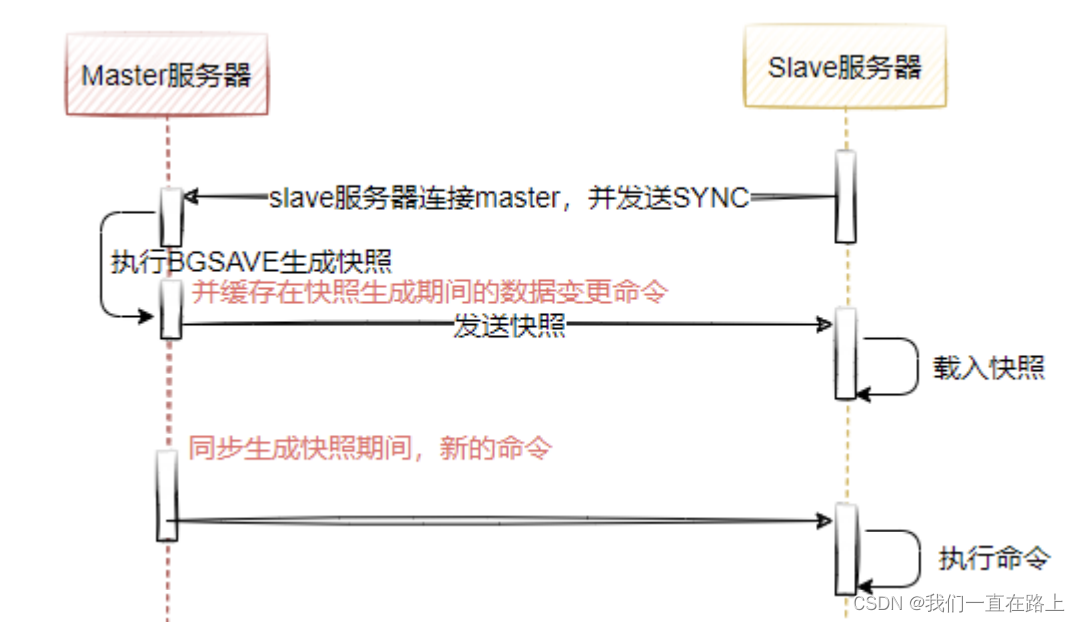
如图所示,表示Redis主从全量复制的整体时序图,全量复制一般发生在Slave节点初始化阶段,这个时候需要把master上所有数据都复制一份,具体步骤是:
- 从服务器连接主服务器,发送SYNC命令;
- 主服务器接收到SYNC命名后,开始执行BGSAVE命令生成RDB文件并使用缓冲区记录此后执行的所有写命令;
- 主服务器BGSAVE执行完后,向所有从服务器发送快照文件,并在发送期间继续记录被执行的写命令(表示RDB异步生成快照期间的数据变更);
- 从服务器收到快照文件后丢弃所有旧数据,载入收到的快照;
- 主服务器快照发送完毕后开始向从服务器发送缓冲区中的写命令;
- 从服务器完成对快照的载入,开始接收命令请求,并执行来自主服务器缓冲区的写命令;
问题:生成RDB期间,master接收到的命令怎么处理?
开始生成RDB文件时,master会把所有新的写命令缓存在内存中。在 slave node 保存了RDB之后,再将新的写命令复制给 slave node。(跟AOF重写期间的思路是一样的)
完成上面几个步骤后就完成了slave服务器数据初始化的所有操作,savle服务器此时可以接收来自用户的读请求,同时,主从节点进入到命令传播阶段,在这个阶段主节点将自己执行的写命令发送给从节点,从节点接收命令并执行,从而保证主从节点数据的一致性。在命令传播阶段,除了发送写命令,主从节点还维持着心跳机制:PING和REPLCONF ACK,下面演示一下具体的实现。
- 在slave服务器redis cli上执行 REPLCONF listening-port 6379 (向主数据库发送replconf命令说明自己的端口号)
- 开始同步,向master服务器发送sync命令开始同步,此时master会发送快照文件和缓存的命令。
127.0.0.1:6379> sync
Entering replica output mode... (press Ctrl-C to quit)
SYNC with master, discarding 202 bytes of bulk transfer...
SYNC done. Logging commands from master.
"ping"
"ping"
- slave会将收到的内容写入到硬盘上的临时文件,当写入完成后会用该临时文件替换原有的RDB快照文件。需要注意的是,在同步的过程中slave并不会阻塞,仍然可以处理客户端的命令。默认情况下slave会用同步前的数据对命令进行响应,如果我们希望读取的数据不能出现脏数据,那么可以在redis.conf文件中配置下面的参数,来使得slave在同步完成对所有命令之前,都回复错误:SYNC with master in progress
slave-serve-stale-data no
- 复制阶段结束后,master执行的任何非查询语句都会异步发送给slave。 可以在master节点执行set命令,可以在slave节点看到如下同步的指令。
redis > sync
"set","11","11"
"ping"
另外需要注意的是:
master/slave 复制策略是采用乐观复制,也就是说可以容忍在一定时间内master/slave数据的内容是不同的,但是两者的数据会最终同步成功。具体来说,redis的主从同步过程本身是异步的,意味着master执行完客户端请求的命令后会立即返回结果给客户端,然后异步的方式把命令同步给slave。这一特征保证启用master/slave后 master的性能不会受到影响。但是另一方面,如果在这个数据不一致的窗口期间,master/slave因为网络问题断开连接,而这个时候,master是无法得知某个命令最终同步给了多少slave数据库。不过redis提供了一个配置项来限制只有数据至少同步给多少个slave的时候,master才是可写的:修改master redis服务的redis.conf, 打开这两个配置,重启即可看到效果
min-replicas-to-write 3 表示只有当3个或以上的slave连接到master,master才是可写的
min-replicas-max-lag 10 表示允许slave最长失去连接的时间,如果10秒还没收到slave的响
应,则master认为该slave以断开
2.增量复制
从Redis2.8开始,主从节点支持增量复制,并且是支持断点续传的增量复制,也就是说如果出现复制异常或者网络连接断开导致复制中断的情况,在系统恢复之后仍然可以按照上次复制的地方继续同步,而不是全量复制。
它的具体原理是:主节点和从节点分别维护一个复制偏移量(offset),代表的是主节点向从节点传递的字节数;主节点每次向从节点传播N个字节数据时,主节点的offset增加N;从节点每次收到主节点传来的N个字节数据时,从节点的offset增加N。主从节点的偏移量可以分别保存在:master_repl_offset:78130 和 slave_repl_offset 这两个字段中,通过下面的命令可以查看。
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:192.168.221.128
master_port:6379
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:77864
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:acb74093b4c9d6fb527d3c713a44820ff0564508
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:77864
second_repl_offset:-1
repl_backlog_active:1 # 开启复制缓冲区
repl_backlog_size:1048576 # 缓冲区最大长度
repl_backlog_first_byte_offset:771 # 起始偏移量,计算当前缓存区可用范围
repl_backlog_histlen:77094 # 以保存数据的有效长度
3.无磁盘复制
前面我们说过,Redis复制的工作原理基于RDB方式的持久化实现的,也就是master在后台保存RDB快照,slave接收到rdb文件并载入,但是这种方式会存在一些问题。
- 当master禁用RDB时,如果执行了复制初始化操作,Redis依然会生成RDB快照,当master下次启动时执行该RDB文件的恢复,但是因为复制发生的时间点不确定,所以恢复的数据可能是任何时间点的。就会造成数据出现问题
- 当硬盘性能比较慢的情况下(网络硬盘),那初始化复制过程会对性能产生影响
因此2.8.18以后的版本,Redis引入了无硬盘复制选项,可以不需要通过RDB文件去同步,直接发送数据,通过以下配置来开启该功能:
repl-diskless-sync yes
master在内存中直接创建rdb,然后发送给slave,不会在自己本地落地磁盘了
4.主从复制注意事项
主从模式解决了数据备份和性能(通过读写分离)的问题,但是还是存在一些不足:
- 第一次建立复制的时候一定是全量复制,所以如果主节点数据量较大,那么复制延迟就比较长,此时应该尽量避开流量的高峰期,避免造成阻塞;如果有多个从节点需要建立对主节点的复制,可以考虑将几个从节点错开,避免主节点带宽占用过大。此外,如果从节点过多,也可以调整主从复制的拓扑结构,由一主多从结构变为树状结构。
- 在一主一从或者一主多从的情况下,如果主服务器挂了,对外提供的服务就不可用了,单点问题没有得到解决。如果每次都是手动把之前的从服务器切换成主服务器,这个比较费时费力,还会造成一定时间的服务不可用。
边栏推荐
- 以交互方式安装ESXi 6.0
- Cdga | six principles that data governance has to adhere to
- 1.php的laravel创建项目
- go语言学习笔记-分析第一个程序
- c#操作xml文件
- What does cross-border e-commerce mean? What do you mainly do? What are the business models?
- Shell script file traversal STR to array string splicing
- MFC pet store information management system
- [there may be no default font]warning: imagettfbbox() [function.imagettfbbox]: invalid font filename
- SET XACT_ ABORT ON
猜你喜欢

Ziguang zhanrui's first 5g R17 IOT NTN satellite in the world has been measured on the Internet of things
【无标题】
Oneforall installation and use

Is it difficult to apply for a job after graduation? "Hundreds of days and tens of millions" online recruitment activities to solve your problems
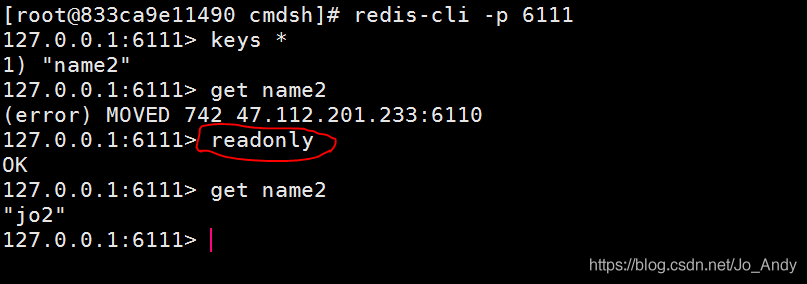
简单解决redis cluster中从节点读取不了数据(error) MOVED
12. (map data) cesium city building map
comsol--三维图形随便画----回转
高校毕业求职难?“百日千万”网络招聘活动解决你的难题

11. (map data section) how to download and use OSM data
12.(地图数据篇)cesium城市建筑物贴图
随机推荐
程序员内卷和保持行业竞争力
The ninth Operation Committee meeting of dragon lizard community was successfully held
Basics - rest style development
Is it difficult to apply for a job after graduation? "Hundreds of days and tens of millions" online recruitment activities to solve your problems
Ddrx addressing principle
[LeetCode] Wildcard Matching 外卡匹配
Dynamic SQL of ibatis
Sklearn model sorting
Risc-v-qemu-virt in FreeRTOS_ Scheduling opportunity of GCC
Open3D 网格(曲面)赋色
Solve the problem of slow access to foreign public static resources
Redis如何实现多可用区?
Summary of websites of app stores / APP markets
Cron expression (seven subexpressions)
-26374 and -26377 errors during coneroller execution
《看完就懂系列》15个方法教你玩转字符串
Startup process of uboot:
R3live series learning (IV) r2live source code reading (2)
中非 钻石副石怎么镶嵌,才能既安全又好看?
跨境电商是啥意思?主要是做什么的?业务模式有哪些?