当前位置:网站首页>Scrapy 框架学习
Scrapy 框架学习
2022-07-04 12:42:00 【华为云】
案例 jd图书爬虫
jd图书网站爬取比较容易,主要是数据的提取
spider 代码:
import scrapyfrom jdbook.pipelines import JdbookPipelineimport refrom copy import deepcopyclass JdbookspiderSpider(scrapy.Spider): name = 'jdbookspider' allowed_domains = ['jd.com'] start_urls = ['https://book.jd.com/booksort.html'] # 处理分类页面的数据 def parse(self, response): # 这里借助了selenium 先访问jd图书网,因为直接get请求jdbook 获取到只是一堆js代码,没有有用的html元素,通过selenium正常访问网页,将page_source(就是当前网页的页面内容,selenium提供的属性)返回给spider进行数据处理 # 处理大分类的列表页 response_data, driver = JdbookPipeline.gain_response_data(url='https://book.jd.com/booksort.html') driver.close() item = {} # 由于selenium返回的page_source是字符串,所以不能直接使用xpath,使用了正则(也可以借助bs4 再使用正则) middle_group_link = re.findall('<em>.*?<a href="(.*?)">.*?</a>.*?</em>', response_data, re.S) big_group_name = re.findall('<dt>.*?<a href=".*?">(.*?)</a>.*?<b>.*?</b>.*?</dt>', response_data, re.S) big_group_link = re.findall('<dt>.*?<a href=".*?channel.jd.com/(.*?)\.html">.*?</a>.*?<b>.*?</b>.*?</dt>', response_data, re.S) middle_group_name = re.findall('<em>.*?<a href=".*?">(.*?)</a>.*?</em>', response_data, re.S) for i in range(len(middle_group_link)): var = str(middle_group_link[i]) var1 = var[:var.find("com") + 4] var2 = var[var.find("com") + 4:] var3 = var2.replace("-", ",").replace(".html", "") var_end = "https:" + var1 + "list.html?cat=" + var3 for j in range(len(big_group_name)): temp_ = var_end.find(str(big_group_link[j]).replace("-", ",")) if temp_ != -1: item["big_group_name"] = big_group_name[j] item["big_group_link"] = big_group_link[j] item["middle_group_link"] = var_end item["middle_group_name"] = middle_group_name[i] # 请求大分组下的小分组的详情页 if var_end is not None: yield scrapy.Request( var_end, callback=self.parse_detail, meta={"item": deepcopy(item)} ) # 处理图书列表页的数据 def parse_detail(self, response): print(response.url) item = response.meta["item"] detail_name_list = re.findall('<div class="gl-i-wrap">.*?<div class="p-name">.*?<a target="_blank" title=".*?".*?<em>(.*?)</em>', response.body.decode(), re.S) detail_content_list = re.findall( '<div class="gl-i-wrap">.*?<div class="p-name">.*?<a target="_blank" title="(.*?)"', response.body.decode(), re.S) detail_link_list = re.findall('<div class="gl-i-wrap">.*?<div class="p-name">.*?<a target="_blank" title=".*?" href="(.*?)"', response.body.decode(), re.S) detail_price_list = re.findall('<div class="p-price">.*?<strong class="J_.*?".*?data-done="1".*?>.*?<em>¥</em>.*?<i>(.*?)</i>', response.body.decode(), re.S) page_number_end = re.findall('<span class="fp-text">.*?<b>.*?</b>.*?<em>.*?</em>.*?<i>(.*?)</i>.*?</span>', response.body.decode(), re.S)[0] print(len(detail_price_list)) print(len(detail_name_list)) for i in range(len(detail_name_list)): detail_link = detail_link_list[i] item["detail_name"] = detail_name_list[i] item["detail_content"] = detail_content_list[i] item["detail_link"] = "https:" + detail_link item["detail_price"] = detail_price_list[i] yield item # 翻页 for i in range(int(page_number_end)): next_url = item["middle_group_link"] + "&page=" + str(2*(i+1) + 1) + "&s=" + str(60*(i+1)) + "&click=0" yield scrapy.Request( next_url, callback=self.parse_detail, meta={"item": deepcopy(item)} )pipeline 代码:
# Define your item pipelines here## Don't forget to add your pipeline to the ITEM_PIPELINES setting# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html# useful for handling different item types with a single interfaceimport csvfrom itemadapter import ItemAdapterfrom selenium import webdriverimport timeclass JdbookPipeline: # 将数据写入csv文件 def process_item(self, item, spider): with open('./jdbook.csv', 'a+', encoding='utf-8') as file: fieldnames = ['big_group_name', 'big_group_link', 'middle_group_name', 'middle_group_link', 'detail_name', 'detail_content', 'detail_link', 'detail_price'] writer = csv.DictWriter(file, fieldnames=fieldnames) writer.writerow(item) return item def open_spider(self, spider): with open('./jdbook.csv', 'w+', encoding='utf-8') as file: fieldnames = ['big_group_name', 'big_group_link', 'middle_group_name', 'middle_group_link', 'detail_name', 'detail_content', 'detail_link', 'detail_price'] writer = csv.DictWriter(file, fieldnames=fieldnames) writer.writeheader() # 提供的正常访问jdbook 方法,借助selenium @staticmethod def gain_response_data(url): drivers = webdriver.Chrome("E:\python_study\spider\data\chromedriver_win32\chromedriver.exe") drivers.implicitly_wait(2) drivers.get(url) drivers.implicitly_wait(2) time.sleep(2) # print(tb_cookie) return drivers.page_source, drivers案例 当当图书爬虫
当当网的爬取也是比较容易, 但是这里需要结合scrapy-redis来实现分布式爬取数据
import urllibfrom copy import deepcopyimport scrapyfrom scrapy_redis.spiders import RedisSpiderimport re# 不再是继承Spider类,而是继承自scrapy_redis的RedisSpider类class DangdangspiderSpider(RedisSpider): name = 'dangdangspider' allowed_domains = ['dangdang.com'] # http://book.dangdang.com/ # 同时,start_urls 也不在使用, 而是定义一个redis_key, spider要爬取的request对象就以该值为key, url为值存储在redis中,spider爬取时就从redis 中获取 redis_key = "dangdang" # 处理图书分类数据 def parse(self, response): div_list = response.xpath("//div[@class='con flq_body']/div") for div in div_list: item = {} item["b_cate"] = div.xpath("./dl/dt//text()").extract() item["b_cate"] = [i.strip() for i in item["b_cate"] if len(i.strip()) > 0] # 中间分类分组 if len(item["b_cate"]) > 0: div_data = str(div.extract()) dl_list = re.findall('''<dl class="inner_dl" ddt-area="\d+" dd_name=".*?">.*?<dt>(.*?)</dt>''', div_data, re.S) for dl in dl_list: if len(str(dl)) > 100: dl = re.findall('''.*?title="(.*?)".*?''', dl, re.S) item["m_cate"] = str(dl).replace(" ", "").replace("\r\n", "") # 小分类分组 a_link_list = re.findall( '''<a class=".*?" href="(.*?)" target="_blank" title=".*?" nname=".*?" ddt-src=".*?">.*?</a>''', div_data, re.S) a_cate_list = re.findall( '''<a class=".*?" href=".*?" target="_blank" title=".*?" nname=".*?" ddt-src=".*?">(.*?)</a>''', div_data, re.S) print(a_cate_list) print(a_link_list) for a in range(len(a_link_list)): item["s_href"] = a_link_list[a] item["s_cate"] = a_cate_list[a] if item["s_href"] is not None: yield scrapy.Request( item["s_href"], callback=self.parse_book_list, meta={"item": deepcopy(item)} ) # 处理图书列表页数据 def parse_book_list(self, response): item = response.meta["item"] li_list = response.xpath("//ul[@class='bigimg']/li") # todo 改进,对不同的图书列表页做不同的处理 # if li_list is None: # print(True) for li in li_list: item["book_img"] = li.xpath('./a[1]/img/@src').extract_first() if item["book_img"] is None: item["book_img"] = li.xpath("//ul[@class='list_aa ']/li").extract_first() item["book_name"] = li.xpath("./p[@class='name']/a/@title").extract_first() item["book_desc"] = li.xpath("./p[@class='detail']/text()").extract_first() item["book_price"] = li.xpath(".//span[@class='search_now_price']/text()").extract_first() item["book_author"] = li.xpath("./p[@class='search_book_author']/span[1]/a/text()").extract_first() item["book_publish_date"] = li.xpath("./p[@class='search_book_author']/span[2]/text()").extract_first() item["book_press"] = li.xpath("./p[@class='search_book_author']/span[3]/a/text()").extract_first() next_url = response.xpath("//li[@class='next']/a/@href").extract_first() yield item if next_url is not None: next_url = urllib.parse.urljoin(response.url, next_url) yield scrapy.Request( next_url, callback=self.parse_book_list, meta={"item": item} )pipeline 代码:
import csvfrom itemadapter import ItemAdapterclass DangdangbookPipeline: # 将数据写入到csv文件中 def process_item(self, item, spider): with open('./dangdangbook.csv', 'a+', encoding='utf-8', newline='') as file: fieldnames = ['b_cate', 'm_cate', 's_cate', 's_href', 'book_img', 'book_name', 'book_desc', 'book_price', 'book_author', 'book_publish_date', 'book_press'] writer = csv.DictWriter(file, fieldnames=fieldnames) writer.writerow(item) return item def open_spider(self, spider): with open('./dangdangbook.csv', 'w+', encoding='utf-8', newline='') as file: fieldnames = ['b_cate', 'm_cate', 's_cate', 's_href', 'book_img', 'book_name', 'book_desc', 'book_price', 'book_author', 'book_publish_date', 'book_press'] writer = csv.DictWriter(file, fieldnames=fieldnames) writer.writeheader()settings 代码:
BOT_NAME = 'dangdangbook'SPIDER_MODULES = ['dangdangbook.spiders']NEWSPIDER_MODULE = 'dangdangbook.spiders'# 需要scrapy-redis 的去重功能,这里引用DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"# 以及调度器SCHEDULER = "scrapy_redis.scheduler.Scheduler"SCHEDULER_PERSIST = True# LOG_LEVEL = 'WARNING'# 设置redis 的服务地址REDIS_URL = 'redis://127.0.0.1:6379'# Crawl responsibly by identifying yourself (and your website) on the user-agentUSER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.82 Safari/537.36'# Obey robots.txt rulesROBOTSTXT_OBEY = FalseITEM_PIPELINES = { 'dangdangbook.pipelines.DangdangbookPipeline': 300,}crontab 定时执行


以上都在Linux平台的直接操作crontab。
在python环境下我们可以借助pycrontab 来操作crontab 来设置定时任务。
补充
自定义的excel 到导出文件格式代码:
from scrapy.exporters import BaseItemExporterimport xlwtclass ExcelItemExporter(BaseItemExporter): def __init__(self, file, **kwargs): self._configure(kwargs) self.file = file self.wbook = xlwt.Workbook() self.wsheet = self.wbook.add_sheet('scrapy') self.row = 0 def finish_exporting(self): self.wbook.save(self.file) def export_item(self, item): fields = self._get_serialized_fields(item) for col, v in enumerate(x for _, x in fields): self.wsheet.write(self.row, col, v) self.row += 1 边栏推荐
- Comprehensive evaluation of modular note taking software: craft, notation, flowus
- PostgreSQL 9.1 soaring Road
- 模块化笔记软件综合评测:Craft、Notion、FlowUs
- Is the outdoor LED screen waterproof?
- AI painting minimalist tutorial
- 一文掌握数仓中auto analyze的使用
- Using nsproxy to forward messages
- CVPR 2022 | transfusion: Lidar camera fusion for 3D target detection with transformer
- Read the BGP agreement in 6 minutes.
- Runc hang causes the kubernetes node notready
猜你喜欢
A taste of node JS (V), detailed explanation of express module
美团·阿里关于多模态召回的应用实践

6 分钟看完 BGP 协议。
eclipse链接数据库中测试SQL语句删除出现SQL语句语法错误
面试官:Redis 过期删除策略和内存淘汰策略有什么区别?

PostgreSQL 9.1 飞升之路
提高MySQL深分页查询效率的三种方案

Will the concept of "being integrated" become a new inflection point of the information and innovation industry?
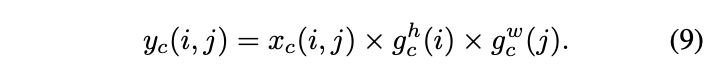
CA:用于移动端的高效坐标注意力机制 | CVPR 2021

It is six orders of magnitude faster than the quantum chemical method. An adiabatic artificial neural network method based on adiabatic state can accelerate the simulation of dual nitrogen benzene der

随机推荐
The old-fashioned synchronized lock optimization will make it clear to you at once!
面向个性化需求的在线云数据库混合调优系统 | SIGMOD 2022入选论文解读
Database lock table? Don't panic, this article teaches you how to solve it
It is six orders of magnitude faster than the quantum chemical method. An adiabatic artificial neural network method based on adiabatic state can accelerate the simulation of dual nitrogen benzene der
Building intelligent gray-scale data system from 0 to 1: Taking vivo game center as an example
BackgroundWorker用法示例
Go zero micro service practical series (IX. ultimate optimization of seckill performance)
阿里云有奖体验:用PolarDB-X搭建一个高可用系统
二分查找的简单理解
老掉牙的 synchronized 锁优化,一次给你讲清楚!
使用 NSProxy 实现消息转发
光环效应——谁说头上有光的就算英雄
实时云交互如何助力教育行业发展
MySQL three-level distribution agent relationship storage
WPF double slider control and forced capture of mouse event focus
[AI system frontier dynamics, issue 40] Hinton: my deep learning career and research mind method; Google refutes rumors and gives up tensorflow; The apotheosis framework is officially open source
XILINX/system-controller-c/BoardUI/无法连接开发板,任意操作后卡死的解决办法
SQL语言
6 分钟看完 BGP 协议。
WPF双滑块控件以及强制捕获鼠标事件焦点