当前位置:网站首页>Multimodal learning pooling with context gating for video classification
Multimodal learning pooling with context gating for video classification
2022-06-29 06:59:00 【Programmers who only know git clone】
Preface
Address of thesis :arxiv
Code address :github
This is a video understanding article paper, The main reason for the multimodality is that the structure combines video embedding, Audio embedding And so on , It can be said to be multimodal fusion .
notes : The paper Won Youtube 8M Kaggle Large-Scale Video understading The champion of the game , Address of the competition : Portal .
Series articles
Updating …
motivation
There seems to be no motivation in the competition articles ? After reading the profile, I felt that I was basically influenced by others paper Inspired by the , Then try the effect of a certain structure in this field , Find out work I used it .
- The game provides the image frame features corresponding to the video , And audio features , Therefore, this paper does not contribute to feature extraction
- Based on the previous , This paper mainly contributes to the direction of feature fusion , The previous methods mainly used LSTM perhaps GRU Time series feature modeling , There are other methods that do not model time series, so they can directly use simple sum、meam Or something more complicated BOW、VLAD And so on . The author of this paper mainly undertakes BOW、VLAD And so on .
- suffer LSTM、GRU Inspired by the door control unit , The author designs a video classification architecture , Combine non temporal aggregation with gating mechanism , Is the following text context gating layer .
structure
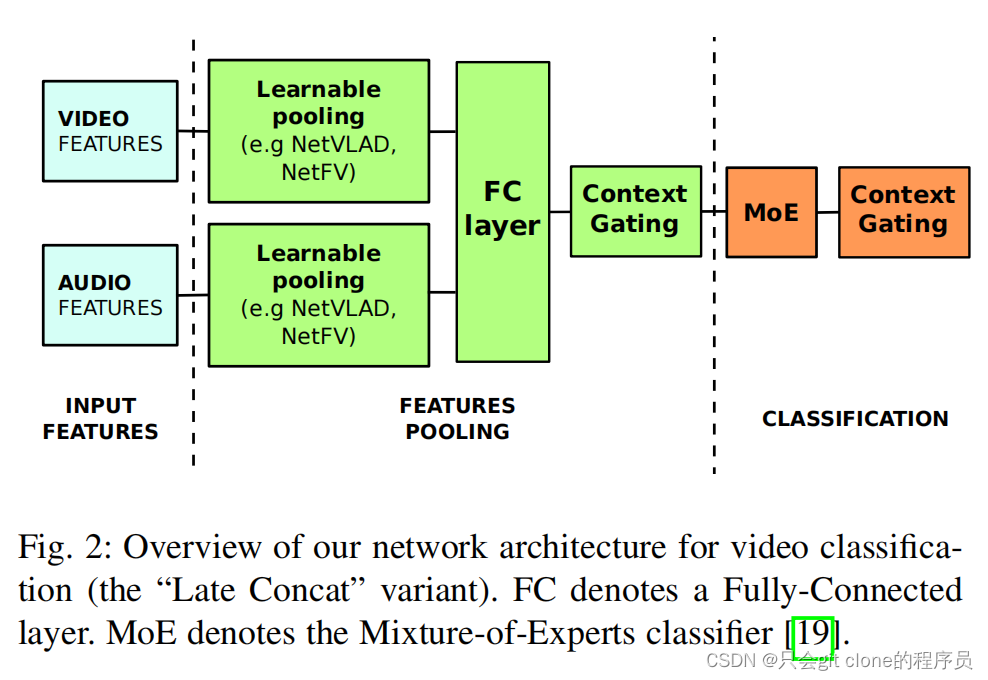
The complete structure is very simple , For ease of understanding , This paper introduces the structure of the thesis in a modular way , First introduce the overall structure, and then introduce the specific implementation of each module .
1、 The first is light blue video features, It can be understood that it is the image feature of video frame extraction provided by the competition , For example, a video is fixed 10 frame , Then suppose we use a typical resnet50 Extracting image features is generally 2048 The vector of the dimension , So we can understand the video features It's just one. (10,2048) Characteristics of .
2、audio features It should generally be that the whole audio is converted into embedding, Sometimes the audio is long and features may be extracted in several segments , Let's assume that it's divided 5 paragraph , The feature latitude extracted from each audio segment 1024, So we have to pour (5,1024) Characteristics of .
3、 Green learnable pooling part , It is the author mentioned in the motivation who has tried a variety of feature fusion methods , Such as the BOW,VLAD,NetVLAD etc. , The input to this module is (N,D) The shape of the , The output is (1,d) The shape of the , Lowercase d The reason is that the latitude of input and output is not necessarily the same, but can be any dimension , Is to put N The three features merge into 1 I mean .
4、 Therefore, from the perspective of image features pooling The module got (1,d_v) And audio features pooling The module got (1,d_a) The characteristics of the are carried out at the last latitude concat Operate to get the fusion features of video and audio (1,d_a+d_v).
5、 This concat The features of are sent to the green in the figure FC layer in , This FC layer After reading the source code of the author, it is a full connection layer plus BN Layer and activation function (FC+BN+relu6).
6、 And then to context Gating Layer , This is what you copied GLU Door control layer , original text : The authors hope to introduce a nonlinear interaction between the activation of input representations . secondly , Different activation values of inputs that wish to be recalibrated by the automatic gating mechanism . People words : Use the activation function to select how many input features need to be retained .
7、 It's out context Gating Back to MOE in ,MOE It is easy to understand how to use input to different expert The output of is weighted .
8、MOE The output is connected to another context Gating.
9、 Finally, the output features are classified and calculated loss.
Structure code example I implemented :
Basically is 1:1 According to the structure of the paper .
Module details
NetVLAD
These two statements are quite clear :
1、 You know NetVLAD
2、 Paper notes :NetVLAD: CNN architecture for weakly supervised place recognition
FC layer
Go straight to the code :
self.MLP = nn.Sequential(
nn.Linear(in_dim, out_dim),
nn.BatchNorm1d(out_dim),
nn.ReLU6()
)
context gating
The formula :
X It's the characteristics of input ,WX+b Will be X To a full connectivity layer ,f Is a nonlinear function , for instance sigmoid perhaps relu etc. , The author uses sigmoid.
MOE

MOE Is to feed input into n individual expert, Every expert With the same structure but different parameters , You can get n Output , Then the input goes through a full connection layer and the output is n A score is right n individual experts The output of is weighted to get the final output .
class Expert_model(nn.Module):
def __init__(self, input_size, output_size, hidden_size):
super(Expert_model, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.fc2 = nn.Linear(hidden_size, output_size)
self.relu = nn.ReLU()
self.log_soft = nn.LogSoftmax(1)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
out = self.log_soft(out)
return out
class MOE(nn.Module):
def __init__(self, input_size, output_size, expert_num, hidden_size=64):
super().__init__()
self.input_size = input_size
self.output_size = output_size
self.expert_num = expert_num
self.hidden_size = hidden_size
self.experts = nn.ModuleList(
[Expert_model(self.input_size, self.output_size, self.hidden_size) for i in range(self.expert_num)])
self.w_gate = nn.Linear(self.input_size, self.expert_num)
def forward(self, x):
# I like to add one sigmoid take gate The output of returns to 0-1 Between , Can prevent the gradient from disappearing
gate_weight = self.w_gate(x).sigmoid().softmax(dim=-1) # bs, expert_num
expert_outputs = [self.experts[i](x) for i in range(self.expert_num)]
expert_outputs = torch.stack(expert_outputs) # expert_num, bs, dim
gate_weight_expert = torch.einsum("bn,nbd->bd", gate_weight, expert_outputs)
return gate_weight_expert
experiment
The above is the complete structure of the thesis , The experimental results show some improvement , But a serious phenomenon was found according to the training and verification loss Change found this structure particularly easy to over fit .
So I tried in MOE Of FC Add dropout layer , And others FC Adding after layer Dropout Layers are all valid , Obviously, the over fitting , And the index still has a certain increase ~
边栏推荐
- List collection implements paging
- Qt STL类型迭代器
- To: Hou Hong: the key to enterprise digital transformation is not technology, but strategy
- 2022.02.15 - 240. Lucky number in matrix
- 二叉树的迭代法前序遍历的两种方法
- 2022.02.15 - SX10-31. House raiding III
- 关于端口转发程序的一点思考
- 力扣每日一题-第30天-594.最长和谐子序列
- JDBC connects to the database and socket sends the client.
- Chapter V online logic analyzer signaltap
猜你喜欢
关于DDNS

QT program packaging and publishing windeployqt tool

. NETCORE uses redis to limit the number of interface accesses

The annual technology inventory of cloud primitives was released, and it was the right time to ride the wind and waves

用机器人教育创造新一代生产和服务工具

QT qframe details

Qt 串口编程

Annual inventory review of Alibaba cloud's observable practices in 2021
Qt QLineEdit详解

2022.02.14 - 239. A single element in an ordered array
随机推荐
Antlr4 recognizes the format of escape string containing quotation marks
Labor skills courses integrated into steam Education
MySQL learning notes
Idea common plug-ins
百度小程序自动提交搜索
Two methods for preorder traversal of binary tree
Creating a new generation of production and service tools with robot education
Presto-Trial
Illegal forward reference and enums
. NETCORE uses redis to limit the number of interface accesses
jetson tx2
UVM验证平台
解析学习幼儿机器人教育的浪潮
IDEA常用插件
Analysis comp122 the Caesar cipher
How does schedulerx help users solve distributed task scheduling problems?
想请教一下,究竟有哪些劵商推荐?在线开户是安全么?
Json对象和Json字符串的区别
软件工程师与软件开发区别? Software Engineer和Software Developer区别?
Qt STL类型迭代器