当前位置:网站首页>transformer一统天下?depth-wise conv有话要说
transformer一统天下?depth-wise conv有话要说
2022-07-26 11:47:00 【夜半罟霖】
本文是对《ON THE CONNECTION BETWEEN LOCAL ATTENTION AND DYNAMIC DEPTH-WISE CONVOLUTION》的分析,作者在cnn领域找到了和local attention模块相似的机制,以此构建出了可以和swin transformer分庭抗礼的CNN架构
局部自注意力机制研究
作者提出局部自注意力网络如swin transforme和深度可分离卷积及其动态变体在稀疏连接这一思路上有相似之处,他们的主要区别在于以下两点:
- 参数共享方面: 深度可分离卷积的参数共享在空间层面,而局部注意力的参数共享在通道层面;
- 动态权重的计算方式:局部注意力中的计算方式是基于局部窗口中的点对位置的点积;而动态卷积中的是基于中心表征的线性映射或者全局池化的表征。
location attention
对于局部自注意力机制,作者主要从 网络正则化策略包括稀疏连接和参数共享以及动态权重预测三个方面来研究。首先假定局部窗口的大小为 N k N_k Nk,即计算局部注意力的序列为 [ x i 1 , x i 2 , x i N k ] [x_{i1},x_{i2},{x_{iN_k}}] [xi1,xi2,xiNk],给出局部自注意力机制的计算公式如下。
y i = ∑ j = 1 N k a i j x i j a i j = e x p ( Q i K i j T D ) Z i , Z s = ∑ j = 1 N k e x p ( Q i K i j T D ) (1) \bold{y}_i=\sum^{N_k}_{j=1}a_{ij}\bold{x}_{ij}\tag{1}\\ a_{ij}=\frac{exp(\frac{\bold{Q}_i\bold{K}^{T}_{ij}}{D})}{Z_i},Z_s=\sum_{j=1}^{N_k}exp(\frac{\bold{Q}_i\bold{K}^{T}_{ij}}{D}) yi=j=1∑Nkaijxijaij=Ziexp(DQiKijT),Zs=j=1∑Nkexp(DQiKijT)(1)
其中 y i ∈ R D , x i j ∈ R D , a i j ∈ R \bold{y}_i\in R^D,\bold{x}_{ij}\in R^D,a_{ij}\in R yi∈RD,xij∈RD,aij∈R,实际上就是由 Q , K Q,K Q,K计算出的输入向量和窗口内向量的归一化权重 a i j a_{ij} aij,再乘上对应向量的嵌入值得出该位置的输出。同样可以写成如下点积的形式:
y i = ∑ j = 1 N k w i j ⊙ x i j \bold{y}_i=\sum^{N_k}_{j=1}\bold{w}_{ij}\odot\bold{x}_{ij} yi=j=1∑Nkwij⊙xij
其中 w i j = [ a i j , a i j , . . . , a i j ] ∈ R D \bold{w}_{ij}=[a_{ij},a_{ij},...,a_{ij}]\in R^D wij=[aij,aij,...,aij]∈RD,从这中形式的局部注意力我们可以分析出以下几条性质:
- 稀疏连接:局部自注意力中的输出在空间上是稀疏连接的,输出向量中的某个元素 y i d y^d_i yid只与窗口内所有输入向量同位置的值 [ x i 1 d , x i 2 d , . . . x i N k d ] [x^d_{i1},x^d_{i2},...x^d_{iN_k}] [xi1d,xi2d,...xiNkd]相关,没有跨通道的联系。(感觉这又有点回到了LeNet和GoogLeNet的思路)
- 参数共享:不同通道间参数是共享的(对于多头注意力来说,在组内的通道间共享),也就就是 w i j \bold{w}_{ij} wij所有值都相同。
- 动态权重:注意力或者说权重的并不是如同CNN中MLP一样通过反向传播来学习,而是与窗口内输入向量的值有关,这就使得权重的计算中传递了跨通道的信息。
- 平移不变性:由于权重的计算是在窗口内部进行,如果窗口是稀疏采样的,比如swin transformer,那么当输入图样的平移长度为窗口的整数倍时,对应的输出值也会保持值相同而位置平移。如果窗口是密集采样,以sliding window的形式采样,那输出就是完全的平移不变。
- 集合表征:窗口内的向量排列顺序并不会对输出造成影响,位置信息被忽略了,需要采用其他的方式来记录。比如可学习的位置表征或者固定的位置表征。
depth-wise convolution
首先介绍一下深度卷积,它指的是对与输入的每个通道都分开进行卷积,假定输入为 H × W × C H\times W\times C H×W×C那就用 C C C个 W × W × 1 W\times W\times 1 W×W×1的卷积D对每个通道分开处理得到 H × W × C H\times W\times C H×W×C的输出,给出窗口大小为 N K N_K NK的一维形式的深度卷积计算公式如下:
y i = ∑ j = 1 N k w o f f s e t ( i , j ) ⊙ x i j \bold{y}_i=\sum^{N_k}_{j=1}\bold{w}_{offset(i,j)}\odot\bold{x}_{ij} yi=j=1∑Nkwoffset(i,j)⊙xij
同样是从以上几个角度分析:
- 稀疏连接:同样的,由于深度卷积对输入的每个通道分开处理,某通道的输出只和同通道的输入有关,无跨通道的联系。
- 参数共享:不同空间位置上是参数共享的,也就是窗口移动时 w o f f s e t ( i , j ) \bold{w}_{offset(i,j)} woffset(i,j)不变,而 w o f f s e t ( i , j ) \bold{w}_{offset(i,j)} woffset(i,j)中的元素则并不相同。
- 动态权重:基础的深度卷积是无动态权重的,只是通过反向传播来学习卷积核的参数,而深度卷积的动态变体则引入了输入相关的权重预测,分为同质变体和异质变体,前者是对窗口内的所有输入向量做池化后线性变化,后者则是对卷积位置的输入向量直接线性变换,公式如下:
h o m o { w 1 , w 2 , . . . , w N k } = g ( G A P ( x 1 , x 2 , . . . , x N ) i n h o m o { w i 1 , w i 2 , . . . , w i N k } = g ( x i ) homo\{\bold{w}_1,\bold{w}_2,...,\bold{w}_{N_k}\}=g(GAP(\bold{x}_1,\bold{x}_2,...,\bold{x}_{N})\\ inhomo\{\bold{w}_{i1},\bold{w}_{i2},...,\bold{w}_{i{N_k}}\}=g(\bold{x}_i) homo{ w1,w2,...,wNk}=g(GAP(x1,x2,...,xN)inhomo{ wi1,wi2,...,wiNk}=g(xi)
其中 g ( ) g() g()为FC+BN+ReLu+,FC在后者的情况下,权重参数在空间位置上不共享了,而是随着窗口位置变化,但是计算权重参数的FC层参数是共享的(和多头注意力一样)。
4.集合表征:由于计算深度卷积时的权重 w o f f s e t ( i , j ) \bold{w}_{offset(i,j)} woffset(i,j)是与输入向量的对计算向量的相对位置有关的,所以隐含了空间位置信息表征,不用使用显式的位置表征。
给出性质对比图如下: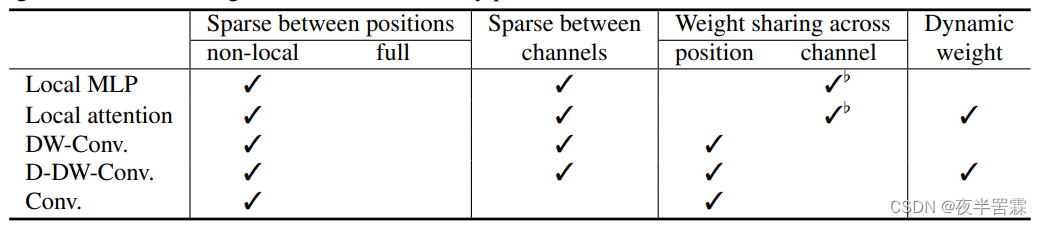
其中Local MLP指用MLP而非注意力来求输出 y i \bold{y}_i yi,D-DW-Conv指深度卷积的动态变体。可以看出深度卷积和局部注意力是非常相似的,同样是具有空间和通道层面的稀疏性,同样存在权重共享,而深度卷积的变体更进一步的拥有了相同的动态权重预测性质。
实验
作者使用深度卷积及其变体来代替swin transformer中注意力模块,前置和后置的线性变换层被替换成了1*1卷积,在多项视觉任务上进行了实验,结果如下:
可以看到在分类任务上基础的DW-Conv已经取得了和swin transformer相近的结果,而且参数和计算量更少;引入了变体之后准确率更是超过了swin transformer,其余任务上的结果类似,基础版深度卷积和swin transformer效果接近,改进版更好。
消融实验
正如之前说的,稀疏连接和参数共享以及动态权重预测是swin transformer非常重要的三个性质。稀疏连接的重要性通过swin trans和vit以及DW-CONV和CONV的结果对比就可以见得,作者通过实验来验证其余两项的重要性:
参数共享
作者对local-mlp和local-attention共享参数的通道数目对性能的影响进行了研究,对后者而言,共享参数的通道数目通过控制head的数目来改变,结果如下:
结论是适当设置共享参数的通道数目,可以涨点。(这个实验说了和没说一样,没有明确结论。)
作者也研究了通道层面的参数共享和空间层面参数共享的影响,但结果也没什么说服力,加了通道层面参数共享后,DW的结果反而更差。
动态权重预测
类似的,动态权重的有效性在前表中就可见得,作者在这里讨论了动态权重计算方式以及窗口移动方式(滑动或者是平移)的影响:
对attention机制而言,窗口移动方式影响不大;同样使用sliding的情况下,线性映射的效果要优于attention,但作者又说大模型的情况下基本没差别,也是没用的实验。
结论
local attention和深度卷积很像,且非同质动态深度卷积要优于local attention,但消融实验属实做的不咋地。
边栏推荐
- Subject 3 turns and turns
- On the construction and management of low code technology in logistics transportation platform
- 专访即构科技李凯:音视频的有趣、行业前沿一直吸引着我
- 【附下载】一款强大的Web自动化漏洞扫描工具——Xray
- Didi was fined 8billion! The era of making money from user data is over
- Redis database, which can be understood by zero foundation Xiaobai, is easy to learn and use!
- 了解string类
- Ga-rpn: recommended area network for guiding anchors
- Audio and video+
- 百问百答第48期:极客有约——可观测体系的建设路径
猜你喜欢







随机推荐
【通信原理】第三章 -- 随机过程[上]
大咖观点+500强案例,软件团队应该这样提升研发效能!
网络协议:TCP/IP协议
。。。。。。
[ten thousand words long text] Based on LSM tree thought Net 6.0 C # realize kV database (case version)
【通信原理】第一章 -- 绪论
Flink 在 讯飞 AI 营销业务的实时数据分析实践
【活动早知道】LiveVideoStack近期活动一览
10 reduce common "tricks"
7月27日19:30直播预告:HarmonyOS3及华为全场景新品发布会
3.1 create menu and game page - up
Understand the string class
PyCharm是真的强
音视频+
Exploration on cache design optimization of community like business
代码实例详解【可重入锁】和【不可重入锁】区别?
The latest heart-shaped puzzle applet source code + with flow master
如何使用数据管道实现测试现代化
Talking about web vitals
Li Kai: the interesting and cutting-edge audio and video industry has always attracted me