当前位置:网站首页>Remember SQL optimization once
Remember SQL optimization once
2022-07-26 03:06:00 【JavaShark】
yesterday (2022-7-22) One of my functions has been launched , The amount of test environment data is small , No big problem , But after production , It's stuck , Then it started like this SQL Optimize , Here is a record of .
It is not convenient to disclose the table structure of the company , Here I have built several tables by myself , Just simulate it .
There must be a bar essence. To say that the watch can not be designed like this , But in fact, this is how the system is designed , If you want to change the table design , The impact is too large ( We are eager to go online ). Of course , Later in this article, the scheme of modifying the design will also be given , To achieve a better solution .
1. Create table
Purchase order form :
CREATE TABLE `purchase_order` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT ' The primary key increases automatically id',
`purchase_time` varchar(255) DEFAULT NULL COMMENT ' Purchase time ',
`purchase_pre_unit_price` decimal(10,2) unsigned zerofill NOT NULL COMMENT ' Purchase reservation unit price ( element /kg)',
`purchase_weight` decimal(10,2) unsigned zerofill NOT NULL COMMENT ' Incoming weight (kg)',
`purchase_bill_no` varchar(255) NOT NULL COMMENT ' Purchase order No ',
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=62181 DEFAULT CHARSET=utf8 COMMENT=' Purchase order ';
Purchase statement :
CREATE TABLE `settlement_voucher` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT ' Self increasing ID',
`purchase_bill_no` varchar(512) DEFAULT NULL COMMENT ' Purchase order No ',
`settlement_bill_no` varchar(64) NOT NULL COMMENT ' Settlement doc No ',
`unit_price` decimal(10,2) unsigned zerofill NOT NULL COMMENT ' Actual settlement unit price ( element /kg)',
`settlement_weight` decimal(10,2) unsigned zerofill NOT NULL COMMENT ' Actual settlement weight (kg)',
`cut_off_time` datetime DEFAULT NULL ON UPDATE CURRENT_TIMESTAMP COMMENT ' Settlement time ',
PRIMARY KEY (`id`),
KEY `idx_settlement_bill_no` (`settlement_bill_no`)
) ENGINE=InnoDB AUTO_INCREMENT=63288 DEFAULT CHARSET=utf8 COMMENT=' Purchase statement ';Invoice form :
CREATE TABLE `invoice` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT ' Primary key ID',
`invoice_code` varchar(255) NOT NULL COMMENT ' Invoice code ',
`invoice_number` varchar(255) NOT NULL COMMENT ' Invoice number ',
`pay_amount` decimal(10,2) DEFAULT NULL COMMENT ' Invoice amount ',
PRIMARY KEY (`id`),
KEY `idx_invoice_number` (`invoice_number`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=' Invoice form ';invoice - Statement related table :
CREATE TABLE `settlement_invoice_relation` (
`id` int(11) NOT NULL AUTO_INCREMENT COMMENT ' Primary key ID',
`invoice_code` varchar(255) DEFAULT NULL COMMENT ' Invoice code ',
`invoice_number` varchar(255) DEFAULT NULL COMMENT ' Invoice number ',
`settlement_bill_no` varchar(64) DEFAULT NULL COMMENT ' Settlement doc No ',
PRIMARY KEY (`id`),
KEY `idx_settlement_bill_no` (`settlement_bill_no`),
KEY `idx_invoice_number` (`invoice_number`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=' invoice - Statement related table ';These are the tables I created myself , First, let's introduce the relationship between these tables :
- Purchase order form (
purchase_order) And purchase statement (settlement_voucher) Through the purchase order number (purchase_bill_no) relation . Here's what's interesting :- One purchase order can correspond to multiple purchase settlement documents , adopt
purchase_bill_norelation , As shown in the following data : - One purchase settlement document can correspond to multiple purchase orders , adopt
purchase_bill_norelation ,settlement_voucherIn the tablepurchase_bill_noThe field stores multiple purchase orders , Use English commas to separate . As shown in the following data :
- One purchase order can correspond to multiple purchase settlement documents , adopt
- Invoice form (
invoice) And statement of accounts (settlement_voucher) There is an association table (settlement_invoice_relation)- Invoice table and association table use
invoice_codeandinvoice_numberrelation - The settlement document table and association table use
settlement_bill_norelation - Invoices and settlement documents are many to many
- Invoice table and association table use
2. demand
Now you need to use the purchase statement ( settlement_voucher ) Query out a list :
- The list field has 【 Purchase time ( Multiple commas are used to separate )、 Average purchase unit price 、 Total scheduled purchase amount , Settlement doc No , Average unit price of settlement , Settlement amount , Settlement time , Invoice number ( Multiple commas are used to separate ), Invoice code ( Multiple commas are used to separate )】
- The query conditions are : Purchase time ( When one purchase settlement document corresponds to multiple purchase documents , As long as there is a purchase order within the time range , Just find out ), Settlement time , Invoice number ( When a settlement document corresponds to multiple invoices , As long as there is an invoice that can be associated , Just find out )
- Sort according to the settlement time
Of course , The actual demand at that time , There are more list fields , There are more query conditions than this ......
3. Insert data into a table
First, give the bill of lading ( purchase_order ) And purchase statement ( settlement_voucher ) Insert each 10 Ten thousand data , I use stored procedures here :
begin
declare i int;
declare purchase_weight decimal(10,2);
declare unit_price decimal(10,2);
declare purchase_bill_no varchar(255);
declare settlement_bill_no varchar(255);
set i=0;
while i<100000 do
select ROUND(RAND()*100,2) into purchase_weight from dual;
select ROUND(RAND()*10,2) into unit_price from dual;
select CONCAT('purchase-',LPAD(i,8,'0')) into purchase_bill_no from dual;
select CONCAT('settlement-',LPAD(i,8,'0')) into settlement_bill_no from dual;
-- Insert the purchase order table , The purchase time is randomly generated
insert into purchase_order(purchase_time,purchase_pre_unit_price,purchase_weight,purchase_bill_no)
select (DATE_ADD(NOW(), INTERVAL FLOOR(1 - (RAND() * 864000)) SECOND )),
unit_price,purchase_weight,purchase_bill_no from dual;
-- Insert statement , The settlement time is randomly generated
insert into settlement_voucher(purchase_bill_no,settlement_bill_no,unit_price,settlement_weight,cut_off_time)
select purchase_bill_no,settlement_bill_no,unit_price,purchase_weight,
(DATE_ADD(NOW(), INTERVAL FLOOR(1 - (RAND() * 864000)) SECOND )) from dual;
set i=i+1;
end while;
endCall stored procedure to generate data :
call pre();
After generation, you need to change several pieces of data randomly , Simulate that one purchase order can correspond to multiple purchase settlement documents , And one purchase settlement document can correspond to multiple purchase orders ( In this way, the data is more realistic ).
The situation that one purchase order can correspond to multiple purchase settlement documents is not simulated , In fact, this situation has little impact on this query .
One purchase settlement document can correspond to multiple purchase orders :

Create some invoice data and settlement documents - Invoice related data , Need to reflect the many to many relationship :
insert into invoice(invoice_code,invoice_number,pay_amount)
VALUES
('111111','1111100','1000'),
('111112','1111101','1001'),
('111113','1111102','1002'),
('111114','1111103','1003'),
('111115','1111104','1004'),
('111116','1111105','1005'),
('111117','1111106','1006'),
('111118','1111107','1007'),
('111119','1111108','1008'),
('111110','1111109','1009');
INSERT into settlement_invoice_relation(invoice_code,invoice_number,settlement_bill_no)
VALUES
('111111','1111100','settlement-00000000'),
('111112','1111101','settlement-00000000'),
('111113','1111102','settlement-00000000'),
('111114','1111103','settlement-00000004'),
('111114','1111103','settlement-00000006'),
('111114','1111103','settlement-00000030'),
('111116','1111105','settlement-00000041'),
('111117','1111106','settlement-00000041'),
('111118','1111107','settlement-00000043');4. Start writing according to your needs SQL
The first step of optimization , Of course, I want the product manager to remove some query conditions , Avoid associating the purchase order table with the purchase settlement table , But you know ......
Here, take the purchase time as an example ( Because it is mainly the association between the purchase order and the purchase settlement order that leads to slow query ), Remember the demand , One purchase settlement may correspond to multiple purchase orders , As long as one of the purchase orders is within the time range , You need to find out this purchase settlement
also : The index in the table I created above also simulates the index before optimization at that time ......
4.1 The first edition
select
GROUP_CONCAT(po.purchase_time) as Purchase time ,
AVG(IFNULL(po.purchase_pre_unit_price,0)) as Average purchase price ,
t.settlement_bill_no as Settlement doc No ,
AVG(IFNULL(t.unit_price,0)) as Average settlement price ,
any_value(t.cut_off_time) as Settlement time ,
any_value(invoice_tmp.invoice_code) as Invoice code ,
any_value(invoice_tmp.invoice_number) as Invoice number
from settlement_voucher t
left join purchase_order po on FIND_IN_SET(po.purchase_bill_no,t.purchase_bill_no)>0
left join (
select sir.settlement_bill_no,
GROUP_CONCAT(i.invoice_number) invoice_number,
GROUP_CONCAT(i.invoice_code) invoice_code
from settlement_invoice_relation sir, invoice i
where sir.invoice_code = i.invoice_code and sir.invoice_number = i.invoice_number
group by sir.settlement_bill_no
) invoice_tmp on invoice_tmp.settlement_bill_no = t.settlement_bill_no
where 1=1
-- and t.settlement_bill_no='settlement-00000000'
and EXISTS(select 1 from purchase_order po1 where FIND_IN_SET(po1.purchase_bill_no,t.purchase_bill_no)>0
and po1.purchase_time >='2022-07-01 00:00:00'
)
and EXISTS(select 1 from purchase_order po1 where FIND_IN_SET(po1.purchase_bill_no,t.purchase_bill_no)>0
and po1.purchase_time <='2022-07-23 23:59:59'
)
group by t.settlement_bill_no;The first edition SQL At that time, it was implemented in the local environment with 5 About seconds , At this time, I have realized the problem , Let alone production , I have to hang up in the test environment .
But look at my own garbage server ( Dual core 4G) Run on this SQL Well , It can't be implemented at all ( Although the company server is better , But the production environment is really stuck ):

I haven't seen the implementation plan at that time , In a glance , This SQL Used in the FIND_IN_SET , I'm sure I won't go to the index , It's useless to build an index , That is, mainly the purchase order table ( purchase_order ) And purchase statement settlement_voucher Correlation will be slow , After all, they have a many to many relationship , Plus this disgusting need . So now think about how to avoid FIND_IN_SET .
Yes , During the meal , A whim : I should be able to split the purchase statement into a temporary table , If the purchase settlement sheet corresponds to 5 A purchase order , I'll split the purchase statement into 5 Data , These five data are different except for the purchase order number , Other fields equally , So that you don't have to FIND_IN_SET 了 .
Do as you say , So there is the second edition below SQL.
4.2 The second edition
Split the purchase statement into the above-mentioned temporary table , You need to add a table :
CREATE TABLE `incre_table` ( `id` int(11) NOT NULL AUTO_INCREMENT, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 COMMENT=' Used to split purchase settlement sheet '; -- Be careful : How many purchase orders does a purchase settlement correspond to , Here is how many pieces of data to insert in turn , I'm here 10 strip That's enough. insert into incre_table(id) VALUES(1); insert into incre_table(id) VALUES(2); insert into incre_table(id) VALUES(3); insert into incre_table(id) VALUES(4); insert into incre_table(id) VALUES(5); insert into incre_table(id) VALUES(6); insert into incre_table(id) VALUES(7); insert into incre_table(id) VALUES(8); insert into incre_table(id) VALUES(9); insert into incre_table(id) VALUES(10);
First, let's see how to split a purchase settlement into multiple pieces :
select
sv.cut_off_time,
sv.settlement_bill_no,
sv.unit_price,
sv.settlement_weight,
SUBSTRING_INDEX(SUBSTRING_INDEX(sv.purchase_bill_no,',',it.id),',',-1) purchase_bill_no
from settlement_voucher sv
RIGHT JOIN incre_table it on it.id<=(LENGTH(sv.purchase_bill_no) - LENGTH(REPLACE(sv.purchase_bill_no,',','')) + 1)
where sv.settlement_bill_no='settlement-00000000';To explain this operation :
- First of all, I created a system with only id Table of
incre_table, Ten pieces of data are inserted , And these ten data must be 1-10. - And then I use
settlement_voucherRight connectedincre_table, And only takeincre_tablein id Data less than or equal to the quantity of the purchase order . This will control this one SQL How many pieces of data should be queried ( It just happens to be the number of purchase orders corresponding to a purchase settlement ). - And then use
SUBSTRING_INDEXTo split one by onesettlement_voucherThe purchase order number in the table
This set of SQL The result of execution is :

combined , I finished the Second Edition SQL:
select
GROUP_CONCAT(po.purchase_time) as Purchase time ,
AVG(IFNULL(po.purchase_pre_unit_price,0)) as Average purchase price ,
t.settlement_bill_no as Settlement doc No ,
AVG(IFNULL(t.unit_price,0)) as Average settlement price ,
any_value(t.cut_off_time) as Settlement time ,
any_value(invoice_tmp.invoice_code) as Invoice code ,
any_value(invoice_tmp.invoice_number) as Invoice number
from (
select
sv.cut_off_time,
sv.settlement_bill_no,
sv.unit_price,
sv.settlement_weight,
SUBSTRING_INDEX(SUBSTRING_INDEX(sv.purchase_bill_no,',',it.id),',',-1) purchase_bill_no
from settlement_voucher sv
RIGHT JOIN incre_table it on it.id<=(LENGTH(sv.purchase_bill_no) - LENGTH(REPLACE(sv.purchase_bill_no,',','')) + 1)
) t
left join purchase_order po on po.purchase_bill_no = t.purchase_bill_no
left join (
select sir.settlement_bill_no,
GROUP_CONCAT(i.invoice_number) invoice_number,
GROUP_CONCAT(i.invoice_code) invoice_code
from settlement_invoice_relation sir, invoice i
where sir.invoice_code = i.invoice_code and sir.invoice_number = i.invoice_number
group by sir.settlement_bill_no
) invoice_tmp on invoice_tmp.settlement_bill_no = t.settlement_bill_no
where 1=1
-- and t.settlement_bill_no='settlement-00000000'
and po.purchase_time >='2022-07-01 00:00:00'
and po.purchase_time <='2022-07-23 23:59:59'
group by t.settlement_bill_no;There must be no problem with the test query data results !!!
well , Here we finally use everything FIND_IN_SET The place of , At this time, it is meaningful to look at the index !
Look at the implementation plan :

Asiba , A bunch of full table scans , Look at the second edition above SQL, Find the purchase list ( purchase_order ) Of purchase_bill_no Fields should be indexed , In principle, this field should have been quoted when designing tables , But I thought it was just that I thought , It's really not indexed , well , Then add an index to it :
create index idx_purchase_bill_no on purchase_order(purchase_bill_no);
After adding this index , Let's look at the implementation plan :
purchase_order Tabular purchase_bill_no Already gone , however settlement_invoice_relation Why not go to the index , It has two indexes ......

Take another look at the execution on my garbage server , See if it can be implemented :

Okay , In order to make settlement_invoice_relation The query of the table also goes through the index , Start the next round of SQL Optimize
4.3 The third edition
Don't aggregate and obtain below invoice_code and invoice_number 了 , Aggregate on it , As for using these two fields as query criteria , Then you can put this one below SQL Another layer of , Query again as a temporary table , I'm not going to do that here
select
GROUP_CONCAT(po.purchase_time) as Purchase time ,
AVG(IFNULL(po.purchase_pre_unit_price,0)) as Average purchase price ,
t.settlement_bill_no as Settlement doc No ,
AVG(IFNULL(t.unit_price,0)) as Average settlement price ,
any_value(t.cut_off_time) as Settlement time ,
GROUP_CONCAT(DISTINCT invoice_tmp.invoice_code) as Invoice code ,
GROUP_CONCAT(DISTINCT invoice_tmp.invoice_number) as Invoice number
from (
select
sv.cut_off_time,
sv.settlement_bill_no,
sv.unit_price,
sv.settlement_weight,
SUBSTRING_INDEX(SUBSTRING_INDEX(sv.purchase_bill_no,',',it.id),',',-1) purchase_bill_no
from settlement_voucher sv
RIGHT JOIN incre_table it on it.id<=(LENGTH(sv.purchase_bill_no) - LENGTH(REPLACE(sv.purchase_bill_no,',','')) + 1)
) t
left join purchase_order po on po.purchase_bill_no = t.purchase_bill_no
left join (
select sir.settlement_bill_no,
i.invoice_number,
i.invoice_code
from settlement_invoice_relation sir, invoice i
where sir.invoice_code = i.invoice_code and sir.invoice_number = i.invoice_number
) invoice_tmp on invoice_tmp.settlement_bill_no = t.settlement_bill_no
where 1=1
-- and t.settlement_bill_no='settlement-00000000'
and po.purchase_time >='2022-07-01 00:00:00'
and po.purchase_time <='2022-07-23 23:59:59'
group by t.settlement_bill_no;Let's look at the implementation plan :

At this time , Basic optimization is over , Look at the results on my spam server :

Come here , Basically, the production can be found in less than three seconds , This time SQL Optimization is over !!!
however , In fact, we can continue to optimize , But there are many changes in the design to the system , The impact is relatively large , Let's talk about the train of thought , Temporarily unable to practice :
You can list the purchase order purchase_order And purchase statement settlement_voucher Between , Create a middle table , Implement many to many relationships , Then index , It should be faster , And it can be done once and for all , In the future, this connection will be more convenient !
边栏推荐
- STM32 - serial port learning notes (one byte, 16 bit data, string, array)
- STM——EXTI外部中断学习笔记
- 对于稳定性测试必需关注的26点
- Personally test five efficient and practical ways to get rid of orders, and quickly collect them to help you quickly find high-quality objects!
- LeetCode·每日一题·剑指 Offer || 115.重建序列·拓扑排序
- Quick check of OGC WebGIS common service standards (wms/wmts/tms/wfs)
- GoLang日志编程系统
- 图像识别(七)| 池化层是什么?有什么作用?
- Arthas' dynamic load class (retransform)
- Continuous delivery and Devops are good friends
猜你喜欢

Personally test five efficient and practical ways to get rid of orders, and quickly collect them to help you quickly find high-quality objects!
![[sql] case expression](/img/05/1bbb0b5099443f7ce5f5511703477e.png)
[sql] case expression

Win11更改磁盘驱动器号的方法

How to effectively prevent others from wearing the homepage snapshot of the website
What if the test / development programmer gets old? Lingering cruel facts
![[translation] safety. Value of sboms](/img/8b/1ad825e7c9b6a87ca1fea812556f3a.jpg)
[translation] safety. Value of sboms

JVM内存模型解析
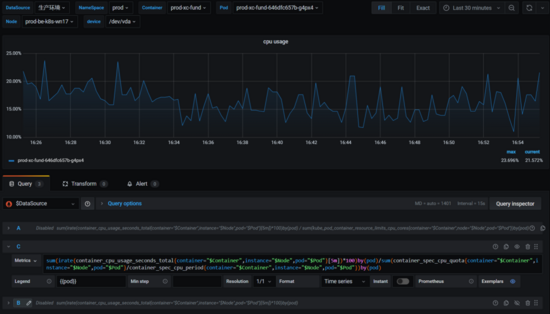
如何正确计算 Kubernetes 容器 CPU 使用率
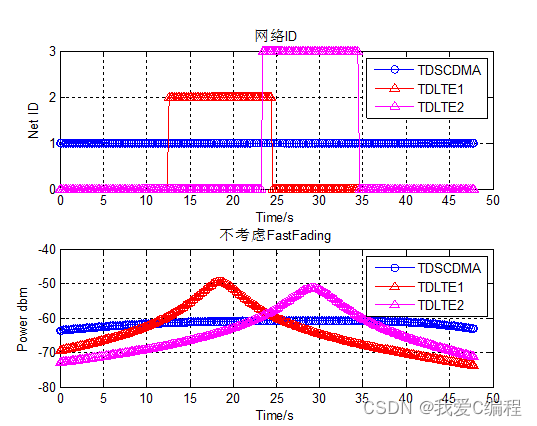
Matlab simulation of vertical handover between MTD SCDMA and TD LTE dual networks

循环与分支(一)
随机推荐
[translation] safety. Value of sboms
FPGA_ Initial use process of vivado software_ Ultra detailed
Win11 hide input method status bar method
YOLOv3: An Incremental Improvement
Neo4j 导入csv数据报错:Neo4j load csv error : Couldn‘t load the external resource
Be highly vigilant! Weaponization of smartphone location data on the battlefield
QT signal transmission between multi-level objects signal transmission between multi-level nested class objects
Continuous delivery and Devops are good friends
Service gateway (zuul)
JSD-2204-酷鲨商城(管理商品模块)-Day02
How to close the case prompt icon of win11? Closing method of win11 case prompt Icon
如何用U盘进行装机?
GoLang日志编程系统
软件测试岗:阿里三面,幸好做足了准备,已拿offer
Arthas' dynamic load class (retransform)
C language layered understanding (C language function)
富文本转化为普通文本
[steering wheel] tool improvement: common shortcut key set of sublime text 4
FPGA_Vivado软件初次使用流程_超详细
当点击Play以后,EditorWindow中的变量会被莫名其妙销毁.