当前位置:网站首页>[0701] [paper reading] allowing data imbalance issue with perforated input during influence
[0701] [paper reading] allowing data imbalance issue with perforated input during influence
2022-07-02 19:04:00 【xiongxyowo】
[ Address of thesis ] [ Code ] [MICCAI 21]
Abstract
Due to the data imbalance between common diseases and rare diseases , Intelligent diagnosis tends to favor common diseases . Even if the rebalancing strategy is applied during model training , This prejudice may still exist . To further alleviate this prejudice , We have come up with a new method , This method works not in the training stage but in the reasoning stage . For any test input data , Based on the difference between the temperature adjusted classifier output and the target probability distribution obtained from the inverse frequency of different diseases , The input data can be slightly disturbed in a way similar to adversarial learning . Compared with the original input , Classifier predictions of disturbed inputs will become less biased towards common diseases . The proposed reasoning stage method can be naturally combined with the rebalancing strategy of any training stage . Extensive evaluation on three different medical image classification tasks and three classifier backbones shows , Our method can continuously improve the performance of the classifier , Even after training in any rebalancing strategy . Especially in a few categories , The performance improvement is huge , This proves the effectiveness of the proposed method in alleviating the bias of the classifier against the dominant category .
Method
This paper solves the problem of unbalanced data set in medical diagnosis , namely , Samples of rare diseases are difficult to collect . The specific method belongs to a kind of post-processing based on test (Test-Time Postprocessing) Methods , Compared with the traditional pre-test pretreatment (Training-Time Preprocessing) There is a certain novelty in the way . The overall process is as follows :
Consider that the data set contains C C C Class training data , Among them the first c c c The number of samples of class is n c n_c nc. If a certain category i i i Of the samples are dominant , So for any input sample x x x, Output softmax probability p p p It also tends to be predicted as a category i i i. Then the practice of this article is also very simple , Disturb the sample during the test , Make it softmax The output is biased towards a few classes .
In the sample x x x Input to the network , You can get FC Layer of logit Output vector z = [ z 1 , z 2 , . . . , z C ] T z = [z_1, z_2,...,z_C]^T z=[z1,z2,...,zC]T. The final classification probability is calculated by taking this z z z Input to softmax In the classifier . about softmax for , It has a temperature coefficient T T T, In normal classification, we set it to 1 Of , In some tasks, such as knowledge distillation , We will set it to be greater than 1, Thus making softmax Output is more " smooth ". So here is also a truth , increase T, Make the prediction probability of common classes lower , The prediction probability of uncommon classes is improved p ^ c = exp ( z c / T ) ∑ k = 1 C exp ( z k / T ) \hat{p}_{c}=\frac{\exp \left(z_{c} / T\right)}{\sum_{k=1}^{C} \exp \left(z_{k} / T\right)} p^c=∑k=1Cexp(zk/T)exp(zc/T) Of course , Just do this step , It can only be said that the prediction probability gap between different classes can be shortened , Not directly " The class with the second highest probability is optimized into the class with the first highest probability ". And in order to achieve this , This paper realizes a perturbation vector : p c ∗ = g ( n c ) ∑ k = 1 C g ( n k ) p_{c}^{*}=\frac{g\left(n_{c}\right)}{\sum_{k=1}^{C} g\left(n_{k}\right)} pc∗=∑k=1Cg(nk)g(nc) So the idea of this thing is actually very primitive . among g ( n c ) = l o g ( M / n c ) g(n_c) = log(M/n_c) g(nc)=log(M/nc), That is, the more frequently a class appears in the training set , So g ( n c ) g(n_c) g(nc) The lower it is . Now? , We will p c ∗ p_{c}^{*} pc∗ As a true value , Then you can get p c ∗ p_{c}^{*} pc∗ And the original forecast p c p_{c} pc The difference of . Based on this difference , You can deduce the corresponding noise that needs to be added : x ~ = x − ε ⋅ sign ( ∇ ℓ ( p ^ , p ∗ ) ) \tilde{\mathbf{x}}=\mathbf{x}-\varepsilon \cdot \operatorname{sign}\left(\nabla \ell\left(\hat{\mathbf{p}}, \mathbf{p}^{*}\right)\right) x~=x−ε⋅sign(∇ℓ(p^,p∗)) So as to achieve the effect of correction in the actual test stage .
Experiment
stay 3 Strip bias Medical data set for Skin7,OCTMNIST,X-ray6 We did experiments on .
Comparison methods include traditional class-level re-weighting,focal loss And more modern two-stage deferred re-sampling,margin-based method LDAM.
边栏推荐
- 开源物联网平台ThingsBoard的安装
- yolov3 训练自己的数据集之生成train.txt
- 拦截器与过滤器的区别
- Novice must see, click two buttons to switch to different content
- 彻底搞懂基于Open3D的点云处理教程!
- Leetcode(81)——搜索旋转排序数组 II
- 使用CLion编译OGLPG-9th-Edition源码
- Looking for innocence in New York -- a beautiful day at the discovery center of Legoland, New Jersey
- 《病人家属,请来一下》读书笔记
- [100 cases of JVM tuning practice] 01 - introduction of JVM and program counter
猜你喜欢
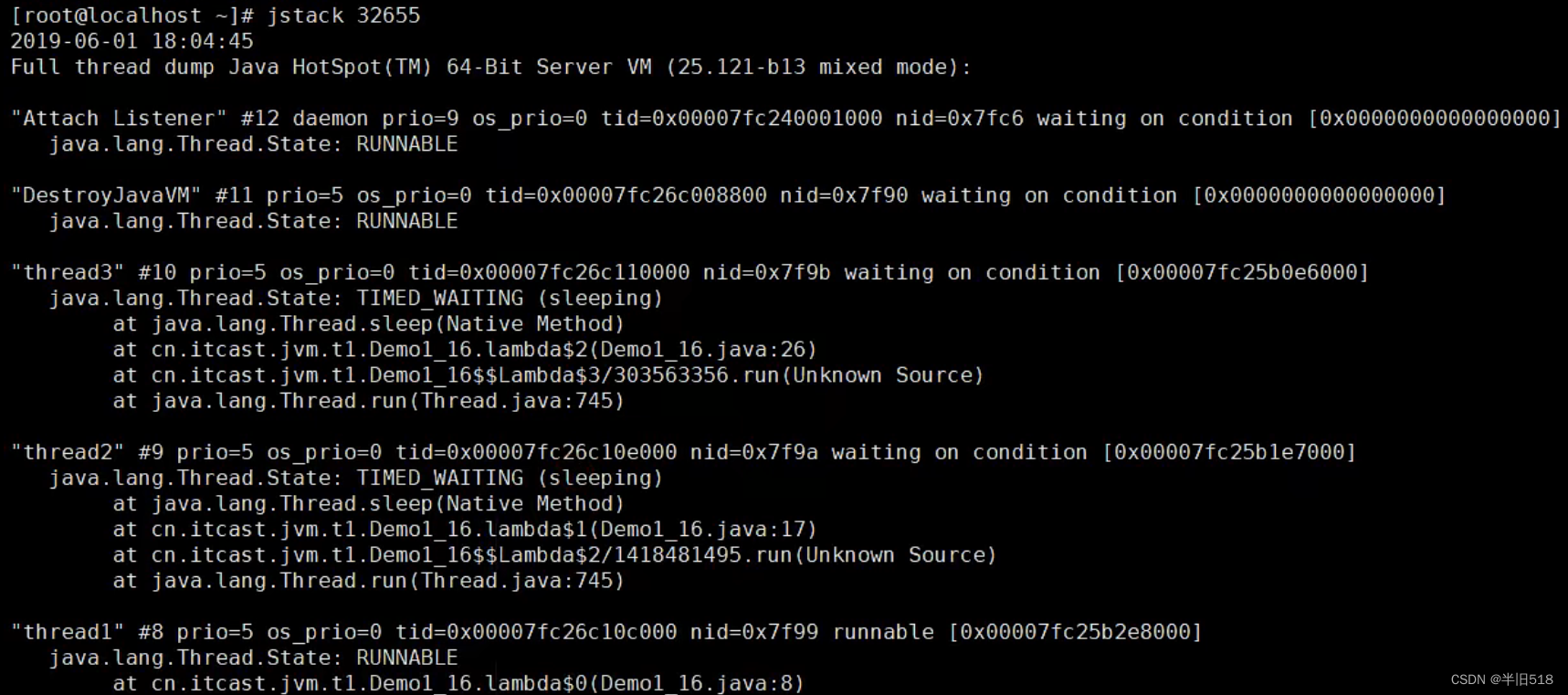
【JVM调优实战100例】02——虚拟机栈与本地方法栈调优五例

Novice must see, click two buttons to switch to different content
![[100 cases of JVM tuning practice] 03 -- four cases of JVM heap tuning](/img/54/8a18cd30e6186528599c0556b1ee3b.png)
[100 cases of JVM tuning practice] 03 -- four cases of JVM heap tuning
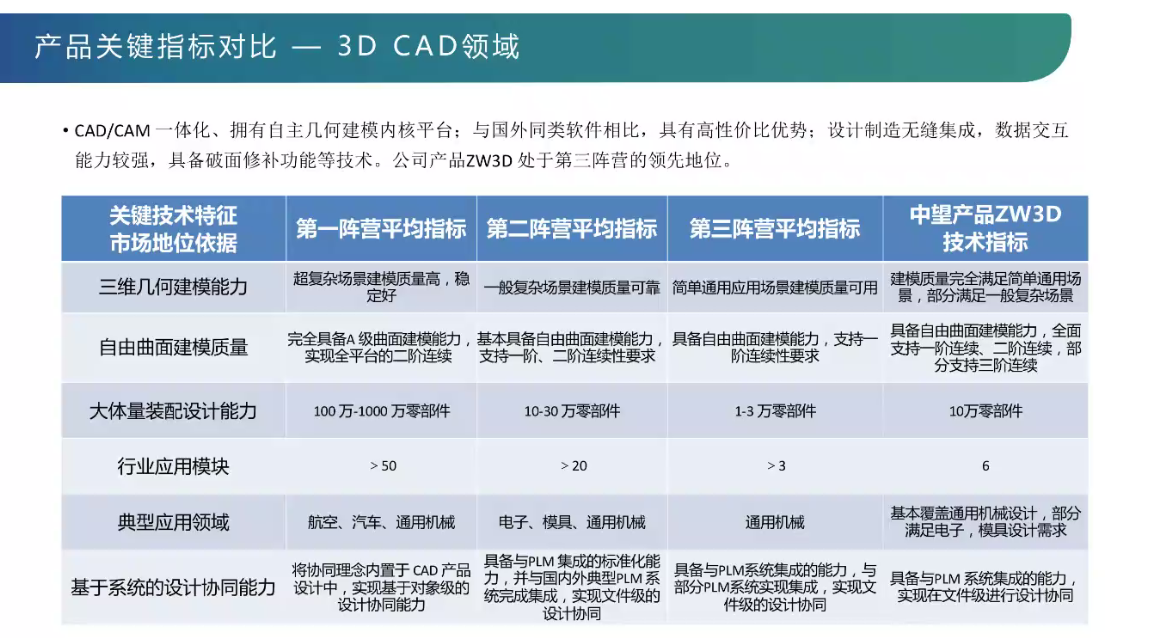
工业软件讲堂-三维CAD设计软件的核心技术解析----讲坛第二次讲座

高频面试题
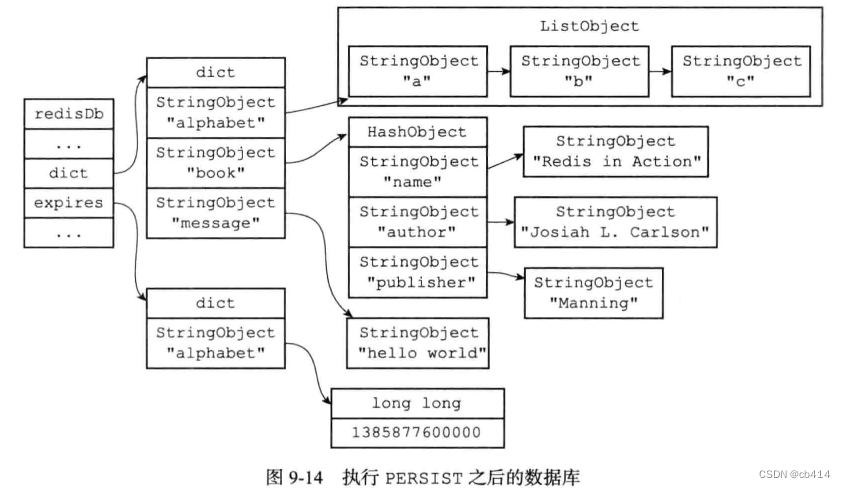
Redis (7) -- database and expiration key

Kubernetes three open interfaces first sight

Responses of different people in technology companies to bugs | daily anecdotes
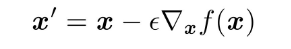
Deep learning mathematics foundation
使用CLion编译OGLPG-9th-Edition源码
随机推荐
新手必看,点击两个按钮切换至不同的内容
消息队列消息丢失和消息重复发送的处理策略
[100 cases of JVM tuning practice] 02 - five cases of virtual machine stack and local method stack tuning
2022软件工程期末考试 回忆版
文字编辑器 希望有错误的句子用红色标红,文字编辑器用了markdown
【测试开发】软件测试—概念篇
R语言ggplot2可视化:gganimate包创建动态柱状图动画(gif)、使用transition_states函数在动画中沿给定维度逐步显示柱状图
The R language dplyr package rowwise function and mutate function calculate the maximum value of multiple data columns in each row in the dataframe data, and generate the data column (row maximum) cor
【愚公系列】2022年07月 Go教学课程 001-Go语言前提简介
options should NOT have additional properties
R语言使用epiDisplay包的lrtest函数对多个glm模型(logisti回归)执行似然比检验(Likelihood ratio test)对比两个模型的性能是否有差异、广义线性模型的似然比检
Learn the knowledge points of eight part essay ~ ~ 1
The student Tiktok publicized that his alma mater was roast about "reducing the seal of enrollment". Netizen: hahahahahahahaha
LightGroupButton* sender = static_ cast<LightGroupButton*>(QObject::sender());
CDN acceleration and breaking J anti-theft chain function
What is cloud primordial? This time, I can finally understand!
Web version 3D visualization tool, 97 things programmers should know, AI frontier paper | information daily # 2022.07.01
How to write controller layer code gracefully?
[0701] [论文阅读] Alleviating Data Imbalance Issue with Perturbed Input During Inference
徹底搞懂基於Open3D的點雲處理教程!