当前位置:网站首页>[IJCAI 2022] parameter efficient large model sparse training method, which greatly reduces the resources required for sparse training
[IJCAI 2022] parameter efficient large model sparse training method, which greatly reduces the resources required for sparse training
2022-07-25 15:58:00 【51CTO】
author : Li Shen 、 Li Yuchao
In recent days, , Alibaba cloud machine learning PAI A paper on large model sparse training 《Parameter-Efficient Sparsity for Large Language Models Fine-Tuning》 Be promoted by artificial intelligence IJCAI 2022 receive .
This paper presents a parameter efficient sparse training algorithm PST, By analyzing the importance index of weight , It is concluded that it has two characteristics : Low rank and structural . According to this conclusion ,PST The algorithm introduces two groups of small matrices to calculate the importance of weight , Compared with the original need for a matrix as large as the weight to save and update the importance index , The amount of parameters that need to be updated in sparse training is greatly reduced . Compare the commonly used sparse training algorithms ,PST The algorithm can be updated only 1.5% In the case of parameters , Achieve similar sparse model accuracy .
background
In recent years, various large models have been proposed by major companies and research institutions , These large models have parameters ranging from tens of billions to trillions , Even there have been super large models at the level of onehundredth billion . These models need to spend a lot of hardware resources for training and deployment , As a result, they are facing the dilemma of difficult application . therefore , How to reduce the resources needed for large model training and deployment has become an urgent problem .
Model compression technology can effectively reduce the resources required for model deployment , Where sparsity is achieved by removing partial weights , The computation in the model can be transformed from dense computation to sparse computation , So as to reduce memory occupation , The effect of speeding up the calculation . meanwhile , Sparse compared to other model compression methods ( Structural pruning / quantitative ), It can achieve higher compression ratio while ensuring the accuracy of the model , It is more suitable for large models with a large number of parameters .
Challenge
The existing sparse training methods can be divided into two categories , One is based on weight data-free Sparse algorithm ; One is based on data data-driven Sparse algorithm . The weight based sparse algorithm is shown in the following figure , Such as magnitude pruning[1], By calculating the weight L1 Norm to evaluate the importance of weight , Based on this, the corresponding sparse results are generated . The weight based sparse algorithm is computationally efficient , No training data is required , But the calculated importance index is not accurate , Thus affecting the accuracy of the final sparse model .

The data based sparse algorithm is shown in the figure below , Such as movement pruning[2], Calculate the product of weight and corresponding gradient as an index to measure the importance of weight . Such methods take into account the role of weights in specific data sets , Therefore, it is important to evaluate the weight more accurately . However, due to the importance of calculating and saving each weight , Therefore, such methods often require additional space to store importance indicators ( In the figure S). At the same time, compared with the weight based sparse method , Often the calculation process is more complex . These shortcomings grow with the size of the model , It will become more obvious .

in summary , Previous sparse algorithms are either efficient but not accurate ( Weight based algorithm ), Either accurate but not efficient ( Data based algorithm ). Therefore, we expect to propose an efficient sparse algorithm , It can accurately and efficiently sparse train large models .
broken
The problem with data-based sparse algorithms is that they generally introduce additional parameters of the same size as the weight to learn the importance of the weight , This makes us start to think about how to reduce the importance of introducing additional parameters to calculate weights . First , In order to maximize the use of existing information to calculate the importance of weights , We design the importance index of the weight into the following formula :

That is, we combine data-free and data-driven To jointly determine the importance of the final model weight . Known ahead data-free The importance index of does not need additional parameters to save and the calculation is efficient , So what we need to solve is how to compress the latter data-driven Additional training parameters introduced by the importance index .
Based on the previous sparse algorithm ,data-driven The importance index can be designed as  , Therefore, we begin to analyze the redundancy of the importance indicators calculated by this formula . First , Based on previous work known , The weight and the corresponding gradient have obvious low rank [3,4], Therefore, we can deduce that the importance index also has low rank , Thus, we can introduce two low rank small matrices to represent the original importance index matrix as large as the weight .
, Therefore, we begin to analyze the redundancy of the importance indicators calculated by this formula . First , Based on previous work known , The weight and the corresponding gradient have obvious low rank [3,4], Therefore, we can deduce that the importance index also has low rank , Thus, we can introduce two low rank small matrices to represent the original importance index matrix as large as the weight .

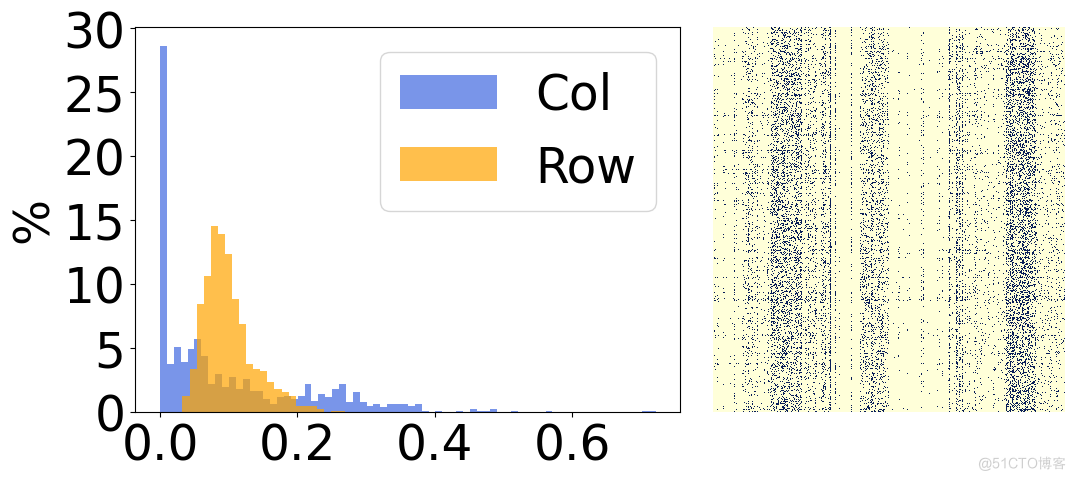
secondly , We analyze the results of the sparse model , It is found that they have obvious structural characteristics . As shown in the figure above , On the right side of each graph is the visual result of the final sparse weight , On the left is the statistics of each line / Column corresponds to the histogram of sparsity . It can be seen that , The picture on the left shows 30% Most of the weights in the rows of have been removed , conversely , The picture on the right shows 30% Most of the weights in the columns of have been removed . Based on this phenomenon , We introduce two small structured matrices to evaluate the weight of each row / The importance of columns .
Based on the above analysis , We found that data-driven The importance index of has low rank and structure , So we can convert it into the following expression :

among A and B Indicates low rank ,R and C Indicates structural . Through this analysis , The importance index matrix, which was originally as large as the weight, was decomposed into 4 A small matrix , Thus, the training parameters involved in sparse training are greatly reduced . meanwhile , To further reduce training parameters , Based on the previous method, we also decompose the weight update into two small matrices U and V, Therefore, the final importance index formula becomes the following form :

The corresponding algorithm framework is shown below :

Final PST The experimental results of the algorithm are as follows , We are NLU(BERT、RoBERTa) and NLG(GPT-2) Task and magnitude pruning and movement pruning Compare , stay 90% Under the sparsity rate of ,PST It can achieve the same model accuracy as the previous algorithm on most data sets , But just 1.5% Training parameters of .


PST Technology has been integrated into Alibaba cloud machine learning PAI Model compression library , as well as Alicemind Platform large model sparse training function . It has accelerated the performance of the large model used within Alibaba Group , In the ten billion big model PLUG On ,PST Compared with the original sparse training, the model accuracy can not be reduced , Speed up 2.5 times , Less memory 10 times . at present , Alibaba cloud machine learning PAI It has been widely used in all walks of life , Provide AI Develop full link services , Realize the independent and controllable AI programme , Improve the efficiency of machine learning engineering in an all-round way .
Title of thesis :Parameter-Efficient Sparsity for Large Language Models Fine-Tuning
Author of the paper :Yuchao Li , Fuli Luo , Chuanqi Tan , Mengdi Wang , Songfang Huang , Shen Li , Junjie Bai
The paper pdf link : https://arxiv.org/pdf/2205.11005.pdf
reference
[1] Song Han, Huizi Mao, and William J Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding.
[2] Victor Sanh, Thomas Wolf, and Alexander M Rush. Movement pruning: Adaptive sparsity by fine-tuning.
[3] Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.
[4] Samet Oymak, Zalan Fabian, Mingchen Li, and Mahdi Soltanolkotabi. Generalization guarantees for neural networks via harnessing the low-rank structure of the jacobian.
边栏推荐
- Cf750f1 thinking DP
- The difference between VaR, let and Const
- 2019 Shaanxi provincial competition j-bit operation + greed
- LeetCode - 379 电话目录管理系统(设计)
- Introduction to redis
- LeetCode - 232 用栈实现队列 (设计 双栈实现队列)
- 2021 Jiangsu race a Array line segment tree, maintain value range, Euler power reduction
- 2021 Shanghai match-h-two point answer
- 2019 Zhejiang race c-wrong arrangement, greedy
- CircleIndicator组件,使指示器风格更加多样化
猜你喜欢
【IJCAI 2022】参数高效的大模型稀疏训练方法,大幅减少稀疏训练所需资源

General test case writing specification

一文入门Redis

Geogle colab notes 1-- run the.Py file on the cloud hard disk of Geogle

Games101 review: 3D transformation

"Digital security" alert NFT's seven Scams

电阻电路的等效变化(Ⅱ)

推荐收藏,这或许是最全的类别型特征的编码方法总结

Circulaindicator component, which makes the indicator style more diversified

Redis分布式锁,没它真不行
随机推荐
Endnote cannot edit range resolution
HDD Hangzhou station · harmonyos technical experts share the features of Huawei deveco studio
Leetcode - 362 knock counter (Design)
MySQL - Summary of common SQL statements
Use cpolar to build a business website (how to buy a domain name)
Okaleido上线聚变Mining模式,OKA通证当下产出的唯一方式
Ice 100g network card fragment message hash problem
Cf365-e - Mishka and divisors, number theory +dp
推荐收藏,这或许是最全的类别型特征的编码方法总结
Cf750f1 thinking DP
The difference between VaR, let and Const
Solve the vender-base.66c6fc1c0b393478adf7.js:6 typeerror: cannot read property 'validate' of undefined problem
【莎士比亚:保持做人的乐趣】
「数字安全」警惕 NFT的七大骗局
Dpdk packet receiving and sending problem case: non packet receiving problem location triggered by mismatched packet sending and receiving function
Window system black window redis error 20creating server TCP listening socket *: 6379: listen: unknown error19-07-28
LeetCode - 677 键值映射(设计)*
如何解决跨域问题
哪里有搭建flink cdc抽mysql数的demo?
Activity review | July 6 Anyuan AI X machine heart series lecture No. 2 | MIT professor Max tegmark shares "symbiotic evolution of human and AI"