当前位置:网站首页>Small sample fault diagnosis - attention mechanism code - Implementation of bigru code parsing
Small sample fault diagnosis - attention mechanism code - Implementation of bigru code parsing
2022-06-24 08:19:00 【Fault diagnosis and python learning】
List of articles
- 1 Reference paper
- 2 Open source code
- 3. Abstract
- 4. Fault diagnosis flow chart
- 5. A network model
- 6. Introduction to network structure
- 7. Network model code
1 Reference paper
Fault diagnosis for small samples based on attention mechanism
2 Open source code
https://github.com/liguge/Fault-diagnosis-for-small-samples-based-on-attention-mechanism
3. Abstract
Aiming at the application of deep learning in fault diagnosis , Mechanical rotating equipment components are prone to failure in complex working environment , There are limited labeled samples of industrial big data 、 Different working conditions 、 Noise and so on . For the above problems , A two path convolution and attention mechanism is proposed (DCA) And two-way gated circulation unit (DCA- bigru) Small sample fault diagnosis method , The performance of this method can be effectively mined by the latest regularization training strategy . utilize BiGRU Realize the fusion of space-time features , utilize DCA Extract the features of the vibration signal fused with the right of attention . Besides , Also pool the global average (GAP) Applied to dimension reduction and fault diagnosis . Experiments show that ,DCA-BiGRU It has excellent generalization ability and robustness , It can effectively diagnose various complex situations .
4. Fault diagnosis flow chart

5. A network model
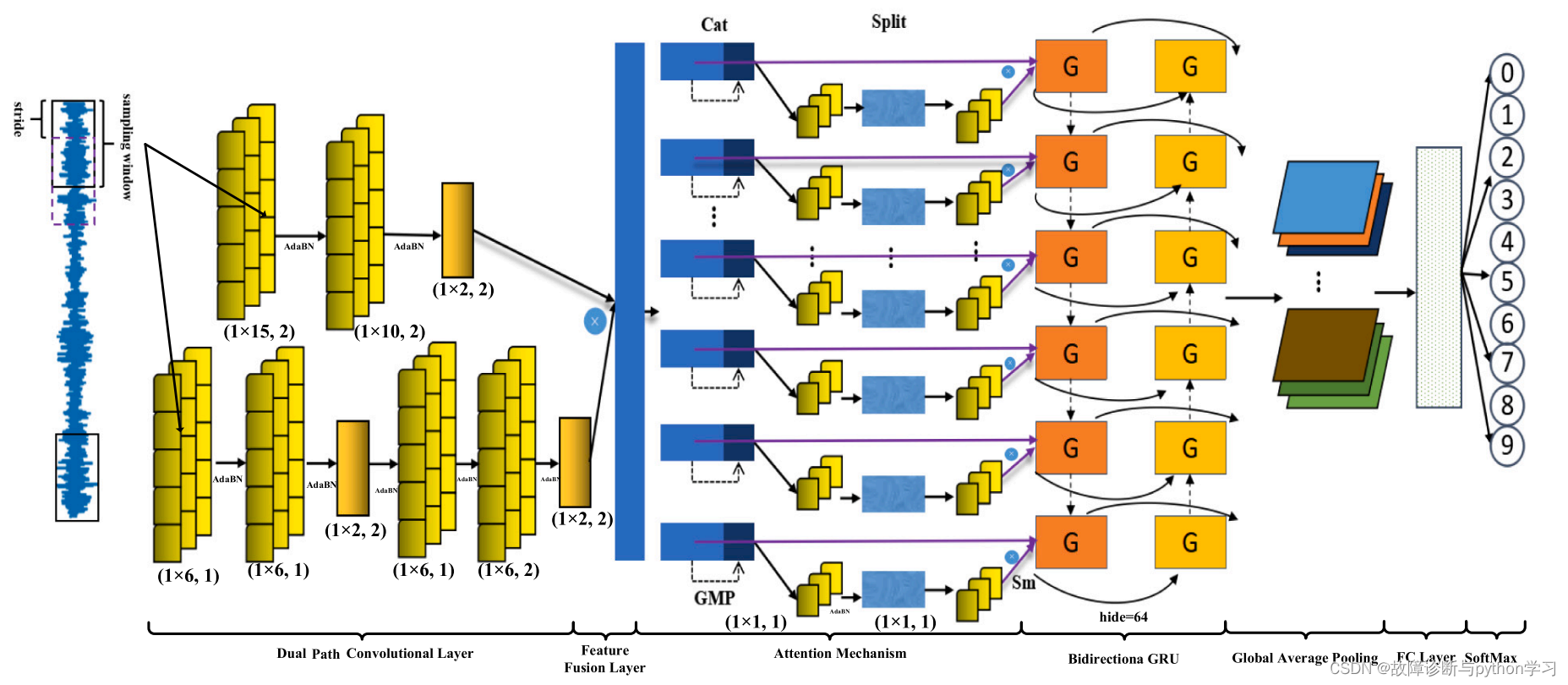
6. Introduction to network structure
Input 1 D data :[batch_size, 1, 1024]–> Two channel convolution –> Feature fusion (cat)–> Attention mechanism –>Bidirection GRU–> Global average pooling (Global average pool)–> Fully connected layer –>softmax Calculate classification probability
7. Network model code
It is recommended to use pytorch,jupyter notebook
7.1MetaAconC
Module code
import torch
from torch import nn
class AconC(nn.Module):
r""" ACON activation (activate or not). # AconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is a learnable parameter # according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>. """
def __init__(self, width):
super().__init__()
self.p1 = nn.Parameter(torch.randn(1, width, 1))
self.p2 = nn.Parameter(torch.randn(1, width, 1))
self.beta = nn.Parameter(torch.ones(1, width, 1))
def forward(self, x):
return (self.p1 * x - self.p2 * x) * torch.sigmoid(self.beta * (self.p1 * x - self.p2 * x)) + self.p2 * x
class MetaAconC(nn.Module):
r""" ACON activation (activate or not). # MetaAconC: (p1*x-p2*x) * sigmoid(beta*(p1*x-p2*x)) + p2*x, beta is generated by a small network # according to "Activate or Not: Learning Customized Activation" <https://arxiv.org/pdf/2009.04759.pdf>. """
def __init__(self, width, r=16):
super().__init__()
self.fc1 = nn.Conv1d(width, max(r, width // r), kernel_size=1, stride=1, bias=True)
self.bn1 = nn.BatchNorm1d(max(r, width // r), track_running_stats=True)
self.fc2 = nn.Conv1d(max(r, width // r), width, kernel_size=1, stride=1, bias=True)
self.bn2 = nn.BatchNorm1d(width, track_running_stats=True)
self.p1 = nn.Parameter(torch.randn(1, width, 1))
self.p2 = nn.Parameter(torch.randn(1, width, 1))
def forward(self, x):
beta = torch.sigmoid(self.bn2(self.fc2(self.bn1(self.fc1(x.mean(dim=2, keepdims=True))))))
return (self.p1 * x - self.p2 * x) * torch.sigmoid(beta * (self.p1 * x - self.p2 * x)) + self.p2 * x
Code testing
x = torch.randn(16, 64, 1024) # Assume that the input x:batch_size=16, channel=64, length=1024
Meta = MetaAconC(64) # When creating an object, you need to enter parameters width, It is the... Of the input data channel
y = Meta(x)
print(y.shape)
>>>output
x.shape: torch.Size([16, 64, 1024])
y.shape: torch.Size([16, 64, 1024])
The result shows that , Input x Of shape And output y Of shape It's the same
7.2 Attention mechanism
Structure of attention mechanism

Module code
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
# self.pool_w = nn.AdaptiveAvgPool1d(1)
self.pool_w = nn.AdaptiveMaxPool1d(1)
mip = max(6, inp // reduction)
self.conv1 = nn.Conv1d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm1d(mip, track_running_stats=False)
self.act = MetaAconC(mip)
self.conv_w = nn.Conv1d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
n, c, w = x.size()
x_w = self.pool_w(x)
y = torch.cat([identity, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_ww, x_c = torch.split(y, [w, 1], dim=2)
a_w = self.conv_w(x_ww)
a_w = a_w.sigmoid()
out = identity * a_w
return out
Module code test
x = torch.randn(16, 64, 1024) # Assume that the input x:batch_size=16, channel=64, length=1024
Att = CoordAtt(inp=64, oup=64) # Create an attention mechanism object , Input parameters inp and oup The parameters are channel
y = Att(x)
print('y.shape:',y.shape)
>>>output
y.shape: torch.Size([16, 64, 1024])
The result shows that , Input x Of shape And output y Of shape It's the same
7.3 BiGRU test
BiGRU chart

x = torch.randn(16, 64, 128) # Assume that the input x:batch_size=16, channel=64, length=128
gru = nn.GRU(128, 64, bidirectional=True) # establish GRU object ,128 It's input data x The length of ;
# If bidirectional by False,64 Is the length of the output data ; If bidirectional by True, Then the output length is 64*2
y = gru(x)
print('y Value :\n',y)
print('y[0] Of shape',y[0].shape)
>>>output
y Value :
(tensor([[[-0.7509, -0.0468, 0.2881, ..., -0.6559, 0.5780, 0.3481],
[ 0.4099, 0.1912, -0.2534, ..., -0.2067, -0.1099, -0.3594],
[ 0.0275, 0.0937, -0.4309, ..., -0.6266, 0.5375, 0.2510],
...,
[-0.1896, -0.0118, -0.4895, ..., 0.2022, 0.3144, 0.1806],
[-0.5026, 0.4926, -0.2578, ..., -0.3386, -0.3908, -0.1203],
[-0.0431, -0.1084, 0.4494, ..., 0.4320, -0.2916, 0.4126]]],
grad_fn=<StackBackward0>))
y[0] Of shape torch.Size([16, 64, 128])
As can be seen from the results ,y The output of is a tuple A tuple type , So it USES y[0] Get the inside tensor data .
7.4 Global average pooling GAP test
# The first step is to type x
x = torch.randn(16, 64, 32) # Assume that the input x:batch_size=16, channel=64, length=128
print('x Value :\n',x)
print('x[0][0] Value :',x[0][0])
print('x[0][0] Average value :',torch.mean(x[0][0]))
# The second step is adaptive average pooling
adavp = nn.AdaptiveAvgPool1d(1) #
y = adavp(x)
print('y Value :',y)
print('y Of shape:',y.shape)
# The third step
z = y.squeeze()
print('z Of shape:',z.shape)
x Value :
tensor([[[ 7.8979e-01, 1.3657e-01, -9.9066e-01, ..., 9.5261e-01,
9.8295e-02, 6.5511e-01],
[-3.5707e-01, -2.3277e+00, -3.2558e-01, ..., -2.2010e-01,
-1.6210e+00, -1.2564e+00],
[ 1.0400e+00, -1.8403e-01, 1.1634e+00, ..., 5.7404e-02,
-7.0334e-01, -1.5286e-01],
...,
[-1.7541e+00, 5.9410e-01, -1.3539e-01, ..., 8.6600e-02,
1.2851e+00, -2.1541e+00],
[ 1.6649e+00, -3.0008e+00, -6.5557e-01, ..., 3.8984e-01,
-2.4122e+00, 1.3892e+00],
[ 3.2660e-01, 1.4245e+00, 8.2627e-01, ..., -1.1504e+00,
8.5084e-01, -2.3794e-02]]])
x[0][0] Value : tensor([ 0.7898, 0.1366, -0.9907, -0.9970, 1.6666, -1.5021, 0.9952, 0.5044,
0.0828, 1.1746, -1.1589, -1.2519, -1.6039, -0.9943, 0.4700, -0.5370,
0.5983, -0.6333, -1.3765, -0.9212, -0.3939, -0.7217, 0.4318, 0.4706,
0.6322, -0.4217, -1.0003, 1.6015, 0.5162, 0.9526, 0.0983, 0.6551])
x[0][0] Average value : tensor(-0.0852)
y Value : tensor([[[-0.0852],
[-0.6024],
[-0.0316],
...,
[ 0.0157],
[-0.2135],
[ 0.1926]]])
y Of shape: torch.Size([16, 64, 1])
z Of shape: torch.Size([16, 64])
As can be seen from the results , input data x1.shape=[16, 64, 32] Global average pooling is the last dimension of input data , And 32 Data points are averaged . obtain [16, 64]
7.5 Overall network test
Overall network code
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.p1_1 = nn.Sequential(nn.Conv1d(in_channels=1, out_channels=50, kernel_size=18, stride=2),
nn.BatchNorm1d(50, track_running_stats=False),
MetaAconC(50))
self.p1_2 = nn.Sequential(nn.Conv1d(50, 30, kernel_size=10, stride=2),
nn.BatchNorm1d(30, track_running_stats=False),
MetaAconC(30))
self.p1_3 = nn.MaxPool1d(2, 2)
self.p2_1 = nn.Sequential(nn.Conv1d(1, 50, kernel_size=6, stride=1),
nn.BatchNorm1d(50, track_running_stats=False),
MetaAconC(50))
self.p2_2 = nn.Sequential(nn.Conv1d(50, 40, kernel_size=6, stride=1),
nn.BatchNorm1d(40, track_running_stats=False),
MetaAconC(40))
self.p2_3 = nn.MaxPool1d(2, 2)
self.p2_4 = nn.Sequential(nn.Conv1d(40, 30, kernel_size=6, stride=1), nn.BatchNorm1d(30, track_running_stats=False),MetaAconC(30))
self.p3_0 = CoordAtt(30, 30)
self.p2_5 = nn.Sequential(nn.Conv1d(30, 30, kernel_size=6, stride=2),
nn.BatchNorm1d(30, track_running_stats=False),
MetaAconC(30))
self.p2_6 = nn.MaxPool1d(2, 2)
self.p3_1 = nn.Sequential(nn.GRU(124, 64, bidirectional=True)) #
# self.p3_2 = nn.Sequential(nn.LSTM(128, 512))
self.p3_3 = nn.Sequential(nn.AdaptiveAvgPool1d(1)) #GAP
self.p4 = nn.Sequential(nn.Linear(30, 10))
def forward(self, x):
p1 = self.p1_3(self.p1_2(self.p1_1(x)))
print('p1.shape:',p1.shape)
p2 = self.p2_6(self.p2_5(self.p2_4(self.p2_3(self.p2_2(self.p2_1(x))))))
print('p2.shape:',p2.shape)
encode = torch.mul(p1, p2)
print('encode.shape:',encode.shape)
# p3 = self.p3_2(self.p3_1(encode))
p3_0 = self.p3_0(encode).permute(1, 0, 2)
print('p3_0.shape:',p3_0.shape)
p3_2, _ = self.p3_1(p3_0)
print('p3_2.shape:',p3_2.shape)
# p3_2, _ = self.p3_2(p3_1)
p3_11 = p3_2.permute(1, 0, 2) #
print('p3_11.shape:',p3_11.shape)
p3_12 = self.p3_3(p3_11).squeeze()
print('p3_12.shape:',p3_12.shape)
# p3_11 = h1.permute(1,0,2)
# p3 = self.p3(encode)
# p3 = p3.squeeze()
# p4 = self.p4(p3_11) # LSTM(seq_len, batch, input_size)
# p4 = self.p4(encode)
p4 = self.p4(p3_12)
print('p4.shape:',p4.shape)
return p4
Code testing
model = Net()
x = torch.randn(16, 1, 1024) # Assume that the input x:batch_size=16, channel=1, length=1024
y = model(x)
>>>output
p1.shape: torch.Size([16, 30, 124])
p2.shape: torch.Size([16, 30, 124])
encode.shape: torch.Size([16, 30, 124])
p3_0.shape: torch.Size([30, 16, 124])
p3_2.shape: torch.Size([30, 16, 128])
p3_11.shape: torch.Size([16, 30, 128])
p3_12.shape: torch.Size([16, 30])
p4.shape: torch.Size([16, 10])
8 Experimental setup
8.1 Model parameter settings

8.2 Experimental data setting

9 Experimental verification
Case study 1:CWRU
Different batch_size The next result
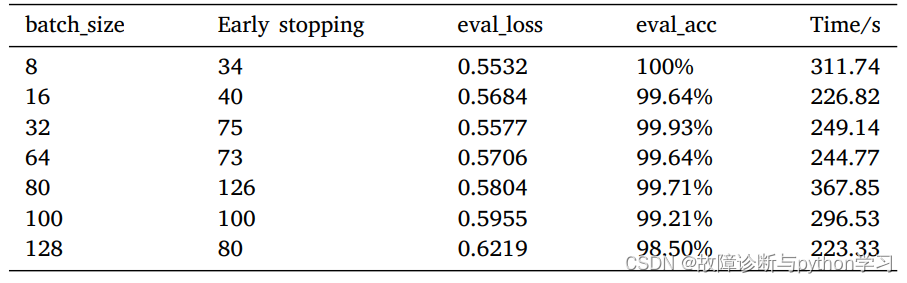
Results under different loads

( Continue to improve in the future )
notes :
① If this paper is helpful to you , It is suggested to quote this thesis ~
② Welcome to the official account 《 Fault diagnosis and maintenance Python Study 》
③ If there is good open source code , Welcome to contact the backstage to recommend ~
边栏推荐
- Swift Extension ChainLayout(UI的链式布局)(源码)
- LabVIEW查找n个元素数组中的质数
- 2022 PMP project management examination agile knowledge points (1)
- [008] filter the table data row by row, jump out of the for cycle and skip this cycle VBA
- Getting started with ffmpeg
- QOpenGL显示点云文件
- Examples of corpus data processing cases (reading multiple text files, reading multiple files specified under a folder, decoding errors, reading multiple subfolder text, batch renaming of multiple fil
- Question 1: the container that holds the most water
- 1-4metaploitable2 introduction
- 蓝桥杯_N 皇后问题
猜你喜欢

2022茶艺师(中级)上岗证题库及在线模拟考试
Installation and use of selenium IDE
![[008] filter the table data row by row, jump out of the for cycle and skip this cycle VBA](/img/a0/f03b8d9c8f5e53078c38cce11f8ad3.png)
[008] filter the table data row by row, jump out of the for cycle and skip this cycle VBA

快速读论文----AD-GCL:Adversarial Graph Augmentation to Improve Graph Contrastive Learning
小样本故障诊断 - 注意力机制代码 - BiGRU代码解析实现

More than observation | Alibaba cloud observable suite officially released

WCF TCP protocol transmission

Écouter le réseau d'extension SWIFT (source)

Coordinate transformation of graphic technology

问题4 — DatePicker日期选择器,2个日期选择器(开始、结束日期)的禁用
随机推荐
一文带你了解Windows操作系统安全,保护自己的电脑不受侵害
51单片机_外部中断 与 定时/计数器中断
LabVIEW查找n个元素数组中的质数
首次曝光 唯一全域最高等级背后的阿里云云原生安全全景图
Swift Extension NetworkUtil(网络监听)(源码)
Introduction to software engineering - Chapter 2 - feasibility study
[introduction to point cloud dataset]
Utilisation de la fermeture / bloc de base SWIFT (source)
研究生英语期末考试复习
MAYA重新拓布
Leetcode 207: course schedule (topological sorting determines whether the loop is formed)
Live broadcast review | detailed explanation of koordinator architecture of cloud native hybrid system (complete ppt attached)
Learning event binding of 3D visualization from scratch
5g industrial router Gigabit high speed low delay
About the iframe anchor, the anchor is offset up and down, and the anchor has page display problems Srcdoc problem of iframe
[teacher zhaoyuqiang] use the Oracle tracking file
不止于观测|阿里云可观测套件正式发布
新准则金融资产三分类:AMC、FVOCI和FVTPL
Robot acceleration level task priority inverse kinematics
【毕业季】你好陌生人,这是一封粉色信笺